Python学习之路 (五)爬虫(四)正则表示式爬去名言网
爬虫的四个主要步骤
- 明确目标 (要知道你准备在哪个范围或者网站去搜索)
- 爬 (将所有的网站的内容全部爬下来)
- 取 (去掉对我们没用处的数据)
- 处理数据(按照我们想要的方式存储和使用)
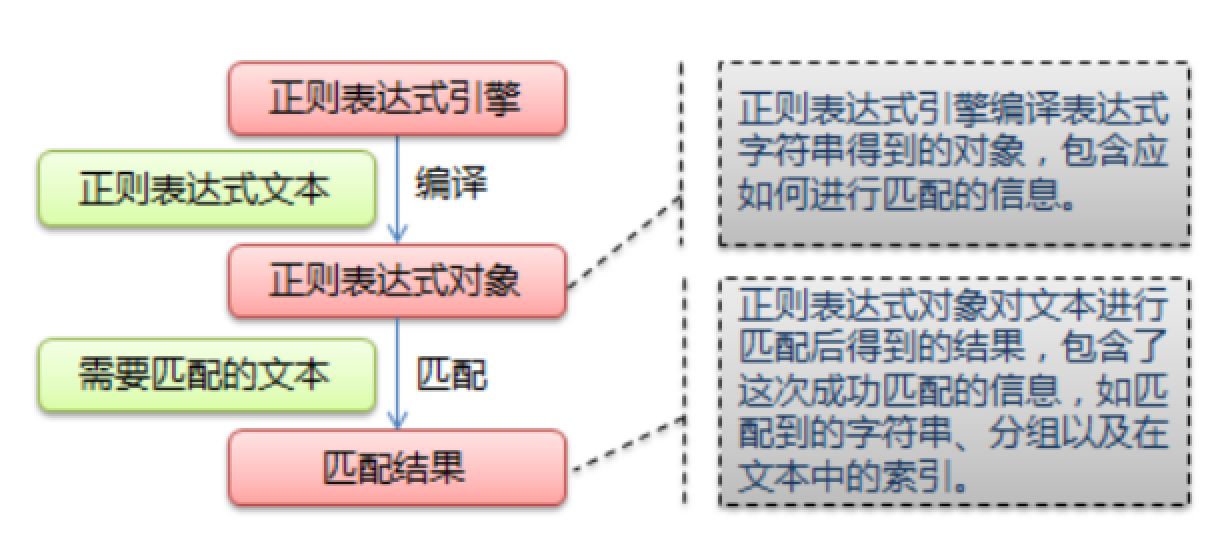
什么是正则表达式
正则表达式,又称规则表达式,通常被用来检索、替换那些符合某个模式(规则)的文本。
正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑。
给定一个正则表达式和另一个字符串,我们可以达到如下的目的:
- 给定的字符串是否符合正则表达式的过滤逻辑(“匹配”);
- 通过正则表达式,从文本字符串中获取我们想要的特定部分(“过滤”)。
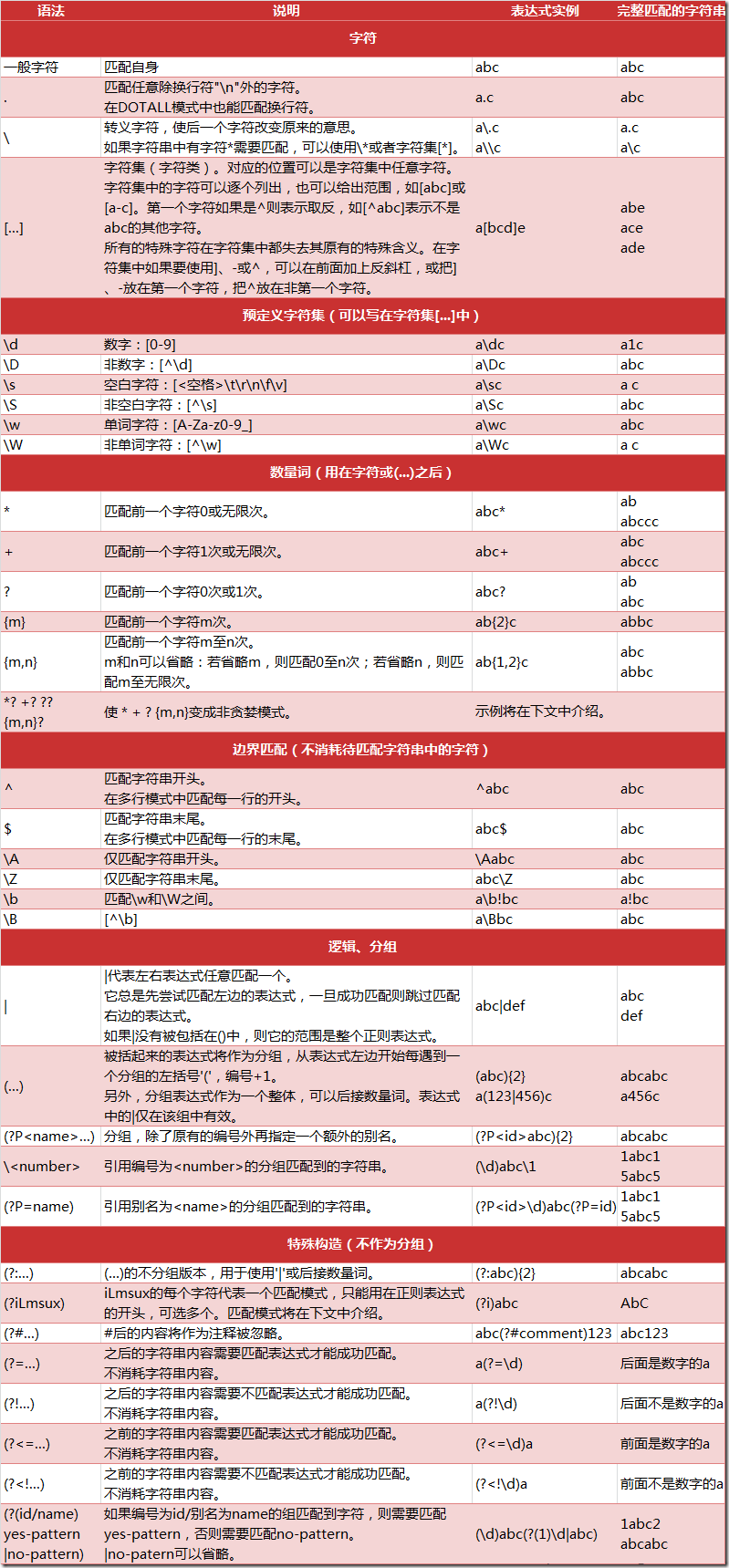
正则表达式匹配规则
Python 的 re 模块
在 Python 中,我们可以使用内置的 re 模块来使用正则表达式。
有一点需要特别注意的是,正则表达式使用 对特殊字符进行转义,所以如果我们要使用原始字符串,只需加一个 r 前缀,示例:
r'chuanzhiboke\t\.\tpython'
使用正则爬去名言网的名言,只获取首页的10条数据
from urllib.request import urlopen import re def spider_quotes(): url = "http://quotes.toscrape.com" response = urlopen(url) html = response.read().decode("utf-8") # 获取 10 个 名言 quotes = re.findall('<span class="text" itemprop="text">(.*)</span>',html) list_quotes = [] for quote in quotes: # strip 从两边开始搜寻,只要发现某个字符在当前这个方法的范围内,统统去掉 list_quotes.append(quote.strip("“”")) # 获取 10 个名言的作者 list_authors = [] authors = re.findall('<small class="author" itemprop="author">(.*)</small>',html) for author in authors: list_authors.append(author) # 获取这10个名言的 标签 tags = re.findall('<div class="tags">(.*?)</div>',html,re.RegexFlag.DOTALL) list_tags = [] for tag in tags: temp_tags = re.findall('<a class="tag" href=".*">(.*)</a>',tag) tags_t1 = [] for tag in temp_tags: tags_t1.append(tag) list_tags.append(",".join(tags_t1)) # 结果汇总 results = [] for i in range(len(list_quotes)): results.append("\t".join([list_quotes[i],list_authors[i],list_tags[i]])) for result in results: print(result) #调取方法 spider_quotes()
BeautifulSoup4解析器
BeautifulSoup 用来解析 HTML 比较简单,API非常人性化,支持CSS选择器、Python标准库中的HTML解析器,也支持 lxml 的 XML解析器。
官方文档:http://beautifulsoup.readthedocs.io/zh_CN/v4.4.0
使用BeautifulSoup4获取名言网首页数据
from urllib.request import urlopen from bs4 import BeautifulSoup url = "http://quotes.toscrape.com" response = urlopen(url) # 初始化一个 bs 实例 # 对应的response对象的解析器, 最常用的解析方式,就是默认的 html.parser bs = BeautifulSoup(response, "html.parser") # 获取 10 个 名言 spans = bs.select("span.text") list_quotes = [] for span in spans: span_text = span.text list_quotes.append(span_text.strip("“”")) # 获取 10 个名言的作者 authors = bs.select("small") list_authors = [] for author in authors: author_text = author.text list_authors.append(author_text) # 获取这10个名言的 标签 divs = bs.select("div.tags") list_tags = [] for div in divs: tag_text = div.select("a.tag") tag_list = [ tag_a.text for tag_a in tag_text] list_tags.append(",".join(tag_list)) #结果汇总 results = [] for i in range(len(list_quotes)): results.append("\t".join([list_quotes[i],list_authors[i],list_tags[i]])) for result in results: print(result)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号