hadoop hive hbase
公司报表是基于数仓开发的,分层是ods>dwd>dwm>dm,sqoop再同步到传统数据库,帆软展示,或tableau展示,这块涉及的是离线计算。
记录下大数据开发设计的概念:
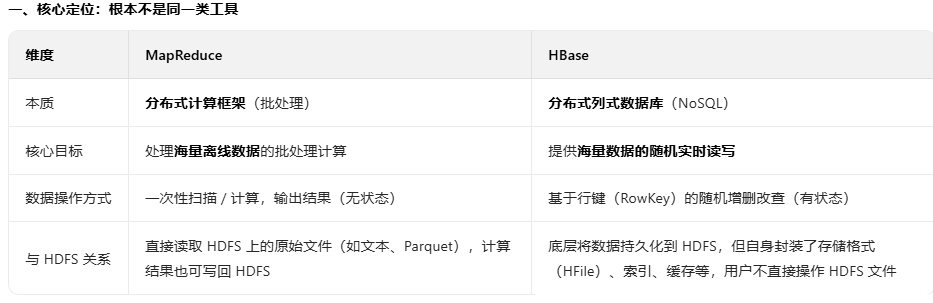
1、hadoop:分布式计算(MapReduce)+分布式文件系统(HDFS),后者可以独立运行,前者可以选择性使用,也可以不使用
2、hive:数据仓库,仓库中的数据是被hdfs管理的数据文件,它支持类似sql语句的功能,你可以通过该语句完成分布式环境下的计算功能,hive会把语句转换成MapReduce,然后交给hadoop执行。这里的计算,仅限于查找和分析,而不是更新、增加和删除。它的优势是对历史数据进行处理,也即 离线计算,因为它的底层是MapReduce,MapReduce在实时计算上性能很差。它的做法是把数据文件加载进来作为一个hive表(或者外部表),让你觉得你的sql操作的是传统的表。
3、hbase:hbase的作用类似于数据库,传统数据库管理的是集中的本地数据文件,而hbase基于hdfs实现对分布式数据文件的管理,比如增删改查。也就是说,hbase只是利用hadoop的hdfs帮助其管理数据的持久化文件(HFile),它跟MapReduce没任何关系。hbase的优势在于实时计算,所有实时数据都直接存入hbase中,客户端通过API直接访问hbase,实现实时计算。由于它使用的是nosql,或者说是列式结构,从而提高了查找性能,使其能运用于大数据场景,这是它跟MapReduce的区别。
总结:
hadoop是hive和hbase的基础,hive依赖hadoop,而hbase仅依赖hadoop的hdfs模块。
hive适用于离线数据的分析,操作的是通用格式的(如通用的日志文件)、被hadoop管理的数据文件,它支持类sql,比编写MapReduce的java代码来的更加方便,它的定位是数据仓库,存储和分析历史数据
hbase适用于实时计算,采用列式结构的nosql,操作的是自己生成的特殊格式的HFile、被hadoop管理的数据文件,它的定位是数据库,或者叫DBMS
hive可以直接操作hdfs中的文件作为它的表的数据,也可以使用hbase数据库作为它的表
————————————————
参考资料:
1、https://blog.csdn.net/m0_67402125/article/details/126582077
2、谷歌三篇大数据相关的论文
===========
二、核心差异拆解
1. 数据处理模式:批处理 vs 实时随机访问
2. 数据存储形态:无状态计算 vs 有状态存储
3. 对 HDFS 的依赖:直接操作 vs 封装抽象
4. 适用场景:离线批处理 vs 实时在线业务
三、二者的关联(不是对立,而是互补)
四、总结:核心区别一句话
备注:公众号清汤袭人能找到我,那是随笔的地方

 浙公网安备 33010602011771号
浙公网安备 33010602011771号