18 张图,一文了解 8 种常见的数据结构
前几天和敖丙交流,他说我们写作的人都是在不停地燃烧自己,所以需要不停地补充燃料。对于他的观点,我不能再苟同了——所以我开始狂补计算机方面的基础知识,这其中就包括我相对薄弱的数据结构。
请肆无忌惮地点赞吧,微信搜索【沉默王二】关注这个在十三朝古都洛阳苟且偷生的程序员。
本文 GitHub github.com/itwanger 已收录,里面还有我精心为你准备的一线大厂面试题。
百度百科对数据结构的定义是:相互之间存在一种或多种特定关系的数据元素的集合。定义很抽象,需要大声地朗读几遍,才有点感觉。怎么让这种感觉来得更强烈,更亲切一些呢?我来列举一下常见的 8 种数据结构,数组、链表、栈、队列、树、堆、图、哈希表。
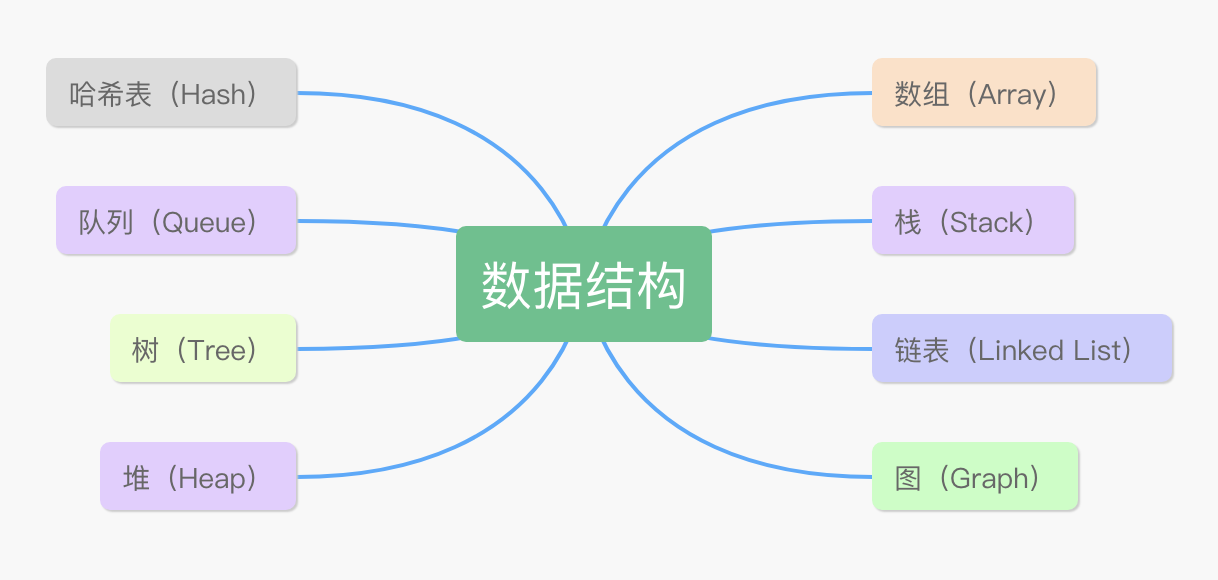
这 8 种数据结构有什么区别呢?
①、数组
优点:
- 按照索引查询元素的速度很快;
- 按照索引遍历数组也很方便。
缺点:
- 数组的大小在创建后就确定了,无法扩容;
- 数组只能存储一种类型的数据;
- 添加、删除元素的操作很耗时间,因为要移动其他元素。
②、链表
《算法(第 4 版)》一书中是这样定义链表的:
链表是一种递归的数据结构,它或者为空(null),或者是指向一个结点(node)的引用,该节点还有一个元素和一个指向另一条链表的引用。
Java 的 LinkedList 类可以很形象地通过代码的形式来表示一个链表的结构:
public class LinkedList<E> {
transient Node<E> first;
transient Node<E> last;
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
}
这是一种双向链表,当前元素 item 既有 prev 又有 next,不过 first 的 prev 为 null,last 的 next 为 null。如果是单向链表的话,就只有 next,没有 prev。
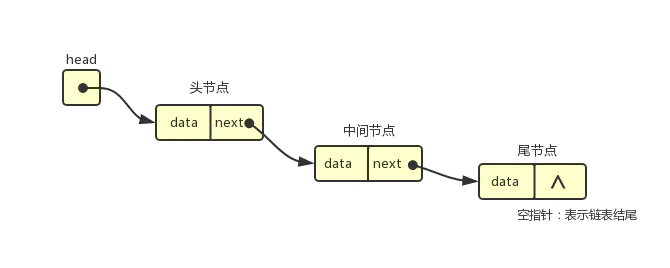
单向链表的缺点是只能从头到尾依次遍历,而双向链表可进可退,既能找到下一个,也能找到上一个——每个节点上都需要多分配一个存储空间。
链表中的数据按照“链式”的结构存储,因此可以达到内存上非连续的效果,数组必须是一块连续的内存。
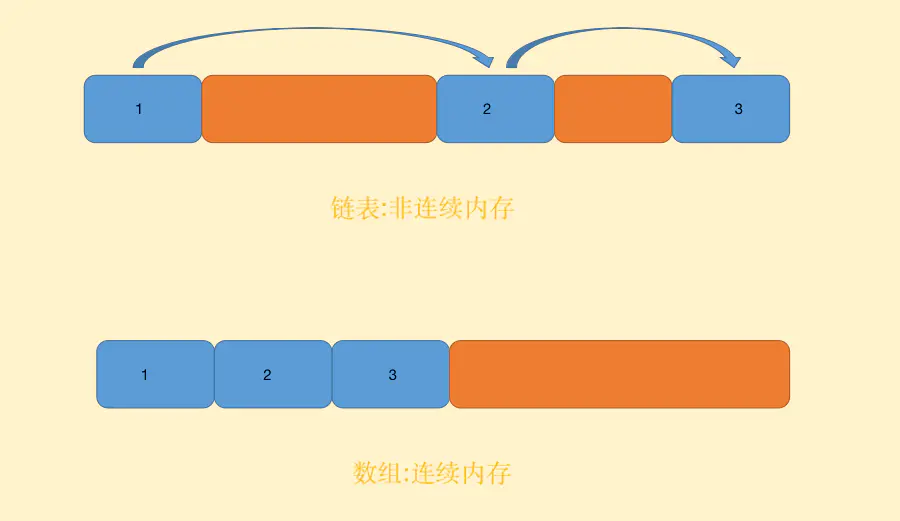
由于不必按照顺序的方式存储,链表在插入、删除的时候可以达到 O(1) 的时间复杂度(只需要重新指向引用即可,不需要像数组那样移动其他元素)。除此之外,链表还克服了数组必须预先知道数据大小的缺点,从而可以实现灵活的内存动态管理。
优点:
- 不需要初始化容量;
- 可以添加任意元素;
- 插入和删除的时候只需要更新引用。
缺点:
- 含有大量的引用,占用的内存空间大;
- 查找元素需要遍历整个链表,耗时。
③、栈
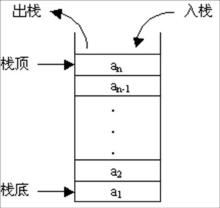
栈就好像水桶一样,底部是密封的,顶部是开口,水可以进可以出。用过水桶的小伙伴应该明白这样一个道理:先进去的水在桶的底部,后进去的水在桶的顶部;后进去的水先被倒出来,先进去的水后被倒出来。
同理,栈按照“后进先出”、“先进后出”的原则来存储数据,先插入的数据被压入栈底,后插入的数据在栈顶,读出数据的时候,从栈顶开始依次读出。
④、队列
队列就好像一段水管一样,两端都是开口的,水从一端进去,然后从另外一端出来。先进去的水先出来,后进去的水后出来。
和水管有些不同的是,队列会对两端进行定义,一端叫队头,另外一端就叫队尾。队头只允许删除操作(出队),队尾只允许插入操作(入队)。
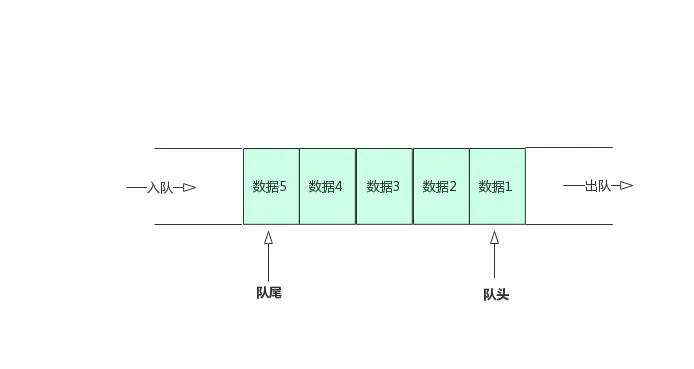
注意,栈是先进后出,队列是先进先出——两者虽然都是线性表,但原则是不同的,结构不一样嘛。
⑤、树
树是一种典型的非线性结构,它是由 n(n>0)个有限节点组成的一个具有层次关系的集合。
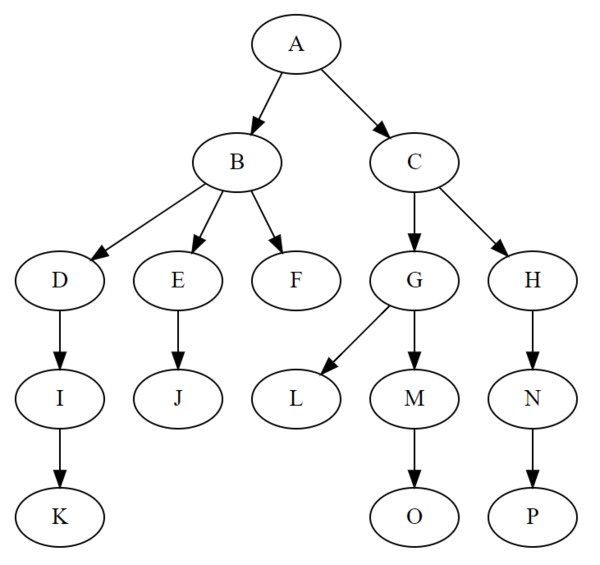
之所以叫“树”,是因为这种数据结构看起来就像是一个倒挂的树,只不过根在上,叶在下。树形数据结构有以下这些特点:
- 每个节点都只有有限个子节点或无子节点;
- 没有父节点的节点称为根节点;
- 每一个非根节点有且只有一个父节点;
- 除了根节点外,每个子节点可以分为多个不相交的子树。
下图展示了树的一些术语:
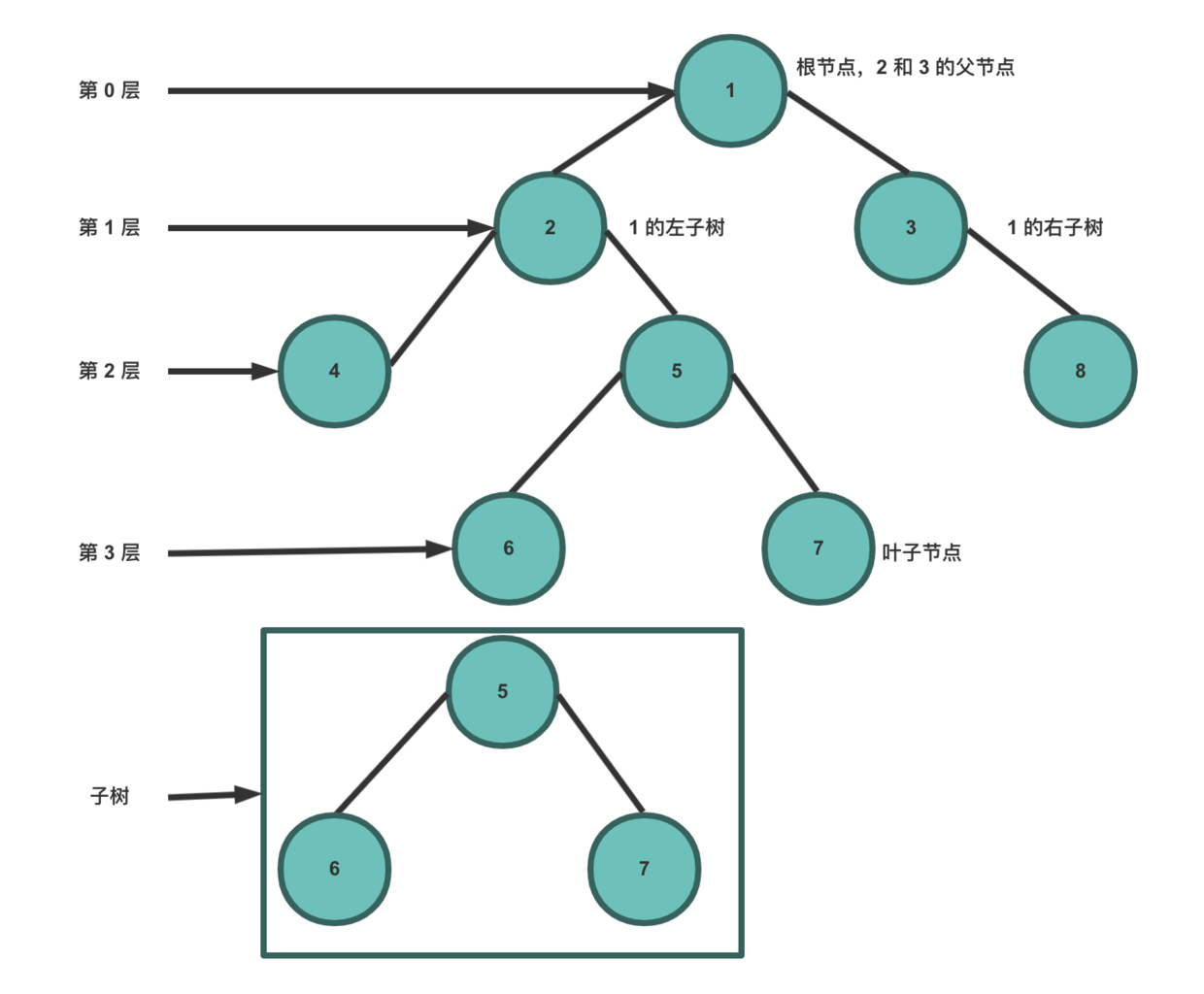
根节点是第 0 层,它的子节点是第 1 层,子节点的子节点为第 2 层,以此类推。
- 深度:对于任意节点 n,n 的深度为从根到 n 的唯一路径长,根的深度为 0。
- 高度:对于任意节点 n,n 的高度为从 n 到一片树叶的最长路径长,所有树叶的高度为 0。
树的种类有很多种,常见的有:
- 无序树:树中任意节点的子节点之间没有顺序关系。那怎么来理解无序树呢,到底长什么样子?
假如有三个节点,一个是父节点,两个是同级的子节点,那么就有三种情况:
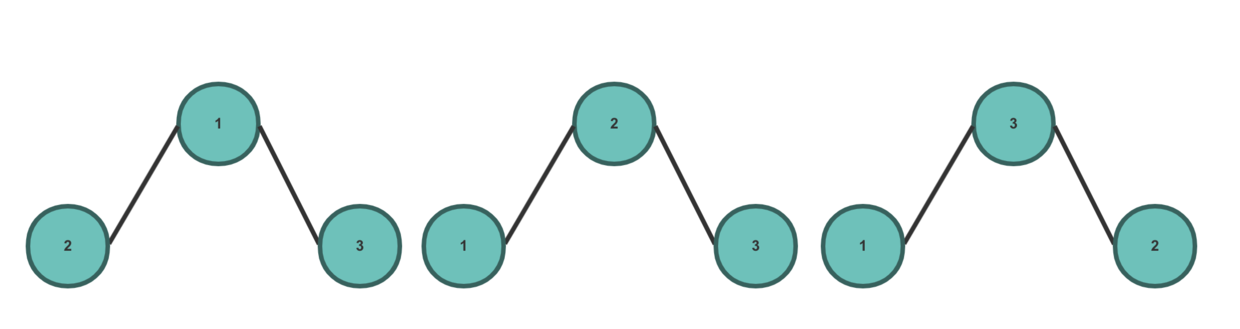
假如有三个节点,一个是父节点,两个是不同级的子节点,那么就有六种情况:
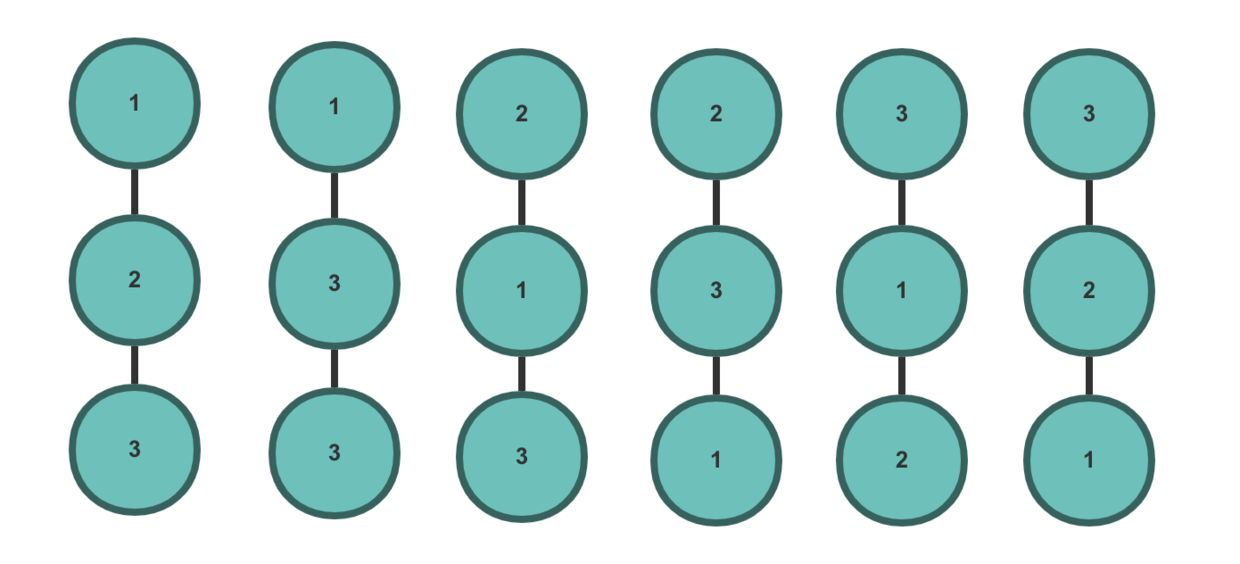
三个节点组成的无序树,合起来就是九种情况。
- 二叉树:每个节点最多含有两个子树。二叉树按照不同的表现形式又可以分为多种。
完全二叉树:对于一颗二叉树,假设其深度为 d(d > 1)。除了第 d 层,其它各层的节点数目均已达最大值,且第 d 层所有节点从左向右连续地紧密排列,这样的二叉树被称为完全二叉树。
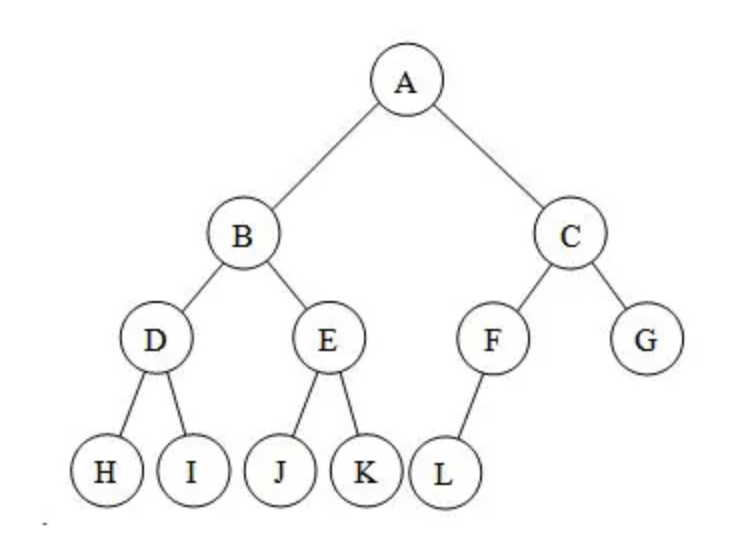
拿上图来说,d 为 3,除了第 3 层,第 1 层、第 2 层 都达到了最大值(2 个子节点),并且第 3 层的所有节点从左向右联系地紧密排列(H、I、J、K、L),符合完全二叉树的要求。
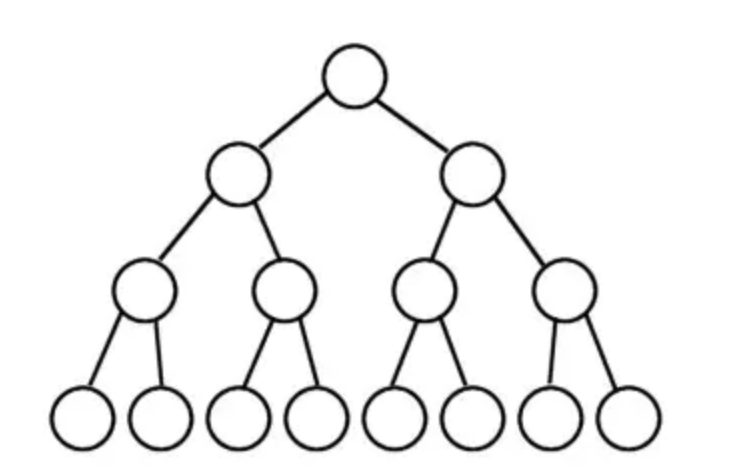
满二叉树:一颗每一层的节点数都达到了最大值的二叉树。有两种表现形式,第一种,像下图这样(每一层都是满的),满足每一层的节点数都达到了最大值 2。
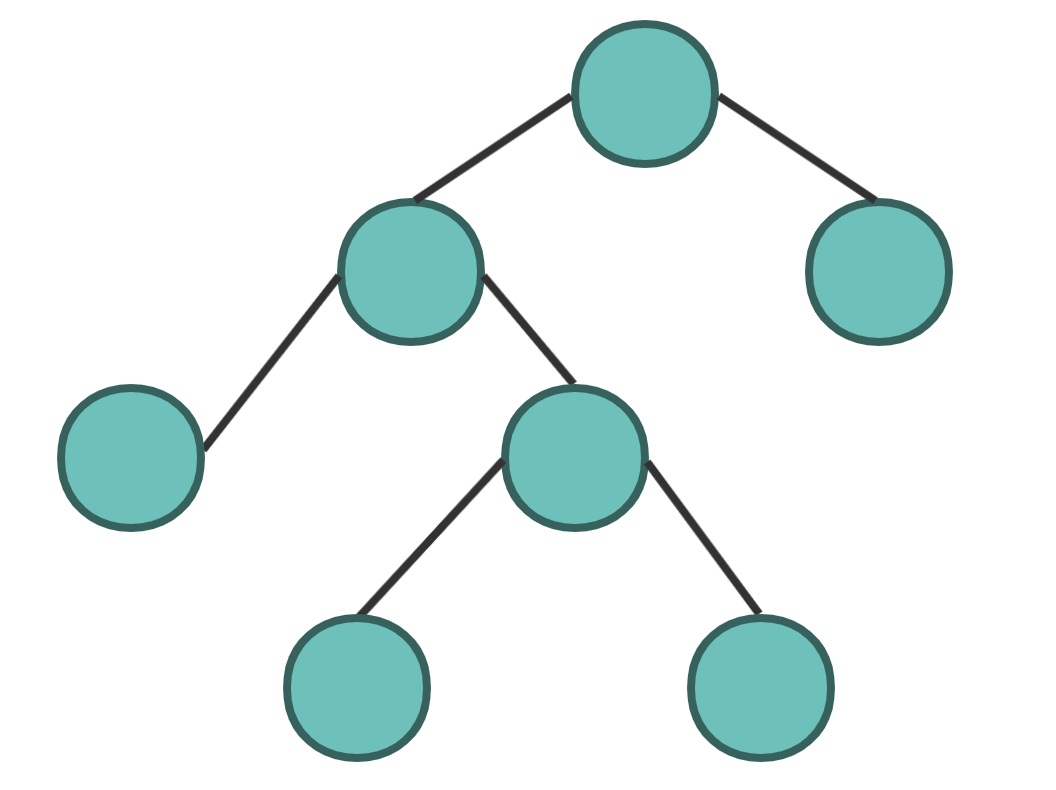
第二种,像下图这样(每一层虽然不满),但每一层的节点数仍然达到了最大值 2。
二叉查找树:英文名叫 Binary Search Tree,即 BST,需要满足以下条件:
- 任意节点的左子树不空,左子树上所有节点的值均小于它的根节点的值;
- 任意节点的右子树不空,右子树上所有节点的值均大于它的根节点的值;
- 任意节点的左、右子树也分别为二叉查找树。
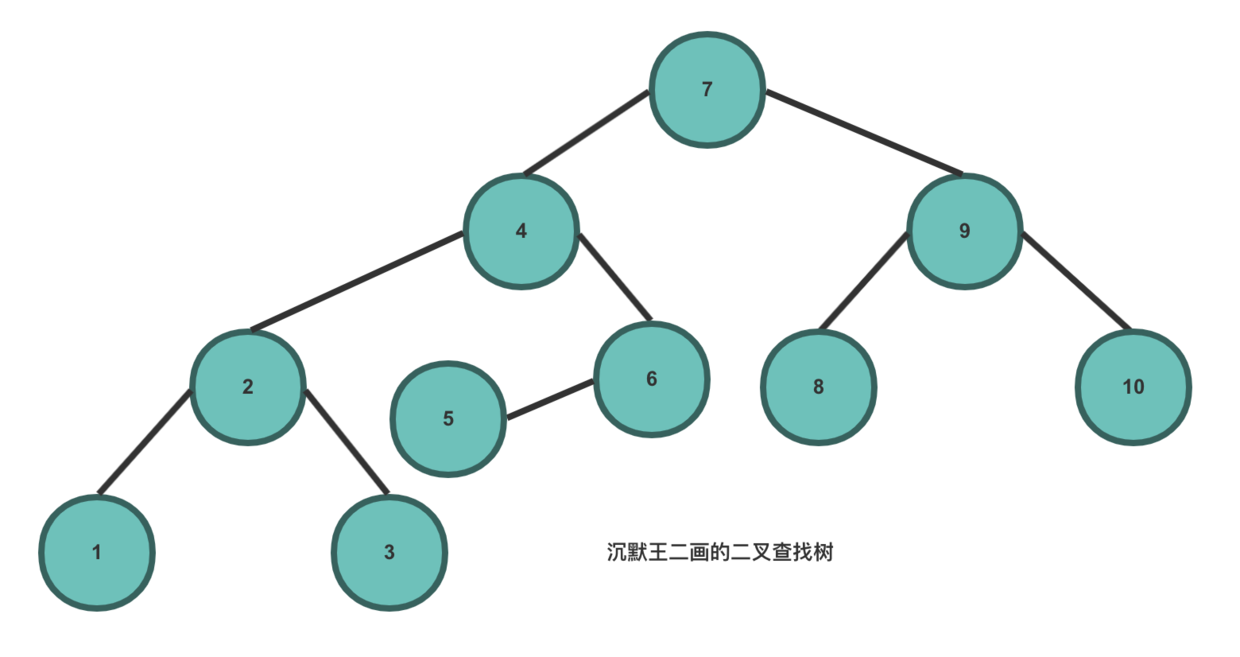
基于二叉查找树的特点,它相比较于其他数据结构的优势就在于查找、插入的时间复杂度较低,为 O(logn)。假如我们要从上图中查找 5 个元素,先从根节点 7 开始找,5 必定在 7 的左侧,找到 4,那 5 必定在 4 的右侧,找到 6,那 5 必定在 6 的左侧,找到了。
理想情况下,通过 BST 查找节点,所需要检查的节点数可以减半。
平衡二叉树:当且仅当任何节点的两棵子树的高度差不大于 1 的二叉树。由前苏联的数学家 Adelse-Velskil 和 Landis 在 1962 年提出的高度平衡的二叉树,根据科学家的英文名也称为 AVL 树。
平衡二叉树本质上也是一颗二叉查找树,不过为了限制左右子树的高度差,避免出现倾斜树等偏向于线性结构演化的情况,所以对二叉搜索树中每个节点的左右子树作了限制,左右子树的高度差称之为平衡因子,树中每个节点的平衡因子绝对值不大于 1。
平衡二叉树的难点在于,当删除或者增加节点的情况下,如何通过左旋或者右旋的方式来保持左右平衡。
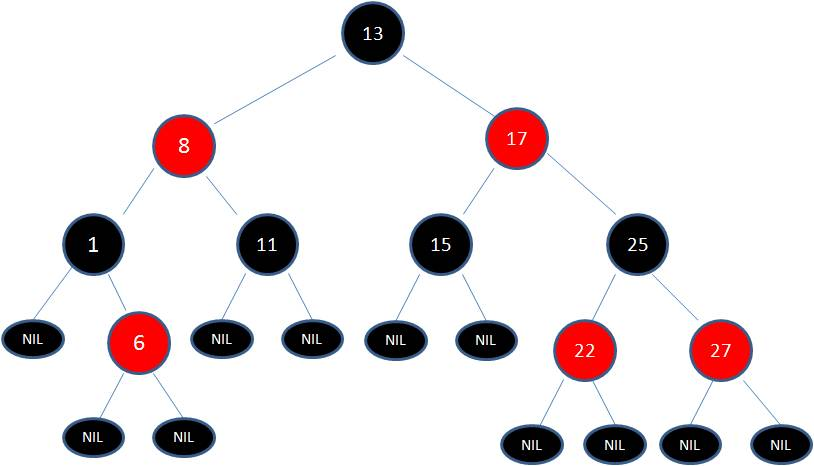
Java 中最常见的平衡二叉树就是红黑树,节点是红色或者黑色,通过颜色的约束来维持着二叉树的平衡:
1)每个节点都只能是红色或者黑色
2)根节点是黑色
3)每个叶节点(NIL 节点,空节点)是黑色的。
4)如果一个节点是红色的,则它两个子节点都是黑色的。也就是说在一条路径上不能出现相邻的两个红色节点。
5)从任一节点到其每个叶子的所有路径都包含相同数目的黑色节点。
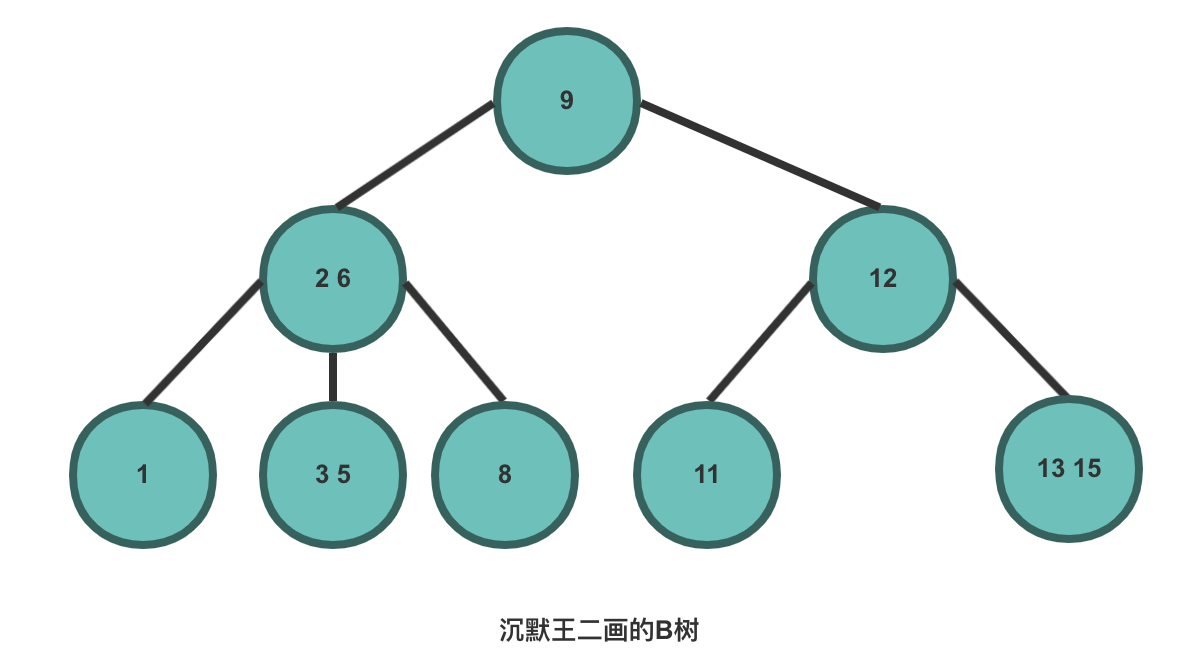
- B 树:一种对读写操作进行优化的自平衡的二叉查找树,能够保持数据有序,拥有多于两个的子树。数据库的索引技术里就用到了 B 树。
⑥、堆
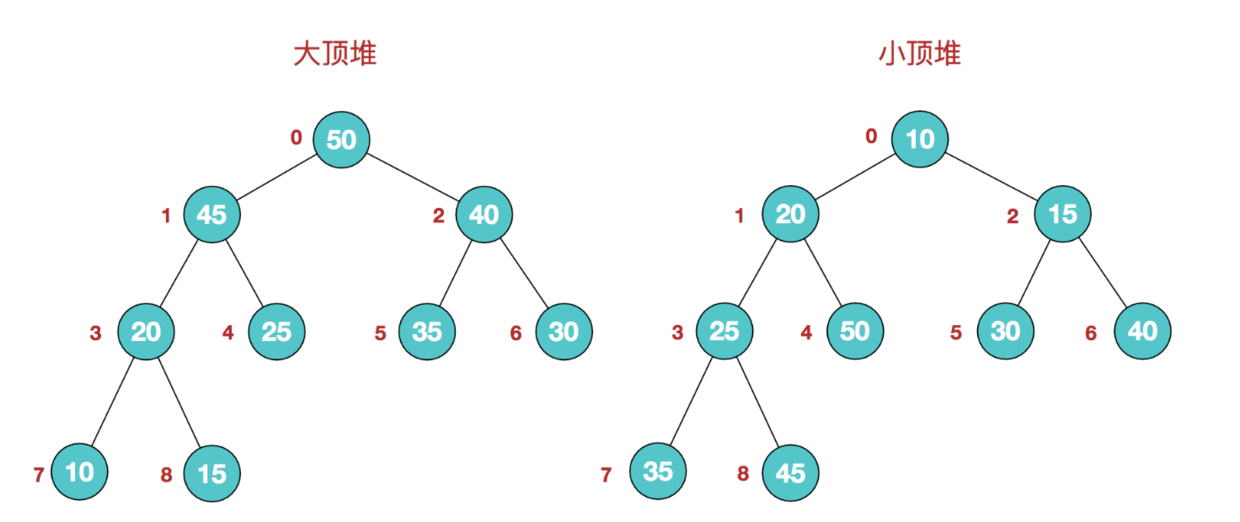
堆可以被看做是一棵树的数组对象,具有以下特点:
- 堆中某个节点的值总是不大于或不小于其父节点的值;
- 堆总是一棵完全二叉树。
将根节点最大的堆叫做最大堆或大根堆,根节点最小的堆叫做最小堆或小根堆。
⑦、图
图是一种复杂的非线性结构,由顶点的有穷非空集合和顶点之间边的集合组成,通常表示为:G(V,E),其中,G 表示一个图,V 是图 G 中顶点的集合,E 是图 G 中边的集合。
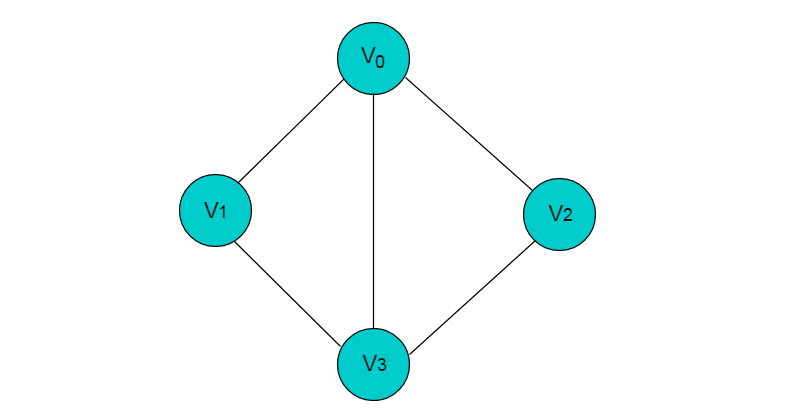
上图共有 V0,V1,V2,V3 这 4 个顶点,4 个顶点之间共有 5 条边。
在线性结构中,数据元素之间满足唯一的线性关系,每个数据元素(除第一个和最后一个外)均有唯一的“前驱”和“后继”;
在树形结构中,数据元素之间有着明显的层次关系,并且每个数据元素只与上一层中的一个元素(父节点)及下一层的多个元素(子节点)相关;
而在图形结构中,节点之间的关系是任意的,图中任意两个数据元素之间都有可能相关。
⑧、哈希表
哈希表(Hash Table),也叫散列表,是一种可以通过关键码值(key-value)直接访问的数据结构,它最大的特点就是可以快速实现查找、插入和删除。
数组的最大特点就是查找容易,插入和删除困难;而链表正好相反,查找困难,而插入和删除容易。哈希表很完美地结合了两者的优点, Java 的 HashMap 在此基础上还加入了树的优点。
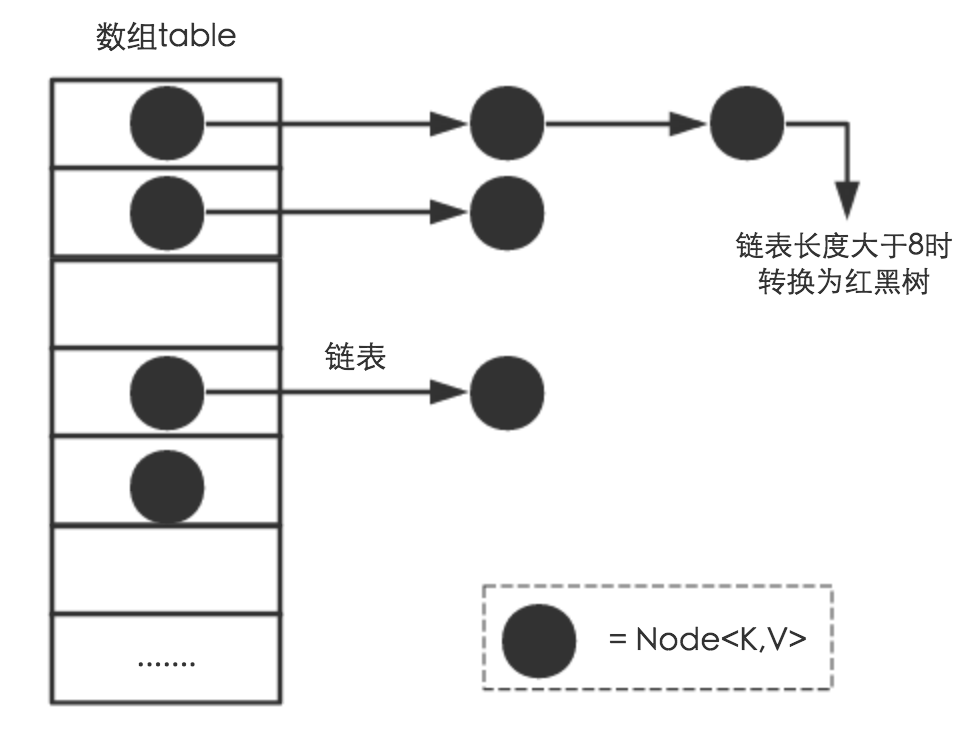
哈希函数在哈希表中起着⾮常关键的作⽤,它可以把任意长度的输入变换成固定长度的输出,该输出就是哈希值。哈希函数使得一个数据序列的访问过程变得更加迅速有效,通过哈希函数,数据元素能够被很快的进行定位。
若关键字为 k,则其值存放在 hash(k) 的存储位置上。由此,不需要遍历就可以直接取得 k 对应的值。
对于任意两个不同的数据块,其哈希值相同的可能性极小,也就是说,对于一个给定的数据块,找到和它哈希值相同的数据块极为困难。再者,对于一个数据块,哪怕只改动它的一个比特位,其哈希值的改动也会非常的大——这正是 Hash 存在的价值!
尽管可能性极小,但仍然会发生,如果哈希冲突了,Java 的 HashMap 会在数组的同一个位置上增加链表,如果链表的长度大于 8,将会转化成红黑树进行处理——这就是所谓的拉链法(数组+链表)。
说句实在话,照这个进度恶补下去,我感觉要秃的节奏,不过,如果能够变得更强,值了——对,值了。
我是沉默王二,一枚沉默但有趣的程序员,关注即可提升学习效率。喜欢这篇文章的小伙伴,请不要忘记四联啊,点赞、收藏、转发、留言,你最美你最帅!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号