<实战训练01>KNN-预测鸢尾花的种类
一、KNN算法简介
K Nearest Neighbor算法又叫KNN算法。如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。
简单来说,就是确定好k值后,在一个样本点周围的k个数据分别属于什么类别,那么该样本点就属于大多数数据所属的类别
二、机器学习算法实现流程
我们将使用机器学习的一般流程来实现这个案例,机器学习解决实际问题的一般流程如下:
-
获取数据集
-
数据基本处理
-
特征工程
-
训练模型
-
模型评估
三、scikit-learn
scikit-learn是python编写的机器学习库,它可以简单而有效的进行数据预测和分析,底层使用了NumPy、SciPy和matplotlib,是个开源免费的项目。
使用流程
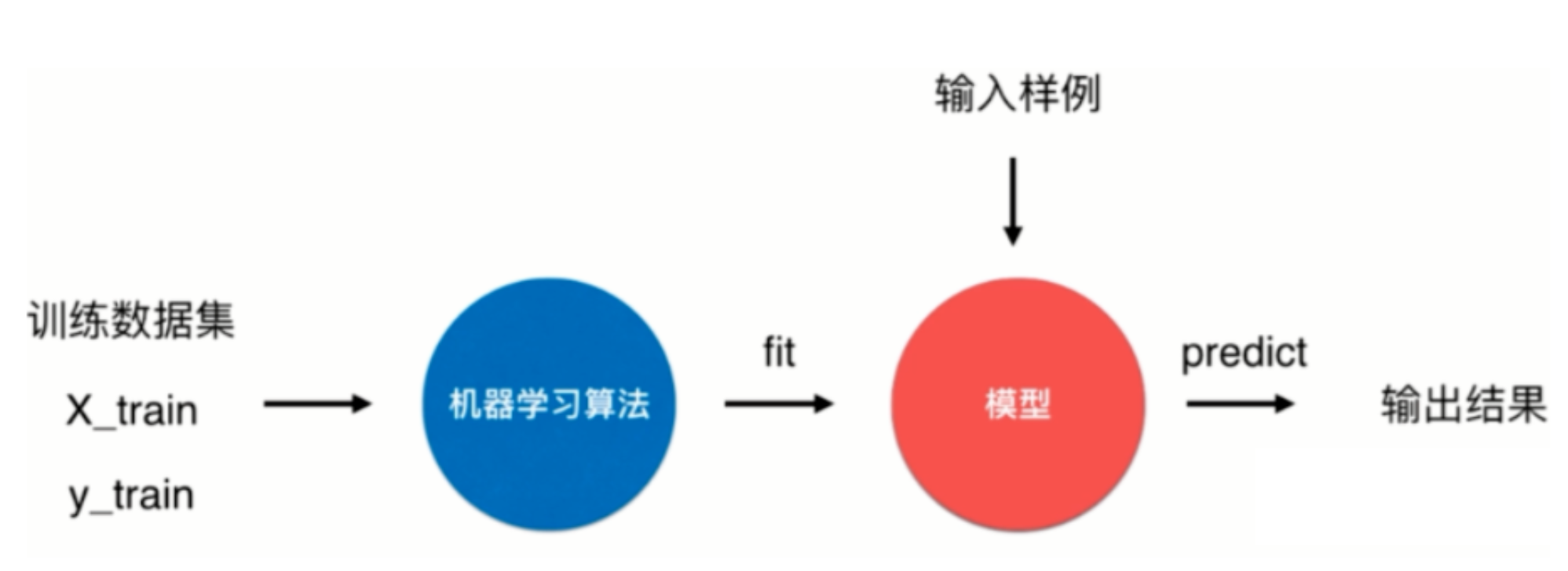
四、预测鸢尾花种类
鸢尾花数据集

代码实现[加注释]
1. 导入相关模块
# sklearn.datasets可以导入数据集
import sklearn.datasets as skdata
# 对数据进行可视化
import matplotlib.pyplot as plt
# 基于matplotlib的更加强大的可视化库
import seaborn as sns
# 用于数据处理-如数据格式化
import pandas as pd
# 做参数选择
import sklearn.model_selection as skmodel
# knn算法包
import sklearn.neighbors as skneighbors
# 对数据集进行分割
import sklearn.preprocessing as skprep
2. 加载iris数据集
iris_data=skdata.load_iris()
# iris_data的类型sklearn.utils.Bunch
type(iris_data)
# iris_data属性['DESCR', 'data', 'feature_names', 'target', 'target_names']
dir(iris_data)
# print(iris_data)
# iris_data.feature_names
# iris_data.target
3.可视化iris数据
seaborn是基于matplotlib核心库进行的了更高级的api封装,配色舒服,图形元素样式细腻
# 3.1 将数据集转化为pandas.DataFrame类型
# param1:data数据 param2:columns=字段名
iris_df=pd.DataFrame(iris_data['data'],columns=['sepal length (cm)',
'sepal width (cm)',
'petal length (cm)',
'petal width (cm)'])
iris_df['Species']=iris_data.target
# print(iris_df)
# 3.2 绘制散点图,初步探索数据间关系,对数据的基本分析
# sns.relplot用来绘制散点图,随便选取两个特征
sns.relplot(x='petal length (cm)',y='sepal length (cm)',data=iris_df,hue='Species')
4. 数据集的划分
# 划分训练集和测试集
# 训练集特征值、测试集特征值、训练集目标值、测试集目标值
x_train, x_test, y_train, y_test = skmodel.train_test_split(iris_data.data, iris_data.target, test_size=0.2)
5. 使用KNN算法做预测
# 实现机器学习算法,构造模型,取k个近邻点->9
knn_model=skneighbors.KNeighborsClassifier(n_neighbors=9)
# 训练数据
knn_model.fit(x_train,y_train)
# 预测数据
y_predict=knn_model.predict(x_test)
y_predict==y_test
6. 计算准确率
score=knn_model.score(x_test,y_test)
score

 浙公网安备 33010602011771号
浙公网安备 33010602011771号