
3.Spark设计与运行原理,基本操作
Spark生态圈以Spark Core为核心,从HDFS、Amazon S3和HBase等持久层读取数据,以MESS、YARN和自身携带的Standalone为资源管理器调度Job完成Spark应用程序的计算。 这些应用程序可以来自于不同的组件,如Spark Shell/Spark Submit的批处理、Spark Streaming的实时处理应用、Spark SQL的即席查询、BlinkDB的权衡查询、MLlib/MLbase的机器学习、GraphX的图处理和SparkR的数学计算等等。
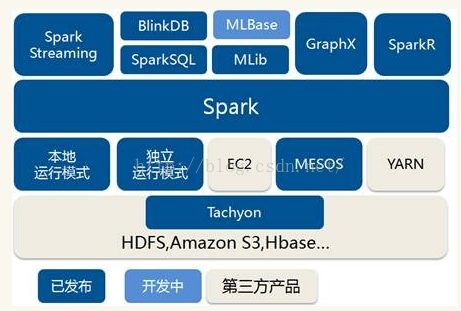
Spark Core
前面介绍了Spark Core的基本情况,以下总结一下Spark内核架构:
提供了有向无环图(DAG)的分布式并行计算框架,并提供Cache机制来支持多次迭代计算或者数据共享,大大减少迭代计算之间读取数据局的开销,这对于需要进行多次迭代的数据挖掘和分析性能有很大提升
在Spark中引入了RDD (Resilient Distributed Dataset) 的抽象,它是分布在一组节点中的只读对象集合,这些集合是弹性的,如果数据集一部分丢失,则可以根据“血统”对它们进行重建,保证了数据的高容错性;
移动计算而非移动数据,RDD Partition可以就近读取分布式文件系统中的数据块到各个节点内存中进行计算
使用多线程池模型来减少task启动开稍
采用容错的、高可伸缩性的akka作为通讯框架
2.2 SparkStreaming
SparkStreaming是一个对实时数据流进行高通量、容错处理的流式处理系统,可以对多种数据源(如Kdfka、Flume、Twitter、Zero和TCP 套接字)进行类似Map、Reduce和Join等复杂操作,并将结果保存到外部文件系统、数据库或应用到实时仪表盘。
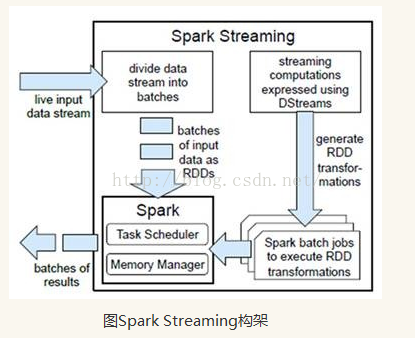
Spark Streaming构架
l计算流程:Spark Streaming是将流式计算分解成一系列短小的批处理作业。这里的批处理引擎是Spark Core,也就是把Spark Streaming的输入数据按照batch size(如1秒)分成一段一段的数据(Discretized Stream),每一段数据都转换成Spark中的RDD(Resilient Distributed Dataset),然后将Spark Streaming中对DStream的Transformation操作变为针对Spark中对RDD的Transformation操作,将RDD经过操作变成中间结果保存在内存中。整个流式计算根据业务的需求可以对中间的结果进行叠加或者存储到外部设备。下图显示了Spark Streaming的整个流程。
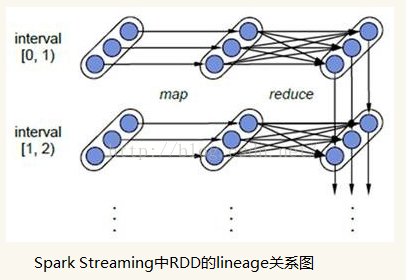
l容错性:对于流式计算来说,容错性至关重要。首先我们要明确一下Spark中RDD的容错机制。每一个RDD都是一个不可变的分布式可重算的数据集,其记录着确定性的操作继承关系(lineage),所以只要输入数据是可容错的,那么任意一个RDD的分区(Partition)出错或不可用,都是可以利用原始输入数据通过转换操作而重新算出的。
对于Spark Streaming来说,其RDD的传承关系如下图所示,图中的每一个椭圆形表示一个RDD,椭圆形中的每个圆形代表一个RDD中的一个Partition,图中的每一列的多个RDD表示一个DStream(图中有三个DStream),而每一行最后一个RDD则表示每一个Batch Size所产生的中间结果RDD。我们可以看到图中的每一个RDD都是通过lineage相连接的,由于Spark Streaming输入数据可以来自于磁盘,例如HDFS(多份拷贝)或是来自于网络的数据流(Spark Streaming会将网络输入数据的每一个数据流拷贝两份到其他的机器)都能保证容错性,所以RDD中任意的Partition出错,都可以并行地在其他机器上将缺失的Partition计算出来。这个容错恢复方式比连续计算模型(如Storm)的效率更高。
l实时性:对于实时性的讨论,会牵涉到流式处理框架的应用场景。Spark Streaming将流式计算分解成多个Spark Job,对于每一段数据的处理都会经过Spark DAG图分解以及Spark的任务集的调度过程。对于目前版本的Spark Streaming而言,其最小的Batch Size的选取在0.5~2秒钟之间(Storm目前最小的延迟是100ms左右),所以Spark Streaming能够满足除对实时性要求非常高(如高频实时交易)之外的所有流式准实时计算场景。
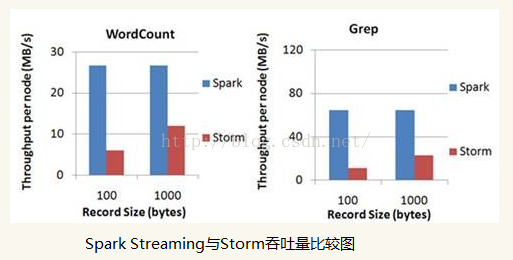
l扩展性与吞吐量:Spark目前在EC2上已能够线性扩展到100个节点(每个节点4Core),可以以数秒的延迟处理6GB/s的数据量(60M records/s),其吞吐量也比流行的Storm高2~5倍,图4是Berkeley利用WordCount和Grep两个用例所做的测试,在Grep这个测试中,Spark Streaming中的每个节点的吞吐量是670k records/s,而Storm是115k records/s。
2.3 Spark SQL
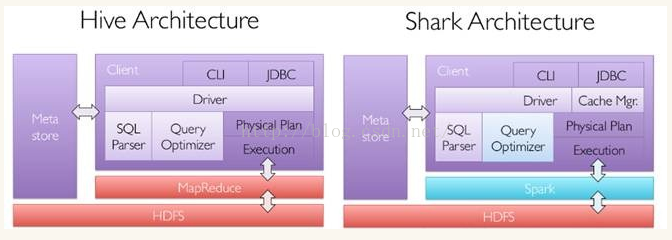
Shark是SparkSQL的前身,它发布于3年前,那个时候Hive可以说是SQL on Hadoop的唯一选择,负责将SQL编译成可扩展的MapReduce作业,鉴于Hive的性能以及与Spark的兼容,Shark项目由此而生。
Shark即Hive on Spark,本质上是通过Hive的HQL解析,把HQL翻译成Spark上的RDD操作,然后通过Hive的metadata获取数据库里的表信息,实际HDFS上的数据和文件,会由Shark获取并放到Spark上运算。Shark的最大特性就是快和与Hive的完全兼容,且可以在shell模式下使用rdd2sql()这样的API,把HQL得到的结果集,继续在scala环境下运算,支持自己编写简单的机器学习或简单分析处理函数,对HQL结果进一步分析计算。
在2014年7月1日的Spark Summit上,Databricks宣布终止对Shark的开发,将重点放到Spark SQL上。Databricks表示,Spark SQL将涵盖Shark的所有特性,用户可以从Shark 0.9进行无缝的升级。在会议上,Databricks表示,Shark更多是对Hive的改造,替换了Hive的物理执行引擎,因此会有一个很快的速度。然而,不容忽视的是,Shark继承了大量的Hive代码,因此给优化和维护带来了大量的麻烦。随着性能优化和先进分析整合的进一步加深,基于MapReduce设计的部分无疑成为了整个项目的瓶颈。因此,为了更好的发展,给用户提供一个更好的体验,Databricks宣布终止Shark项目,从而将更多的精力放到Spark SQL上。
Spark SQL允许开发人员直接处理RDD,同时也可查询例如在 Apache Hive上存在的外部数据。Spark SQL的一个重要特点是其能够统一处理关系表和RDD,使得开发人员可以轻松地使用SQL命令进行外部查询,同时进行更复杂的数据分析。除了Spark SQL外,Michael还谈到Catalyst优化框架,它允许Spark SQL自动修改查询方案,使SQL更有效地执行。
还有Shark的作者是来自中国的博士生辛湜(Reynold Xin),也是Spark的核心成员,具体信息可以看他的专访 http://www.csdn.net/article/2013-04-26/2815057-Spark-Reynold
Spark SQL的特点:
l引入了新的RDD类型SchemaRDD,可以象传统数据库定义表一样来定义SchemaRDD,SchemaRDD由定义了列数据类型的行对象构成。SchemaRDD可以从RDD转换过来,也可以从Parquet文件读入,也可以使用HiveQL从Hive中获取。
l内嵌了Catalyst查询优化框架,在把SQL解析成逻辑执行计划之后,利用Catalyst包里的一些类和接口,执行了一些简单的执行计划优化,最后变成RDD的计算
l在应用程序中可以混合使用不同来源的数据,如可以将来自HiveQL的数据和来自SQL的数据进行Join操作。
Shark的出现使得SQL-on-Hadoop的性能比Hive有了10-100倍的提高, 那么,摆脱了Hive的限制,SparkSQL的性能又有怎么样的表现呢?虽然没有Shark相对于Hive那样瞩目地性能提升,但也表现得非常优异,如下图所示:
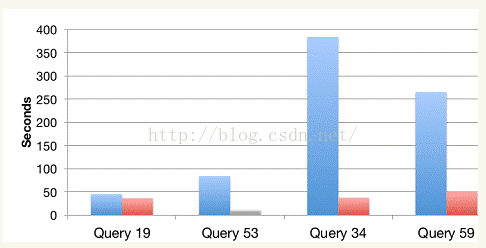
为什么sparkSQL的性能会得到怎么大的提升呢?主要sparkSQL在下面几点做了优化:
1. 内存列存储(In-Memory Columnar Storage) sparkSQL的表数据在内存中存储不是采用原生态的JVM对象存储方式,而是采用内存列存储;
2. 字节码生成技术(Bytecode Generation) Spark1.1.0在Catalyst模块的expressions增加了codegen模块,使用动态字节码生成技术,对匹配的表达式采用特定的代码动态编译。另外对SQL表达式都作了CG优化, CG优化的实现主要还是依靠Scala2.10的运行时放射机制(runtime reflection);
3. Scala代码优化 SparkSQL在使用Scala编写代码的时候,尽量避免低效的、容易GC的代码;尽管增加了编写代码的难度,但对于用户来说接口统一。
2.请详细阐述Spark的几个主要概念及相互关系:RDD,DAG,Application, job,stage,task,Master, worker, driver,executor,Claster Manager
RDD:弹性分布式数据集,是分布式内存的一个抽象概念,提供了一种高度受限的共享内存模型。
DAG:有向无环图,反映RDD之间的依赖关系。
Application应用:用户编写的Spark应用程序job。
Job作业:一个作业包含多个RDD及作用于相应RDD上的各种操作。
Stage阶段:是作业的基本调度单位,每个作业会因为RDD之间的依赖关系拆分成多组任务集合TaskSet,称为调度阶段。调度阶段的划分是由DAGScheduler来划分的,有Shuffle Map Stage和Resuit Stage两种。
Task任务:分发到Executor上的工作任务,是spark实际执行应用的最小单元。
Master:主控节点,顾名思义,类似于领导者,在整个集群中,最多只有一个Master处于Active状态。
Worker:根据Cluster Manager的指令分配资源,执行应用程序,释放资源。
Driver:提交了应用之后,便会启动一个对应的 driver 进程。driver 进程就是应用的 main()函数,并且构建 SparkContext 对象。向Manger申请应用所需的资源,启动Executor,向Executor发送代码和文件。
Executor:进程宿主在worker节点上,一个 worker 可以有多个executor ,负责运行任务Task
- 每个 executor 持有一个线程池,每个线程可以执行一个 task,并将结果返回给 Driver 。
- 块管理器Block Manager,为RDD 提供内存存储(内存+磁盘)
Claster Manager:集群资源管理器,自带的或Mesos或YARN,负责申请和管理在Worker Node上运行应用所需的资源。
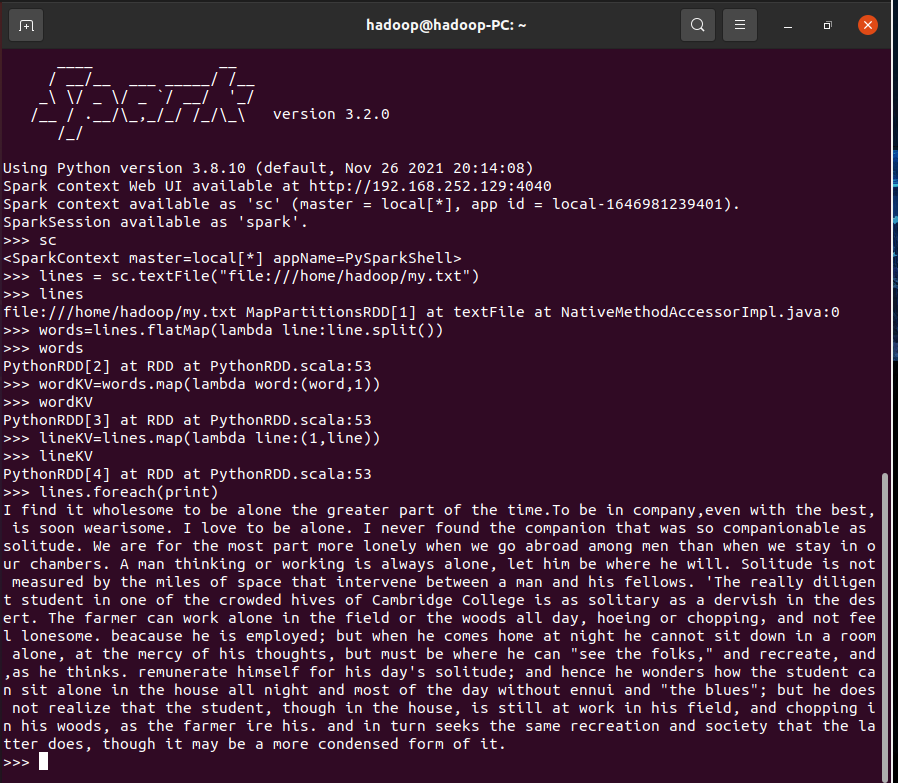
3.在PySparkShell尝试以下代码,观察执行结果,理解sc,RDD,DAG。请画出相应的RDD转换关系图。
>>> sc
>>> lines = sc.textFile("file:///home/hadoop/my.txt")
>>> lines
>>> words=lines.flatMap(lambda line:line.split())
>>> words
>>> wordKV=words.map(lambda word:(word,1))
>>> wordKV
>>> lineKV=lines.map(lambda line:(1,line))
>>> lineKV
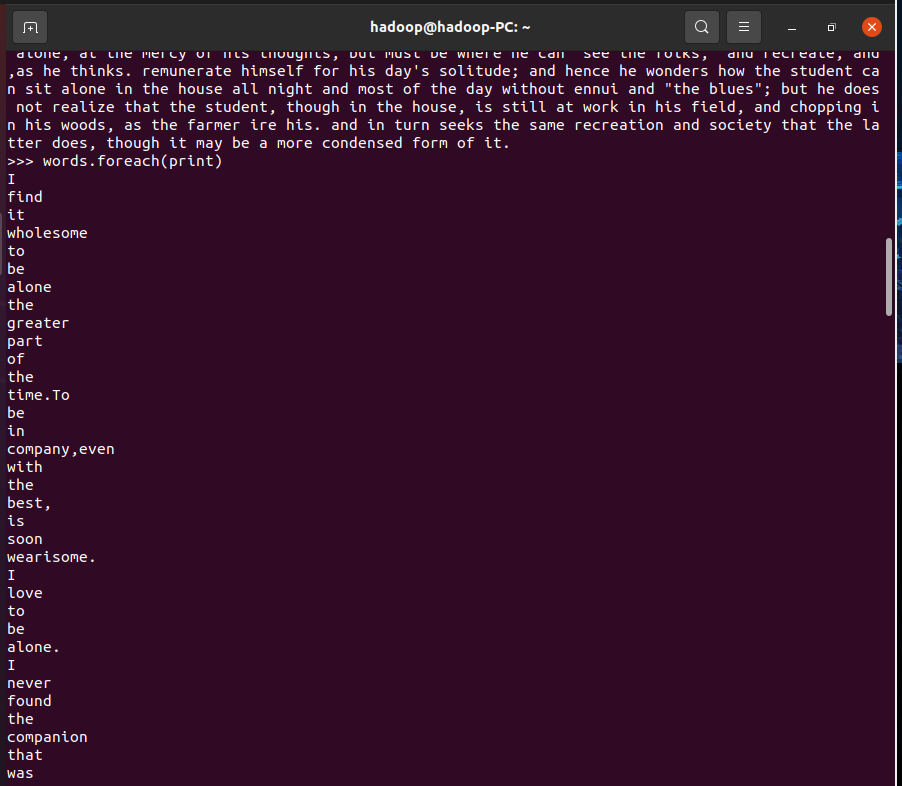
>>> lines.foreach(print)
>>> words.foreach(print)
>>>wordKV.foreach(print)
>>>lineKV.foreach(print)

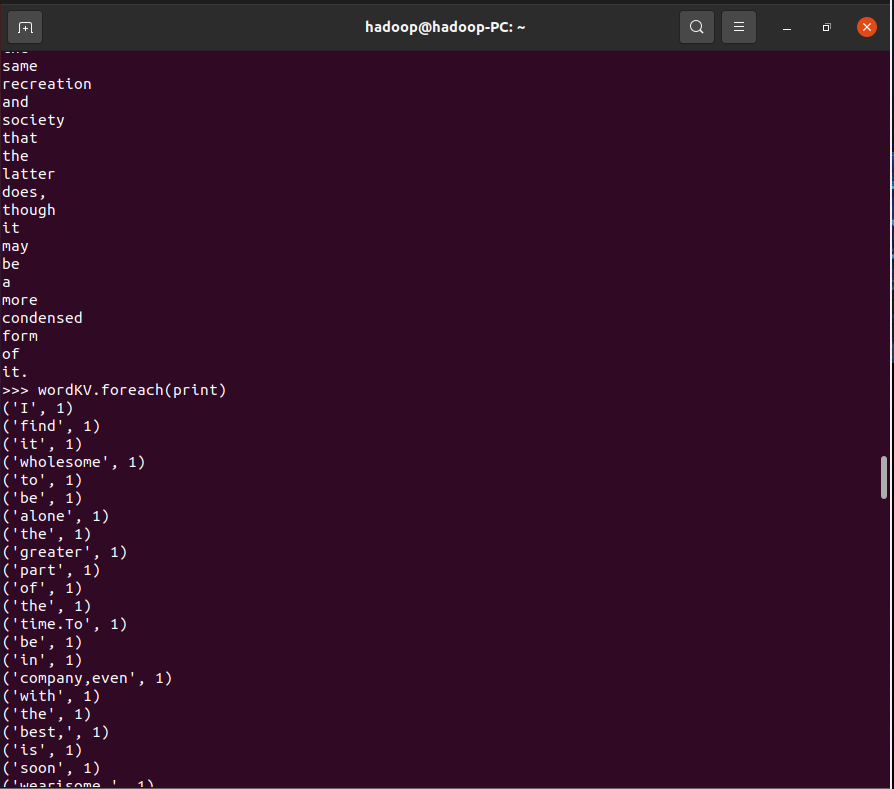
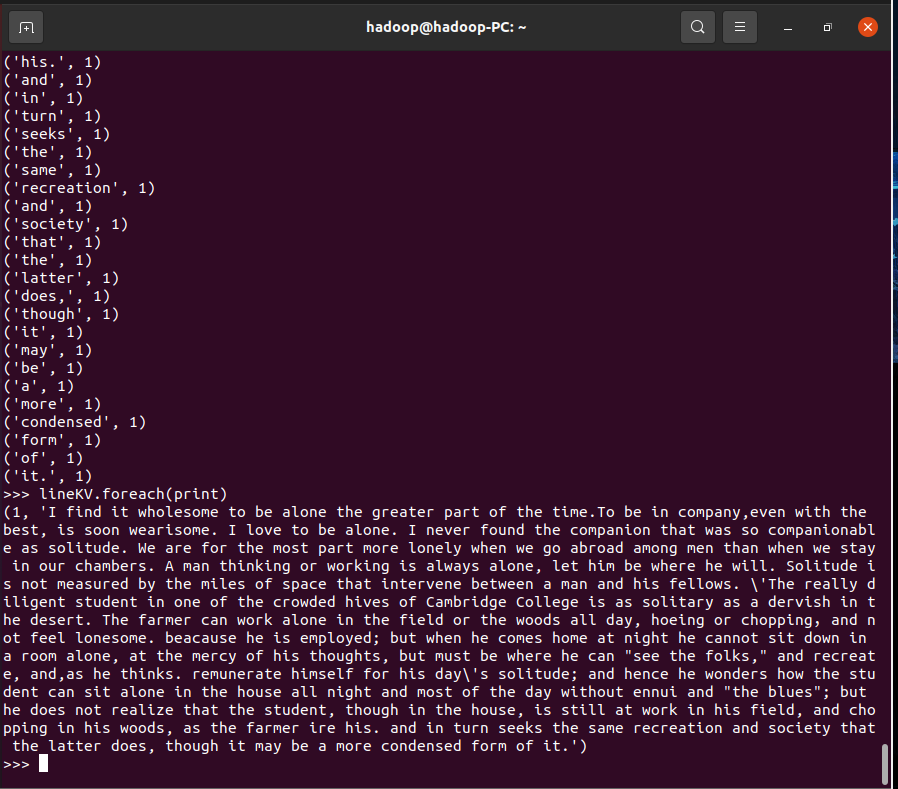
RDD转换关系图:


