
python-基本内置模块(OS、shutil、sys、文件压缩、日志处理、异常处理、正则)
os模块
os,就是operating system的缩写,译作:操作系统。
os模块是Python标准库中的一个用于访问操作系统相关功能的常用模块,它提供了很多使用操作系统功能和访问操作系统信息的方法和属性。
但os模块中的提供的操作并不是在所有的操作系统都通用的,有些操作的实现是基于特定系统平台的,比如linux系统相关的文件权限管理和进程管理。
os模块的主要功能:
- 访问和操作系统相关信息
- 操作目录及文件
- 执行系统命令
- 管理进程
模块导入方式
import os
常用属性
| 属性 | 描述 |
|---|---|
| os.name | 查看当前操作系统的名称。Windows平台下返回‘nt’,Linux或mac OS则返回‘posix’。 |
| os.sep | 当前平台的路径分隔符。在windows系统下,为‘\’,在Linux系统中,为‘/’。 |
| os.linesep | 行结束符。在不同的系统中行尾的结束符是不同的,例如在Windows下为‘\r\n’,Linux系统下为"\n" |
| os.environ | 获取当前操作系统的环境变量 |
点击查看代码
# linux系统下运行代码:
import os
if __name__ == '__main__':
print(os.name) # posix
print(os.sep) # /
print(os.linesep.encode()) # b'\n'
print(os.environ)
print(os.environ.get("USERNAME")) # 也可以使用中括号[]来提取里面的信息 zhangsan
"""
environ({
'PATH': '/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:', # 操作系统系统环境变量中,可执行文件的搜索路径,python的路径以及pip包安装器的路径必须在里面
'USERNAME': 'zhangsan', # 当前系统用户名
'LOGNAME': 'zhangsan', # 当前系统用户名
'PWD': '/home/zhangsan/Desktop/code', # 当前程序的工作目录
'LANGUAGE': 'zh_CN:en_US:en', # 操作系统的语言
'PYTHONPATH': '/home/zhangsan/Desktop/code:/opt/pycharm-2020.3.5/plugins/python/helpers/pycharm_matplotlib_backend:/opt/pycharm-2020.3.5/plugins/python/helpers/pycharm_display', # python可导包文件的搜索路径
'SHELL': '/bin/bash', # 操作系统的shell终端的路径,类似windows的 cmd.exe macOS的 /bin/sh
'LANG': 'zh_CN.UTF-8', # 操作系统的语言
'PYTHONIOENCODING': 'UTF-8', # python操作文件的默认编码
'USER': 'zhangsan', # 当前系统用户名
'PYTHONUNBUFFERED': '1', # python错误输出缓存设置
'HOME': '/home/zhangsan' # 当前系统用户的家目录
})
"""
print(os.linesep.encode()) # b'\r\n'
# windows系统下运行代码:
import os
if __name__ == '__main__':
print(os.name) # nt
print(os.sep) # \
print(os.linesep.encode()) # b'\r\n'
print(os.environ)
print(os.environ.get("USERNAME")) # 获取当前系统用户的用户名 465
"""
environ({
'COMPUTERNAME': 'WIN-Q0O96WREJ2', # 计算机设备名称
'COMSPEC': 'C:\\WINDOWS\\system32\\cmd.exe', # cmd终端的路径
'HOMEDRIVE': 'C:', # 当前系统用户家目录所在的驱动器盘符
'HOMEPATH': '\\Users\\Administrator', # 当前系统用户的家目录
'LOGONSERVER': '\\\\WIN-Q0O96WREJ2', # 主机名
'NUMBER_OF_PROCESSORS': '12', # 当前系统CPU的逻辑处理器数量
'OS': 'Windows_NT', # 操作系统类型
'PATH': 'C:\\tool\\Python38;C:\\WINDOWS\\system32;C:\\WINDOWS;...', # 操作系统系统环境变量中,可执行文件的搜索路径,python的路径以及pip包安装器的路径必须在里面
'PYTHONIOENCODING': 'UTF-8', # python操作文件的默认编码
'PYTHONPATH': 'C:\\Users\\Administrator\\PycharmProjects\\pythonProject;', # python可导包文件的搜索路径
'PYTHONUNBUFFERED': '1', # python错误输出缓存设置
'SYSTEMROOT': 'C:\\WINDOWS', # 系统主目录
'TEMP': 'C:\\Users\\ADMINI~1\\AppData\\Local\\Temp', # 临时文件夹
'TMP': 'C:\\Users\\ADMINI~1\\AppData\\Local\\Temp', # 临时文件夹
'USERNAME': 'Administrator', # 当前系统用户名
'WINDIR': 'C:\\WINDOWS', # 操作系统目录的位置
})
"""
print(os.linesep.encode()) # b'\r\n'
环境变量
所谓的环境变量(Environment Variables),就是存储在计算机系统中的软件相关的路径信息或软件配置参数。在计算机执行指令(系统软件,应用软件,系统命令)时,为执行的指令提供的一个环境信息(变量信息,变量参数)。如果在系统执行指令时如果没有对应的环境变量,则可能会导致系统找不到当前指令的存储位置或出现操作失败等问题。
python中的os模块的environ属性,提供了在python运行程序期间临时改变环境变量的操作。
注意:是临时改变,当程序执行完了以后会再次恢复。如果要永久修改,则可以直接到系统窗口或者系统文件中进行永久修改。
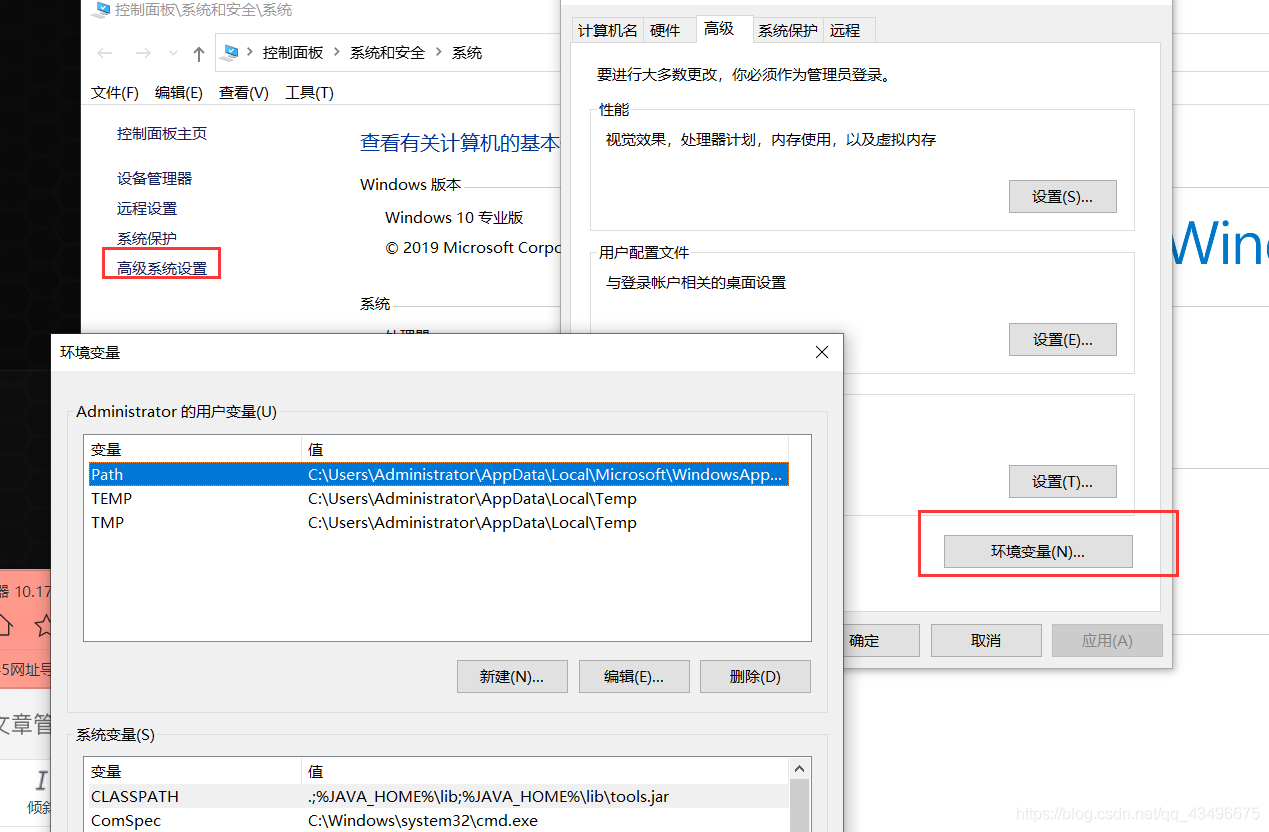
windows系统
直接上鼠标右键->此电脑->高级系统设置-> 环境变量->可以往用户变量(新建),也可以在系统变量中新建
Linux系统
用户环境变量:~/.bashrc
系统环境变量:/etc/profile
例如:给linux系统永久增加一个用户环境变量.
# 使用vim编辑器打开用户环境变量文件
vim ~/.bashrc
# 在末尾增加内容
export 变量名=变量值
# :wq 保存退出,使用source更新环境变量
source ~/.bashrc
读取环境变量
os.environ 是一个环境变量的字典对象,可以通过 get 方法或者中括号获取键对应的值。一般工作中使用get。
点击查看代码
import os
# 如果有这个键,返回对应的值,如果没有,则返回 none。而使用中括号会报错。
print(os.environ.get("HOME"))
# 也可以设置默认值,当键存在时返回对应的值,不存在时,返回默认值
print(os.environ.get("HOME", "/")) # 环境变量HOME不存在,返回 /
# 也可以使用getenv来读取
print( os.getenv('变量名') )
新增环境变量
import os
# os.environ['变量名'] = '变量值'
os.environ["HOMEPATH"] = "/home/zhangsan"
# 保留,linux下面没有效果
# os.putenv("变量名", "变量值")
# 环境变量的键要按照变量的命名规范,值只能是string类型
os.environ.setdefault("HOMEPATH3", "/home/zhangsan")
print(os.environ)
更新环境变量
针对已经存在的环境变量,直接改值,就可以达到修改环境变量的效果,但是python程序执行结束以后,会重新回复的。
os.environ["HOMEPATH3"] = "/home/xiaozhang"
删除环境变量
# del os.environ['变量名']
# del(os.environ['变量名'])
os.environ.setdefault("HOMEPATH", "/home/xiaozhang")
print(os.environ)
del os.environ['HOMEPATH']
print(os.environ)
判断环境变量是否存在
# '变量名' in os.environ # 存在返回 True,不存在返回 False
# 一般都是先判断是否有该环境变量存在,然后再进行读取、修改或删除
# 注意,不要删除系统默认的环境变量
if os.getenv("HOMEPATH"):
del os.environ['HOMEPATH']
print(os.environ)
文件操作
| 方法 | 描述 |
|---|---|
| os.remove(path) | 删除文件,不能删除目录,文件不存在则报错 |
| os.unlink(path) | 删除文件,不能删除目录,文件不存在则报错 |
| os.rename(src, dst) | 重命名文件,src源文件不存在,或dst新文件名已存在都会报错。 |
| os.stat(file) | 获取文件/目录的属性 |
| os.chmod(path, mode) | 修改文件权限,mode为代表文件权限的八进制整数 |
| os.utime(file) | 修改文件的最后修改事件和最后访问时间 |
| os.access(path, mode) | 判断文件权限是否可访问 |
| os.chown(path, uid, gid) | 更改文件所有者,只支持linux/macos等类unix或unix系统下超级管理员权限进行操作 |
点击查看代码
import os, stat
"""os.remove() 删除一个指定路径的文件"""
os.remove("1.exe")
# 少用
os.unlink("1.exe")
"""os.rename() 文件重命名"""
attr = os.stat("home")
print(attr)
"""
os.stat_result(
st_mode=16893,
st_ino=672683,
st_dev=2053,
st_nlink=2,
st_uid=1000,
st_gid=1000,
st_size=4096,
st_atime=1649944855,
st_mtime=1649944855,
st_ctime=1649944855)
"""
print(attr[0]) # 获取文件描述符,相当于print(attr[stat.ST_MODE]) 16893
print(attr[6]) # 获取文件大小[字节],相当于print(attr[stat.ST_SIZE]) 4096
print(attr[7]) # 文件的最后访问时间,相当于print(attr[stat.ST_ATIME]) 1649944855
print(attr[8]) # 文件的最后修改时间,相当于print(attr[stat.ST_MTIME]) 1649944855
print(attr[9]) # 文件的创建时间,相当于print(attr[stat.ST_CTIME]) 1649944855
print(stat.S_ISDIR(attr[stat.ST_MODE])) # 判断当前是否目录 True
print(stat.S_ISREG(attr[stat.ST_MODE])) # 判断当前是否普通文件 False
"""os.chmod() 修改文件/目录权限"""
os.chmod("2.py", 0o700)
os.chmod("home", 0o644)
# 终端下可以通过ls -l 进行查看执行效果
"""os.utime()修改文件时间戳"""
import time
ts = time.time()
os.utime("2.py", (ts, ts))
data = os.stat("2.py")
print(data[7]) # 获取当前文件的最后访问时间 1649946052
print(data[8]) # 获取当前文件的最后修改时间 1649946052
"""os.chown() 修改文件拥有者"""
# windows下会报错
os.chown("2.py", 100, -1)
"""os.access() 判断当前程序对指定文件的访问权限"""
print(os.access("4.txt", os.R_OK)) # 是否可读,相当于print(os.access("2.py", 4))
print(os.access("4.txt", os.W_OK)) # 是否可写,相当于print(os.access("2.py", 2))
print(os.access("4.txt", os.X_OK)) # 是否可执行,相当于print(os.access("2.py", 1))
目录操作
| 方法 | 描述 |
|---|---|
| os.mkdir() | 新建空目录,目录存在,则报错。 |
| os.listdir(path=".") | 列出指定目录下所有文件组成的列表,不指定path,则默认当前程序所在的工作目录 |
| os.scandir(path=".") | 列出指定目录下所有文件组成的迭代器,不指定path,则默认当前程序所在的工作目录 |
| os.getcwd() | 获取当前程序的工作目录,相当于pwd |
| os.chdir(path) | 改变当前程序的工作目录,相当于cd |
| os.rmdir() | 删除空目录,删除非空目录会报错,如果要删除非空目录,则可以使用shutil.rmtree() |
| os.makedirs() | 创建多级空目录,如果多级目录重叠则报错,部分重叠不会报错。mkdir -p |
| os.removedirs() | 删除多级目录,如果是非空目录则会报错,参考上面os.mkdir的描述。rm -rf |
点击查看代码
import os
"""os.mkdir()新建空目录"""
os.mkdir("home")
# 如果要给目录创建文件,则可以使用之前的open内置函数
for i in range(10):
open(f"home/test_{i}.py", "w")
"""os.listdir() 列出当前程序的工作目录下的所有文件"""
# 列出当前程序的工作目录下所有文件
file_list = os.listdir()
print(file_list) # ['2.py', '21-模块与包', '作业', '4.txt', '.idea', 'venv', 'home']
# 列出指定目录下所有文件
file_list = os.listdir("home")
print(file_list) # ['test_7.py', 'test_8.py', 'test_2.py', 'test_5.py', 'test_9.py', 'test_0.py', 'test_1.py', 'test_6.py', 'test_4.py', 'test_3.py']
"""os.getcwd() 获取当前程序的工作目录"""
print(os.getcwd()) # /home/zhangsan/Desktop/Demo
"""os.chdir()改变当前程序的工作目录"""
os.chdir("home")
# 查看改变后的工作目录
print(os.getcwd()) # /home/moluo/Desktop/Demo/home
# 因为上面已经改变了当前程序的工作目录,因此再次调用listdir得到的就是改变后的工作目录下的文件
file_list = os.listdir()
print(file_list) # ['test_7.py', 'test_8.py', 'test_2.py', 'test_5.py', 'test_9.py', 'test_0.py', 'test_1.py', 'test_6.py', 'test_4.py', 'test_3.py']
"""os.rmdir()删除空目录"""
# 先创建一个空目录进行测试
os.mkdir("demoDir")
import time
time.sleep(5)
# 打开系统目录来观察,在pycharm因为输出缓冲的原因是看不到效果的,
# 5秒后删除该空目录
os.rmdir("demoDir")
# 以下代码会报错,因为home里面有文件,是非空目录
os.rmdir("home") # OSError: [Errno 39] Directory not empty: 'home'
# 删除非空目录
del_dir = "sms"
os.chdir(del_dir)
for i in os.listdir():
os.remove(f"{i}")
os.chdir("..")
os.rmdir(del_dir)
# 当然,上面的代码有问题,如果删除的目录中不仅存在文件,还存在子目录的话,则会出错。
# 但是,如果在没有使用其他的模块提供的操作情况下,上面的思路是没有问题的。
"""os.makedirs()创建多级目录"""
os.makedirs("2021/06/01")
"""os.removedirs()删除多级空目录"""
os.removedirs("2021/06/01")
路径操作
os.path模块是python提供给开发者用于判断识别文件/目录路径操作的。
| 方法 | 描述 |
|---|---|
| os.path.isdir() | 判断name是不是一个目录,name不是目录就返回false |
| os.path.isfile() | 判断name是不是一个文件,不存在返回false |
| os.path.islink() | 判断文件是否连接文件,返回boolean |
| os.path.dirname(filename) | 返回文件路径的目录部分 |
| os.path.basename(filename) | 返回文件路径的文件名部分 |
| os.path.join(dirname,basename) | 将文件路径和文件名凑成完整文件路径 |
| os.path.abspath(name) | 获得绝对路径 |
| os.path.realpath(path) | 返回path的真实路径 |
| os.path.getatime() | 返回最近访问时间 浮点型 |
| os.path.getmtime() | 返回上一次修改时间 浮点型 |
| os.path.getctime() | 返回文件创建时间 浮点型 |
| os.path.getsize() | 返回文件大小 字节单位 |
| os.path.exists() | 判断文件或目录是否存在 |
| os.path.normcase(path) | 转换path的大小写和斜杠 |
| os.path.isabs() | 如果path是绝对路径,返回True |
| os.path.samefile() | 是否相同路径的文件,返回boolean,文件不存在则会报错 |
| os.path.split(filename) | 将文件路径和文件名分割(会将最后一个目录作为文件名而分离) |
| os.path.normpath(path) | 规范path字符串形式 |
| os.path.relpath(path[, start]) | 从start开始计算相对路径 |
| os.path.commonprefix(list) | 返回list(多个路径)中,所有path共有的最长的路径 |
| os.path.expanduser(path) | 把path中包含的~和~user转换成用户目录 |
点击查看代码
import os
"""os.path.isdir() 判断name是不是一个目录,name不是目录就返回false"""
print(os.path.isdir("home")) # True
print(os.path.isdir("2.py")) # False 不是目录,或不存在的文件都会返回False
""" os.path.isfile() 判断name是不是一个文件,不存在返回false"""
print(os.path.isfile("3333.py")) # False 不是文件,或不存在的文件都会返回False
print(os.path.isfile("2.py")) # True
"""os.path.islink() 判断文件是否连接文件,返回boolean"""
print(os.path.islink("2.py")) # False
# 注意:普通文件不是链接文件
# linux 创建链接文件
# 硬链接:ln 源文件名绝对路径 链接文件名绝对路径
# 软链接:ln -s 源文件名绝对路径 链接文件名绝对路径
"""os.path.dirname(filename) 返回文件路径的目录部分"""
# 返回当前文件的文件名部分
dir = os.path.basename(__file__)
print(dir)
"""os.path.join(dirname,basename) 将文件路径和文件名凑成完整文件路径"""
dir = "python/project"
file = "2.py"
ret = os.path.join(dir,file)
print(ret) # python/project/2.py
# 工作种常见用法
dir = os.path.dirname(__file__)
file = "2.py"
ret = os.path.join(dir, file)
print(ret)
"""os.path.abspath(path)返回path的绝对路径,只是拼接路径,不会去检测文件是否存在"""
print(os.path.abspath("2.py")) # /home/zhangsan/Desktop/Demo/2.py
print(os.path.abspath(".")) # /home/zhangsan/Desktop/Demo
print(os.path.abspath("../2.py")) # /home/zhangsan/Desktop/2.py
print(os.path.abspath("../home/2.py")) # /home/zhangsan/Desktop/home/2.py
"""os.path.realpath(path) 返回path的绝对路径,只是拼接路径,不会去检测文件是否存在"""
print(os.path.realpath("2.py")) # /home/zhangsan/Desktop/Demo/2.py
print(os.path.realpath(".")) # /home/zhangsan/Desktop/Demo
print(os.path.realpath("../2.py")) # /home/zhangsan/Desktop/2.py
print(os.path.realpath("../home/2.py")) # /home/zhangsan/Desktop/home/2.py
"""os.path.getatime()返回最近访问时间 浮点型"""
print(os.path.getatime("2.py")) # 1649986279.2595923
"""os.path.getmtime()返回上一次修改时间 浮点型"""
print(os.path.getmtime("2.py")) # 1649986279.2595923
"""os.path.getctime()返回文件创建时间 浮点型"""
print(os.path.getctime("2.py")) # 1649986279.2595923
"""os.path.getsize()返回文件大小 字节单位"""
print(os.path.getsize("2.py")) # 2590
"""os.path.exists() 判断文件或目录是否存在"""
print(os.path.exists("2.py")) # True
print(os.path.exists("228.py")) # False
print(os.path.exists("mydemo")) # False
"""os.path.normcase(path) 转换path的大小写和斜杠"""
print(os.path.normcase("../home/2.py"))
"""os.path.isabs() 如果path是绝对路径,返回True"""
print(os.path.isabs("../home/2.py")) # False
"""os.path.samefile() 是否相同路径的文件,返回boolean,文件不存在则会报错"""
print(os.path.samefile("2.py", "./2.py")) # True
print(os.path.samefile("2.py", "home/2.py"))
"""os.path.split(filename)将文件路径和文件名分割(会将最后一个目录作为文件名分离)"""
print(os.path.split("home/2.py")) # ('home', '2.py')
"""os.path.normpath(path)规范path字符串形式"""
print(os.path.normpath("./home\\2.py")) # home\2.py
"""os.path.relpath(path[, start]) 从start开始计算相对路径"""
print(os.path.relpath("./test_2.py","home")) # ../test_2.py
"""os.path.commonprefix(list) 返回list(多个路径)中,所有path共有的最长的路径"""
path_list = ["home/2022/test_2.py", "home/2022/06/test_01.py"]
print(os.path.commonprefix(path_list)) # home/2022/
"""os.path.expanduser(path) 把path中包含的”~“和”~user“转换成用户目录"""
print(os.path.expanduser("~/Desktop/home/2.py")) # /home/zhangsan/Desktop/home/2.py
系统参数与命令执行
| ** 方法** | 描述 |
|---|---|
| os.popen(command) | 创建一个命令管道对象,通往 cmd/shell终端。返回值是连接到管道的文件对象。 |
| os.system(command) | 执行操作系统命令,无法获取屏幕输出的信息,命令执行成功返回0,命令执行失败返回错误提示 |
| os.cpu_count() | 获取当前系统的逻辑cpu个数 |
点击查看代码
import os
# popen 执行终端命令
command = "ls -la"
ret = os.popen(command)
print(ret) # 返回一个命令管道对象 <os._wrap_close object at 0x7fa8cebd3eb0>
# print(ret.read())
print(ret.readlines()) # 一行一行的读,返回一个列表
# 如果要执行多条命令,务必要写在一块,一并执行
ret = os.popen("mkdir my_demo && cd my_demo && echo 'print(\"hello world\")' > 1.py && /home/zhangsan/anaconda3/bin/python3.8 ./1.py")
print(ret.read()) # hello world
# os.system 一样可以让终端执行命令,但是命令执行的结果不可控,会把结果直接输出到终端。
command = "cat home/1.py"
ret = os.system(command)
print(f"ret={ret}")
"""
print("hello world")
ret=0
"""
"""获取当前操作系统的逻辑CPU数量"""
ret = os.cpu_count()
print(ret) # 4
shutil模块
shutil模块提供了一系列对文件和文件集合的高阶操作。 特别是提供了一些支持文件拷贝和删除、复制、移动的操作。
| 方法 | 描述 |
|---|---|
| copyfileobj(fsrc, fdst[, length=0]) | 复制文件,length的单位是字符,表示一次读多少字符。 |
| copyfile(src,dst) | 复制文件内容,不包含文件状态相关的元信息 |
| copymode(src,dst) | 仅复制文件权限 , 不包括内容,文件不存在则报错 |
| copystat(src,dst) | 复制文件状态相关的元信息,包括权限,组,用户,修改时间等,不包括内容 |
| copy(src,dst) | 复制文件权限和内容 |
| copy2(src,dst) | 复制文件权限和内容,还包括权限,组,用户,时间等 |
| copytree(src,dst) | 复制文件夹里所有内容(递归复制) |
| rmtree(path) | 递归删除文件或者目录 |
| move(src,dst) | 移动文件或者文件夹 |
点击查看代码
import shutil
"""copyfileobj(fsrc, fdst) 完整复制文件"""
fsrc = open("2.py", mode="r", encoding="utf-8")
fdst = open("2.txt", mode="w", encoding="utf-8")
shutil.copyfileobj(fsrc, fdst)
"""copyfile(src,dst) 仅复制文件内容 , 底层调用了 copyfileobj"""
shutil.copyfile("2.txt", "3.txt")
"""copymode(src, dst) 仅复制文件权限"""
shutil.copymode("1.txt", "4.txt")
""" copystat(src,dst) 仅复制文件状态的元信息,包括权限,组,用户,修改时间等,不包括内容 """
shutil.copystat("1.txt", "5.txt")
""" copy(src,dst) 复制文件权限和内容 """
shutil.copy("1.txt", "6.txt")
""" copy2(src,dst) 复制文件权限和内容,还包括权限,组,用户,时间等"""
shutil.copy2("1.txt", "7.txt")
"""copytree(src, dst) 递归文件夹里所有内容"""
shutil.copytree("home", "demo02")
"""rmtree(path) 递归删除当前文件夹及其中所有内容"""
shutil.rmtree("ccc")
"""move(path1, path2) 移动文件或者文件夹"""
# 注意path2参数要在末尾加上斜杠,否则在移动到不存在目录以后就会改名
shutil.move("./home", "./dome2")
sys模块
sys模块主要是针对与Python解释器相关的变量和方法,不是针对主机操作系统的。
模块导入方式:
import sys
| 属性/方法 | 描述 |
|---|---|
| sys.path | 返回python解释器的搜索模块与包路径,默认使用环境变量PYTHONPATH的值 |
| sys.platform | 返回操作系统平台名称,Linux系统是"linux", windows系统是"win32", max OS是"darwin" |
| sys.modules | 返回系统导入的模块字段,key是模块名,value是模块 |
| sys.version | 获取Python解释程序的版本信息 |
| sys.version_info | ‘final‘表示最终,也有‘candidate‘表示候选,表示版本级别,是否有后继的发行 |
| sys.executable | Python解释程序路径 |
| sys.argv | 命令行参数List,第一个元素是程序本身路径 |
| sys.hexversion | 获取Python解释程序的版本值,16进制格式如:0x020403F0 |
| sys.exec_prefix | 返回python解释器安装的目录位置 |
| sys.builtin_module_names | Python解释器导入的内建模块列表 |
| sys.getdefaultencoding() | 返回当前你所用的默认的字符编码 |
| sys.setdefaultencoding(name) | 用来设置当前默认的字符编码,低版本2.7以下才有,python3中已经移除。 |
| sys.exit(n) | 退出程序,其实就是exit()函数 |
点击查看代码
import sys
"""sys.path 返回python解释器的搜索模块与包路径,初始化时使用PYTHONPATH环境变量的值 """
print(sys.path)
# 临时增加一个导包路径,即可在后续操作中让python在新的路径中进行导包操作
# sys.path.insert(0, "路径字符串")
""" sys.platform 返回操作系统平台名称 """
print(sys.platform) # linux, win32, darwin
""" sys.modules 返回系统导入的模块字段,key是模块名,value是模块 """
print(sys.modules)
# 返回所有python解释器已经导入的模块列表
print(sys.modules.keys())
""" sys.version 获取Python解释程序的版本信息 """
print(sys.version)
# 3.8.10 (default, Mar 15 2022, 12:22:08)
# [GCC 9.4.0] # 表示我们使用的是Cpython
""" sys.api_version 解释器的C的API版本 """
print(sys.api_version)
""" sys.version_info ‘final‘表示最终,也有‘candidate‘表示候选,表示版本级别,是否有后继的发行 """
print(sys.version_info) # sys.version_info(major=3, minor=8, micro=10, releaselevel='final', serial=0)
""" sys.executable Python解释程序路径 """
print(sys.executable) # /usr/bin/python3.8
"""
sys.argv 打印调用python程序时,在终端下跟在python解释器命令后面所有的参数信息,
第一个元素是程序本身路径
"""
print(sys.argv) # ['/home/zhangsan/Desktop/Demo/模块与包.py']
"""
cat 1.py
--------------
import sys
print(sys.argv)
--------------
(base) test@ubuntu:~/Desktop/Demo$ python3 1.py test01 test02 test03
['1.py', 'test01', 'test02', 'test03']
"""
""" sys.hexversion 获取Python解释程序的版本值,16进制格式如:0x020403F0 """
print(sys.hexversion) # 50858736
""" sys.exec_prefix 返回python解释器安装的目录位置 """
print(sys.exec_prefix) # /usr
""" sys.builtin_module_names Python解释器导入的内建模块列表 """
print(sys.builtin_module_names)
"""
('_abc', '_ast', '_bisect', '_blake2', '_codecs', '_collections', '_csv', '_datetime', '_elementtree',
'_functools', '_heapq', '_imp', '_io', '_locale', '_md5', '_operator', '_pickle', '_posixsubprocess',
'_random', '_sha1', '_sha256', '_sha3', '_sha512', '_signal', '_socket', '_sre', '_stat', '_statistics',
'_string', '_struct', '_symtable', '_thread', '_tracemalloc', '_warnings', '_weakref', 'array', 'atexit',
'binascii', 'builtins', 'cmath', 'errno', 'faulthandler', 'fcntl', 'gc', 'grp', 'itertools', 'marshal',
'math', 'posix', 'pwd', 'pyexpat', 'select', 'spwd', 'sys', 'syslog', 'time', 'unicodedata', 'xxsubtype', 'zlib')
"""
""" sys.getdefaultencoding() 返回当前你所用的默认的字符编码格式 """
print(sys.getdefaultencoding()) # utf-8
""" sys.exit(n) 退出程序,正常退出时exit() """
sys.exit()
print("hello world") # 因为上面代码已经退出了,所以此处不会执行
标准输入、标准输出、标准错误输出
要弄清什么是标准> 输入/标准输出/标准错误输出,首先需要弄懂什么是IO。
I就是Input,译作输入,表示从外部设备输入到内存。O就是output,译作输出,表示从内存输出到外部设备。
而标准输入和标准输出就是用于IO操作的。在linux操作系统中,一切文件/目录/设备都是文件。因此所谓的标准输入、标准输出以及标准错误输出,其实就是linux系统下的3个默认文件,/dev/stdin、/dev/stdout、/dev/stderr。这3个文件并非普通文件,而是默认设备的链接文件。因此, 对/dev/stdin、/dev/stdout、/dev/stderr的读写操作,本质上对系统默认输入和输出设备进行读写,系统默认的输入和输出设备默认一般是终端。当然,/dev/stdin、/dev/stdout、/dev/stderr仅仅是链接文件,并非真正的设备,他们之间的关系仅仅是关联。
| 属性/方法 | 描述 |
|---|---|
| sys.stdout | 标准输出文件对象 |
| sys.stdout.write("内容") | 标准输出内容 |
| sys.stdout.writelines() | 无换行输出 |
| sys.stdin | 标准输入文件对象 |
| sys.stdin.read() | 输入一行 |
| sys.stdin.readline() | 从标准输入读一行,sys.stdout.write(“a”) 屏幕输出a |
| sys.stderr | 标准错误输出文件对象 |
| sys.stderr.write("内容") | 无换行输出错误 |
点击查看代码
import sys
""" sys.stdout 标准输出 """
print(sys.stdout) # <_io.TextIOWrapper name='<stdout>' mode='w' encoding='utf-8'>
""" sys.stdout.write() 标准输出内容 """
sys.stdout.write("hello world") # hello world
sys.stdout.write("hello world\n") # hello world 会换行
sys.stdout.write("hello world\n") # hello world 会换行
print("hello world") # 调用print的过程中,实际上是引用了sys.stdout.write(obj+’/n’)
""" sys.stdout.writelines() 无换行输出 """
sys.stdout.writelines(["hello", " world\n"]) # hello world
""" sys.stdin 标准输入 """
print(sys.stdin) # <_io.TextIOWrapper name='<stdin>' mode='r' encoding='utf-8'>
""" sys.stdin.read() 输入一行 """
print("请输入你的姓名:", end="")
ret = sys.stdin.read() # 输入完成以后,回车,并使用ctrl+d结束输入
print(f"您刚才输入的是:{ret}")
""" sys.stdin.readline() 从标准输入读一行"""
print("请输入您的姓名:", end="")
ret = sys.stdin.readline() # 输入完成以后,回车,表示结束输入
print(f"您刚才输入的是:{ret}")
ret = input("请输入您的姓名:") # 内部本质上执行了sys.stdin.readline().strip('/n')
print(f"您刚才输入的是:{ret}")
""" sys.stdin.readlines() 从标准输入读多行"""
print("请输入您的留言:", end="")
ret = sys.stdin.readlines() # 输入完成以后,并使用ctrl+d结束输入
print(f"您刚才输入的是{ret}")
# 请输入您的留言:afdaffdsf
# dfafdafas
# dafafafda
# afaff
# ^D
# 您刚才输入的是['afdaffdsf\n', 'dfafdafas\n', 'dafafafda\n', 'afaff\n']
""" sys.stderr 错误输出 """
print(sys.stderr) # <_io.TextIOWrapper name='<stderr>' mode='w' encoding='utf-8'>
sys.stderr.write("对不起!!!!报错了!!!") # 对不起!!!!报错了!!!
了解:终端输出带颜色内容
"""了解:终端输出带颜色内容"""
格式语法:\033[显示方式;字体颜色;背景颜色m
显示方式 意义
-------------------------
0 终端默认设置
1 高亮显示
4 使用下划线
7 反白显示
字体颜色 背景颜色 效果
---------------------------------------
30 40 黑色
31 41 红色
32 42 绿色
33 43 黃色
34 44 蓝色
35 45 紫红色
36 46 青蓝色
37 47 白色
例子:
print('\033[1;31;40m')
print('*' * 50)
print('*HOST:\t', 2002)
print('*URI:\t', 'http://127.0.0.1')
print('*ARGS:\t', 111)
print('*TIME:\t', '22:28')
print('*' * 50)
文件压缩模块
python中内置了一系列用于对文件进行打包和解压缩的标准库模块,常见的有tar模块、zip模块。
zipfile模块
基本使用
import zipfile
# 创建一个ZipFile对象, 表示一个zip文件
# ZipFile(路径包名,模式,压缩or打包,可选allowZip64)
zf = zipfile.ZipFile(file[, mode[, compression[, allowZip64]]])
# 参数:
# 1. file表示文件的路径或类文件对象(file-like object)
# 2. mode表示设置打开zip文件的访问权限模式,默认值为r
# r 表示读取已经存在的zip文件
# w 表示新建一个zip文档或覆盖一个已经存在的zip文档
# a 表示将数据追加到一个现存的zip文档中。
# 3. compression表示在写zip文档时使用的压缩方法
# zipfile.ZIP_STORED 只是存储模式,不会对文件进行压缩,这个是默认值
# zipfile.ZIP_DEFLATED 对文件进行zip算法压缩
# 4. allowZip64,如果要操作的zip文件大小超过2G,则必须设置allowZip64=True,否则报错。
压缩文件
点击查看代码
import zipfile
# 1.zipfile.ZipFile() 写模式w打开或者新建压缩文件
zf = zipfile.ZipFile("1.zip", "w", zipfile.ZIP_DEFLATED)
# 2. zf.write(路径,别名) 向压缩文件中添加文件内容
zf.write("/home/zhangsan/Desktop/1.py","1.py")
zf.write("/home/zhangsan/Desktop/2.py","1.py")
# 3. zf.close() 关闭压缩文件
zf.close()
支持with上下文管理器语句
点击查看代码
import zipfile
# 1. zipfile.ZipFile() 写模式w打开或者新建压缩文件
with zipfile.ZipFile("1.zip", "w", zipfile.ZIP_DEFLATED) as zf:
# 2. zf.write(路径,别名) 向压缩文件中添加文件内容
zf.write("/home/zhangsan/Desktop/1.py", "1.py")
zf.write("/home/zhangsan/Desktop/2.py", "1.py")
解压文件
点击查看代码
import zipfile
# 1. zipfile.ZipFile() 读模式r打开压缩文件
with zipfile.ZipFile("1.zip", "r") as zf:
# 2.zf.extractall(解压路径) 解压所有文件到某个路径下
# zf.extract(包内指定文件,解压路径) 解压指定的某个文件到某个路径下
zf.extractall("/home/zhangsan/Desktop")
zf.extract("1.py", "/home/zhangsan/Desktop")
追压文件
点击查看代码
import zipfile
# 直接使用a模式,像上面压缩文件操作一样,直接通过write操作即可
with zipfile.ZipFile("11.zip", "a", zipfile.ZIP_DEFLATED) as zf:
zf.write("/home/zhangsan/Desktop/3.py", "3.py")
查看包内容
点击查看代码
import zipfile
with zipfile.ZipFile("1.zip", "r") as zf:
data = zf.namelist()
print(data)
tarfile模块
基本使用
import tarfile
# 打开或创建一个tar文件
tf = tarfile.open(name=None, mode='r')
# 参数:
# 1. name表示tar文件的路径
# 2. mode表示设置打开tar文件的访问权限模式,默认值为r
# r 打开和读取透明算法进行压缩的tar文件[可以使用这个打开读取, gzip, bzip2, lzma]
# r: 打开和读取没有进行压缩算法的tar文件
# r:gz 打开和读取使用gzip算法压缩的tar文件
# r:bz2 打开和读取使用bzip2算法压缩的tar文件
# r:xz 打开和读取使用lzma算法压缩的tar文件
# w 新建或覆盖一个已存在的未压缩的tar文件
# w:gz 新建或覆盖一个已存在的使用gzip算法压缩的tar文件
# w:bz2 新建或覆盖一个已存在的使用bzip2算法压缩的tar文件
# w:xz 新建或覆盖一个已存在的使用lzma算法压缩的tar文件
# a 将文件追加到一个现存的未压缩的tar文件中
打包不压缩
打包归档,但是不进行压缩
点击查看代码
import tarfile
# 1. 创建一个tar文件
tf = tarfile.open("data.tar", "w")
# 2. 往tar文件中添加文件
# # tf.add(路径,别名)
tf.add("/home/123/Desktop/1.py", "1.py")
tf.add("/home/123/Desktop/2.py", "2.py")
tf.add("/home/123/Desktop/3.py", "3.py")
# 3.关闭文件
tf.close()
同样,也支持with上下文管理器语句
点击查看代码
import tarfile
# 打开或创建一个tar包
with tarfile.open("data.tar", "w") as tf:
# tf.add(路径,别名)
tf.add("/home/123/Desktop/1.py", "1.py")
tf.add("/home/123/Desktop/2.py", "2.py")
tf.add("/home/123/Desktop/3.py", "3.py")
打包并压缩
点击查看代码
import tarfile
"""bz2, 使用bzip2算法压缩打包"""
with tarfile.open("data.tar.bz2", "w:bz2") as tf:
tf.add("/home/123/Desktop/code/1.py", "1.py")
tf.add("/home/123/Desktop/code/2.py", "2.py")
tf.add("/home/123/Desktop/code/3.py", "3.py")
"""gz, 使用gzip算法压缩打包"""
with tarfile.open("data.tar.gz", "w:gz") as tf:
tf.add("/home/123/Desktop/code/1.py", "1.py")
tf.add("/home/123/Desktop/code/2.py", "2.py")
tf.add("/home/123/Desktop/code/3.py", "3.py")
"""xz, 使用lzma算法压缩打包"""
with tarfile.open("data.tar.xz", "w:xz") as tf:
tf.add("/home/123/Desktop/code/1.py", "1.py")
tf.add("/home/123/Desktop/code/2.py", "2.py")
tf.add("/home/123/Desktop/code/3.py", "3.py")
解压文件
点击查看代码
import tarfile
with tarfile.open("data.tar.xz", "r") as tf:
# 解压所有文件到指定路径
tf.extractall("/home/moluo/Desktop")
# 解压单个文件到指定路径
# tf.extract("3.py", "/home/moluo/Desktop")
查看包内容
点击查看代码
import tarfile
with tarfile.open("1.zip", "r") as tf:
data = tf.getnames()
print(data)
追加打包
注意:这里是追加打包,不是追加压缩!!!tar归档文件无法直接追加压缩!!!
点击查看代码
import tarfile
"""追加打包"""
# 只能对之前使用w模式创建的未压缩的tar包进行追加!!看清楚后缀!!!
with tarfile.open("data.tar", "a") as tf:
tf.add("/home/123/Desktop/code/sysdemo.py", "sysdemo.py")
解决tarfile追加不压缩的问题
点击查看代码
import tarfile, os
"""追加压缩"""
# tarfile不支持直接追加压缩的,所以可以先解压,在打包压缩
# 1.解压文件
path1 = "./backup/data.tar.bz2/" # 临时目录
with tarfile.open("data.tar.bz2", "r") as tf:
tf.extractall(path1)
# 2. 追加合并文件
# os.system("cp -a /home/123/Desktop/4.py " + path1)
shutil.copy("/home/123/Desktop/code/sysdemo.py", path1) # 复制文件
shutil.copytree("/home/moluo/Desktop/code/demo2", f"{path1}/demo2") # 复制目录
# 3.重新打包
list_file = os.listdir(path1)
# print(list_file)
# 4.创建一个新的bz2模式的压缩包
with tarfile.open("data_new.tar.bz2", "w:bz2") as tf:
# 循环遍历文件夹当中的所有内容
for file in list_file:
# 拼接路径
file_path = os.path.join(path1,file)
# tf.add(路径,别名)
tf.add(file_path, file)
# 5.临时删除目录
shutil.rmtree("./backup")
基于生成器来提取tar大文件中指定内容
点击查看代码
import os, tarfile
def tar_files(members):
for tarinfo in members:
if os.path.splitext(tarinfo.name)[1] == ".py": # 过滤条件
yield tarinfo
with tarfile.open("data_new.tar.bz2", "r") as tf:
tf.extractall("./new_data", members=tar_files(tf))
日志处理
python内置了一个用于记录程序运行过程的日志信息的标准库模块-logging。
在软件开发完成并部署到公网服务器以后,我们肯定要让服务器里面的软件能二十四小时甚至长年累月地不停机地运行的。那么,软件在服务器运行过程中是否正常运行还是出现了异常错误,这就需要我们开发人员重点关注了,但是开发人员毕竟会有下班回家的时候,如果在下班过程中也就是夜里,如果用户使用软件出现了异常错误?那么,开发人员第二天要怎么知道前一天晚上软件发生的这个错误呢?这时候,就需要日志了。
日志介绍
所谓日志,就是记录和跟踪程序运行过程中所发生的事件的文件内容。记录程序的运行日志是一种可以追踪软件运行时所发生事件的方法。开发人员可以提前在代码中调用日志功能来记录程序执行过程中是否会发生了某些日志事件,如文件被误删了,数据读取失败了,用户注册账号失败等。这些日志事件可以用一个包含可选变量数据的消息来描述。此外,日志事件也可以按不同的重要性和紧急性来划分严重性级别(level)。
开发中,一个事件的发生就会记录一条对应的日志信息,而一个日志信息通常需要包括事件相关的以下几个内容:
- 事件发生时间-年月日时分秒
- 事件发生位置-所在的文件路径或网址路径
- 事件的严重程度–日志level级别
- 事件内容-日志内容
上面这些都是一条日志记录中可能包含的字段信息,当然还可以包括一些其他信息(如我们后面学习到的进程ID、进程名称、线程ID、线程名称等)。日志格式就是用来定义一条日志记录中包含那些字段的,且日志格式通常都是可以自定义的。
logging模块默认定义了以下几个日志等级,它允许开发人员自定义其他日志级别,但是这是不被推荐的,尤其是在开发供别人使用的第三方模块时,因为这会导致不同模块里面的日志级别的产生混乱。
| 日志等级 (level) |
等级 (从低到高) |
描述 |
|---|---|---|
| loging.DEBUG | 10 | 调试级别,在程序出现异常时,开发人员会使用DEBUG日志来进行问题诊断。 |
| loging.INFO | 20 | 运行级别,记录一些关键信息到日志中让开发人员确认程序是正常运行的。 |
| loging.WARNING | 30 | 警告级别,记录如某些函数被废弃了或服务器磁盘可用空间较低等情况。 |
| loging.ERROR | 40 | 错误级别,记录程序运行时导致程序运行终止的错误信息,如调用了未定义的函数等情况。 |
| loging.CRITICAL | 50 | 致命级别,记录让程序不能启动不能运行的危险错误信息,如语法错误等情况。 |
开发应用程序或部署开发环境时,可以使用DEBUG或INFO级别的日志获取尽可能详细的日志信息来进行开发或部署调试;
应用上线或部署生产环境时,应该使用WARNING或ERROR或CRITICAL级别的日志来降低机器的I/O压力和提高获取错误日志信息的效率。日志级别的指定通常都是在应用程序的配置文件中进行指定的。
注意:
- 日志严重等级是从上到下依次升级的,即:DEBUG < INFO < WARNING(WARN) < ERROR < CRITICAL(FATAL)
- 当程序中指定一个日志级别后,程序会记录所有大于或等于指定级别的日志信息,而不是只记录指定级别的日志信息,同样,logging模块也可以指定日志记录器的日志级别,只有大于或等于该指定日志级别的日志信息才会记录,小于该级别的日志将会被丢弃。
简单日志配置
一般针对单文件的python脚本程序,小项目
点击查看代码
import logging
# LOG_FORMAT = "%(日志时间)s %(日志记录器名称)s %(日志等级名称)s %(程序路径)s:%(行号)d %(日志信息)s "
# %(变量名)数据类型,s表示字符串,d表示整数
LOG_FORMAT = "%(asctime)s %(name)s %(levelname)s %(pathname)s:%(lineno)d %(message)s "
# %(name)s, 是日志器名称,在简单日志配置中,我们没有配置这个名称,默认就是root日志器
# 配置输出时间的格式,注意月份和天数不要搞乱了
DATE_FORMAT = '%Y-%m-%d %H:%M:%S %A' # %A周几
# 通过 logging.basicConfig 进行简单日志配置
# logging.basicConfig(
# level=logging.WARNING, # 会输出到日志信息中的日志级别(大于或等于该级别)
# format=LOG_FORMAT, # 日志格式
# datefmt=DATE_FORMAT, # 时间格式
# )
logging.basicConfig(
level=logging.INFO, # 会输出到日志信息中的日志级别(大于或等于该级别)
format=LOG_FORMAT, # 日志格式
datefmt=DATE_FORMAT, # 时间格式
filename="demo.1.log", # 记录日志到文件
)
# 经过上面配置好的简单日志,接着就可以直接使用日志
logging.debug("调试代码")
logging.info("记录程序是否正常运行")
logging.warning("记录程序运行过程中的警告信息")
logging.error("记录程序运行过程中的异常/错误信息")
logging.fatal("记录程序运行过程中的致命错误信息")
# 2022-04-15 09:04:26 Friday root DEBUG /home/123/Desktop/code/1-日志处理-简单日志配置.py:18 debug等级,调试代码
# 2022-04-15 09:04:26 Friday root INFO /home/123/Desktop/code/1-日志处理-简单日志配置.py:19 info等级,记录程序是否正常运行
# 2022-04-15 09:04:26 Friday root WARNING /home/123/Desktop/code/1-日志处理-简单日志配置.py:20 warning等级,记录程序运行过程中的警告信息
# 2022-04-15 09:04:26 Friday root ERROR /home/123/Desktop/code/1-日志处理-简单日志配置.py:21 error等级,记录程序运行过程中的异常/错误信息
# 2022-04-15 09:04:26 Friday root CRITICAL /home/123/Desktop/code/1-日志处理-简单日志配置.py:22 fatal等级,记录程序运行过程中的致命错误信息
# 日志整理收集,一般可以记录到代码中写成程序,部分开发人员直接终端下处理
# cat demo.1.log | grep ERROR
# cat demo.1.log | grep ERROR | awk '{print $1,$2, $5, $6, $7, $8}' > error.log
basicConfig函数参数
| 参数名称 | 描述 |
|---|---|
| filename | 指定日志输出目标文件的文件名(可以写文件名也可以写文件的完整的绝对路径,写文件名日志放执行文件目录下,写完整路径按照完整路径生成日志文件),指定该设置项后日志信心就不会被输出到控制台了 |
| filemode | 指定日志文件的打开模式,默认为’a'。需要注意的是,该选项要在filename指定时才有效 |
| format | 指定日志格式字符串,即指定日志输出时所包含的字段信息以及它们的顺序。logging模块定义的格式字段下面会列出。 |
| datefmt | 指定日期/时间格式。需要注意的是,该选项要在format中包含时间字段%(asctime)s时才有效 |
| level | 指定日志器的日志级别 |
| stream | 指定日志输出目标stream,如sys.stdout、sys.stderr以及网络stream。需要说明的是,stream和filename不能同时提供,否则会引发 ValueError异常 |
| style | Python 3.2中新添加的配置项。指定format格式字符串的风格,可取值为'%'、'{‘和’$',默认为'%' |
| handlers | Python 3.3中新添加的配置项。该选项如果被指定,它应该是一个创建了多个Handler的可迭代对象,这些handler将会被添加到root logger。需要说明的是:filename、stream和handlers这三个配置项只能有一个存在,不能同时出现2个或3个,否则会引发ValueError异常。 |
format格式字符串参数
https://docs.python.org/zh-cn/3/library/logging.html#logrecord-attributes
| 字段/属性名称 | 使用格式 | 描述 |
|---|---|---|
| asctime | %(asctime)s | 将日志的时间构造成可读的形式,默认情况下是‘2016-02-08 12:00:00,123’精确到毫秒 |
| name | %(name)s | 所使用的日志器名称,默认是’root',因为默认使用的是 rootLogger |
| filename | %(filename)s | 调用日志输出函数的模块的文件名; pathname的文件名部分,包含文件后缀 |
| funcName | %(funcName)s | 由哪个function发出的log, 调用日志输出函数的函数名 |
| levelname | %(levelname)s | 日志的最终等级(被filter修改后的) |
| message | %(message)s | 日志信息, 日志记录的文本内容 |
| lineno | %(lineno)d | 当前日志的行号, 调用日志输出函数的语句所在的代码行 |
| levelno | %(levelno)s | 该日志记录的数字形式的日志级别(10, 20, 30, 40, 50) |
| pathname | %(pathname)s | 完整路径 ,调用日志输出函数的模块的完整路径名,可能没有 |
| process | %(process)s | 当前进程, 进程ID。可能没有 |
| processName | %(processName)s | 进程名称,Python 3.1新增 |
| thread | %(thread)s | 当前线程, 线程ID。可能没有 |
| threadName | %(thread)s | 线程名称 |
| module | %(module)s | 调用日志输出函数的模块名, filename的名称部分,不包含后缀即不包含文件后缀的文件名 |
| created | %(created)f | 当前时间,用UNIX标准的表示时间的浮点数表示; 日志事件发生的时间–时间戳,就是当时调用time.time()函数返回的值 |
| relativeCreated | %(relativeCreated)d | 输出日志信息时的,自Logger创建以 来的毫秒数; 日志事件发生的时间相对于logging模块加载时间的相对毫秒数 |
| msecs | %(msecs)d | 日志事件发生事件的毫秒部分。logging.basicConfig()中用了参数datefmt,将会去掉asctime中产生的毫秒部分,可以用这个加上 |
详细日志配置
日志流处理流程是一个模块级别的函数是logging.getLogger([name])(返回一个logger日志器对象,如果没有指定名字将返回root logger)。
四大组件
在介绍logging模块的日志流处理流程之前,我们先来介绍下logging模块的四大组件:
| 组件名称 | 对应类名 | 功能描述 |
|---|---|---|
| 日志器 | Logger | 提供了应用程序可一直记录日志的对象 |
| 处理器 | Handler | 将logger创建的日志记录发送到合适的目的地进行输出的对象 |
| 过滤器 | Filter | 提供了更细粒度的控制工具来决定输出哪条日志记录,丢弃哪条日志记录 |
| 格式器 | Formatter | 决定日志记录的最终输出的字段格式 |
logging模块就是通过这些组件来完成日志流处理流程的,上面所使用的logging简单日志配置也是通过这些组件来实现的。
这些组件之间的关系描述:
-
日志器(Logger)需要通过处理器(Handler)将日志信息输出到目标位置,如:文件、sys.stdout(标准输出)、网络、邮件等,
不同的处理器(Handler)可以将日志输出到不同的位置。
-
日志器(Logger)可以设置多个处理器(Handler)将一条日志记录同时输出到多个不同的位置。
-
每个处理器(Handler)都可以设置自己的过滤器(Filter)实现日志过滤,从而只保留感兴趣的日志。
-
每个处理器(Handler)都可以设置自己的格式器(Formatter)实现同一条日志以不同的格式输出到不同的地方。
简单点说就是:日志器(Logger)是入口,真正干活儿的是处理器(Handler),处理器(handler)还可以通过过滤器(Filter)和格式器(Formatter)对要输出的日志内容做过滤和格式化等处理操作。
Handler
Handler的作用是基于日志消息的等级将日志信息分发到预先指定的位置(文件、网络、邮件等)。Logger日志器对象可以通过addHandler()方法为自己添加0个或者更多个handler处理器对象。比如,一个应用程序可能想要实现以下几个日志需求:
- 把所有日志都发送到一个日志文件中;
- 把所有级别大于等于error的日志发送到stdout(标准输出,也就是终端);
- 把所有级别为critical的日志发送到一个email邮件地址或短信。这种场景就需要3个不同的handlers,每个handler负责发送一个特定严重级别的日志到一个特定的位置。
Handler.setLevel(lel): # 指定被处理的信息级别,低于lel级别的信息将被忽略
Handler.setFormatter():# 给这个handler选择一个格式器对象进行日志进行格式化输出
Handler.addFilter(filt):# Handler.removeFilter(filt):新增或删除一个filter过滤器对象
需要说明的是,应用程序代码不应该直接实例化和使用Handler实例。因为Handler实际是一个日志处理器的一个抽象对象,它只定义了拥有handlers处理器都应该实现的流程而已,同时提供了一些常用处理器可以让我们直接使用或覆盖的这些流程。下面是一些常用的Handler处理器:
| Handler | 描述 |
|---|---|
| logging.StreamHandler | 将日志消息发送到输出到Stream(标准设备),如std.out, std.err或任何file-like对象。 |
| logging.FileHandler | 将日志消息写入到文件中,默认情况下文件大小会无限增长 |
| logging.handlers.RotatingFileHandler | 将日志消息写入到文件中,并支持日志文件按大小进行切割 |
| logging.hanlders.TimedRotatingFileHandler | 将日志消息写入到文件中,并支持日志文件按时间进行切割 |
| logging.handlers.HTTPHandler | 将日志消息以GET或POST的方式发送给一个HTTP服务器 |
| logging.handlers.SMTPHandler | 将日志消息发送给一个指定的email地址 |
| logging.NullHandler | 该Handler实例会忽略error messages,通常被想使用logging的library开发者使用来避免’No handlers could be found for logger XXX’信息的出现。 |
Formater
Formater格式器对象用于配置日志信息的最终顺序、结构和内容。与logging.Handler不同的是,应用代码可以直接使用Formatter格式器对象。另外,如果你的应用程序需要一些特殊的处理行为,也可以单独实现一个Formatter的对象完成。
Formatter使用参数格式如下:
logging.Formatter(fmt=None, datefmt=None, style='%')
可见,该构造方法接收3个可选参数:
- fmt:指定消息格式化字符串,如果不指定该参数则默认使用message的原始值
- datefmt:指定日期格式字符串,如果不指定该参数则默认使用”%Y-%m-%d %H:%M:%S"
- style:Python 3.2新增的参数,可取值为 ‘%’, ‘{‘和 ‘$',如果不指定该参数则默认使用’%’
Filter
Filter对象可以被Handler处理器和Logger日志器用来做比level更细粒度的、更复杂的过滤功能。Filter是一个过滤器抽象对象,它只允许某个logger层级下的日志事件通过过滤。源代码中Filter的基本格式如下:
class logging.Filter(name='')
def filter(record):
"""日志过滤条件"""
pass
比如,一个filter过滤器对象传递的name自定义参数的值为’A.B’,那么该filter对象将只允许格式如下的日志记录通过:‘A.B’,‘A.B,C’,‘A.B.C.D’,‘A.B.D’,而名称为’A.C', ‘B.A.B’,'B.C'的loggers产生的日志则会被过滤掉。如果没有指定过滤数据,或者要过滤的字段值为空字符串,则允许所有的日志事件通过过滤。
filter方法用于具体控制传递的日志记录是否能通过过滤,如果filter该方法返回值为0表示不能通过过滤,返回值为非0表示可以通过过滤。
补充说明:
- 如果有需要,也可以在filter(record)方法内部改变该record日志记录,比如添加、删除或修改一些信息
- 我们还可以通过filter做一些统计工作,比如可以计算下被一个特殊的logger日志器或handler处理所操作的record日志数量等。
日志流处理流程
1、创建一个日志器对象logger
2、设置日志器logger的通用日志等级level
3、创建合适数量的Handler处理器对象(其中,如果日志输出到文件中,则要有日志的存储路径)
4、设置每个Handler处理器单独的日志等级level
5、创建合适数量的格式器formatter,对日志格式化
6、向Handler处理器中添加格式器对象formatter
7、将上面创建的Handler处理器添加到日志器logger中
8、最终在异常处理过程中,打印输出日志
logger.debug()
logger.info()
logger.warning()
logger.error()
logger.critical()
点击查看代码
import logging
def log(name):
# 创建logger,如果参数name表示日志器对象名,name为空则返回root logger
logger = logging.getLogger(name)
# 务必设置一个初始化日志等级
logger.setLevel(logging.DEBUG)
# 这里进行判断,如果logger.handlers列表为空则添加,否则多次调用log日志函数会重复添加
if not logger.handlers:
# 创建handler
fh = logging.FileHandler("test.log", encoding = "utf-8")
sh = logging.StreamHandler()
# 单独设置logger日志等级
fh.setLevel(logging.INFO)
# 设置输出日志格式
simple_formatter = logging.Formatter(
fmt="{levelname} {asctime} {name} {module}: {lineno} {message}",
datefmt="%Y/%m/%d %H/%M/%S",
style="{"
)
verbose_formatter = logging.Formatter(
fmt="{levelname} {asctime} {name} {pathname}:{lineno} {message}",
datefmt="%Y/%m/%d %H/%M/%S",
style="{"
)
# 为handler指定输出格式
fh.setFormatter(verbose_formatter)
sh.setFormatter(simple_formatter)
# 为logger添加日志处理器
logger.addHandler(fh)
logger.addHandler(sh)
return logger # 直接返回logger
logger = log("moluo1")
logger.debug("查错")
logger.info("提示")
logger.warning("警告")
logger.error("错误")
logger.critical("危险")
# 注意:
# 因为logging模块是基于单例模式线程安全的,所以get_logger()如果名字参数相同则返回的是同一个对象,所以
# 添加handler的时候一定要判断,不要重复添加造成重复打印日志的bug!
日志分割处理
点击查看代码
import logging
from logging.handlers import RotatingFileHandler, TimedRotatingFileHandler
def log(name):
# 创建日志器logger,如果参数name表示日志器对象名,name为空则返回root logger(logging内置的根日志器)
logger = logging.getLogger(name)
# 务必设置日志器的通用日志等级
logger.setLevel(logging.DEBUG)
# 这里进行判断,如果logger.handlers日志器的处理器列表为空则添加,否则多次调用log日志函数会重复添加
if not logger.handlers:
# 创建合适数量的处理器handler
sh = logging.StreamHandler() # 终端处理器
fh = RotatingFileHandler(
filename="demo.4.log", # 主日志文件
maxBytes=300 * 1024 * 1024, # 指定单个日志的大小,单位:字节
backupCount=10, # 指定备份日志数量,总日志数量 = backupCount(备份数量) + 1(主日志)
encoding="utf-8"
)
# 单独设置处理器handler的各自日志等级
# sh.setLevel(logging.DEBUG) # 如果等级于上面的通用等级一样,可以省略不写
fh.setLevel(logging.INFO)
# 设置合适数量的格式器,指定日志格式
simple_formatter = logging.Formatter( # 简单格式
fmt="{asctime} {levelname} {module}:{lineno} {message}",
datefmt="%H:%M:%S",
style="{"
)
verbose_formatter = logging.Formatter( # 详细格式
fmt="{asctime} {levelname} {name} {pathname}:{lineno} {message}",
datefmt="%Y/%m/%d %H:%M:%S",
style="{"
)
# 为处理器handler指定格式器,设置输出的日志格式
sh.setFormatter(simple_formatter)
fh.setFormatter(verbose_formatter)
# 为日志器logger添加的处理器handler
logger.addHandler(fh)
logger.addHandler(sh)
return logger # 直接返回logger
# 调用上面声明的日志处理函数,得到一个日志处理对象
logger = log("xiaozhangOA")
logger.debug("查错")
logger.info("提示")
logger.warning("警告")
logger.error("错误")
logger.critical("危险")
日志配置模式
通过字典、yaml、json格式对日志的配置信息进行统一配置,然后实现日志处理。最终效果与上面一样。
点击查看代码
import logging.config
# 这里的是字典配置模式
LOGGING_CONFIG = {
"version": 1, # 日志处理模块logging的版本号,如果将来官方的logging模块的版本升级,这里的设置就可以让程序继续使用原来的日志处理流程
"formatters": { # 格式器的配置
"verbose": { # verbose是自定义的命名,表示详细格式
'format': '{levelname} {asctime} {pathname}:{lineno} {message}',
'style': '{',
},
"simple": { # simple是自定义的命名,表示简单格式
"format": "{levelname} {module} {message}",
'style': '{',
},
},
"handlers": { # 处理器的配置
"console": { # console是自定义的命名,表示终端处理器
"class": "logging.StreamHandler", # 终端处理器对象
"level": logging.DEBUG, # 处理器的日志等级
"formatter": "simple", # 给处理器指定格式器
},
# "file": { # file是自定义的命名,表示文件处理器
# "class": "logging.FileHandler", # 文件处理器
# "level": logging.INFO, # 处理器的日志等级
# "filename": "./demo.5.log", # 文件处理器必须设置文件路径
# "formatter": "verbose", # 给处理器指定格式器
# },
"file": {
"class": "logging.handlers.RotatingFileHandler", # 文件分割日志处理器
"level": logging.INFO, # 处理器的日志等级
"filename": "demo.5.log", # 主日志文件名
"maxBytes": 1024, # 指定单个日志的大小,单位:字节
"backupCount": 10, # 指定备份日志数量,总日志数量 = backupCount(备份数量) + 1(主日志)
"formatter": "verbose", # 给处理器指定格式器
},
},
"loggers": { # 日志器配置
"xiaomingOA": { # 给日志器命名
"handlers": ["console", "file"], # 给日志器绑定合适数量的处理器,
"level": logging.DEBUG, # 日志器的通用等级
"propagate": False, # 是否屏蔽其他日志器的日志,主要针对第三方模块的日志配置,False表示不屏蔽
}
},
"disable_existing_loggers": True, # 是否禁用掉已经存在的日志器对象,True表示禁用
}
# 通过上面的字典,配置日志流处理流程
logging.config.dictConfig(LOGGING_CONFIG)
# 代码测试
logger = logging.getLogger("xiaozhangOA")
logger.debug("查错")
logger.info("提示")
logger.warning("警告")
logger.error("错误")
logger.critical("危险")
异常处理基础
当Python解释器检测到运行的程序出现错误时,解释器就无法继续执行代码或者继续执行下去会导致未知的结果出现,python解释器就会输出一些错误的提示,这就是所谓的"异常"(Exception)。程序错误一般都会分为两种:语法错误(SyntaxError)和异常错误(ExceptionError)。
语法错误:代码没有按照python语法规则去编写,产生的错误。
异常错误:代码在语法正确的前提下,程序因为用户的使用或者开发者编写的逻辑混乱产生的错误信息。
当然,程序出现了错误时,我们作为开发者都需要去处理的。
python中就提供了容错语句和抛出异常语句给我们去解决这些问题。
# 容错语句
try:
# 尝试执行缩进语句代码块,如果出错,则会代码停止跳到except中捕获错误
pass
except ...:
# 捕获异常语句,当有异常发生时,则会来到except进行判断,是否捕获了当前类型的错误。
# except后面直接跟着:冒号,则表示捕获的是 Exception这个错误,Exception是所有异常错误的顶级类型
pass
else:
# 当try语句块代码执行无误时,就会自动执行else语句块
pass
finally:
# 不过代码是否出错,这里最终都会被执行
pass
# 可以主动抛异常, 异常可以通过自定义的方式实现自己的提示错误(后面学到面向对象时会涉及到)
raise 异常("错误提示")
异常处理,代码:
点击查看代码
import os
file = input("请输入你要打开的文件路径:")
if os.path.isfile(file):
with open(file,"r") as f:
content = f.read()
print(content)
else:
print("文件读取错误,不存在的文件!")
# 判断不过来的,总会有意料之外的异常错误,这时候,我们就需要容错语句了。
file = input("请输入你要打开的文件路径:")
with open(file, "r") as f:
content = f.read()
print(content)
"""try ...except 容错处理 """
file = input("请输入你要打开的文件路径:")
try: # 尝试执行缩进语句块的代码
with open(file,"r") as f:
content = f.read()
print(content)
except FileNotFoundError: # 捕获错误,一个try可以跟着1个或多个except语句
print("文件读取错误!不存在的文件!")
except UnicodeDecodeError:
ext = os.path.basename(file).split(".")[-1]
print(f"文件读取错误!不能读取{ext}格式的文件!")
except: # 注意:一般都要在最后对前面的except没有捕获到的错误,进行最后一步的错误
print("文件读取错误!未知错误!")
"""如果except声明了,但是捕获的异常类型不对,则异常还会继续导致程序错误的"""
file = "data.zip"
try: # 尝试执行缩进语句块的代码
with open(file, "r") as f:
content = f.read()
print(content)
except FileNotFoundError: # 捕获错误,一个try可以跟着1个或多个except语句
print("文件读取错误!不存在的文件!")
"""try....except ... else """
file = "demo.1.log"
file = "data.zip"
try: # 尝试执行缩进语句块的代码
with open(file, "r") as f:
content = f.read()
print(content)
except FileNotFoundError: # 捕获错误,一个try可以跟着1个或多个except语句
print("文件读取错误!不存在的文件!")
except UnicodeDecodeError:
ext = os.path.basename(file).split(".")[-1]
print(f"文件读取错误!不能读取{ext}格式的文件!")
except: # 注意:一般都要在最后对前面的except没有捕获到的错误,进行最后一步的错误
print("文件读取错误!未知错误!")
else:
# 如果代码执行到任意一个except语句块,则不会执行else语句块
print("文件正常读取完毕!")
"""try....except ... else...finally"""
file = "data.zip"
try: # 尝试执行缩进语句块的代码
f = open(file, "r")
content = f.read()
# try语句块中一旦出现异常,则异常代码往下的代码就不会被执行,会自动跳到except里面
print(content)
except FileNotFoundError: # 捕获错误,一个try可以跟着1个或多个except语句
print("文件读取错误!不存在的文件!")
except UnicodeDecodeError:
ext = os.path.basename(file).split(".")[-1]
print(f"文件读取错误!不能读取{ext}格式的文件!")
except: # 注意:一般都要在最后对前面的except没有捕获到的错误,进行最后一步的错误
print("文件读取错误!未知错误!")
else:
# 如果代码执行到任意一个except语句块,则不会执行else语句块
print("文件正常读取完毕!")
finally:
# 针对网络请求,特殊文件读写,就要在程序运行结果以后,不管是否发生了异常,都要关闭
f.close()
print(f.closed)
"""finally一旦使用了,无论如何都会执行的"""
def fn(a,b):
try:
s = a + b
return s # 之前说过,函数中如果遇到return以后,就会结束不会往下继续执行了。但是这个规则遇到finally要让步
except:
print("报错了")
return 0
finally:
print("finall语句")
s = fn(1, 20)
print(s)
抛出异常语句,代码:
点击查看代码
num = input("请输入输入一个手机号码:")
if not num.isdecimal() or len(num) != 11:
raise Exception("输入错误,我们要的是手机号码哦!")
常见的内置异常
| 类名 | 描述 |
|---|---|
| Exception | 未知异常,所有异常的总类型,一般用于主动抛出异常或者自定义异常 |
| IndexError | 索引超出序列的范围,操作列表,元组,类列表对象,类元组对象 |
| KeyError | 字典中查找一个不存在的关键字 |
| NameError | 尝试访问一个不存在的变量 |
| IndentationError | 缩进错误 |
| AttributeError | 尝试访问未知的对象属性 |
| StopIteration | 迭代器没有更多的值 |
| AssertionError | 断言语句(assert)失败,用于单元测试(unit test) |
| EOFError | 用户输入文件末尾标志EOF(Ctrl+d) |
| FloatingPointError | 浮点计算错误 |
| GeneratorExit | generator.close()方法被调用的时候 |
| ImportError | 导入模块失败的时候 |
| KeyboardInterrupt | 用户输入中断键(Ctrl+c) |
| MemoryError | 内存溢出(可通过删除对象释放内存) |
| NotImplementedError | 尚未实现的方法 |
| OSError | 操作系统产生的异常(例如打开一个不存在的文件) |
| OverflowError | 数值运算超出最大限制 |
| ReferenceError | 弱引用(weak reference)试图访问一个已经被垃圾回收机制回收了的对象 |
| RuntimeError | 一般的运行时错误 |
| SyntaxError | Python的语法错误 |
| TabError | Tab和空格混合使用 |
| SystemError | Python编译器系统错误 |
| SystemExit | Python编译器进程被关闭 |
| TypeError | 不同类型间的无效操作 |
| UnboundLocalError | 访问一个未初始化的本地变量(NameError的子类) |
| UnicodeError | Unicode相关的错误(ValueError的子类) |
| UnicodeEncodeError | Unicode编码时的错误(UnicodeError的子类) |
| UnicodeDecodeError | Unicode解码时的错误(UnicodeError的子类) |
| UnicodeTranslateError | Unicode转换时的错误(UnicodeError的子类) |
| ValueError | 传入无效的参数 |
| ZeroDivisionError | 数学中,0不能作为除数,当代码中使用0作为除数,就出现该异常。 |
例如打开一个错误的文件,则会出现IOError,代码:
点击查看代码
try:
print('-----test--1---')
open('123.txt','r')
print('-----test--2---')
except IOError:
print("文件无法打开")
查看异常信息
点击查看代码
try:
1 / 0
except Exception as e:
print(e) # 打印错误的提示内容,一般用于提示给用户,或者记录到日志中
info = sys.exc_info()
print(info)
# (<class 'ZeroDivisionError'>, ZeroDivisionError('division by zero'), <traceback object at 0x7f4e01bef900>)
print(info[-1].tb_lineno) # 异常出现的行号
# 11
print(info[-1].tb_frame.f_code.co_filename) # 异常出现的文件路径
# /home/moluo/Desktop/code/8-异常处理-抛出异常.py
正则表达式
问题:如何用户在注册时输入一个文本字符串,我们怎么判断该文本字符串是不是⼿机号码呢?
要解决这个问题,那么我们就要清楚国内的手机号码排列规则,是必须以1、01、+86开头的11位的数字字符串。而且手机前三位一般是130-199。而如果使用之前学习的字符串操作来识别手机号,那么我们势必需要进行很多的if判断,这时候,就可以使用正则表达式来进行字符的规则操作了。
Regular Expression,译作正则表达式或正规表示法,表示有规则的表达式,意思是说,描述一段文本排列规则的表达式。
正则表达式并不是Python的一部分。而是一套独立于编程语言,用于处理复杂文本信息的强大的高级文本操作工具。正则表达式拥有自己独特的规则语法以及一个独立的正则处理引擎,我们根据正则语法编写好规则(模式)以后,引擎不仅能够根据规则进行模糊文本查找,还可以进行模糊分割,替换等复杂的文本操作,能让开发者随心所欲地处理文本信息。正则引擎一般由编程语言提供操作,像python就提供了re模块或regex模块来调用正则处理引擎。
正则表达式在处理文本的效率上不如系统自带的字符串操作,但功能却比系统自带的要强大许多。
最早的正则表达式来源于Perl语言,后面其他的编程语言在提供正则表达式操作时基本沿用了Perl语言的正则语法,所以我们学习python的正则以后,也可以在java,php,go,javascript,sql等编程语言中使用。
正则对字符串或文本的操作,无非是分割、匹配、查找和替换。
正则语法
正则表达式一般由正则模式和模式修正符两部分组成, 写法如下:
/正则模式/模式修正符
正则模式就是用于描述字符串排列规则的代码,而模式修正符就是给正则模式增强特殊功能的。一般使用双斜杠来表示正则模式的开始和结束,当然如果没有模式修正符的时候,双斜杠也可以省略不写(python中的正则模式和修正符是分开处理的,所以一般python开发人员是不需要双斜杠分界符的)。其中正则模式也会分2部分组成,分别是原子(Atom,也叫原子符)和元字符(Metacharseter)。元字符一般都会写在原子的后面(右边)。
- 原子,组成字符串或文本的基本元素,例如,数字、字母、文本符号、中文等多字节字符等都属于原子。
- 元字符,就是对左边的原子的数量或类型进行补充描述的特殊代码。
a{3} # 这里a就是一个原子,{3}表示左边的a重复出现3次。因此这段正则要处理的文本就是aaa这样的文本
元字符(Metacharacters)
元字符是具有特殊含义的字符。
| 元字符 | 描述 | 示例 |
|---|---|---|
| [] | 匹配一个中括号中出现的任意原子 | "[a-z]" |
| [^原子] | 匹配一个没有在中括号出现的任意原子 | "[^0-9]" |
| \ | 转义字符,可以把原子转换特殊元字符,也可以把特殊元字符转成原子。 | "\d" |
| ^ | 叫开始边界符或开始锚点符,匹配一行的开头位置 | "^hello" |
| $ | 叫结束边界符或结束锚点符,匹配一行的结束位置 | "world$" |
| . | 叫通配符、万能通配符或通配元字符,匹配1个除了换行符\n以外任何原子 | "he..o" |
| * | 叫星号贪婪符,指定左边原子出现0次或多次 | "0*133" |
| ? | 叫非贪婪符,指定左边原子出现0次或1次 | "0?135" |
| + | 叫加号贪婪符,指定左边原子出现1次或多次 | "ab+c" |
| {n,m} | 叫数量范围贪婪符,指定左边原子的数量范围,有{n},{n, }, {,m}, {n,m}四种写法,其中n与m必须是非负整数。 | "hel{2}o" |
| | | 指定原子或正则模式进行二选一或多选一 | "a |
| () | 对原子或正则模式进行捕获提取和分组划分整体操作, | (http |
点击查看代码
import re
"""re.findall(正则模式, 文本) 基于正则模式查找文本内容"""
"""在python中,正则表达式是以字符串格式出现的,然后有正则模块提供的函数把字符串发送给正则引擎处理的"""
"""[] 匹配一个中括号中出现的任意一个原子"""
ret = re.findall("[123]", "abc4d3ab2")
print(ret) # ['3', '2']
ret = re.findall('a[abc]b', 'aab abb acb adb')
print(ret) # ['aab', 'abb', 'acb']
# 左边正则模式的中括号是元字符,右边文本的中括号是普通原子,两个有区别
ret = re.findall('<[ab]>', '<a> <b> <<b <<b>> <[b]>')
print(ret) # ['<a>', '<b>', '<b>']
"""[^] 匹配一个没有在中括号出现的任意原子"""
ret = re.findall('a[^ab]b', 'aab abb acb adbdaacb baacb')
print(ret) # ['acb', 'adb', 'acb', 'acb']
# 因为正则中[]表示任选其一的原子,而[]里面出现^表示对没在中括号里面的原子任选其一
# 那如果查找文本中的[],那么我们需要对中括号本身代表特殊作用要取消掉
"""\ 转义字符,可以把原子转换特殊元字符,也可以把特殊元字符转成原子"""
# 提取文本中的[]
ret = re.findall('\[b\]', '[b]')
print(ret) # ['[b]']
# 提取文本a.com或b.com或者c.com
ret = re.findall('[]abc]\.com', 'a.com b.cn c.com d.net aacom abcom adcccom')
print(ret) # ['a.com', 'c.com']
# 如果没有反斜杠,则结果不对,因为正则语法中 . 表示通配符,代表除了\n换行符以外的任意一个原子
ret = re.findall('[abc].com', 'a.com b.cn c.com d.net aacom abcom adcccom')
print(ret) # 'a.com', 'c.com', 'aacom', 'abcom', 'cccom']
# \ 还可以把原子转换成元字符
ret = re.findall('[0123456789]', 'a1c3d3558')
print(ret) # ['1', '3', '3', '5', '5', '8']
# 在编码中如果字符的顺序是连续的,可以使用-来表示1段连续范围的字符
ret = re.findall('[4-9]', 'a1c3d3558')
print(ret) # ['5', '5', '8']
ret = re.findall('[a-g]', 'a1wgc3d3kh5mw5h 8q')
print(ret) # ['a', 'g', 'c', 'd']
# [a-z] # 任意一个小写字母
# [A-Z] # 任意一个大写字母
# [0-9] # 任意一个数字
# [0-9] 还可以使用\d表示
ret = re.findall('\d', 'a1c3d3558')
print(ret) # ['1', '3', '3', '5', '5', '8']
""" ^ 开始边界符或开始锚点符,匹配一行的开头位置"""
txt = "hello, world, hello, python"
# 找到最开始的hello
ret = re.findall('^hello', txt)
print(ret) # ['hello']
txt = " hello, world"
ret = re.findall('^hello', txt)
print(ret) # []
""" $ 叫结束边界符或结束锚点符,匹配一行的结束位置 """
txt = "hello, world, welcome to my world"
ret = re.findall('world$', txt)
print(ret) # ['world']
""" . 通配符,匹配1个除了换行符\n以外任何原子 """
txt = "13300005678 133bbbb5678 133****5678 133*****5678 133***56786766 133** **5678 133 5678 "
ret = re.findall("133....5678", txt)
文本中任意字符都算原子,当然空格也是
print(ret) # ['13300005678', '133bbbb5678', '133****5678', '133 5678']
""" ? 非贪婪符,匹配0个或者1个原子 """
ret = re.findall('a?b', 'abbzab abb aab')
print(ret) # ['ab', 'b', 'ab', 'ab', 'b', 'ab']
""" + 加号贪婪符,匹配1个或者多个原子 """
ret = re.findall('a+b', 'b ab aaaaaab abb aabbccbbaaaabaab')
print(ret) # ['ab', 'aaaaaab', 'ab', 'aab', 'aaaab', 'aab']
ret = re.findall('a+b+', 'b ab aaaaaab abb aabbccbbaaaabaab')
print(ret) # ['ab', 'aaaaaab', 'abb', 'aabb', 'aaaab', 'aab']
""" * 星号贪婪符, 匹配0个或者多个a """
ret = re.findall('a*b', 'b ab aaaaaab abbbbbbb')
print(ret) # ['b', 'ab', 'aaaaaab', 'ab', 'b', 'b', 'b', 'b', 'b', 'b']
ret = re.findall('0*133........', '13312345678 0000133123456767 01332332214 0133202054')
print(ret) # ['13312345678', '000013312345676', '01332332214 ']
ret = re.findall('.*', '13312345678 0000133123456767 01332332214 0133202054')
print(ret) # ['13312345678 0000133123456767 01332332214 0133202054', '']
""" {m,n} 范围贪婪符,匹配m个至n个原子
# 逗号左边的的非负整数必须<=右边的非负整数
{n} 匹配左边的n个原子
{n,} 匹配左边的n个以上原子
{n,m} 匹配左边的最少n个,最多m个以上原子
{,n} 匹配左边的最多n个原子
* 相当于 {0,}
+ 相当于 {1,}
? 相当于 {0,1}
"""
ret = re.findall('a{1,3}b', 'aaab ab aab abbb aaz aabb')
print(ret) # ['aaab', 'ab', 'aab', 'ab', 'aab']
ret = re.findall('a{2,}b', 'aaab ab aab abbb aaz aabb')
print(ret) # ['aaab', 'aab', 'aab']
""" | 指定原子或正则模式进行二选一或多选一 """
txt = "13512356782 17118856782 178560356782"
# 只匹配135或171的手机号
ret = re.findall('135\d{8}|171\d{8}|178', txt)
print(ret) # ['13512356782', '17118856782', '178']
""" () 对原子或正则模式进行捕获提取和分组操作 """
txt = "13512356782 17118856782 178560356782"
ret = re.findall("(135|171)\d{8}", txt)
print(ret) # ['135', '171']
# () 具备模式捕获的能力,也就是优先提取数据的能力,所以会导致\d{8}没有显示,所以要通过(?:) 取消模式捕获
txt = "13512356782 17118856782 178560356782"
ret = re.findall("(?:135|171)\d{8}", txt)
print(ret) # ['13512356782', '17118856782']
特殊元字符
特殊元字符是
\开头的元字符,由于某些正则模式会在开发中反复被用到,所以正则语法预定义了一些特殊正则模式以方便我们简写。
| 元字符 | 描述 | 示例 |
|---|---|---|
| \d | 匹配一个数字原子,等价于[0-9]。 |
\d |
| \D | 匹配一个非数字原子。等价于[^0-9]或[^\d]。 |
"\D" |
| \b | 匹配一个单词边界原子,也就是指单词和空格间的位置。 | er\b |
| \B | 匹配一个非单词边界原子,等价于 [^\b] |
r"\Bain"r"ain\B" |
| \n | 匹配一个换行符 | |
| \t | 匹配一个制表符,tab键 | |
| \s | 匹配一个任何空白字符原子,包括空格、制表符、换页符等等。等价于[ \f\n\r\t\v]。 |
"\s" |
| \S | 匹配一个任何非空白字符原子。等价于[^ \f\n\r\t\v]或 [^\s]。 |
"\S" |
| \w | 匹配一个包括下划线的单词原子。等价于[A-Za-z0-9_]。 |
"\w" |
| \W | 匹配任何非单词字符。等价于[^A-Za-z0-9_] 或 [^\w]。 |
"\W" |
点击查看代码
import re
"""特殊元字符,也叫预设元字符,或预设正则模式"""
""" \d 1个数字原子 """
txt = "1alala2"
ret = re.findall('\d', txt)
print(ret) # ['1', '2']
""" \D 1个非数字原子 """
txt = "1alala2"
ret = re.findall('\D', txt)
print(ret) # ['a', 'l', 'a', 'l', 'a']
""" \b 1个单词边界原子 """
txt = "my name is nana. nihao,nana"
ret = re.findall(r'\bna', txt)
print(ret) # ['na', 'na', 'na']
""" \B 1个非单词边界原子 """
txt = "my name is nana. nihao,nana"
ret = re.findall(r'\Bna', txt)
print(ret) # ['na', 'na']
""" \n 1个换行符原子 """
txt = """wo jiao nana.\nnihao,nana
ni zai nali"""
ret = re.findall(r'\nni', txt)
print(ret) # ['\nni', '\nni']
"""\s 匹配一个任何空白字符原子"""
txt = """wo jiao nana.\nnihao,nana
ni zai nali, nihao"""
ret = re.findall('\sni', txt)
print(ret) # ['\nni', '\nni', '\tni']
"""\S 匹配一个任何非空白字符原子"""
txt = """wo jiao nana.\nnihao,nana
ni zai nali, nihao"""
ret = re.findall(r'\Sna', txt)
print(ret) # ['ana', ',na']
"""\w 匹配一个包括下划线的单词原子 等价于[A-Za-z0-9_]。"""
txt = """wo jiao nana.\nnihao,nana, python_django, b2c"""
ret = re.findall(r'\w+', txt)
print(ret) # ['wo', 'jiao', 'nana', 'nihao', 'nana', 'python_django', 'b2c']
"""\W 匹配一个非下划线非单词的原子 等价于[^A-Za-z0-9_]。"""
txt = "wo jiao nana.\nnihao,nana, python_django, b2c"
ret = re.findall('\W+', txt)
print(ret) # [' ', ' ', '.\n', ',', ', ', ', ']
常用正则表达式
工作中,正则一般用于验证数据、校验用户输入的信息、爬虫、运维日志分析等。其中如果是验证用户输入的数据:
| 场景 | 正则表达式 |
|---|---|
| 用户名 | ^[a-z0-9_-]{3,16}$ |
| 密码 | ^[a-z0-9_-]{6,18}$ |
| 手机号码 | ^(?:\+86)?1[3-9]\d{9}$ |
| 颜色的十六进制值 | `^#?([a-f0-9] |
| 电子邮箱 | ^[a-z\d]+(\.[a-z\d]+)*@([\da-z](-[\da-z])?)+\.[a-z]+$ |
| URL | `^(?:https:// |
| IP 地址 | `((2[0-4]\d |
| HTML 标签 | ^<([a-z]+)([^<]+)*(?:>(.*)<\/\1> |
| utf-8编码下的汉字范围 | ^[\u2E80-\u9FFF]+$ |
re模块
Python提供了处理正则表达式的模块有标准库的re模块和第三方模块regex。
导入
re模块后,可以开始使用正则表达式了。
import re
查找一个手机号码
点击查看代码
import re
txt = "13312345678"
ret = re.search('^1[3-9]\d{9}$', txt)
print(ret) # <re.Match object; span=(0, 11), match='13312345678'>
if ret:
print(ret.group()) # 13312345678
注意:python本身没有内置正则处理的,python中的正则就是一段字符串,我们需要使用python模块中提供的函数把字符串发送给正则引擎,正则引擎会把字符串转换成真正的正则表达式来处理文本内容。
re模块提供了一组正则处理函数,使我们可以在字符串中搜索匹配项:
| 函数 | 描述 |
|---|---|
| findall | 按指定的正则模式查找文本中所有符合正则模式的匹配项,以列表格式返回结果。 |
| search | 在字符串中任何位置查找首个符合正则模式的匹配项,存在则返回re.Match对象,不存在返回None |
| match | 判定字符串开始位置是否匹配正则模式的规则,匹配则返回re.Match对象,不匹配返回None |
| split | 按指定的正则模式来分割字符串,返回一个分割后的列表 |
| sub | 把字符串按指定的正则模式来查找符合正则模式的匹配项,并可以替换一个或多个匹配项成其他内容。 |
findall
findall()函数返回包含所有匹配项的列表,如果找不到匹配项,则返回一个空列表。
点击查看代码
import re
# 匹配上
txt = "His name is iron man, He's Amazing"
ret = re.findall("ma", txt)
print(ret) # ['ma', 'ma']
# 匹配不上
txt = "my name is moluo"
ret = re.findall("python", txt)
print(ret) # []
search
search()函数搜索匹配的字符串,如果匹配上则返回匹配对象re.Match。如果有多个匹配项,则仅返回匹配项的第一个匹配项,如果找不到匹配项,则返回值为None:
点击查看代码
import re
# 匹配上
txt = "我今年18岁,我的弟弟比我小13岁"
ret = re.search('\d', txt)
print(ret) # <re.Match object; span=(3, 4), match='1'>
print("获取首个匹配到的数字原子的下标范围:", ret.span()) # 获取首个匹配到的数字原子的下标范围: (3, 4)
print("获取首个匹配到的数字原子的开始下标:", ret.start()) # 获取首个匹配到的数字原子的开始下标: 3
print("获取首个匹配到的数字原子的结束下标:", ret.end()) # 获取首个匹配到的数字原子的结束下标: 4
# 匹配不上
txt = """我今年18岁,我的弟弟比我小13岁"""
ret = re.search('moluo', txt)
print(ret) # None
match
match()函数搜索匹配的字符串开始位置,如果匹配上则返回匹配对象,如果找不到匹配项,则返回值为None
点击查看代码
import re
# 匹配上
ret = re.match('1[3-9]\d{9}','13928835900,这是我的手机号码')
print(ret) # <re.Match object; span=(0, 11), match='13928835900'>
print(ret.group()) # 13928835900
# 匹配不上
ret = re.match('1[3-9]\d{9}', '我的手机号码是13928835900')
print(ret) # None
ret = re.match("1[3-9]\d{9}$", "我的手机号码是13928835900")
print(ret) # None
split
split()函数返回一个列表,对字符串进行正则分割。
点击查看代码
import re
txt = "my name is zhangsan"
ret = re.split("\s", txt)
print(ret) # ['my', 'name', 'is', 'zhangsan']
可以通过指定
maxsplit参数来控制分割的次数,例如,仅在第1次出现时才拆分字符串:
点击查看代码
import re
txt = "my name is zhangsan"
ret = re.split("\s", txt, 1)
print(ret) # ['my', 'name is zhangsan']
sub
sub()函数用选择的文本替换匹配:
点击查看代码
import re
txt = "my name is zhangsan"
ret = re.sub("\s", "-", txt)
print(ret) # my-name-is-zhangsan
可以通过指定
count参数来控制替换次数:
点击查看代码
import re
txt = "my name is zhangsan"
ret = re.sub("\s", "-", txt, 2)
print(ret) # my-name-is zhangsan
正则进阶
匹配分组
匹配分组,也叫模式分组。
| 字符 | 功能 |
|---|---|
| a|b | 匹配左右任意一个模式,a与b代表的是一段任意的正则模式 |
| (ab) | 将括号中字符作为一个分组,表示一个整体,a与b代表的是一段任意的正则模式 |
\num |
引用分组num匹配到的字符串,num是一个正整数,代表的是前一个参数里面的对应位置的小括号中的模式。 |
(?P<name>) |
分组起别名 |
(?P=name) |
引用别名为name分组匹配到的字符串 |
注意:分组别名的P是大写字母。
点击查看代码
import re
"""匹配分组/模式分组"""
# 匹配 www.baidu.com 或者 www.tmall.com
# 正则中 . 是万能通配符,\. 表示文本中的普通原子
ret = re.search(r"(www)\.(baidu|tmall)\.(com)", "www.tmall.com")
if ret:
print(ret) # <re.Match object; span=(0, 13), match='www.tmall.com'>
print(ret.group()) # www.tmall.com # 没有提取小括号中的模式
print(ret.groups()) # ('www', 'tmall', 'com') # 提取小括号中的模式,也叫模式捕获
print(ret.group(1)) # www
print(ret.group(2)) # tmall
print(ret.group(3)) # com
"""取消模式分组"""
txt = "13512356782 17118856782 178560356782"
ret = re.findall("(?:135|171)\d{8}", txt) # # 匹配135或171的手机号
print(ret) # ['13512356782', '17118856782']
txt = "<h1>这是web前端代码</h1> <h1>尖括号圈住的是html标签</h1>"
ret = re.findall(r"<h1>(.+)</h1>", txt)
print(ret) # ['这是web前端代码</h1> <h1>尖括号圈住的是html标签']
txt = "<h1>这是web前端代码</h1> <h1>尖括号圈住的是html标签</h1>"
ret = re.findall(r"<h1>(.+?)</h1>", txt) # ?可以让.+模式只激活0次或1次,达到多次匹配的效果
print(ret) # ['这是web前端代码', '尖括号圈住的是html标签']
txt = r"<h1>这是web前端代码</h1> <h2>尖括号圈住的是html标签</h2> <title>腾讯首页</title> <a href=\"javascript:void(0);\">更换城市</a>"
ret = re.findall(r"<[a-zA-Z]+\d?>(.+?)</[a-zA-Z]+\d?>", txt)
print(ret) # ['这是web前端代码', '尖括号圈住的是html标签', '腾讯首页']
# 复杂的HTML标签的内容提取
txt = """<h1>这是web前端代码</h1> <h2>尖括号圈住的是html标签</h2> <title>腾讯首页</title> <a href="javascript:void(0);">更换城市</a> <li><a href="javascript:void(0);">北京市</a></li>"""
ret = re.findall(r"<.*?>([^<]+?)</.*?>", txt) # ?可以让.+模式只激活0次或1次,达到多次匹配的效果
print(ret) # ['这是web前端代码', '尖括号圈住的是html标签', '腾讯首页', '更换城市', '北京市']
"""分组命名"""
txt = """<h1>这是web前端代码</h1> <h2>尖括号圈住的是html标签</h2> <title>腾讯首页</title> <a href="javascript:void(0);">更换城市</a> <li><a href="javascript:void(0);">北京市</a></li>"""
ret = re.search(r"<.*?>(?P<content>[^<]+?)</(?P<tag>.*?)>", txt)
if ret:
print(ret) # <re.Match object; span=(0, 18), match='<h1>这是web前端代码</h1>'>
print(ret.groupdict()) # # {'content': '这是web前端代码', 'tag': 'h1'}
# 其他的正则函数中,也支持模式分组别名,但是没有什么用途而已
txt = """<h1>这是web前端代码</h1> <h2>尖括号圈住的是html标签</h2> <title>腾讯首页</title> <a href="javascript:void(0);">更换城市</a> <li><a href="javascript:void(0);">北京市</a></li>"""
ret = re.findall(r"<.*?>(?P<content>[^<]+?)</(?P<tag>.*?>)", txt) # ?可以让.+模式只激活0次或1次,达到多次匹配的效果
print(ret) # [('这是web前端代码', 'h1>'), ('尖括号圈住的是html标签', 'h2>'), ('腾讯首页', 'title>'), ('更换城市', 'a>'), ('北京市', 'a>')]
"""模式的反向引用,模式的反向捕获"""
txt = "13512345678"
ret = re.sub(r"(\d{3})\d{4}(\d{4})", r"\1****\2", txt, count=1)
print(ret) # 135****5678
贪婪模式
Python里关于数量词的元字符在匹配查找的时候,会出现贪婪匹配的行为(在少数语言里也可能是默认非贪婪),总是尝试尽可能多的匹配符合正则模式的字符内容;
非贪婪则相反,总是尝试尽可能少的匹配符合正则模式的字符内容。
在"*","?","+","{m,n}"后面加上?,则可以是使贪婪变成非贪婪。
点击查看代码
txt = "My computer IP is 192-168-21-253"
ret = re.match(".+(\d+-\d+-\d+-\d+)", txt)
print(ret) # <re.Match object; span=(0, 32), match='My computer IP is 192-168-21-253'>
print(ret.group()) # My computer IP is 192-168-21-253
print(ret.group(1)) # 2-168-21-253
ret = re.match(".+?(\d+-\d+-\d+-\d+)", txt)
print(ret.group(1)) # 192-168-21-253
模式修正符
模式修正符,也叫正则修饰符,模式修正符就是给正则模式增强或增加功能的。
| 修正符 | re模块提供的变量 | 描述 |
|---|---|---|
| i | re.I | 使模式对大小写不敏感,也就是不区分大小写 |
| m | re.M | 使模式在多行文本中可以多个行头和行位,影响 ^ 和 $ |
| s | re.S | 让通配符. 可以代码所有的任意原子(包括换行符\n在内) |
点击查看代码
import re
"""I 修正符"""
# 默认情况下,模式区分大小写,也就是对字母大小写不敏感。
txt = "python是一门脚本语言,Python是一门面向对象的编程语言,PYTHON也是一门开源的类C语言,与java,php,go语言类似"
ret = re.findall('python', txt)
print(ret) # ['python']
ret = re.findall('python', txt, re.I)
print(ret) # ['python', 'Python', 'PYTHON']
"""M 修正符"""
# 可以让模式在多行文本中,分行区分行头^行尾$
txt = """pyThon是一门脚本语言,python简单易学,
Python是一门面向对象的编程语言,属于强类型范畴
PYTHON也是一门开源的类C语言,与java,php,go语言类似,python语法类似C语言
"""
# re.M+re.I 表示同时使用I和M修正符
ret = re.findall('^python', txt, re.M+re.I) # 在re.M的增强下,^不再是代表字符串文本的开头位置,而是代表了一行的开始
print(ret) # ['pyThon', 'Python', 'PYTHON']
"""S 修正符"""
# 让.变成真正的通配符,包含\n换行符
txt = """
<a href="http://www.baidu.com">百度</a>
<a href="http://www.tmall.com">天猫</a>
<a href="http://www.taobao.com">
淘宝
</a>
"""
ret = re.findall('<.*?>(.*?)</.*?>', txt, re.S)
print(ret) # ['百度', '天猫', '\n 淘宝\n']
正则在文本处理方面的应用
正则经常用于数据提取,爬虫数据抓取工作。
import re
BASE_URL = "https://www.znl**.com"
with open("穿越大明.html", "r", encoding="utf-8") as f:
# 读取内容,将来通过网络模块进行下载读取[urllib, requests, scapy]
page = f.read()
# 提取关键信息所在的范围内容,去除不必要的内容
content = re.findall(r'id="main">.*?</.*?>(.*?)<div class="listpage">', page, re.I+re.S+re.M)
data_list = re.findall(r'<li><a href="(.*?)">(.*?)</a></li>', content[0], re.I+re.S+re.M)
for item in data_list:
print(f"网址:{BASE_URL}{item[0]}; 标题: {item[1]}")
针对Linux系统下的命令,例如grep,sed,awk等命令也是支持正则的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号