Python【第六篇】反射、递归、异常处理
reflect反射
通过hasattr()、getattr()、setattr()、delattr()来实现反射;
首先,区分两个概念【标识名】和看起来相同的【字符串】。两者字面上看起来一样,却是两种东西;
例如:
def func():
print("func是这个函数的名字!")
s = "func"
print("{0}是个字符串".format(s))
前者是函数func的函数名,后者只是一个叫"func"的字符串,两者是不同的事物。可以用func()的方式调用函数func,但不能用"func"()的方式调用函数,不能通过字符串来调用名字看起来相同的函数。
场景:根据用户输入url的不同,调用不同的函数,实现不同的操作也就是一个WEB框架的url路由功能。
首先有一个commons.py文件,里面定义几个函数,分别用于展示不同的页面。这就是Web服务的视图文件,用于处理实际的业务逻辑。
commons.py
#!/usr/bin/env python
# -*- coding: utf-8 -*-
__author__ = 'tian'
__data__ = '2019/5/8 11:54'
def login():
print("这是一个登录页面")
def logout():
print("这是一个退出页面")
def home():
print("这是网站主页面")
visit.py
#!/usr/bin/env python
# -*- coding: utf-8 -*-
__author__ = 'tian'
__data__ = '2019/5/8 11:55'
import commons
def run():
inp = input("请输入您想访问页面的url:").strip()
if inp == "login":
commons.login()
elif inp == "logout":
commons.logout()
elif inp == "home":
commons.home()
else:
print("404")
if __name__ == '__main__':
run()
运行visit.py --->输入home页面结果如下:请输入您想访问页面的url:home 输出:这是网站主页面。
这就实现了一个简单的url路由功能,根据不同的url,执行不同的函数,获得不同的页面。
如果commons文件里有成千上万个函数呢?难道在visit模块里写上成百上千个elif?显然这是不可能的,那么怎么办?
仔细观察visit.py中的代码,发现用户输入的url字符串和相应调用的函数名很像,如果能用这个字符串直接调用函数就好了!但是【字符串】是不能用来调用函数的。为了解决这个问题,Python提供了反射机制,帮助我们实现这一想法。
主要就表现在getattr()等几个内置函数上!
将前面的visit.py修改一下:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
__author__ = 'tian'
__data__ = '2019/5/8 11:55'
import commons
def run():
inp = input("请输入您想访问页面的url:").strip()
func = getattr(commons,inp)
func()
if __name__ == '__main__':
run()
func = getattr(commons,inp)语句是关键,通过getattr()函数从commons模块里,查找到和inp字符串【外形】相同的函数名,并将其返回然后赋值给func变量。变量func此时就指向那个函数,func()就可以调用该函数。
getattr()函数的使用方法:接收2个参数:前面的是一个类或者模块,后面的是一个字符串。
这个过程就相当于把一个字符串变成一个函数名的过程,这是一个动态范围的过程,一切都不写死,全部根据用户输入来变化。
上面代码有bug,就是如果用户输入一个非法的url,例如:jpg 由于在commons里没有同名的函数,肯定会如下图错误:
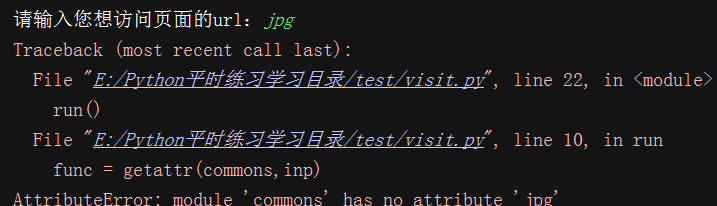
如何解决呢?Python提供了一个hasattr()的内置函数,用法和getattr()基本相似,它可以判断commons中是否具有某个成员,返回True或False;
修改如下:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
__author__ = 'tian'
__data__ = '2019/5/8 11:55'
import commons
def run():
inp = input("请输入您想访问页面的url:").strip()
if hasattr(commons,inp):
func = getattr(commons,inp)
func()
else:
print("404")
if __name__ == '__main__':
run()
这样就没有问题了,通过hasattr()的判断,可以防止非法输入导致的错误,并将其统一定位到错误页面。
Python的四个重要内置函数:getattr()、hasattr()、delattr()、setattr()较为全面的实现了基于字符串的反射机制。
动态导入模块
前面的例子需要commons.py和visit.py模块在同一目录下,并且所有的页面处理函数都在commons模块内:
但在实际环境中,页面处理函数往往被分类放置在不同目录的不同模块中。
原则上只需要在visit.py模块中逐个导入每个视图模块即可。但是,如果这些模块很多呢?难道要在visit里写上一大堆的import语句逐个导入account、manage、commons模块吗?要是有1000个模块呢?
可以使用Python内置的__import__(字符串参数)函数解决这个问题。通过它,可以实现类似getattr()的反射功能。__import__()方法会根据字符串参数,动态地导入同名的模块。
修改一下visit.py
#!/usr/bin/env python
# -*- coding: utf-8 -*-
__author__ = 'tian'
__data__ = '2019/5/8 11:55'
def run():
inp = input("请输入您想访问页面的url:").strip()
modules,func = inp.split("/")
obj = __import__(modules)
if hasattr(obj,func):
func = getattr(obj,func)
func()
else:
print("404")
if __name__ == '__main__':
run()
需要注意:输入的时候要同时提供模块名和函数名字,并用斜杠分隔。

同样这里有个小bug,如果目录结构是这样,visit.py和commons.py不在同一个目录下,存在跨包的问题:
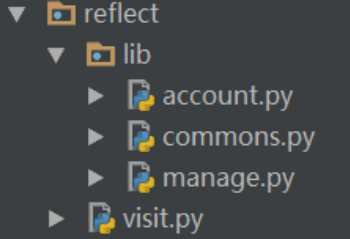
那么在visit的调用语句中,必须进行修改:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
__author__ = 'tian'
__data__ = '2019/5/8 11:55'
def run():
inp = input("请输入您想访问页面的url:").strip()
modules,func = inp.split("/")
obj = __import__("lib."+modules,fromlist=True) #注意fromlist参数
if hasattr(obj,func):
func = getattr(obj,func)
func()
else:
print("404")
if __name__ == '__main__':
run()
总结:反射指基于字符串的形式去对象(模块)中操作成员。
导入模块的方式
- import xxx;
- from xxx import oooo;
- 动态导入(根据字符串:)obj =__import__("xxx");
- 动态导入不同目录,根据字符串导入模块,obj =__import__("xxx.oo.xxx",fromlist=True)
模块与包
编程语言中,代码块、函数、类、模块、一直到包逐级封装层层调用。
在Python中一个.py文件就是一个模块,模块是比类更高一级的封装。
模块可以分为自定义模块、内置模块、第三方模块。
自定义模块就是自己编写的模块,如果水平很高可以申请为Python内置的标准模块之一,如果在网上发布自己的模块并允许其他人使用,那么就变成了第三方模块。
使用模块的好处?
- 首先,提供了代码的可维护性。
- 编写代码不必要从零开始,当一个模块编写完毕,就可以被其他模块引用,不用重复造轮子。
- 使用模块还可以避免类名、函数名、变量名发生冲突。相同名字的类、函数、变量完全可以分别存在不同的模块中。
为了避免模块名冲突,Python又引入了按目录来组织模块的方法,称为包(Package)包是模块的集合,比模块又高一级的封装。没有比包更高级别的封装,但是包可以嵌套包就像文件夹目录一样。
包名通常全部小写,避免使用下划线。
要在程序中使用其它模块(包、类、函数),就必须先导入对应的模块(包/函数/类)。
Python中模块导入的方式有以下几种:
- import xx.xx
- from xx.xx import xx
- from xx.xx import xx as rename
- from xx.xx import *
1、import xx.xx
这里将对象(包、模块、类、函数)中的所有内容导入。如果该对象是个模块,那么调用对象内的类、函数、变量时,需要以modul.xxx的方式。
例如:被到导入的模块Module_a
#module_a.py
def func():
print("这里是 module A")
#Main.py
import module_a
module_a.func() #调用方法
2、From xx.xx import xx.xx
从某个对象内导入某个指定的部分到当前命名空间中,不会将整个对象导入。这种方式可以节省写长串导入路径的麻烦,但要小心名字冲突。
#module_a.py
def func():
print("这里是 module A")
#Main.py
from module_a import func
func() #调用方法
3、from xx.xx import xx as rename
为了避免命名冲突,在导入的时候,可以给导入的对象重命名。
4、from xx,xx import *
将对象内所有的内容全部导入。非常容易发生命名冲突,谨慎使用。
模块搜索路径
无论在程序中执行了多少次import,一个模块只会被导入一次。这样可以防止一遍又一遍地导入模块,节省内存和计算机资源。
那么,当使用import语句的时候,Python解释器是怎么样找到对应的文件呢?
Python根据sys.path的设置的顺序来搜索模块。
import sys
print(sys.path)
#输出
['E:\\test', 'E:\\test', 'C:\\Python34\\python34.zip', 'C:\\Python34\\DLLs', 'C:\\Python34\\lib', 'C:\\Python34','C:\\Python34\\lib\\site-packages']
这些设置可以自定义。通过sys.path.append('路径')的方法为sys.path路径列表添加需要的路径。
默认情况下,模块的搜索顺序:
- 当前执行脚本所在的目录
- Python的安装模块
- Python安装目录里面的site-packages目录
自定义 ---> 内置 --->第三方模块的顺序查找。任何一步查找到了,就会忽略后面的路径,所以模块的放置位置是有区别的。
在自定义模块的时候,对模块的命名一定要注意,不要和官方标准模块以及一些比较有名的第三方模块重名,否则就容易出现模块导入错误的情况发生。
包(Package)
前面我们已经介绍过,包是一种管理模块的手段,采用包名、子包名...模块名的调用形式,非常类似文件系统中的文件目录。但是包不等于文件目录!
含有__init__.py文件的目录才会被认为是一个包:
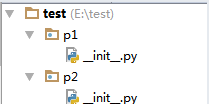
上图中的test、p1和p2都是包,因为目录内都有__init__.py文件。
___init__.py可以是空文件,也可以有Python代码,__init__.py本身就是一个模块。
递归
函数自己调用自己就是递归
例如:阶乘 1*2*3*...7
def func(num):
if num == 1:
return 1;
return num * func(num-1)
x = func(7)
print(x)
异常处理
在程序运行过程中,总会遇到各种各样的问题和错误。有些错误是编写代码时造成的,例如语法错误、调用错误、逻辑错误。还有一些错误,是不开预料的错误但是完全有可能发生,例如文件不存在、
磁盘空间不足、网络堵塞、系统错误等等。这些导致程序在运行过程中出现异常中断和退出的错误,统称为异常。大多数异常都不会被程序处理,而是以错误信息的形式展现出来。
异常有很多种类型,Python内置了几十种常见的异常,就在builtins模块内,无需特别导入,直接就可使用。需要注意的是,所有异常都是异常类,首字母是【大写.
为了保住程序的正常运行,提高程序健壮性和可用性。应当尽量考虑全面,将可能出现的异常进行处理。
Python内置了一套try...except..finally(else)...的异常处理机制,基础语法如下:
try:
pass
except Exception as ex:
pass
Python的异常机制具有嵌套处理能力,例如:下面的函数f3()调用f2(),f2()调用f1(),虽然是在f1()出错了。但只需要在f3()进行异常捕获,不需要每一层都捕获异常。
def f1():
return 10/0
def f2():
f1()
def f3():
f2()
try:
f3()
except ZeroDivisionError as er:
print(er)
try...except...语句处理异常的工作机制如下:
- 首先,执行try子句(关键字try和关键字except之间的语句)
- 如果没有异常发送,忽略except子句,try子句执行后结束
- 如果在执行try字句的过程中发生了异常,那么try字句余下的部分被忽略。如果异常的类型和except之后的名称相符,那么对应的except子句将被执行。
try:
print("发生异常之前的语句正常执行")
print(1/0)
print("发生异常之后的语句不会被执行")
except ZeroDivisionError as er:
print(er)
#发生异常之前的语句正常执行
#division by zero
#如果程序发生的异常不在你的捕获列表中,那么依然会抛出别的异常。
s1 = 'hello'
try:
int(s1)
except IndexError as er: #非法值异常
print(er)
#ValueError: invalid literal for int() with base 10: 'hello'
finally和else子句
try except语法还有一个可选的else子句,如果使用这个子句,那么必须放在所有的except字句之后。这个子句将在try字句没有发生任何 异常的时候执行。
try:
print("正常了")
except IOError:
print('错误了')
else:
print("进入了else里面")
finally子句无论try执行情况和except异常触发情况finally子句都会被执行
try:
print('try...')
r = 10 / int('a')
print('result:', r)
except ValueError as e:
print('ValueError:', e)
finally:
print('finally...')
print('END')
当else和finally同时存在时
try:
pass
except:
pass
else:
print("else")
finally:
print("finally")
#输出 else finally
#如果发生异常
try:
1/0
except:
pass
else:
print("else")
finally:
print("finally")
#输出finally
主动抛出异常
很多时候需要主动抛出一个异常。Python内置了一个关键字raise,可以主动触发异常。
raise唯一的一个参数指定了要被抛出的异常实例,如果什么参数都不给,那么会默认抛出当前异常。
