StarRocks-常用函数
StarRocks-SQL TRIM函数 介绍
SQL TRIM函数是一种用于删除字符串前后空格或指定字符的函数。它可以用于去除字符串中不必要的空格或其他字符,以方便处理和比较字符串数据。
TRIM函数的语法如下:
TRIM([BOTH | LEADING | TRAILING] [trim_character FROM] input_string)
其中,input_string是要操作的字符串,trim_character是要删除的字符,BOTH、LEADING和TRAILING是指定删除位置的关键字。如果省略BOTH、LEADING和TRAILING,则默认删除字符串两端的空格。
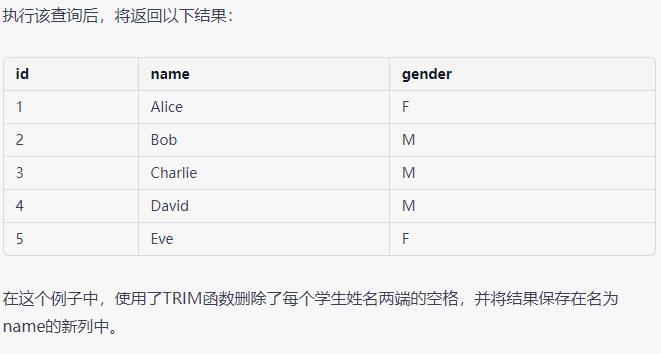
![alt text]()
要去除学生姓名中的空格,可以使用以下SQL查询:
SELECT id, TRIM(name) AS name, gender
FROM students;
![alt text]()
StarRocks-SQL row_number() 介绍
SQL中的ROW_NUMBER()是一个窗口函数(window function),用于给查询结果集中的每一行分配一个唯一的数字。该函数返回每一行的排名,排名从1开始,依次递增,不允许重复。
ROW_NUMBER()的语法如下:
ROW_NUMBER() OVER (
[PARTITION BY partition_expression, ... ]
ORDER BY sort_expression [ASC | DESC], ...
)
其中,PARTITION BY子句可选,用于将结果集分成若干个分区。每个分区都会独立计算ROW_NUMBER(),并从1开始递增。
StarRocks-SQL 中 ROW_NUMBER() 函数介绍
在 SQL 中,ROW_NUMBER() 函数是一个用于生成一个有序数字序列的窗口函数。它可以用于对查询结果进行编号,可以按照特定的排序方式指定顺序,并按照该顺序为每一行生成一个唯一的数字。
该函数通常与 ORDER BY 子句一起使用,以指定排序规则。一般情况下,ROW_NUMBER() 函数将按照指定的排序规则为每一行生成一个唯一的数字。
例如,以下 SQL 语句将为名为 "customers" 的表中的每一行生成一个唯一的数字:
SELECT ROW_NUMBER() OVER (ORDER BY customer_id) AS row_num, customer_name
FROM customers;
在上面的例子中,ROW_NUMBER() 函数将按照 "customer_id" 列中的值对查询结果进行排序,并为每一行生成一个唯一的数字。此外,AS 关键字用于为该列指定一个别名 "row_num",以便在查询结果中引用该列。
请注意,ROW_NUMBER() 函数是一个窗口函数,因此它不能在 GROUP BY 子句中使用。
StarRocks-over 开窗配合聚合函数用法
max(class_a_ser_type) over (PARTITION by receipt_id,class_id),
StarRocks-SQL OVER函数 介绍
SQL OVER函数是一种用于执行聚合函数(如SUM、AVG、MAX、MIN等)的窗口函数。它允许在执行聚合函数时,同时对每个行组执行计算,并返回结果集中包含所有原始行及其对应的计算结果。
OVER函数的语法如下:
SELECT column1, column2, ..., aggregate_function(column_name) OVER (
[PARTITION BY partition_expression, ... ]
[ORDER BY sort_expression [ASC|DESC], ... ]
[ROWS frame_specification]
) AS column_alias
FROM table_name;
其中,aggregate_function可以是SUM、AVG、MAX、MIN等聚合函数,column_name是要对其执行聚合函数的列。OVER函数中的partition_expression和sort_expression用于指定要对哪些行执行聚合函数,并按照哪些列排序。frame_specification指定了计算窗口的范围。
partition_expression可以用于将行分组,并在每个分组内执行聚合函数。sort_expression用于按照指定的列对行进行排序,以便正确计算每个行的位置。frame_specification用于定义计算窗口的范围,可以是UNBOUNDED PRECEDING、CURRENT ROW、UNBOUNDED FOLLOWING等。
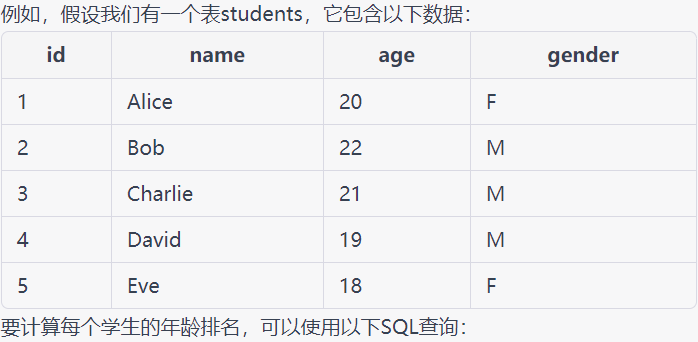
例如,假设我们有一个表students,它包含以下数据:
![alt text]()
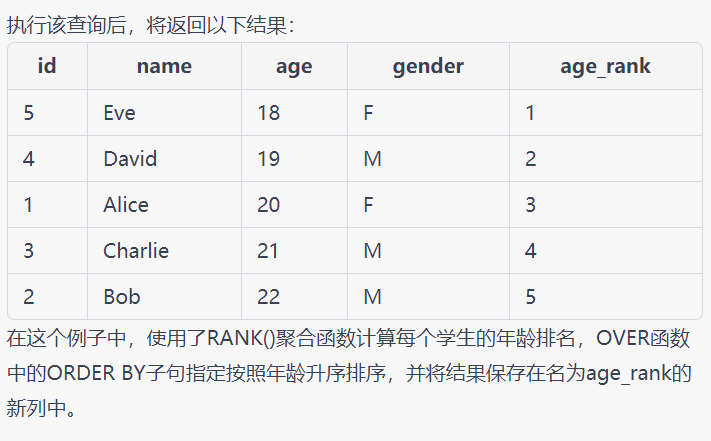
SELECT id, name, age, gender,
RANK() OVER (ORDER BY age) AS age_rank
FROM students;
![alt text]()
row_number() over (partition by userId order by custCommtime desc) as rnk
ROW_NUMBER () over(PARTITION by a.custMobile_decode order by b.orderCreateddate desc) as rnk
StarRocks-SQL union 介绍
SQL UNION是一种用于合并两个或多个SELECT语句结果集的操作符。它可以将两个或多个SELECT语句的结果合并成一个结果集,该结果集包含所有SELECT语句返回的行,且不会有重复行。
UNION操作符的语法如下:
SELECT column1, column2, ...
FROM table1
UNION
SELECT column1, column2, ...
FROM table2;
UNION操作符的使用要求两个SELECT语句具有相同数量和类型的列,列的顺序也必须相同。如果两个SELECT语句的结果集中包含不同的列,或者列的顺序不同,则会导致错误。
在使用UNION操作符时,可以使用UNION ALL代替UNION。UNION ALL与UNION类似,但它不会去除重复行。这意味着,如果两个SELECT语句返回的结果集有相同的行,则在使用UNION ALL时这些行将出现两次。
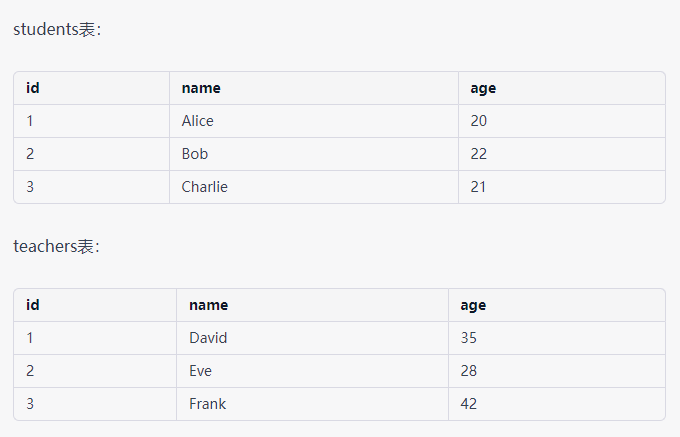
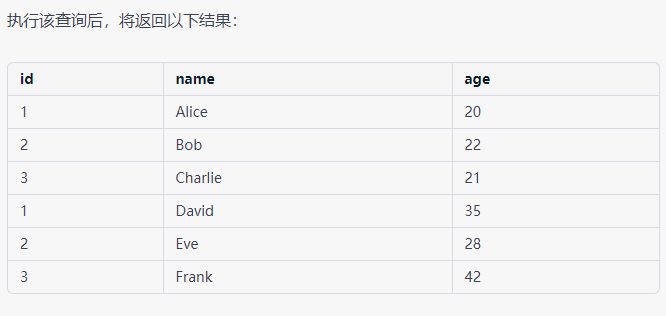
例如,假设我们有两个表students和teachers,它们分别包含以下数据:
students表:
![alt text]()
SELECT id, name, age
FROM students
UNION
SELECT id, name, age
FROM teachers;
![alt text]()
StarRocks-SQL data_add介绍
SQL DATE_ADD() 函数是用于向日期或时间值添加指定的时间间隔的函数。可以使用它来添加年、月、日、时、分、秒等时间间隔。语法如下:
DATE_ADD(date, INTERVAL value unit)
* date: 必需。要添加时间间隔的日期或时间值。
* value: 必需。要添加的时间间隔值。
* unit: 必需。时间间隔的单位。可以是 YEAR、MONTH、DAY、HOUR、MINUTE 或 SECOND 等。
下面是一些使用 DATE_ADD() 函数的示例:
1、添加天数
SELECT DATE_ADD('2022-03-20', INTERVAL 7 DAY) as new_date;
结果为:
+------------+
| new_date |
+------------+
| 2022-03-27 |
+------------+
2、添加小时数
SELECT DATE_ADD('2022-03-20 12:30:00', INTERVAL 5 HOUR) as new_time;
结果为:
+---------------------+
| new_time |
+---------------------+
| 2022-03-20 17:30:00 |
+---------------------+
3、添加年数:
SELECT DATE_ADD('2022-03-20', INTERVAL 2 YEAR) as new_date;
结果为:
+------------+
| new_date |
+------------+
| 2024-03-20 |
+------------+
DATE_ADD() 函数可以与其他日期和时间函数一起使用,例如 DATE_SUB() 函数、DATEDIFF() 函数等。它可以用于各种情况,例如计算到期日期、计算过期时间等。注意,当向日期或时间值添加负值间隔时,可以使用 DATE_SUB() 函数。
StarRocks-sql 中 if介绍
在 SQL 中,IF 函数是一个条件表达式,用于根据给定的条件返回不同的结果。它的语法通常如下所示:
IF(condition, value_if_true, value_if_false)
其中:
* condition:需要进行测试的条件表达式。
* value_if_true:如果条件表达式为真,则返回的值。
* value_if_false:如果条件表达式为假,则返回的值。
以下是一个使用 IF 函数的示例:
SELECT IF(1=1, 'TRUE', 'FALSE');
这将测试条件 1=1 是否为真。由于该条件为真,因此将返回 'TRUE'。
IF 函数常用于根据条件返回不同的结果,例如在查询中根据某个字段的值返回不同的文本或值。
需要注意的是,在不同的 DBMS 中,IF 函数的语法和行为可能会有所不同。在某些 DBMS 中,可能需要使用其他条件表达式,例如 CASE 表达式来实现类似的功能。因此,在使用 IF 函数时,需要参考特定 DBMS 的文档以确保其正确使用。
StarRocks-sql case when then 介绍
SQL CASE WHEN THEN语句是一种条件语句,它在数据库中用于根据一个或多个条件执行不同的操作或返回不同的结果。 它类似于编程语言中的if-else语句。
下面是一个简单的例子,说明如何使用CASE WHEN THEN语句:
SELECT product_name,
CASE
WHEN product_price < 10 THEN 'Cheap'
WHEN product_price >= 10 AND product_price <= 50 THEN 'Reasonable'
WHEN product_price > 50 THEN 'Expensive'
END AS 'Price Category'
FROM products;
在上面的例子中,根据产品价格将产品分为三个不同的价格类别,并将价格类别作为新列返回。CASE WHEN THEN语句的语法如下:
CASE
WHEN condition1 THEN result1
WHEN condition2 THEN result2
...
ELSE resultN
END
* CASE:开始CASE语句
* WHEN:在CASE语句中定义条件
* THEN:在条件为真时返回的结果
* ELSE:可选,如果没有条件满足,则返回默认结果
* END:结束CASE语句
在上面的例子中,如果价格低于10,则返回'Cheap',如果价格在10到50之间,则返回'Reasonable',如果价格高于50,则返回'Expensive'。如果没有条件满足,则返回NULL或默认值(如果使用了ELSE)。
CASE WHEN THEN语句非常灵活,并且可以嵌套在其他CASE WHEN THEN语句中以进行更复杂的逻辑操作。它是在SQL查询中非常有用的工具,可用于创建可读性强的、易于理解的查询。
StarRocks-sql 中 count(1) 介绍
在 SQL 中,COUNT() 函数用于返回指定表中行的数量。它接受一个参数,可以是表中的某个列或任意的表达式,返回该列或表达式不为空的行数。COUNT(1) 是一种常见的使用方式,它用于返回表中的所有行数,而不考虑具体的列名或表达式。
以下是一个使用 COUNT(1) 函数的示例:
SELECT COUNT(1) FROM customers;
这将返回 customers 表中的行数。
在某些 DBMS 中,COUNT(*) 也可以用于返回表中的所有行数,但在其他 DBMS 中,COUNT(*) 和 COUNT(1) 的性能可能会有所不同。通常情况下,使用 COUNT(1) 要比使用 COUNT(*) 更高效,因为 COUNT(*) 必须检查所有列的值,而 COUNT(1) 只需检查一列的值。
需要注意的是,在使用 COUNT() 函数时,需要注意空值的处理。在某些 DBMS 中,COUNT() 函数可能不包括空值行。如果需要包括空值行,请使用 COUNT(*) 函数。
StarRocks-sql <> 介绍
在 SQL 中,<> 是一个比较运算符,用于检查两个表达式是否不相等。它的语法通常如下所示:
expression1 <> expression2
其中:
* expression1 和 expression2:需要比较的表达式。
以下是一个使用 <> 运算符的示例:
SELECT * FROM customers WHERE country <> 'USA';
这将从 customers 表中选择所有 country 不等于 'USA' 的记录。
需要注意的是,<> 运算符在某些 DBMS 中可能被替换为 != 运算符,用于表示相同的意思。在其他 DBMS 中,可能需要使用不同的运算符或函数来执行相同的操作。因此,在使用 <> 运算符时,需要参考特定 DBMS 的文档以确保其正确使用。
StarRocks-sql length() 介绍
在 SQL 中,LENGTH() 函数用于返回字符串的长度。它接受一个字符串作为参数,并返回该字符串的字符数,包括空格和特殊字符。
以下是一个使用 LENGTH() 函数的示例:
SELECT LENGTH('Hello World');
这将返回字符串 'Hello World' 的长度,即 11。
LENGTH() 函数常用于检查字符串是否达到一定长度或截取字符串的一部分。例如,可以使用 LENGTH() 函数来检查字符串是否超过数据库表格的字段长度限制,或在执行 SUBSTRING() 函数时确定要截取的字符串长度。
需要注意的是,在不同的 DBMS 中,LENGTH() 函数可能会以不同的方式工作或使用不同的名称(例如,在某些 DBMS 中,该函数可能称为 LEN())。因此,在使用 LENGTH() 函数时,需要参考特定 DBMS 的文档以确保其正确使用。
StarRocks-sql cast() 介绍
在 SQL 中,CAST() 函数用于将一个数据类型的值转换为另一个数据类型。它通常用于更改数据类型,例如将字符串转换为数字、将日期转换为字符串等等。
CAST() 函数通常由以下部分组成:
1. CAST:用于指示开始执行转换。
2. expression:需要进行转换的表达式。
3. AS:用于指示接下来的数据类型是转换后的数据类型。
4. data_type:转换后的数据类型。
以下是一个使用 CAST() 函数的示例:
SELECT CAST('123' AS INT);
这将把字符串 '123' 转换为整数 123。如果字符串不能转换为整数,则会出现错误。
除了 INT,还可以使用其他数据类型,例如 VARCHAR、DATE、TIME 等等。以下是一些示例:
SELECT CAST(123 AS VARCHAR);
SELECT CAST('2022-05-01' AS DATE);
SELECT CAST('12:30:00' AS TIME);
需要注意的是,使用 CAST() 函数进行类型转换可能会导致数据丢失或不准确,例如将一个大数值转换为整数时可能会截断小数部分。因此,在使用 CAST() 函数时需要谨慎考虑,并确保转换后的结果是正确的。
StarRocks-sql 的now() 函数
在 SQL 中,NOW() 函数是一个日期/时间函数,它返回当前系统日期和时间。
NOW() 函数的具体返回值的格式依赖于你所使用的 DBMS 和当前日期和时间的格式设置。通常,它返回一个带日期和时间的字符串,如下所示:
YYYY-MM-DD HH:MM:SS
其中 YYYY 是四位年份,MM 是两位月份,DD 是两位日期,HH 是小时(24小时制),MM 是分钟,SS 是秒。
以下是一个使用 NOW() 函数的示例:
SELECT NOW();
这将返回当前系统日期和时间的值,例如:
2023-03-24 10:30:15
NOW() 函数常用于记录时间戳,例如记录操作的时间或创建日期时间戳列。另外,还可以与其他日期和时间函数一起使用,例如 DATE_ADD()、DATE_SUB()、DATEDIFF() 等等。
需要注意的是,NOW() 函数返回的时间戳是基于服务器上的当前系统日期和时间,而不是基于客户端。如果需要基于客户端的时间戳,可以考虑使用其他语言或框架中提供的相应函数,如 JavaScript 中的 Date.now()。
StarRocks-sql 语句中 with as 介绍
WITH 语句(也称为 Common Table Expression 或 CTE)是一种在 SQL 查询中定义临时表格的方法。它类似于子查询,但它更易读、易用和灵活,通常用于简化大型复杂查询的编写。
使用 WITH 语句,可以将一个或多个子查询的结果定义为一个或多个临时表格,并将其作为查询的一部分使用。这样可以避免在查询中重复编写相同的子查询,从而简化 SQL 代码的编写和阅读。
WITH 语句通常由以下部分组成:
1. WITH:用于指示开始定义 CTE。
2. cte_name:CTE 的名称,可在后面的查询中使用。
3. AS:用于指示接下来的语句是 CTE 的定义部分。
4. subquery:CTE 的定义,通常是一个子查询。
5. 主查询:使用定义的 CTE 执行查询。
以下是一个使用 WITH 语句的示例:
WITH sales_totals AS (
SELECT customer_id, SUM(amount) AS total_sales
FROM sales
GROUP BY customer_id
)
SELECT customers.name, sales_totals.total_sales
FROM customers
JOIN sales_totals ON customers.id = sales_totals.customer_id
ORDER BY sales_totals.total_sales DESC;
在上面的例子中,sales_totals 是一个临时表格,其中包含每个客户的总销售额。然后使用这个临时表格连接到 customers 表格来检索客户姓名和总销售额,并按总销售额进行排序。
总之,WITH 语句是 SQL 查询中一个非常有用的功能,它可以帮助开发人员更轻松地编写和阅读复杂查询,并提高查询性能。
StarRocks-SQL中对应的 REGEXP_REPLACE 函数 介绍
REGEXP_REPLACE 是一种用于字符串替换的函数,常用于 SQL 中的正则表达式操作。它允许你使用正则表达式模式来匹配字符串,并将匹配到的部分替换为指定的值。下面是 REGEXP_REPLACE 函数的基本语法:
REGEXP_REPLACE(source_string, pattern, replacement)
其中:
* source_string 是要进行替换操作的源字符串。
* pattern 是正则表达式模式,用于匹配源字符串中的子串。
* replacement 是要替换匹配到的子串的新值。
该函数会在源字符串中查找所有匹配 pattern 的子串,并将其替换为 replacement。如果 pattern 没有匹配到任何子串,源字符串将不会被改变。
以下是一个示例,演示如何使用 REGEXP_REPLACE 函数将字符串中的某个子串替换为新的值:
SELECT REGEXP_REPLACE('Hello, World!', 'o', 'X') AS replaced_string;
输出结果将是 'HellX, WOrld!',其中所有的 'o' 被替换为 'X'。
需要注意的是,不同的数据库系统可能会略有差异,因此在具体的数据库中使用 REGEXP_REPLACE 函数时,可能需要查阅相关的文档以了解更多细节和特定的语法规则。
StarRocks-regexp_replace 函数,对字符串进行正则匹配
###### 说明
对字符串 str 进行正则匹配,将命中 pattern 的部分使用 repl 来进行替换。
###### 语法
regexp_replace(str, pattern, repl)
###### 演示
MySQL > SELECT regexp_replace('a b c', " ", "-");
+-----------------------------------+
| regexp_replace('a b c', ' ', '-') |
+-----------------------------------+
| a-b-c |
+-----------------------------------+
MySQL > SELECT regexp_replace('a b c','(b)','<\\1>');
+----------------------------------------+
| regexp_replace('a b c', '(b)', '<\1>') |
+----------------------------------------+
| a <b> c |
+----------------------------------------+
StarRocks-regexp函数,对字符串进行正则匹配,存在返回1,不存在返回0
BOOLEAN regexp(VARCHAR expr, VARCHAR pattern);
select count(1) from (
select regexp(commContent,'(13|15|18|17)[0-9]{9}') as isNumber ,commContent ,*
from datawarehouse.dwd_ct_CtComm dccc where commDelstatus = 'N' and isPhysicsDel = 2
) t where t.isNumber = 1
StarRocks-DATE_ADD 函数,向日期添加指定的时间间隔
##### 说明
向日期添加指定的时间间隔
##### 语法
DATETIME DATE_ADD(DATETIME|DATE date,INTERVAL expr type)
##### 参数说明
* date:必须是合法的日期表达式。可以是 DATETIME 或 DATE 类型。
* expr:需要添加的时间间隔,支持的数据类型为 INT。
* type:时间间隔的单位,取值可以是 YEAR,MONTH,DAY,HOUR,MINUTE,或 SECOND。
##### 演示
select date_add('2010-11-30 23:59:59', INTERVAL 2 DAY);
+-------------------------------------------------+
| date_add('2010-11-30 23:59:59', INTERVAL 2 DAY) |
+-------------------------------------------------+
| 2010-12-02 23:59:59 |
+-------------------------------------------------+
select date_add('2010-11-30', INTERVAL 2 DAY);
+----------------------------------------+
| date_add('2010-11-30', INTERVAL 2 DAY) |
+----------------------------------------+
| 2010-12-02 00:00:00 |
+----------------------------------------+
1 row in set (0.01 sec)
date_add(now(), interval -30 day)
###
对字符串 str 进行正则匹配,抽取符合 pattern 的第 pos 个匹配部分,需要 pattern 完全匹配 str 中的某部分,才能返回 pattern 部分中需匹配部分,如果没有匹配就返回空字符串。
###
regexp_extract(str, pattern, pos)
###
str: 支持的数据类型为 VARCHAR。
pattern: 支持的数据类型为 VARCHAR。
pos: 支持的数据类型为 INT。
select regexp_extract('https://yl.niceloo.com/tgy/2023/xfy/sogou/ds/yd-rk3/qg-gp/?e_id=S-19091&qz_gdt=gp6c2zigaaadw24ds3rq',
'e_id=(.*)&',1) as isNumber
S-19091
StarRocks-聚合逻辑,替换 group_concate()
array_join(array_sort(array_distinct(array_agg(c_init_project))),',') AS c_init_project,
StarRocks-DATE_SUB 函数,向日期添加指定的时间间隔
select DATE_SUB(NOW() ,INTERVAL 365 day) 向前 推进 365天
select DATE_SUB(NOW() ,INTERVAL 3 month) 向前 推进 3个月
StarRocks-数据导入
### 开发环境 导入数据
curl --location-trusted -u root:****** -H "column_separator:," -T mdm_user_detail.csv -XPUT http://192.168.10.20:8030/api/mdm_prod/mdm_user_detail_test/_stream_load
### 生产环境 导入数据
curl --location-trusted -u root:***** -H "column_separator:," -T 001.csv -XPUT http://172.21.1.87:8030/api/test/data_wh_0812/_stream_load
注:如果导入时间格式 数据不成功,将时间格式中的 "" 替换掉 ,不要 " 号
StarRocks-加解密函数
### 解码函数创建
CREATE FUNCTION UDF_AES_DECODE(string)
RETURNS string
properties (
"symbol" = "com.youlu.udf.AESDecodeUdf",
"type" = "StarrocksJar",
"file" = "http://172.21.1.118:9011/common-starrocks-udf-1.0.0.jar"
);
### 逐字模糊匹配函数创建
CREATE FUNCTION UDF_SPLIT_ENCODE(string)
RETURNS string
properties (
"symbol" = "com.youlu.udf.SplitEncodeUdf",
"type" = "StarrocksJar",
"file" = "http://172.21.1.118:9011/common-starrocks-udf-1.0.0.jar"
);
### 加密函数创建
CREATE FUNCTION UDF_AES_ENCODE(string)
RETURNS string
properties (
"symbol" = "com.youlu.udf.AESEncodeUdf",
"type" = "StarrocksJar",
"file" = "http://172.21.1.118:9011/common-starrocks-udf-1.0.0.jar"
);
StarRocks-执行计划
starrocks
----逻辑执行计划------
explain
explain costs
##### 例举说明
explain
<查询语句>
select TABLE_SCHEMA , TABLE_NAME , TABLE_COMMENT , TABLE_ROWS from information_schema.tables t order by TABLE_ROWS desc
StarRocks-修改对应表中副本数
ALTER TABLE ads_fineReport.ads_clue_achievement_order SET ("replication_num" = "3");
StarRocks-对应删除指定表中字段
alter table test.data_wh_0928_01 drop column col02
StarRocks-对应指定表多字段删除
alter table test.dwd_ct_CtCustproj_wh0418
drop column isAbnormal,
drop column abnormalInfo,
drop column isPhysicsDel,
drop column dcTime
StarRocks-对应为指定表中添加字段
alter table test.data_wh_0928_01 add column col03 VARCHAR(300) NULL COMMENT "测试字段" after col02
StarRocks-对应为指定表中多字段添加
alter table ads_fineReport.ads_clue_achievement_order
add column clue_es_dpt_source_name VARCHAR(300) NULL COMMENT "来源部门名称" after clue_es_status,
add column clue_es_dpt_source_id VARCHAR(300) NULL COMMENT "来源部门标识" after clue_es_status
--
alter table ads_fineReport.ads_employee_intention
add column clue_origin_name_two VARCHAR(300) NULL COMMENT "最新行为来源二级名称" after status ,
add column clue_origin_id_two VARCHAR(100) NULL COMMENT "最新行为来源二级标识" after status ,
add column clue_origin_name_one VARCHAR(300) NULL COMMENT "最新行为来源一级级名称" after status ,
add column clue_origin_id_one VARCHAR(100) NULL COMMENT "最新行为来源一级标识" after status ,
add column clue_sourcetime VARCHAR(100) NULL COMMENT "最新行为时间" after status ,
add column clue_project_name_two VARCHAR(300) NULL COMMENT "最新行为项目二级名称" after status ,
add column clue_project_id_two VARCHAR(100) NULL COMMENT "最新行为项目二级标识" after status ,
add column clue_project_name_one VARCHAR(300) NULL COMMENT "最新行为项目一级名称" after status ,
add column clue_project_id_one VARCHAR(100) NULL COMMENT "最新行为项目一级标识" after status
StarRocks-排除所有表的dctime更新时间
select concat('select \'', a.TABLE_NAME, '\', max(dcTime) from ', a.TABLE_NAME, ' union all')
from information_schema.tables a
join information_schema.`columns` b on a.TABLE_SCHEMA = b.TABLE_SCHEMA and a.TABLE_NAME = b.TABLE_NAME
where a.TABLE_SCHEMA = 'datawarehouse'
and a.TABLE_NAME like 'dwd_%'
and b.COLUMN_NAME = 'dcTime'
group by a.TABLE_NAME
StarRocks-更新指定分区数据
INSERT OVERWRITE insert_wiki_edit PARTITION(p06, p12)
WITH LABEL insert_load_wikipedia_ow_2
SELECT * FROM source_wiki_edit;
StarRocks-表名重命名
alter table dws.dws_McBehaviorInfo_test rename dws_McBehaviorInfo
StarRocks-删除表名,并清除存储空间
drop table 表名 force
StarRocks-查询指定库中的数据量
show data
StarRocks-精度数据转化decimal
cast(class_amount as decimal(20,2))
StarRocks-获取JSON 数据中指定数组信息后进行 数据转行操作
with t as ( ... ...)
select *
from t, unnest(transferOutMoneyArray) AS unnest
StarRocks-获取JSON 数据中指定数据信息,转为数组操作
cast(get_json_string(t3.aiApplyform,'$.classTransferOuts.[*].transferOutMoney') as array<bigint>) as transferOutMoneyArray
StarRocks-获取JSON 数据中指定数据信息
get_json_string(t3.aiApplyform,'$[0].refundTag')
StarRocks-LPAD 字符串自动不全位数函数
LPAD(123, 5, '0')
select LPAD(123, 5, '0')
-- 00123
select CONCAT(left('12345',3) , LPAD(123, 5, '0')) AS padded_string;
StarRocks-尽量不使用函数
substring(receipt_time,1,10) >= '2022-04-01'
substring() 以后尽量不使用 改为 时间直接比较
StarRocks-取对应身份证号中的时间
select custIdcard,custIdcard_decode,SUBSTRING(custIdcard_decode,7,8) as idcarddata ,
to_date(SUBSTRING(custIdcard_decode,7,8))as '身份证时间'
from datawarehouse.dwd_ct_CtCust dccc where custIdcard <> ''
StarRocks-sql 语句实现 创建一个新表拥有指定表的数据表结构
CREATE TABLE new_table LIKE existing_table;
在这个语句中,new_table 是你要创建的新表的名称,existing_table 是你想要拥有其数据表结构的现有表的名称。执行这个语句后,new_table 将会拥有与 existing_table 相同的表结构,包括列名、数据类型和约束等。
请确保将 new_table 替换为你想要创建的新表的实际名称,将 existing_table 替换为你想要拥有其数据表结构的现有表的实际名称。
StarRocks-sql 语句计算一列数据中字符出现的概率百分比
SELECT character_column, COUNT(*) AS total_count, (COUNT(*) * 100.0 / SUM(COUNT(*)) OVER()) AS percentage FROM your_table GROUP BY character_column
请确保将上述查询中的 "character_column" 替换为你要计算概率的列名,"your_table" 替换为你的表名。
该查询会计算每个不同字符的出现次数、总出现次数和百分比。百分比计算使用了窗口函数 SUM(COUNT(*)) OVER() 来获取总出现次数,然后将每个字符的出现次数与总次数相除,并乘以100来获得百分比。
该查询结果将返回每个字符的出现次数、总出现次数和百分比。
StarRocks-sql 语句实现多行字段聚合拼接到一起,并用 | 符号进行分割
在 SQL 中,可以使用 GROUP_CONCAT 函数来实现多行字段的聚合拼接,并用指定的分隔符进行分割。下面是一个示例 SQL 语句:
SELECT group_concat(column_name SEPARATOR '|')
FROM table_name
GROUP BY some_column;
其中,column_name 是要拼接的字段名,table_name 是表名,some_column 是用于分组的列名。在 GROUP_CONCAT 函数中,SEPARATOR 参数指定了分隔符,可以是任何字符或字符串。
例如,如果要将一个名为 students 的表中的所有学生姓名拼接到一起,并用竖线字符进行分割,可以使用以下 SQL 语句:
SELECT GROUP_CONCAT(name SEPARATOR '|')
FROM students;
执行这个语句后,会返回一个包含所有学生姓名的字符串,其中每个姓名之间都用竖线字符进行分割。
StarRocks-SQL 实现手机号4位脱敏操作
要实现手机号4位脱敏操作,可以使用SQL中的SUBSTR和CONCAT函数来截取和拼接字符串。
假设我们有一个表phone_numbers,它包含了用户的手机号码,可以使用以下SQL查询来进行手机号码的脱敏操作:
SELECT CONCAT(SUBSTR(phone_number, 1, 3), '****', SUBSTR(phone_number, 8)) AS masked_phone_number
FROM phone_numbers;
在上面的SQL查询中,我们使用了SUBSTR函数截取了手机号码的前3位和后4位,中间用“****”代替,并使用CONCAT函数将它们拼接成新的脱敏后的手机号码。执行该查询后,将返回一个包含脱敏后手机号码的结果集。
例如,如果原始手机号码是“13812345678”,那么脱敏后的手机号码将变成“138****5678”。
StarRocks-SQL limit 操作介绍
SQL中的LIMIT操作用于限制查询结果的数量,常用于分页查询或者限制TOP N的查询结果。
LIMIT语法如下:
SELECT column1, column2, ...
FROM table_name
LIMIT offset, count;
其中,offset表示要跳过的行数,count表示要返回的行数。假设我们有一个表students,它包含了所有学生的成绩信息,如果要查询前10名成绩最好的学生,可以使用以下SQL查询:
SELECT * FROM students
ORDER BY score DESC
LIMIT 10;
在上面的SQL查询中,我们首先使用ORDER BY对成绩进行降序排序,然后使用LIMIT限制返回结果的数量为10条。
如果要进行分页查询,可以使用LIMIT语句的第二个参数来指定每页返回的行数,使用第一个参数来指定跳过的行数。例如,如果要查询第11-20名成绩最好的学生,可以使用以下SQL查询:
SELECT * FROM students
ORDER BY score DESC
LIMIT 10 OFFSET 10;
在上面的SQL查询中,我们使用LIMIT的第二个参数指定每页返回的行数为10,使用第一个参数指定要跳过的前10条数据。执行该查询后,将返回第11-20名成绩最好的学生的数据。
StarRocks-SQL 查询left join 未匹配上字典表中数据的字段
假设您有两个表:一个主表和一个字典表。主表中有一个字段,您希望找到这个字段的所有值,这些值在字典表中没有匹配到。
以下是一种使用 SQL LEFT JOIN 和 WHERE 子句的方法来实现这个查询:
SELECT main_table.field
FROM main_table
LEFT JOIN dictionary_table
ON main_table.field = dictionary_table.field
WHERE dictionary_table.field IS NULL;
上面的 SQL 查询首先将主表和字典表进行左连接(LEFT JOIN),这意味着它会返回主表中所有记录,无论是否与字典表中的记录匹配。
然后,在 WHERE 子句中,我们检查字典表中的字段是否为空(IS NULL),这表示它在字典表中没有匹配项。如果是这样,我们就只返回主表中的这个字段(main_table.field)。
这样,您就能找到主表中那些在字典表中找不到匹配项的记录。
StarRocks-SQL 语句提取两张表两列数据中,数据不一致的操作
您可以使用 SQL 的 JOIN 操作结合 WHERE 子句来提取两张表中两列数据不一致的行。以下是一种可能的方法:
SELECT table1.column1, table1.column2, table2.column1, table2.column2
FROM table1
JOIN table2 ON table1.join_column = table2.join_column
WHERE table1.column1 <> table2.column1 OR table1.column2 <> table2.column2;
在这个例子中,您需要替换 "table1"、"table2"、"column1"、"column2" 和 "join_column" 为您实际使用的表名和列名。JOIN 操作使用 "join_column" 作为两个表之间的连接点。WHERE 子句检查每一行的两个列是否相同,如果不同,则会将该行包括在结果集中。
StarRocks-sql 语句处理 json 数据
SQL 语句可以通过内置的 JSON 函数和操作符来处理 JSON 数据。以下是一些常用的 SQL 语句处理 JSON 数据的方法:
提取 JSON 字段的值:
使用 -> 或 ->> 操作符来提取 JSON 字段的值,例如:
SELECT data->'name' AS name, data->>'age' AS age FROM users;
这个语句从名为 users 的表中选取 JSON 字段 data 中的 name 和 age 字段的值。
判断 JSON 字段是否包含某个键:
使用 ? 或 ?| 或 ?& 操作符来判断 JSON 字段是否包含某个键,例如:
SELECT * FROM users WHERE data ? 'name';
这个语句从名为 users 的表中选取包含 name 键的 JSON 字段 data。
添加 JSON 字段:
使用 json_build_object 函数来添加 JSON 字段,例如:
UPDATE users SET data = json_build_object('name', 'John', 'age', 30) WHERE id = 1;
这个语句将名为 users 的表中 id 字段为 1 的记录的 data 字段替换为包含 name 和 age 字段的 JSON 对象。
更新 JSON 字段:
使用 -> 或 ->> 操作符和 json_set 函数来更新 JSON 字段,例如:
UPDATE users SET data = json_set(data, '{age}', '31') WHERE id = 1;
这个语句将名为 users 的表中 id 字段为 1 的记录的 data 字段中的 age 字段更新为 31。
删除 JSON 字段:
使用 jsonb_set 函数来删除 JSON 字段,例如:
UPDATE users SET data = jsonb_set(data, '{name}', 'null', true) WHERE id = 1;
这个语句将名为 users 的表中 id 字段为 1 的记录的 data 字段中的 name 字段删除。
以上是一些常用的 SQL 语句处理 JSON 数据的方法,可以根据实际情况选择适合的方法来处理 JSON 数据。
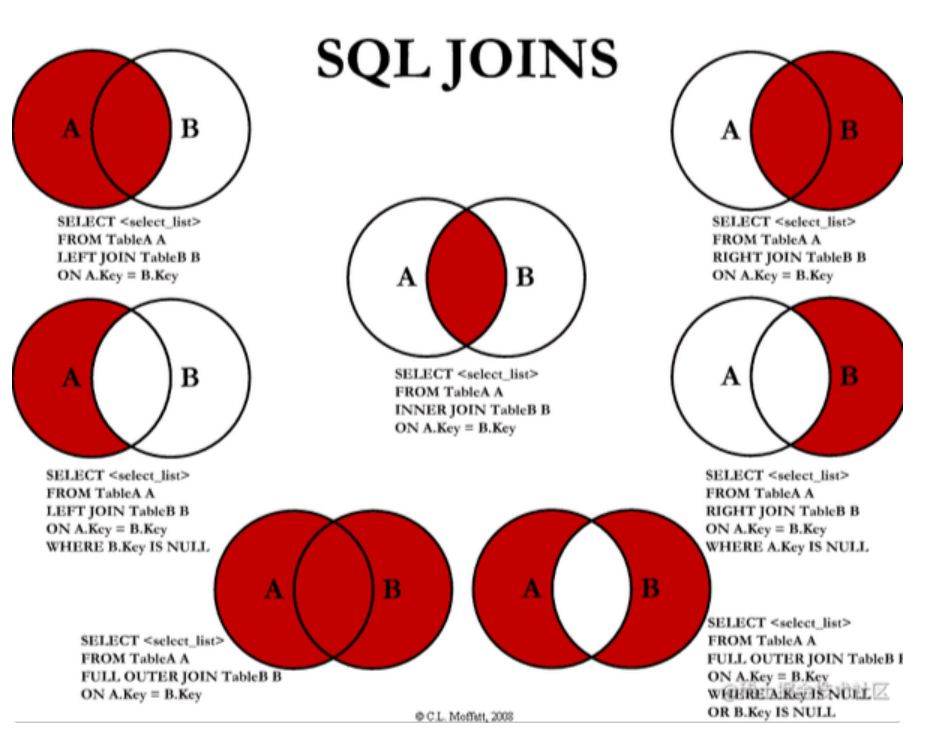
关联查询对比图
![alt text]()




 浙公网安备 33010602011771号
浙公网安备 33010602011771号