mysql 覆盖索引
参考自 cnblogs.com/chenpingzhao/p/4776981.html
概念:索引包含查询需要的所有字段,则称为覆盖索引,不需要再回表。
判断标准:explain,如果 extra列=using index,则会覆盖索引
表结构
CREATE TABLE `inventory` ( `inventory_id` mediumint(8) unsigned NOT NULL AUTO_INCREMENT, `film_id` smallint(5) unsigned NOT NULL, `store_id` tinyint(3) unsigned NOT NULL, `last_update` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, PRIMARY KEY (`inventory_id`), KEY `idx_fk_film_id` (`film_id`), KEY `idx_store_id_film_id` (`store_id`,`film_id`), CONSTRAINT `fk_inventory_film` FOREIGN KEY (`film_id`) REFERENCES `film` (`film_id`) ON UPDATE CASCADE, CONSTRAINT `fk_inventory_store` FOREIGN KEY (`store_id`) REFERENCES `store` (`store_id`) ON UPDATE CASCADE ) ENGINE=InnoDB AUTO_INCREMENT=4582 DEFAULT CHARSET=utf8 |
explain
mysql> EXPLAIN SELECT store_id, film_id FROM sakila.inventory\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: inventory
type: index
possible_keys: NULL
key: idx_store_id_film_id
key_len: 3
ref: NULL
rows: 4581
Extra: Using index
1 row in set (0.03 sec)

-- 5.7.33-log
select version()
| 字段 | 值 | 含义说明 |
|---|---|---|
| id | 1 | 查询的唯一标识(此处只有一个查询,无子查询 / 联表) |
| select_type | SIMPLE | 简单查询(非子查询、非联表、非派生表) |
| table | t | 本次查询涉及的表名是 t |
| partitions | (空) | 表未做分区,无分区匹配信息 |
| type | ref | 访问类型为 ref(非主键 / 唯一索引的等值匹配,属于高效级别,仅次于 const/eq_ref) |
| possible_keys | idx_task_id | 优化器认为可能用到的索引:idx_task_id |
| key | idx_task_id | 实际使用的索引:idx_task_id(与 possible_keys 一致,索引选择合理) |
| key_len | 147 |
使用的索引长度为 147 字节(需结合字段类型判断:如
|
| ref | const | 索引匹配的是常量值(如 WHERE task_id = '固定值') |
| rows | 1 | 优化器预估需要扫描的行数(仅 1 行,效率极高) |
| filtered | 100.0 | 经过条件过滤后剩余的行数比例(100% 表示无额外过滤,条件直接命中索引) |
| Extra | Using index | 覆盖索引(Covering Index):查询所需字段全部包含在索引中,无需回表查询主键 / 其他字段 |

6196行增加where 后
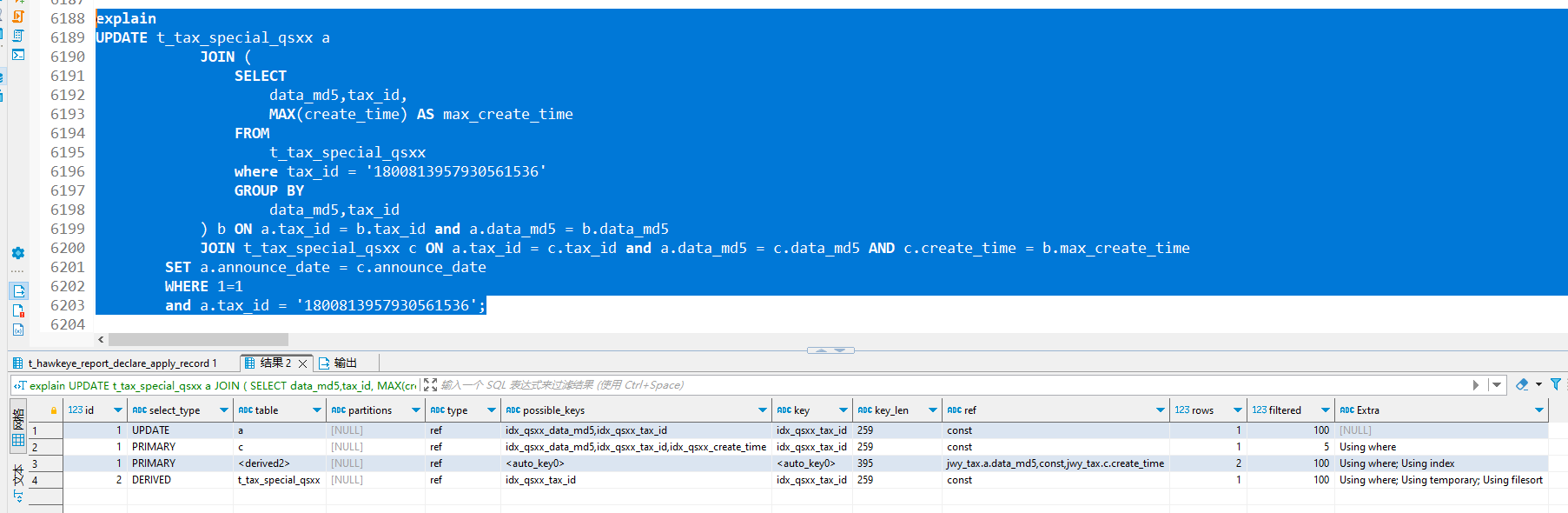
三、剩余问题:为何子查询仍有「临时表 + 文件排序」?
四、最终优化:创建「分组 + 排序」覆盖索引(根治临时表 / 文件排序)
优化后预期效果:
*
备注:公众号清汤袭人能找到我,那是随笔的地方
备注:公众号清汤袭人能找到我,那是随笔的地方

 浙公网安备 33010602011771号
浙公网安备 33010602011771号