
YOLO训练自己的数据集的一些心得
-------------------------------------------------------------------------------------------------
训练心得
1. 在yolo中训练时,修改源码文件detector后需要make clean 后重新make,修改cfg文件后不需要
2. 很多博客中会要求修改src中的yolo.c文件,其实那是早期的版本中训练要求的,darknet不需要。原因是这样的,在官网里有一段执行test的代码是:
./darknet detect cfg/yolo.cfg yolo.weights data/dog.jpg
这是一段简写的执行语句。它的完整形式是这样的:
./darknet detector test cfg/coco.data cfg/yolo.cfg yolo.weights data/dog.jpg
其实修改.c文件的作用就是让我们可以使用简写的test执行语句,程序会自动调用.c里面设置好的路径内容。我个人觉得这个很没有必要。
3. 当有多块GPU时,如果选择不同的卡进行训练时,输入以下命令:0或者1表示GPU的序号
./darknet detector -i 0 test cfg/voc.data cfg/yolo-voc.cfg backup/yolo-voc_final.weights testpicture/001.jpg
4. 生成的最终的final模型与中间模型没有太大区别,中间模型是不同数量的数据样本进行训练得到的。final其实就是max_batch训练完之后的那一个
5. 当训练过程中需要输出log文件即日志文件时,需要在训练时一起输出,补充以下命令:
./darknet detector train cfg/tiny-yolo.cfg tiny-yolo_8000.conv.9 2>1 | tee person_train_log.txt
命令:tee person_train_log.txt :保存log时会生成两个文件,文件1里保存的是网络加载信息和checkout点保存信息,person_train_log.txt中保存的是训练信息。
6. 当选取.cfg网络,在darknet官网还有很多博文里面都是用的yolo-voc.cfg,我用这个网络训练一直失败。体现在训练好久后test,没有bbox和predict结果。出现这种问题有两种情况,一是训练发散了;二是训练不充分,predict结果置信概率太低。
(1)对于训练发散,其实很容易发现的,就是在训练的时候观察迭代次数后边的两个loss值,如果这两个值不断变大到几百就说明训练发散啦。可以通过降低learning rate 和 提高batch数量解决这个问题;(2)对于训练不充分的时候如何显示出predict结果,可以在test的时候设置threshold,darknet默认是.25,你可以尝试逐渐降低这个值看效果。
./darknet detector test cfg/voc.data cfg/yolo-voc.cfg backup/yolo-voc_final.weights testpicture/001.jpg -thresh 0.25
7. 我在训练模型的时候输出了中间模型,发现有的模型只有0kb,但是正常的模型应该是202.3MB。由于我用的是服务器,把darkent放到桌面上了,本来桌面的存储空间就小,我又设置的迭代45000次,每1000次输出一个模型,这就意味着要占用10G,明显桌面没有这么大,后来换了一个位置后训练正常。
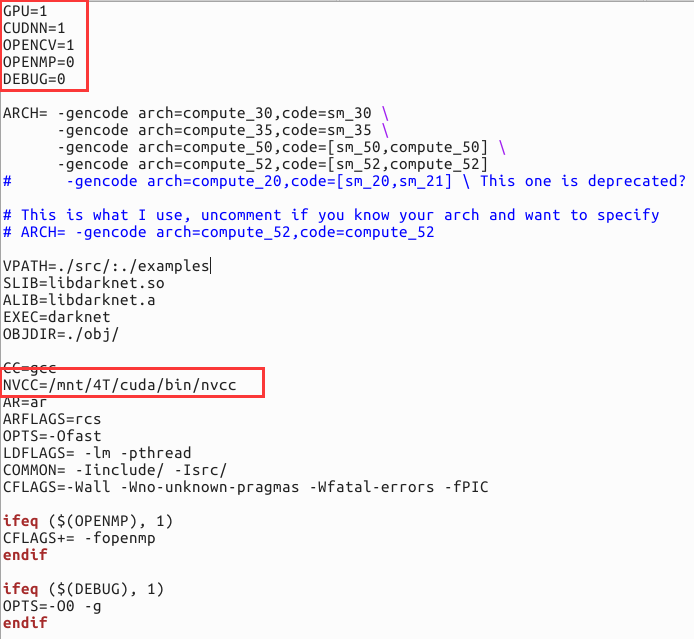
8. 开GPU跑,真的比只有CPU快很多很多倍,可以在Makefile中设置开启GPU,GPU=1 CUDNN=1 NVCC的路径也要修改。
9. 当训练过程中被中断,可以将最后一次的模型作为预训练模型继续训练。如果一次训练时间太长,可以用中间自动保存的模型继续训练,中间自动保存模型,默认文件夹不改变的情况下在backup里面,训练命令:
./darknet detector train cfg/voc.data cfg/yolo-voc.cfg yolo-voc_final.weights
不过我一开始没试成功,加上这个模型直接就除了final。
后面分析出了原因:cfg配置文件中max_batchs设置的为45000,中断之后将中断的模型作为预训练模型的前提迭代次数没有达到45000,如果之前已经训练完成了45000次,再次训练会直接输出final模型呢。如果想当完全训练完成后,会生成yolo-voc_final.weights模型,如果在现有的final模型之上继续训练,可以修改cfg配置文件。
预处理及测试
1.yolo
yolo的官网介绍了yolo的安装与测试。建议大家多看看英文官网,因为中文网更新的慢,而且有部分内容省略了。按照官网的步骤就不会有错。
2.数据的预处理
yolo的数据包括训练数据和验证数据(训练数据用来训练模型,验证数据用来调整模型)。训练数据和验证数据都包括:a.图片;b.标签。需要说明的是,如果采用VOC的话,标签需要特定xml格式,还要转化为txt。下面以我目标检测“猫”为例讲解。
(1)在“Image”文件夹下存放所有的图片样本(包括训练数据和验证数据,而且最好是jpg格式)
(2)下载labelImg(一种图像标记工具,给图像中的目标打上标签,且可以生成训练需要的xml格式),具体的使用方法可以百度,操作起来很简单。
(3)与“Image”文件夹同级新建“xml”文件夹,“xml”文件夹存放labelImg得到的所有图片样本的标签。
(4)现在就是要将所有的样本分成训练集和验证集,而且要将训练集和验证集对应的xml也分开。这里下载python脚本,直接放在“Image”和“xml”文件夹同级路径。下载链接 密码:wdv0
(5)运行traindata.py:生成trainImage文件夹,存放训练图片;生成trainImageXML文件夹,存放训练图片xml标签;生成validateImage文件夹,存放验证集图片;生成validateImageXML文件夹,存放验证集图片的xml标签。
(6)运行trans.py,生成trainImageLabelTxt文件夹,存放训练图片通过xml标签转化得到的txt文件(若在训练过程提示txt文件找不到,则把此文件夹下的txt文件夹移动到trainImage文件夹);生成validateImageLabelTxt文件夹,道理一样。
(7)另外得到的trainImagePath.txt和validateImagePath.txt存放着训练图片和验证图片的路径。
3.修改配置文件
接下来就是修改配置文件了:
(1)cfg/voc.data文件中:
classes= 1 train = /home/pdd/pdwork/darknet2/darknet/VOC/cat/trainImagePath.txt valid = /home/pdd/pdwork/darknet2/darknet/VOC/cat/validateImagePath.txt names = data/cats.names
classes存放类别总数(这里只有cat一种),train 和valid 放着的是训练图片和验证图片的路径
(2)yolo-voc.cfg
将[region]中的classes改为1(这里只有cat一类),将最后一个[convolutional](紧挨着[region]的前一个)中的filter改为30(filter的公式filters=(classes+ coords+ 1)* (NUM) ,我的是(1+4+1)* 5=30)。
(3)cats.names
在data文件夹下新建cats.names,具体见(1)。
4.下载预训练文件
下载darknet19_448.conv.23,以在其他数据集上pretrain的模型做为初值,下载链接,密码:ynhg。放在darknet文件夹下。
5.训练
在darknet文件夹路径下运行命令:
./darknet detector train cfg/voc.data cfg/yolo-voc.cfg cfg/darknet19_448.conv.23
系统默认会迭代45000次batch,如果需要修改训练次数,进入cfg/yolo_voc.cfg修改max_batches的值。
6.测试
训练完成后,模型成功保存,输入命令测试一下这个模型吧:
./darknet detector test cfg/voc.data cfg/yolo-voc.cfg backup/yolo-voc_final.weights testpicture/001.jpg
参数解释
1. cfg文件参数含义
batch: 每一次迭代送到网络的图片数量,也叫批数量。增大这个可以让网络在较少的迭代次数内完成一个epoch。在固定最大迭代次数的前提下,增加batch会延长训练时间,但会更好的寻找到梯度下降的方向。如果你显存够大,可以适当增大这个值来提高内存利用率。这个值是需要大家不断尝试选取的,过小的话会让训练不够收敛,过大会陷入局部最优。
subdivision:这个参数很有意思的,它会让你的每一个batch不是一下子都丢到网络里。而是分成subdivision对应数字的份数,一份一份的跑完后,在一起打包算作完成一次iteration。这样会降低对显存的占用情况。如果设置这个参数为1的话就是一次性把所有batch的图片都丢到网络里,如果为2的话就是一次丢一半。
angle:图片旋转角度,这个用来增强训练效果的。从本质上来说,就是通过旋转图片来变相的增加训练样本集。
saturation,exposure,hue:饱和度,曝光度,色调,这些都是为了增强训练效果用的。
learning_rate:学习率,训练发散的话可以降低学习率。学习遇到瓶颈,loss不变的话也减低学习率。
max_batches: 最大迭代次数。
policy:学习策略,一般都是step这种步进式。
step,scales:这两个是组合一起的,举个例子:learn_rate: 0.001, step:100,25000,35000 scales: 10, .1, .1 这组数据的意思就是在0-100次iteration期间learning rate为原始0.001,在100-25000次iteration期间learning rate为原始的10倍0.01,在25000-35000次iteration期间learning rate为当前值的0.1倍,就是0.001, 在35000到最大iteration期间使用learning rate为当前值的0.1倍,就是0.0001。随着iteration增加,降低学习率可以是模型更有效的学习,也就是更好的降低train loss。
最后一层卷积层中filters数值是 5×(类别数 + 5)。
region里需要把classes改成你的类别数。
最后一行的random,是一个开关。如果设置为1的话,就是在训练的时候每一batch图片会随便改成320-640(32整倍数)大小的图片。目的和上面的色度,曝光度等一样。如果设置为0的话,所有图片就只修改成默认的大小 416*416。
2. 训练log中各参数的意义
Region Avg IOU:平均的IOU,代表预测的bounding box和ground truth的交集与并集之比,期望该值趋近于1。
Class:是标注物体的概率,期望该值趋近于1.
Obj:期望该值趋近于1.
No Obj:期望该值越来越小但不为零.
Avg Recall:期望该值趋近1
avg:平均损失,期望该值趋近于0
rate:当前学习率
-------------------------------------------------------------------------------------------------
如果上面的资料对你有启发,麻烦点个推荐,让更多人的人看到哦。
关注公众号【两猿社】,懂点互联网,懂点IC的程序猿,带你丰富项目经验哦


 浙公网安备 33010602011771号
浙公网安备 33010602011771号