
2.3、python数据类型的介绍
数据类型的介绍
什么是数字类型:

数字类型的分类:
Python3 中有六个标准的数据类型:
- Number(数字)
- String(字符串)
- List(列表)
- Tuple(元组)
- Set(集合)
- Dictionary(字典)
Python3 的六个标准数据类型中:
- 不可变数据(3 个):Number(数字)、String(字符串)、Tuple(元组);
- 可变数据(3 个):List(列表)、Dictionary(字典)、Set(集合)。
字符串(Str)
定义:字符串是一个有序的字符的集合,用于存储和表示基本的文本信息,Python中的字符串用单引号 ' 或双引号 " 括起来来创建字符串,同时可以用反斜杠 \ 转义特殊字符。
name='egon'
#说明:在Python3中,所有的字符串都是Unicode字符串,Python 不支持单字符类型,单字符在 Python 中也是作为一个字符串使用。
取值:
索引值以 0 为开始值,-1 为从末尾的开始位置。

例1:
str = 'Runoob'
print (str) # 输出字符串 Runoob
print (str[0:-1]) # 输出第一个到倒数第二个的所有字符 Runoo
print (str[0]) # 输出字符串第一个字符 R
print (str[2:5]) # 输出从第三个开始到第五个的字符 noo
print (str[2:]) # 输出从第三个开始的后的所有字符 noob
print (str * 2) # 输出字符串两次 RunoobRunoob
print (str + "TEST") # 连接字符串 RunoobTEST
例2:
word = 'Python'
print(word[0], word[5]) # 结果 P n
print(word[-1], word[-6]) # 结果 n P
补充:
Python 使用反斜杠(\)转义特殊字符,如果你不想让反斜杠发生转义,可以在字符串前面添加一个 r,表示原始字符串:
print('Ru\noob')
结果:
Ru
oob
print(r'Ru\noob') #结果 Ru\noob
另外,反斜杠(\)可以作为续行符,表示下一行是上一行的延续。也可以使用 """...""" 或者 '''...''' 跨越多行。
注意,Python 没有单独的字符类型,一个字符就是长度为1的字符串。
字符串拼接:
加号 + 是字符串的连接符, 星号 * 表示复制当前字符串,紧跟的数字为复制的次数。实例如下:


字符串的格式化输出
Python的字符串格式化有两种方式: 百分号方式、format方式
百分号方式:


格式: %[(name)][flags][width].[precision]typecode 参数: (name) 可选,用于选择指定的key flags 可选,可供选择的值有: + 右对齐;正数前加正好,负数前加负号 - 左对齐;正数前无符号,负数前加负号; 空格 右对齐;正数前加空格,负数前加负号; 0 右对齐;正数前无符号,负数前加负号;用0填充空白处 width 可选,占有宽度 precision 可选,小数点后保留的位数 typecode 必选,可供选择的值有: s,获取传入对象的__str__方法的返回值,并将其格式化到指定位置 r,获取传入对象的__repr__方法的返回值,并将其格式化到指定位置 c,整数:将数字转换成其unicode对应的值,10进制范围为 0 <= i <= 1114111(py27则只支持0-255);字符:将字符添加到指定位置 o,将整数转换成 八 进制表示,并将其格式化到指定位置 x,将整数转换成十六进制表示,并将其格式化到指定位置 d,将整数、浮点数转换成 十 进制表示,并将其格式化到指定位置 e,将整数、浮点数转换成科学计数法,并将其格式化到指定位置(小写e) E,将整数、浮点数转换成科学计数法,并将其格式化到指定位置(大写E) f, 将整数、浮点数转换成浮点数表示,并将其格式化到指定位置(默认保留小数点后6位) F,同上 g,自动调整将整数、浮点数转换成 浮点型或科学计数法表示(超过6位数用科学计数法),并将其格式化到指定位置(如果是科学计数则是e;) G,自动调整将整数、浮点数转换成 浮点型或科学计数法表示(超过6位数用科学计数法),并将其格式化到指定位置(如果是科学计数则是E;) %,当字符串中存在格式化标志时,需要用 %%表示一个百分号 注:Python中百分号格式化是不存在自动将整数转换成二进制表示的方式 常用格式化: tpl = "i am %s" % "alex" tpl = "i am %s age %d" % ("alex", 18) tpl = "i am %(name)s age %(age)d" % {"name": "alex", "age": 18} tpl = "percent %.2f" % 99.97623 tpl = "i am %(pp).2f" % {"pp": 123.425556, } tpl = "i am %.2f %%" % {"pp": 123.425556, }
format方式:
语法: [[fill]align][sign][#][0][width][,][.precision][type] 参数: fill 【可选】空白处填充的字符 align 【可选】对齐方式(需配合width使用) <,内容左对齐 >,内容右对齐(默认) =,内容右对齐,将符号放置在填充字符的左侧,且只对数字类型有效。 即使:符号+填充物+数字 ^,内容居中 sign 【可选】有无符号数字 +,正号加正,负号加负; -,正号不变,负号加负; 空格 ,正号空格,负号加负; # 【可选】对于二进制、八进制、十六进制,如果加上#,会显示 0b/0o/0x,否则不显示 , 【可选】为数字添加分隔符,如:1,000,000 width 【可选】格式化位所占宽度 .precision 【可选】小数位保留精度 type 【可选】格式化类型 传入” 字符串类型 “的参数 s,格式化字符串类型数据 空白,未指定类型,则默认是None,同s 传入“ 整数类型 ”的参数 b,将10进制整数自动转换成2进制表示然后格式化 c,将10进制整数自动转换为其对应的unicode字符 d,十进制整数 o,将10进制整数自动转换成8进制表示然后格式化; x,将10进制整数自动转换成16进制表示然后格式化(小写x) X,将10进制整数自动转换成16进制表示然后格式化(大写X) 传入“ 浮点型或小数类型 ”的参数 e, 转换为科学计数法(小写e)表示,然后格式化; E, 转换为科学计数法(大写E)表示,然后格式化; f , 转换为浮点型(默认小数点后保留6位)表示,然后格式化; F, 转换为浮点型(默认小数点后保留6位)表示,然后格式化; g, 自动在e和f中切换 G, 自动在E和F中切换 %,显示百分比(默认显示小数点后6位) 常用格式化: tpl = "i am {}, age {}, {}".format("seven", 18, 'alex') tpl = "i am {}, age {}, {}".format(*["seven", 18, 'alex']) tpl = "i am {0}, age {1}, really {0}".format("seven", 18) tpl = "i am {0}, age {1}, really {0}".format(*["seven", 18]) tpl = "i am {name}, age {age}, really {name}".format(name="seven", age=18) tpl = "i am {name}, age {age}, really {name}".format(**{"name": "seven", "age": 18}) tpl = "i am {0[0]}, age {0[1]}, really {0[2]}".format([1, 2, 3], [11, 22, 33]) tpl = "i am {:s}, age {:d}, money {:f}".format("seven", 18, 88888.1) tpl = "i am {:s}, age {:d}".format(*["seven", 18]) tpl = "i am {name:s}, age {age:d}".format(name="seven", age=18) tpl = "i am {name:s}, age {age:d}".format(**{"name": "seven", "age": 18}) tpl = "numbers: {:b},{:o},{:d},{:x},{:X}, {:%}".format(15, 15, 15, 15, 15, 15.87623, 2) tpl = "numbers: {:b},{:o},{:d},{:x},{:X}, {:%}".format(15, 15, 15, 15, 15, 15.87623, 2) tpl = "numbers: {0:b},{0:o},{0:d},{0:x},{0:X}, {0:%}".format(15) tpl = "numbers: {num:b},{num:o},{num:d},{num:x},{num:X}, {num:%}".format(num=15)
字符串的运算符:
下表实例变量a值为字符串 "Hello",b变量值为 "Python":
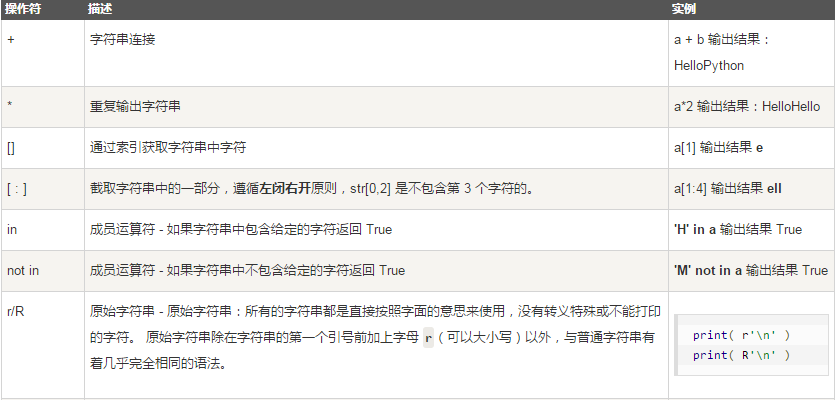
#!/usr/bin/python3
a = "Hello"
b = "Python"
print("a + b 输出结果:", a + b)
print("a * 2 输出结果:", a * 2)
print("a[1] 输出结果:", a[1])
print("a[1:4] 输出结果:", a[1:4])
if( "H" in a) :
print("H 在变量 a 中")
else :
print("H 不在变量 a 中")
if( "M" not in a) :
print("M 不在变量 a 中")
else :
print("M 在变量 a 中")
print (r'\n')
print (R'\n')
结果:
a + b 输出结果: HelloPython
a * 2 输出结果: HelloHello
a[1] 输出结果: e
a[1:4] 输出结果: ell
H 在变量 a 中
M 不在变量 a 中
\n
\n
python的字符串内建函数:
1、capitalize():将字符串的第一个字母变成大写,其他字母变小写。
语法:
str.capitalize()
参数:
无
实例:
#!/usr/bin/python3
str = "this is string example from runoob....wow!!!"
print ("str.capitalize() : ", str.capitalize())
结果:
str.capitalize() : This is string example from runoob....wow!!!
2、center(width, fillchar):方法返回一个指定的宽度 width 居中的字符串,fillchar 为填充的字符,默认为空格。
语法:
str.center(width[, fillchar])
参数:
width -- 字符串的总宽度。
fillchar -- 填充字符。
实列
#!/usr/bin/python3
str = "[www.runoob.com]"
print ("str.center(40, '*') : ", str.center(40, '*'))
结果:
str.center(40, '*') : ************[www.runoob.com]************
3、count(str, beg= 0,end=len(string)):用于统计字符串里某个字符出现的次数。可选参数为在字符串搜索的开始与结束位置。
语法:
str.count(sub, start= 0,end=len(string))
参数:
sub -- 搜索的子字符串
start -- 字符串开始搜索的位置。默认为第一个字符,第一个字符索引值为0。
end -- 字符串中结束搜索的位置。字符中第一个字符的索引为 0。默认为字符串的最后一个位置。
实例:
str="www.runoob.com"
sub='o'
print ("str.count('o') : ", str.count(sub))
sub='run'
print ("str.count('run', 0, 10) : ", str.count(sub,0,10))
打印结果:
str.count('o') : 3
str.count('run', 0, 10) : 1
4、bytes.decode(encoding="utf-8", errors="strict"):指定的编码格式解码 bytes 对象。默认编码为 'utf-8'。
语法:
bytes.decode(encoding="utf-8", errors="strict")
参数:
encoding -- 要使用的编码,如"UTF-8"。
errors -- 设置不同错误的处理方案。默认为 'strict',意为编码错误引起一个UnicodeError。 其他可能得值有 'ignore', 'replace', 'xmlcharrefreplace', 'backslashreplace' 以及通过 codecs.register_error() 注册的任何值。
实列:
str = "菜鸟教程";
str_utf8 = str.encode("UTF-8")
str_gbk = str.encode("GBK")
print(str)
print("UTF-8 编码:", str_utf8)
print("GBK 编码:", str_gbk)
print("UTF-8 解码:", str_utf8.decode('UTF-8','strict'))
print("GBK 解码:", str_gbk.decode('GBK','strict'))
打印结果:
菜鸟教程
UTF-8 编码: b'\xe8\x8f\x9c\xe9\xb8\x9f\xe6\x95\x99\xe7\xa8\x8b'
GBK 编码: b'\xb2\xcb\xc4\xf1\xbd\xcc\xb3\xcc'
UTF-8 解码: 菜鸟教程
GBK 解码: 菜鸟教程
5、encode(): 方法以指定的编码格式编码字符串。errors参数可以指定不同的错误处理方案。
语法:
str.encode(encoding='UTF-8',errors='strict')
参数:
encoding -- 要使用的编码,如: UTF-8。
errors -- 设置不同错误的处理方案。默认为 'strict',意为编码错误引起一个UnicodeError。 其他可能得值有 'ignore', 'replace', 'xmlcharrefreplace', 'backslashreplace' 以及通过 codecs.register_error() 注册的任何值。
实例
#!/usr/bin/python3
str = "菜鸟教程";
str_utf8 = str.encode("UTF-8")
str_gbk = str.encode("GBK")
print(str)
print("UTF-8 编码:", str_utf8)
print("GBK 编码:", str_gbk)
print("UTF-8 解码:", str_utf8.decode('UTF-8','strict'))
print("GBK 解码:", str_gbk.decode('GBK','strict'))
结果:
菜鸟教程
UTF-8 编码: b'\xe8\x8f\x9c\xe9\xb8\x9f\xe6\x95\x99\xe7\xa8\x8b'
GBK 编码: b'\xb2\xcb\xc4\xf1\xbd\xcc\xb3\xcc'
UTF-8 解码: 菜鸟教程
GBK 解码: 菜鸟教程
6、endswith(): 方法用于判断字符串是否以指定后缀结尾,如果以指定后缀结尾返回 True,否则返回 False。可选参数 "start" 与 "end" 为检索字符串的开始与结束位置。
语法:
str.endswith(suffix[, start[, end]])
参数
suffix -- 该参数可以是一个字符串或者是一个元素。
start -- 字符串中的开始位置。
end -- 字符中结束位置。
实例
#!/usr/bin/python3
Str='Runoob example....wow!!!'
suffix='!!'
print (Str.endswith(suffix))
print (Str.endswith(suffix,20))
suffix='run'
print (Str.endswith(suffix))
print (Str.endswith(suffix, 0, 19))
结果
True
True
False
False
7、expandtabs(): 方法把字符串中的 tab 符号('\t')转为空格,tab 符号('\t')默认的空格数是 8。
语法:
str.expandtabs(tabsize=8)
参数:
tabsize -- 指定转换字符串中的 tab 符号('\t')转为空格的字符数。
实列:
#!/usr/bin/python3
str = "this is\tstring example....wow!!!"
print ("原始字符串: " + str)
print ("替换 \\t 符号: " + str.expandtabs())
print ("使用16个空格替换 \\t 符号: " + str.expandtabs(16))
结果:
原始字符串: this is string example....wow!!!
替换 \t 符号: this is string example....wow!!!
使用16个空格替换 \t 符号: this is string example....wow!!!
8、find(str, beg=0, end=len(string)) :方法检测字符串中是否包含子字符串 str ,如果指定 beg(开始) 和 end(结束) 范围,则检查是否包含在指定范围内,如果指定范围内如果包含指定索引值,返回的是索引值在字符串中的起始位置。如果不包含索引值,返回-1。
语法:
str.find(str, beg=0, end=len(string))
参数:
str -- 指定检索的字符串
beg -- 开始索引,默认为0。
end -- 结束索引,默认为字符串的长度。
实列:
#!/usr/bin/python3
str1 = "Runoob example....wow!!!"
str2 = "exam";
print (str1.find(str2))
print (str1.find(str2, 5))
print (str1.find(str2, 10))
结果:
7
7
-1
9、index(): 方法检测字符串中是否包含子字符串 str ,如果指定 beg(开始) 和 end(结束) 范围,则检查是否包含在指定范围内,该方法与 python find()方法一样,只不过如果str不在 string中会报一个异常。
语法:
str.index(str, beg=0, end=len(string))
参数:
str -- 指定检索的字符串
beg -- 开始索引,默认为0。
end -- 结束索引,默认为字符串的长度。
实列:
#!/usr/bin/python3
str1 = "Runoob example....wow!!!"
str2 = "exam";
print (str1.index(str2))
print (str1.index(str2, 5))
print (str1.index(str2, 10))
结果:
7
7
Traceback (most recent call last):
File "test.py", line 8, in <module>
print (str1.index(str2, 10))
ValueError: substring not found
10、isalnum() 如果字符串至少有一个字符并且所有字符都是字母或数字则返 回 True,否则返回 False
语法:
str.isalnum()
参数:
无。
实列:
#!/usr/bin/python3
str = "runoob2016" # 字符串没有空格
print (str.isalnum())
str = "www.runoob.com"
print (str.isalnum())
结果:
True
False
11、isalpha() 如果字符串至少有一个字符并且所有字符都是字母则返回 True, 否则返回 False
语法:
str.isalpha()
参数:
无。
实列:
#!/usr/bin/python3
str = "runoob"
print (str.isalpha())
str = "Runoob example....wow!!!"
print (str.isalpha())
结果:
True
False
12、isdigit() 如果字符串只包含数字则返回 True 否则返回 False..
语法:
str.isdigit()
参数:
无。
实列:
#!/usr/bin/python3
str = "123456";
print (str.isdigit())
str = "Runoob example....wow!!!"
print (str.isdigit())
结果:
True
False
13、islower():如果字符串中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是小写,则返回 True,否则返回 False
islower() 方法检测字符串是否由小写字母组成。
语法:
str.islower()
参数:
无
实列:
#!/usr/bin/python3
str = "RUNOOB example....wow!!!"
print (str.islower())
str = "runoob example....wow!!!"
print (str.islower())
结果:
False
True
14、isnumeric():如果字符串中只包含数字字符,则返回 True,否则返回 False
isnumeric() 方法检测字符串是否只由数字组成。这种方法是只针对unicode对象。
注:定义一个字符串为Unicode,只需要在字符串前添加 'u' 前缀即可
语法
str.isnumeric()
参数
无。
实例
#!/usr/bin/python3
str = "runoob2016"
print (str.isnumeric())
str = "23443434"
print (str.isnumeric())
结果:
False
True
15、isspace():如果字符串中只包含空白,则返回 True,否则返回 False
Python isspace() 方法检测字符串是否只由空白字符组成。
语法:
str.isspace()
参数
无。
实例
#!/usr/bin/python3
str = " "
print (str.isspace())
str = "Runoob example....wow!!!"
print (str.isspace())
结果:
True
False
16、istitle():如果字符串是标题化的(见 title())则返回 True,否则返回 False
istitle() 方法检测字符串中所有的单词拼写首字母是否为大写,且其他字母为小写。
语法
str.istitle()
参数
无。
实例
#!/usr/bin/python3
str = "This Is String Example...Wow!!!"
print (str.istitle())
str = "This is string example....wow!!!"
print (str.istitle())
结果
True
False
17、isupper():如果字符串中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是大写,则返回 True,否则返回 False
isupper() 方法检测字符串中所有的字母是否都为大写。
语法
str.isupper()
参数
无。
实例
#!/usr/bin/python3
str = "THIS IS STRING EXAMPLE....WOW!!!"
print (str.isupper())
str = "THIS is string example....wow!!!"
print (str.isupper())
结果:
True
False
18、join(seq):以指定字符串作为分隔符,将 seq 中所有的元素(的字符串表示)合并为一个新的字符串
Python join() 方法用于将序列中的元素以指定的字符连接生成一个新的字符串。
语法:
str.join(sequence)
参数:
sequence -- 要连接的元素序列。
实例:
s1 = "-"
s2 = ""
seq = ("r", "u", "n", "o", "o", "b") # 字符串序列
print (s1.join( seq ))
print (s2.join( seq ))
结果:
r-u-n-o-o-b
runoob
19、len(string):返回字符串长度
Python len() 方法返回对象(字符、列表、元组等)长度或项目个数。
语法
len( s )
参数
s -- 对象。
实例
>>>str = "runoob"
>>> len(str) # 字符串长度
6
>>> l = [1,2,3,4,5]
>>> len(l) # 列表元素个数
5
20、ljust(width[, fillchar]):返回一个原字符串左对齐,并使用 fillchar 填充至长度 width 的新字符串,fillchar 默认为空格。
ljust() 方法返回一个原字符串左对齐,并使用空格填充至指定长度的新字符串。如果指定的长度小于原字符串的长度则返回原字符串。
语法
str.ljust(width[, fillchar])
参数
width -- 指定字符串长度。
fillchar -- 填充字符,默认为空格。
实例
str = "Runoob example....wow!!!"
print (str.ljust(50, '*'))
结果:
Runoob example....wow!!!**************************
21、ower();转换字符串中所有大写字符为小写.
Python lower() 方法转换字符串中所有大写字符为小写。
语法
str.lower()
参数
无。
实例
#!/usr/bin/python3
str = "Runoob EXAMPLE....WOW!!!"
print( str.lower() )
结果:
runoob example....wow!!!
22、lstrip():截掉字符串左边的空格或指定字符。
lstrip() 方法用于截掉字符串左边的空格或指定字符。
语法
str.lstrip([chars])
参数
chars --指定截取的字符。
实例
str = " this is string example....wow!!! ";
print( str.lstrip() );
str = "88888888this is string example....wow!!!8888888";
print( str.lstrip('8') );
结果:
this is string example....wow!!!
this is string example....wow!!!8888888
23、maketrans():创建字符映射的转换表,对于接受两个参数的最简单的调用方式,第一个参数是字符串,表示需要转换的字符,第二个参数也是字符串表示转换的目标。
maketrans() 方法用于创建字符映射的转换表,对于接受两个参数的最简单的调用方式,第一个参数是字符串,表示需要转换的字符,第二个参数也是字符串表示转换的目标。
两个字符串的长度必须相同,为一一对应的关系。
注:Python3.4 已经没有 string.maketrans() 了,取而代之的是内建函数: bytearray.maketrans()、bytes.maketrans()、str.maketrans() 。
语法
str.maketrans(intab, outtab)
参数
intab -- 字符串中要替代的字符组成的字符串。
outtab -- 相应的映射字符的字符串
实例
intab = "aeiou"
outtab = "12345"
trantab = str.maketrans(intab, outtab)
str = "this is string example....wow!!!"
print (str.translate(trantab))
结果:
th3s 3s str3ng 2x1mpl2....w4w!!!
24、max(str):返回字符串 str 中最大的字母。
max() 方法返回字符串中最大的字母。
语法
max(str)
参数
str -- 字符串。
实例
str = "runoob"
print ("最大字符: " + max(str))
结果:
最大字符: u
25、min(str):返回字符串 str 中最小的字母。
Python min() 方法返回字符串中最小的字母。
语法
min(str)
参数
str -- 字符串。
实例
str = "runoob";
print ("最小字符: " + min(str));
结果:
最小字符: b
26、replace(old, new [, max]):把 将字符串中的 str1 替换成 str2,如果 max 指定,则替换不超过 max 次。
replace() 方法把字符串中的 old(旧字符串) 替换成 new(新字符串),如果指定第三个参数max,则替换不超过 max 次。
语法:
str.replace(old, new[, max])
参数
old -- 将被替换的子字符串。
new -- 新字符串,用于替换old子字符串。
max -- 可选字符串, 替换不超过 max 次
实例
str = "www.w3cschool.cc"
print ("菜鸟教程旧地址:", str)
print ("菜鸟教程新地址:", str.replace("w3cschool.cc", "runoob.com"))
str = "this is string example....wow!!!"
print (str.replace("is", "was", 3))
结果:
菜鸟教程旧地址: www.w3cschool.cc
菜鸟教程新地址: www.runoob.com
thwas was string example....wow!!!
27、rfind(str, beg=0,end=len(string)):类似于 find()函数,不过是从右边开始查找.
Python rfind() 返回字符串最后一次出现的位置,如果没有匹配项则返回-1。
语法
str.rfind(str, beg=0 end=len(string))
参数
str -- 查找的字符串
beg -- 开始查找的位置,默认为0
end -- 结束查找位置,默认为字符串的长度。
实例
str1 = "this is really a string example....wow!!!"
str2 = "is"
print (str1.rfind(str2))
print (str1.rfind(str2, 0, 10))
print (str1.rfind(str2, 10, 0))
print (str1.find(str2))
print (str1.find(str2, 0, 10))
print (str1.find(str2, 10, 0))
结果:
5
5
-1
2
2
-1
28、rindex( str, beg=0, end=len(string)):类似于 index(),不过是从右边开始.
rindex() 返回子字符串 str 在字符串中最后出现的位置,如果没有匹配的字符串会报异常,你可以指定可选参数[beg:end]设置查找的区间。
语法
str.rindex(str, beg=0 end=len(string))
参数
str -- 查找的字符串
beg -- 开始查找的位置,默认为0
end -- 结束查找位置,默认为字符串的长度。
实例
str1 = "this is really a string example....wow!!!"
str2 = "is"
print (str1.rindex(str2))
print (str1.rindex(str2,10))
5
Traceback (most recent call last):
File "test.py", line 6, in <module>
print (str1.rindex(str2,10))
ValueError: substring not found
29、rjust(width,[, fillchar]): 返回一个原字符串右对齐,并使用fillchar(默认空格)填充至长度 width 的新字符串
rjust() 返回一个原字符串右对齐,并使用空格填充至长度 width 的新字符串。如果指定的长度小于字符串的长度则返回原字符串。
语法
str.rjust(width[, fillchar])
参数
width -- 指定填充指定字符后中字符串的总长度.
fillchar -- 填充的字符,默认为空格。
实例
str = "this is string example....wow!!!"
print (str.rjust(50, '*'))
结果:
******************this is string example....wow!!!
30、rstrip() :删除字符串字符串末尾的空格.
rstrip() 删除 string 字符串末尾的指定字符(默认为空格).
语法
str.rstrip([chars])
参数
chars -- 指定删除的字符(默认为空格)
实例
str = " this is string example....wow!!! "
print (str.rstrip())
str = "*****this is string example....wow!!!*****"
print (str.rstrip('*'))
结果:
this is string example....wow!!!
*****this is string example....wow!!!
31、split(str="", num=string.count(str)):num=string.count(str)) 以 str 为分隔符截取字符串,如果 num 有指定值,则仅截取 num+1 个子字符串
split()通过指定分隔符对字符串进行切片,如果参数 num 有指定值,则仅分隔 num+1 个子字符串
语法
str.split(str="", num=string.count(str))
参数
str -- 分隔符,默认为所有的空字符,包括空格、换行(\n)、制表符(\t)等。
num -- 分割次数。默认为 -1, 即分隔所有。
实例
str = "this is string example....wow!!!"
print (str.split( )) # 以空格为分隔符
print (str.split('i',1)) # 以 i 为分隔符
print (str.split('w')) # 以 w 为分隔符
结果:
['this', 'is', 'string', 'example....wow!!!']
['th', 's is string example....wow!!!']
['this is string example....', 'o', '!!!']
以下实例以 # 号为分隔符,指定第二个参数为 1,返回两个参数列表。
txt = "Google#Runoob#Taobao#Facebook"
# 第二个参数为 1,返回两个参数列表
x = txt.split("#", 1)
print(x)
结果:
['Google', 'Runoob#Taobao#Facebook']
32、splitlines([keepends]):按照行('\r', '\r\n', \n')分隔,返回一个包含各行作为元素的列表,如果参数 keepends 为 False,不包含换行符,如果为 True,则保留换行符。
Python splitlines() 按照行('\r', '\r\n', \n')分隔,返回一个包含各行作为元素的列表,如果参数 keepends 为 False,不包含换行符,如果为 True,则保留换行符。
语法:
str.splitlines([keepends])
参数
keepends -- 在输出结果里是否去掉换行符('\r', '\r\n', \n'),默认为 False,不包含换行符,如果为 True,则保留换行符。
实例
>>> 'ab c\n\nde fg\rkl\r\n'.splitlines()
['ab c', '', 'de fg', 'kl']
>>> 'ab c\n\nde fg\rkl\r\n'.splitlines(True)
['ab c\n', '\n', 'de fg\r', 'kl\r\n']
33、startswith(substr, beg=0,end=len(string)):检查字符串是否是以指定子字符串 substr 开头,是则返回 True,否则返回 False。如果beg 和 end 指定值,则在指定范围内检查
startswith() 方法用于检查字符串是否是以指定子字符串开头,如果是则返回 True,否则返回 False。如果参数 beg 和 end 指定值,则在指定范围内检查。
语法:
str.startswith(substr, beg=0,end=len(string));
参数
str -- 检测的字符串。
substr -- 指定的子字符串。
strbeg -- 可选参数用于设置字符串检测的起始位置。
strend -- 可选参数用于设置字符串检测的结束位置。
实例:
str = "this is string example....wow!!!"
print (str.startswith( 'this' )) # 字符串是否以 this 开头
print (str.startswith( 'string', 8 )) # 从第八个字符开始的字符串是否以 string 开头
print (str.startswith( 'this', 2, 4 )) # 从第2个字符开始到第四个字符结束的字符串是否以 this 开头
True
True
False
34、strip([chars]):在字符串上执行 lstrip()和 rstrip()
Python strip() 方法用于移除字符串头尾指定的字符(默认为空格)或字符序列。
注意:该方法只能删除开头或是结尾的字符,不能删除中间部分的字符。
语法:
str.strip([chars]);
参数
chars -- 移除字符串头尾指定的字符序列。
实例
str = "*****this is **string** example....wow!!!*****"
print (str.strip( '*' )) # 指定字符串 *
结果:
this is **string** example....wow!!!
以上下例演示了只要头尾包含有指定字符序列中的字符就删除:
str = "123abcrunoob321"
print (str.strip( '12' )) # 字符序列为 12
结果:
3abcrunoob3
35、swapcase():将字符串中大写转换为小写,小写转换为大写
swapcase() 方法用于对字符串的大小写字母进行转换。
语法
str.swapcase();
参数
NA。
实例
str = "this is string example....wow!!!"
print (str.swapcase())
str = "This Is String Example....WOW!!!"
print (str.swapcase())
结果:
THIS IS STRING EXAMPLE....WOW!!!
tHIS iS sTRING eXAMPLE....wow!!!
36、title():返回"标题化"的字符串,就是说所有单词都是以大写开始,其余字母均为小写(见 istitle())
Python title() 方法返回"标题化"的字符串,就是说所有单词的首个字母转化为大写,其余字母均为小写(见 istitle())。
语法:
str.title();
参数
NA。
实例
str = "this is string example from runoob....wow!!!"
print (str.title())
结果:
This Is String Example From Runoob....Wow!!!
非字母后的第一个字母将转换为大写字母:
txt = "hello b2b2b2 and 3g3g3g"
x = txt.title()
print(x)
结果:
Hello B2B2B2 And 3G3G3G
37、translate(table, deletechars=""):根据 str 给出的表(包含 256 个字符)转换 string 的字符, 要过滤掉的字符放到 deletechars 参数中
translate() 方法根据参数table给出的表(包含 256 个字符)转换字符串的字符,要过滤掉的字符放到 deletechars 参数中。
语法:
str.translate(table)
bytes.translate(table[, delete])
bytearray.translate(table[, delete])
参数
table -- 翻译表,翻译表是通过 maketrans() 方法转换而来。
deletechars -- 字符串中要过滤的字符列表。
实例
intab = "aeiou"
outtab = "12345"
trantab = str.maketrans(intab, outtab) # 制作翻译表
str = "this is string example....wow!!!"
print (str.translate(trantab))
结果:
th3s 3s str3ng 2x1mpl2....w4w!!!
38、upper():转换字符串中的小写字母为大写
Python upper() 方法将字符串中的小写字母转为大写字母。
语法:
str.upper()
参数
NA。
实例
str = "this is string example from runoob....wow!!!";
print ("str.upper() : ", str.upper())
结果:
str.upper() : THIS IS STRING EXAMPLE FROM RUNOOB....WOW!!!
39、zfill (width):返回长度为 width 的字符串,原字符串右对齐,前面填充0
Python zfill() 方法返回指定长度的字符串,原字符串右对齐,前面填充0。
语法
str.zfill(width)
参数
width -- 指定字符串的长度。原字符串右对齐,前面填充0
实例
str = "this is string example from runoob....wow!!!"
print ("str.zfill : ",str.zfill(40))
print ("str.zfill : ",str.zfill(50))
结果:
str.zfill : this is string example from runoob....wow!!!
str.zfill : 000000this is string example from runoob....wow!!!
40、isdecimal():检查字符串是否只包含十进制字符,如果是返回 true,否则返回 false。
isdecimal() 方法检查字符串是否只包含十进制字符。这种方法只存在于unicode对象。
注意:定义一个十进制字符串,只需要在字符串前添加 'u' 前缀即可。
语法:
str.isdecimal()
参数
无
实例
str = "runoob2016"
print (str.isdecimal())
str = "23443434"
print (str.isdecimal())
结果:
False
True
补充:
isprintable() 判断所有字符是否都可被打印
test = "ab\nc" v = test.isprintable() print(v) False
translate()和maketrans() 创建字符间映射关系
test1 = "alknv,zxcvl;kajwpijklansnzxc,vnlk;wejrqoin" test2 = test1.maketrans("aeiounlk;,","12345789 _") v = test1.translate(test2) print(v) 1897v_zxcv8 91jwp3j9817s7zxc_v789 w2jrq437
partition() 将字符串从左侧匹配并切割为三部分
test = "asdfasdfasdf" v = test.partition("s") print(v) ('a', 's', 'dfasdfasdf')
rpartition() 将字符串从右侧开始匹配并切割为三部分
test = "asdfasdfasdf" v = test.rpartition("s") print(v) ('asdfasdfa', 's', 'df')
isidentifier() 判断是否为标识符(字母、数字、下划线)
test1 = "abc_123" test2 = "a b c*123" v1 = test1.isidentifier() v2 = test2.isidentifier() print(v1,v2) True False
更多方法参考:https://www.runoob.com/python3/python3-string.html
数字(Number)
Python 数字数据类型用于存储数值,不允许改变。Python3 支持 int、float、bool、complex(复数)。
内置的 type() 函数可以用来查询变量所指的对象类型。
a, b, c, d = 20, 5.5, True, 4+3j
print(type(a), type(b), type(c), type(d))
<class 'int'> <class 'float'> <class 'bool'> <class 'complex'>
int(整型)
通常被称为是整型或整数,是正或负整数,不带小数点。Python3 整型是没有限制大小的,可以当作 Long 类型使用,所以 Python3 没有 Python2 的 Long 类型。在64位系统上,整数的位数为64位,取值范围为-263~263-1,即-9223372036854775808~9223372036854775807
浮点型(float)
浮点型由整数部分与小数部分组成,浮点型也可以使用科学计数法表示(2.5e2 = 2.5 x 102 = 250)
复数( (complex))
复数由实数部分和虚数部分构成,可以用a + bj,或者complex(a,b)表示, 复数的实部a和虚部b都是浮点型。
Python 数字类型转换
-
int(x) 将x转换为一个整数。
-
float(x) 将x转换到一个浮点数。
-
complex(x) 将x转换到一个复数,实数部分为 x,虚数部分为 0。
-
complex(x, y) 将 x 和 y 转换到一个复数,实数部分为 x,虚数部分为 y。x 和 y 是数字表达式。
Python 数字类型运算
python支持 +, -, * 和 /,
列子: >>> 2 + 2 4 >>> 50 - 5*6 20 >>> (50 - 5*6) / 4 5.0 >>> 8 / 5 # 总是返回一个浮点数 1.6 在整数除法中,除法 / 总是返回一个浮点数,如果只想得到整数的结果,丢弃可能的分数部分,可以使用运算符 // : >>> 17 / 3 # 整数除法返回浮点型 5.666666666666667 >>> >>> 17 // 3 # 整数除法返回向下取整后的结果 5 >>> 17 % 3 # %操作符返回除法的余数 2 >>> 5 * 3 + 2 17 // 得到的并不一定是整数类型的数,它与分母分子的数据类型有关系。 >>> 7//2 3 >>> 7.0//2 3.0 >>> 7//2.0 3.0 等号 = 用于给变量赋值。赋值之后,除了下一个提示符,解释器不会显示任何结果。 >>> width = 20 >>> height = 5*9 >>> width * height 900 Python 可以使用 ** 操作来进行幂运算: >>> 5 ** 2 # 5 的平方 25 >>> 2 ** 7 # 2的7次方 128 不同类型的数混合运算时会将整数转换为浮点数: >>> 3 * 3.75 / 1.5 7.5 >>> 7.0 / 2 3.5
Python 数字类型的数学函数:详情
abs(x):返回数字的绝对值,如abs(-10) 返回 10
语法: abs( x )
参数: x -- 数值表达式,可以是整数,浮点数,复数。
返回值: 函数返回 x(数字)的绝对值,如果参数是一个复数,则返回它的大小。
列子:
print ("abs(-40) : ", abs(-40)) # 结果:abs(-40) : 40
print ("abs(100.10) : ", abs(100.10)) #结果:abs(100.10) : 100.1
ceil(x):返回数字的上入整数,如math.ceil(4.1) 返回 5
语法:
import math
math.ceil( x )
注意:
ceil()是不能直接访问的,需要导入 math 模块,通过静态对象调用该方法。
参数:
x -- 数值表达式。
返回值:
函数返回返回一个大于或等于 x 的的最小整数。
列子:
#!/usr/bin/python3
import math # 导入 math 模块
print ("math.ceil(-45.17) : ", math.ceil(-45.17))
print ("math.ceil(100.12) : ", math.ceil(100.12))
print ("math.ceil(100.72) : ", math.ceil(100.72))
print ("math.ceil(math.pi) : ", math.ceil(math.pi))
结果 #
math.ceil(-45.17) : -45
math.ceil(100.12) : 101
math.ceil(100.72) : 101
math.ceil(math.pi) : 4
cmp(x, y):如果 x < y 返回 -1, 如果 x == y 返回 0, 如果 x > y 返回 1。 Python 3 已废弃,使用 (x>y)-(x<y) 替换。
exp(x): 返回e的x次幂(ex),如math.exp(1) 返回2.718281828459045
语法:
以下是 exp() 方法的语法:
import math
math.exp( x )
注意:
exp()是不能直接访问的,需要导入 math 模块,通过静态对象调用该方法。
参数:
x -- 数值表达式。
返回值
返回x的指数,ex。
实例:
import math # 导入 math 模块
print ("math.exp(-45.17) : ", math.exp(-45.17))
print ("math.exp(100.12) : ", math.exp(100.12))
print ("math.exp(100.72) : ", math.exp(100.72))
print ("math.exp(math.pi) : ", math.exp(math.pi))
结果:
math.exp(-45.17) : 2.4150062132629406e-20
math.exp(100.12) : 3.0308436140742566e+43
math.exp(100.72) : 5.522557130248187e+43
math.exp(math.pi) : 23.140692632779267
fabs(x) : 返回数字的绝对值,如math.fabs(-10) 返回10.0
floor(x) : 返回数字的下舍整数,如math.floor(4.9)返回 4
log(x):如math.log(math.e)返回1.0,math.log(100,10)返回2.0
log10(x): 返回以10为基数的x的对数,如math.log10(100)返回 2.0
max(x1, x2,...):返回给定参数的最大值,参数可以为序列。
min(x1, x2,...) : 返回给定参数的最小值,参数可以为序列。
modf(x): 返回x的整数部分与小数部分,两部分的数值符号与x相同,整数部分以浮点型表示。
pow(x, y) :x**y 运算后的值。
round(x [,n]) : 返回浮点数x的四舍五入值,如给出n值,则代表舍入到小数点后的位数。
sqrt(x):返回数字x的平方根。
Python 数字类型的随机函数:详情

Python 数字类型的三角函数:详情
Python 数字类型的数学常量:详情

列表(List)
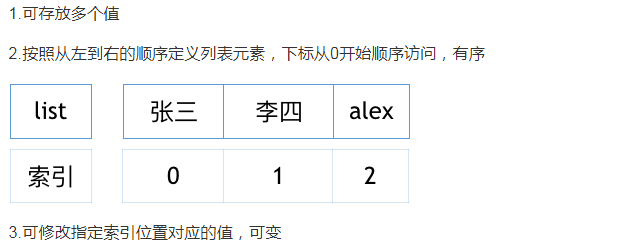
定义:中括号 [] 括起来,用“,”分割每个元素,列表中可以存储任何类型,如:数字、字符串、布尔值、列表… 。列表的存储是不连续的。
列表特性:
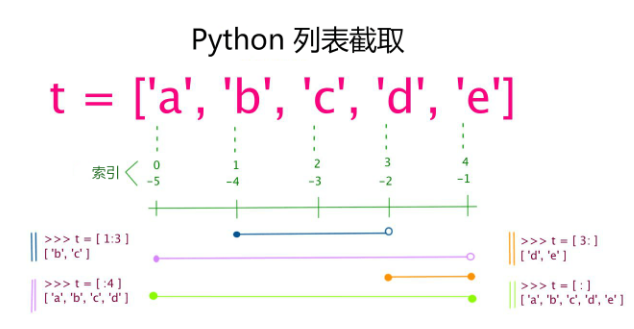
列表的取值:
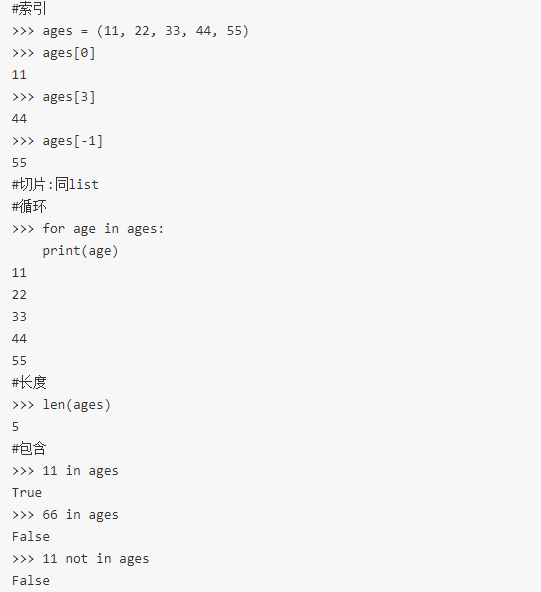
1、切片取值
li=[1,2,"a","b"]
print(li[:3]) #[1, 2, 'a']
2、索引取值
li=[1,2,"a","b"]
print(li[1]) #2
3、for循环取值
li=[1,2,"a","b"]
for i in li:
print(i) #依次打印li内元素
4、Python 列表截取可以接收第三个参数,参数作用是截取的步长,以下实例在索引 1 到索引 4 的位置并设置为步长为 2(间隔一个位置)来截取字符串:
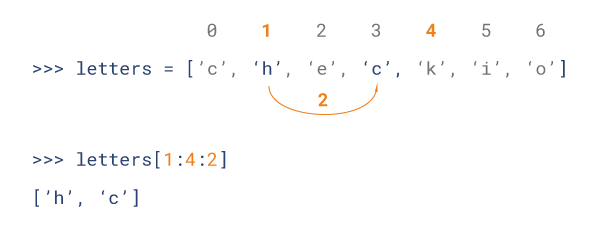
列表的修改:
通过索引修改
li=[1,2,"a","b"]
li[2]="Hello"
print(li) #[1, 2, 'Hello', 'b']
通过切片修改
li=[1,2,"a","b"]
li[::2]=['c','d']
print(li) #['c', 2, 'd', 'b']
in、not in操作
判断内容存不存在列表内,返回布尔值,只能判断当前列表的选项,列表选项的子选项内容不能判断
li=[1,2,"a","b"]
print('a' in li) #True
print(3 in li) #False
列表与字符串的转换

列表的函数
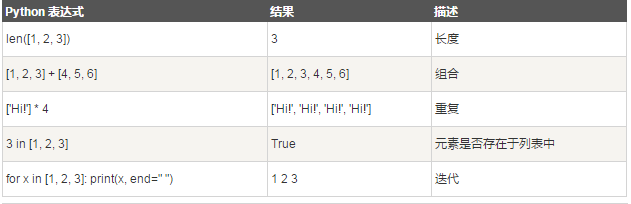
len(list):返回列表元素个数
len() 方法返回列表元素个数。 语法: len(list) 参数: list -- 要计算元素个数的列表。 实列: #!/usr/bin/python3 list1 = ['Google', 'Runoob', 'Taobao'] print (len(list1)) list2=list(range(5)) # 创建一个 0-4 的列表 print (len(list2))
max() 方法返回列表元素中的最大值。
max() 方法返回列表元素中的最大值。 语法: max(list) 参数 list -- 要返回最大值的列表。 实例 list1, list2 = ['Google', 'Runoob', 'Taobao'], [456, 700, 200] print ("list1 最大元素值 : ", max(list1)) print ("list2 最大元素值 : ", max(list2)) 结果: list1 最大元素值 : Taobao list2 最大元素值 : 700
min() 方法返回列表元素中的最小值。
min() 方法返回列表元素中的最小值。 语法 min(list) 参数 list -- 要返回最小值的列表。 实例 list1, list2 = ['Google', 'Runoob', 'Taobao'], [456, 700, 200] print ("list1 最小元素值 : ", min(list1)) print ("list2 最小元素值 : ", min(list2)) 结果: list1 最小元素值 : Google list2 最小元素值 : 200
list() 方法用于将元组或字符串转换为列表。
list() 方法用于将元组或字符串转换为列表。 注:元组与列表是非常类似的,区别在于元组的元素值不能修改,元组是放在括号中,列表是放于方括号中 语法 list( seq ) 参数 seq -- 要转换为列表的元组或字符串。 实例 aTuple = (123, 'Google', 'Runoob', 'Taobao') list1 = list(aTuple) print ("列表元素 : ", list1) str="Hello World" list2=list(str) print ("列表元素 : ", list2) 结果: 列表元素 : [123, 'Google', 'Runoob', 'Taobao'] 列表元素 : ['H', 'e', 'l', 'l', 'o', ' ', 'W', 'o', 'r', 'l', 'd']
列表的方法
list.append(obj):在列表末尾添加新的对象
append() 方法用于在列表末尾添加新的对象。 语法: list.append(obj) 参数: obj -- 添加到列表末尾的对象。 实例 #!/usr/bin/python3 list1 = ['Google', 'Runoob', 'Taobao'] list1.append('Baidu') print ("更新后的列表 : ", list1) 结果: 更新后的列表 : ['Google', 'Runoob', 'Taobao', 'Baidu']
list.count(obj):统计某个元素在列表中出现的次数
count() 方法用于统计某个元素在列表中出现的次数。 语法: list.count(obj) 参数 obj -- 列表中统计的对象。 实例 aList = [123, 'Google', 'Runoob', 'Taobao', 123]; print ("123 元素个数 : ", aList.count(123)) print ("Runoob 元素个数 : ", aList.count('Runoob')) 123 元素个数 : 2 Runoob 元素个数 : 1
list.extend(seq):在列表末尾一次性追加另一个序列中的多个值(用新列表扩展原来的列表)
extend() 函数用于在列表末尾一次性追加另一个序列中的多个值(用新列表扩展原来的列表)。 语法 list.extend(seq) 参数 seq -- 元素列表,可以是列表、元组、集合、字典,若为字典,则仅会将键(key)作为元素依次添加至原列表的末尾。 实例 list1 = ['Google', 'Runoob', 'Taobao'] list2=list(range(5)) # 创建 0-4 的列表 list1.extend(list2) # 扩展列表 print ("扩展后的列表:", list1) 结果: 扩展后的列表: ['Google', 'Runoob', 'Taobao', 0, 1, 2, 3, 4] 不同数据类型 # 语言列表 language = ['French', 'English', 'German'] # 元组 language_tuple = ('Spanish', 'Portuguese') # 集合 language_set = {'Chinese', 'Japanese'} # 添加元组元素到列表末尾 language.extend(language_tuple) print('新列表: ', language) # 添加集合元素到列表末尾 language.extend(language_set) print('新列表: ', language) 新列表: ['French', 'English', 'German', 'Spanish', 'Portuguese'] 新列表: ['French', 'English', 'German', 'Spanish', 'Portuguese', 'Japanese', 'Chinese']
list.index(obj):从列表中找出某个值第一个匹配项的索引位置
index() 函数用于从列表中找出某个值第一个匹配项的索引位置。 语法 list.index(x[, start[, end]]) 参数 x-- 查找的对象。 start-- 可选,查找的起始位置。 end-- 可选,查找的结束位置。 实例: list1 = ['Google', 'Runoob', 'Taobao'] print ('Runoob 索引值为', list1.index('Runoob')) print ('Taobao 索引值为', list1.index('Taobao')) 语法: Runoob 索引值为 1 Taobao 索引值为 2 实列2: list1 = ['Google', 'Runoob', 'Taobao', 'Facebook', 'QQ'] # 从指定位置开始搜索 print ('Runoob 索引值为', list1.index('Runoob',1)) Runoob 索引值为 1
list.insert(index, obj):将对象插入列表
insert() 函数用于将指定对象插入列表的指定位置。 语法 list.insert(index, obj) 参数 index -- 对象obj需要插入的索引位置。 obj -- 要插入列表中的对象。 实例 list1 = ['Google', 'Runoob', 'Taobao'] list1.insert(1, 'Baidu') print ('列表插入元素后为 : ', list1) 结果: 列表插入元素后为 : ['Google', 'Baidu', 'Runoob', 'Taobao']
list.pop([index=-1]):移除列表中的一个元素(默认最后一个元素),并且返回该元素的值
pop() 函数用于移除列表中的一个元素(默认最后一个元素),并且返回该元素的值。 语法 list.pop([index=-1]) 参数 index -- 可选参数,要移除列表元素的索引值,不能超过列表总长度,默认为 index=-1,删除最后一个列表值。 实例 list1 = ['Google', 'Runoob', 'Taobao'] list1.pop() print ("列表现在为 : ", list1) list1.pop(1) print ("列表现在为 : ", list1) 结果: 列表现在为 : ['Google', 'Runoob'] 列表现在为 : ['Google']
list.remove(obj):移除列表中某个值的第一个匹配项
remove() 函数用于移除列表中某个值的第一个匹配项。 语法 list.remove(obj) 参数 obj -- 列表中要移除的对象。 实例 list1 = ['Google', 'Runoob', 'Taobao', 'Baidu'] list1.remove('Taobao') print ("列表现在为 : ", list1) list1.remove('Baidu') print ("列表现在为 : ", list1) 列表现在为 : ['Google', 'Runoob', 'Baidu'] 列表现在为 : ['Google', 'Runoob']
list.reverse():反向列表中元素
reverse() 函数用于反向列表中元素。 语法 list.reverse() 参数 NA。 实例 list1 = ['Google', 'Runoob', 'Taobao', 'Baidu'] list1.reverse() print ("列表反转后: ", list1) 结果: 列表反转后: ['Baidu', 'Taobao', 'Runoob', 'Google']
list.sort( key=None, reverse=False):对原列表进行排序
sort() 函数用于对原列表进行排序,如果指定参数,则使用比较函数指定的比较函数。 语法 list.sort( key=None, reverse=False) 参数 key -- 主要是用来进行比较的元素,只有一个参数,具体的函数的参数就是取自于可迭代对象中,指定可迭代对象中的一个元素来进行排序。 reverse -- 排序规则,reverse = True 降序, reverse = False 升序(默认)。 实例 aList = ['Google', 'Runoob', 'Taobao', 'Facebook'] aList.sort() print ( "List : ", aList) 结果: List : ['Facebook', 'Google', 'Runoob', 'Taobao'] 实列2: # 列表 vowels = ['e', 'a', 'u', 'o', 'i'] # 降序 vowels.sort(reverse=True) # 输出结果 print ( '降序输出:', vowels ) 结果: 降序输出: ['u', 'o', 'i', 'e', 'a']
list.clear():清空列表
clear() 函数用于清空列表,类似于 del a[:]。 语法: list.clear() 参数: 无 实列: list1 = ['Google', 'Runoob', 'Taobao', 'Baidu'] list1.clear() print ("列表清空后 : ", list1) 结果: 列表清空后 : []
list.copy():复制列表
copy() 函数用于复制列表,类似于 a[:]。 语法 list.copy() 参数 无。 实例 list1 = ['Google', 'Runoob', 'Taobao', 'Baidu'] list2 = list1.copy() print ("list2 列表: ", list2) 结果: list2 列表: ['Google', 'Runoob', 'Taobao', 'Baidu']
补充:
Python列表脚本操作符
列表对 + 和 * 的操作符与字符串相似。+ 号用于组合列表,* 号用于重复列表。
Python列表截取与拼接及嵌套
Python的列表截取与字符串操作类型,如下所示: L=['Google', 'Runoob', 'Taobao']
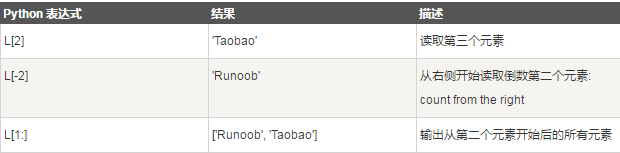
>>>L=['Google', 'Runoob', 'Taobao']
>>> L[2]
'Taobao'
>>> L[-2]
'Runoob'
>>> L[1:]
['Runoob', 'Taobao']
拼接操作:
>>>squares = [1, 4, 9, 16, 25]
>>> squares += [36, 49, 64, 81, 100]
>>> squares
[1, 4, 9, 16, 25, 36, 49, 64, 81, 100]
使用嵌套列表即在列表里创建其它列表
>>>a = ['a', 'b', 'c']
>>> n = [1, 2, 3]
>>> x = [a, n]
>>> x
[['a', 'b', 'c'], [1, 2, 3]]
>>> x[0]
['a', 'b', 'c']
>>> x[0][1]
'b'
元祖(Tuple)
定义:元组,其实是对列表的二次加工,是有序的,元组写在小括号 () 里,元素之间用逗号隔开,第一元素不能被修改、增加、删除。
# 元组,其实是对列表的二次加工,元素不可被修改,不能被增加或者删除
# 一般写元组的时候,推荐在最后加一个逗号
li = [11,22,33,44] # 列表
tu = (111,222,333,444,) #元祖
tup3 = "a", "b", "c", "d"; # 不需要括号也可以
type(tup3) #结果:<class 'tuple'>
注意:
元组中只包含一个元素时,需要在元素后面添加逗号,否则括号会被当作运算符使用
>>>tup1 = (50)
>>> type(tup1) # 不加逗号,类型为整型
<class 'int'>
>>> tup1 = (50,)
>>> type(tup1) # 加上逗号,类型为元组
<class 'tuple'>
作用:存多个值,对比列表来说,元组不可变(是可以当做字典的key的),主要是用来读
特性:1.可存放多个值 2.不可变 3.按照从左到右的顺序定义元组元素,下标从0开始顺序访问,有序
元组元素的查看

元组与列表、字符串的转换


元祖的运算
与字符串一样,元组之间可以使用 + 号和 * 号进行运算。这就意味着他们可以组合和复制,运算后会生成一个新的元组。

元组的魔法(方法)

join拼接

extend

补充:
max(tuple)返回元组中元素最大值
>>> tuple2 = ('5', '4', '8') >>> max(tuple2) '8'
min(tuple)返回元组中元素最小值
>>> tuple2 = ('5', '4', '8') >>> min(tuple2) '4'
字典(Dict)
创建:字典的每个键值(key=>value)对用冒号(:)分割,每个对之间用逗号(,)分割,整个字典包括在花括号({})中 ,基本格式:由键值对组成,一个key对应一个value值{ }
d ={key1:value1,key2:value2}
说明:
key:列表、字典不能作为key,一般是唯一的
value:任何值都可以作为value,可以重复,但键不行,键必须不可变,所以可以用数字,字符串或元组充当,而用列表就不行
如果一个字典中出现了相同的key值,则后面出现的会覆盖前面出现的
布尔值的True与False分别会与数字1和0混淆,也会出现覆盖现象,但此种覆盖是前面代替后面的
字典的查找

for循环查找

字典的操作

字典的内置函数
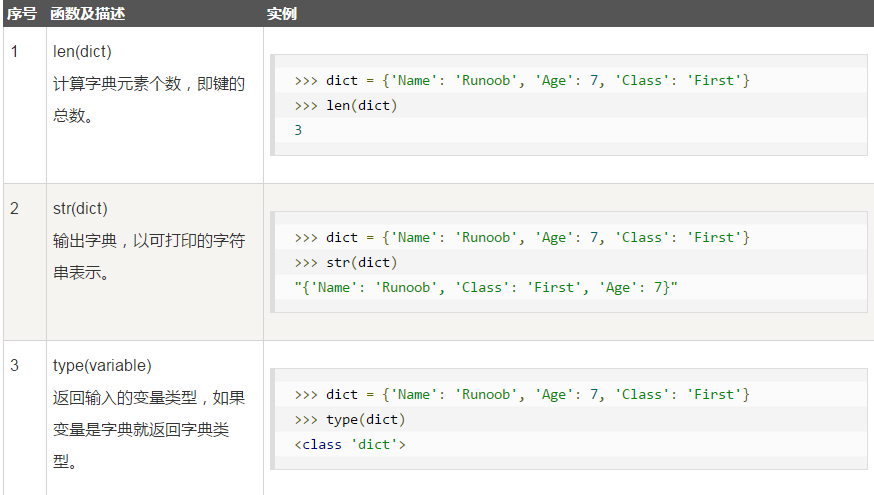
字典的内置方法:
clear():删除字典内所有元素
Python 字典 clear() 函数用于删除字典内所有元素。
语法:
dict.clear()
参数:
NA。
实列:
dict = {'Name': 'Zara', 'Age': 7}
print ("字典长度 : %d" % len(dict))
dict.clear()
print ("字典删除后长度 : %d" % len(dict))
结果:
字典长度 : 2
字典删除后长度 : 0
copy():返回一个字典的浅复制
Python 字典 copy() 函数返回一个字典的浅复制。
语法:
dict.copy()
参数
NA。
实例
dict1 = {'Name': 'Runoob', 'Age': 7, 'Class': 'First'}
dict2 = dict1.copy()
print ("新复制的字典为 : ",dict2)
新复制的字典为 : {'Age': 7, 'Name': 'Runoob', 'Class': 'First'}
直接赋值和 copy 的区别
dict1 = {'user':'runoob','num':[1,2,3]}
dict2 = dict1 # 浅拷贝: 引用对象
dict3 = dict1.copy() # 浅拷贝:深拷贝父对象(一级目录),子对象(二级目录)不拷贝,还是引用
# 修改 data 数据
dict1['user']='root'
dict1['num'].remove(1)
# 输出结果
print(dict1) # {'user': 'root', 'num': [2, 3]}
print(dict2) # {'user': 'root', 'num': [2, 3]}
print(dict3) # {'user': 'runoob', 'num': [2, 3]}
实例中 dict2 其实是 dict1 的引用(别名),所以输出结果都是一致的,dict3 父对象进行了深拷贝,不会随dict1 修改而修改,子对象是浅拷贝所以随 dict1 的修改而修改。
fromkeys():创建一个新字典,以序列seq中元素做字典的键,val为字典所有键对应的初始值
Python 字典 fromkeys() 函数用于创建一个新字典,以序列 seq 中元素做字典的键,value 为字典所有键对应的初始值。
语法:
dict.fromkeys(seq[, value])
参数:
seq -- 字典键值列表。
value -- 可选参数, 设置键序列(seq)对应的值,默认为 None。
实例:
seq = ('name', 'age', 'sex')
dict = dict.fromkeys(seq)
print ("新的字典为 : %s" % str(dict))
dict = dict.fromkeys(seq, 10)
print ("新的字典为 : %s" % str(dict))
结果:
新的字典为 : {'age': None, 'name': None, 'sex': None}
新的字典为 : {'age': 10, 'name': 10, 'sex': 10}
不指定值:
x = ('key1', 'key2', 'key3')
thisdict = dict.fromkeys(x)
print(thisdict) # {'key1': None, 'key2': None, 'key3': None}
get(key, default=None):返回指定键的值,如果值不在字典中返回default值
Python 字典 get() 函数返回指定键的值,如果值不在字典中返回默认值。
语法:
dict.get(key, default=None)
参数:
key -- 字典中要查找的键。
default -- 如果指定键的值不存在时,返回该默认值值。
实例:
dict = {'Name': 'Runoob', 'Age': 27}
print ("Age 值为 : %s" % dict.get('Age'))
print ("Sex 值为 : %s" % dict.get('Sex', "NA"))
结果:
Age 值为 : 27
Sex 值为 : NA
key in dict 如果键在字典dict里返回true,否则返回false
Python 字典 in 操作符用于判断键是否存在于字典中,如果键在字典 dict 里返回 true,否则返回 false。而 not in 操作符刚好相反,如果键在字典 dict 里返回 false,否则返回true。
语法:
key in dict
参数:
key -- 要在字典中查找的键。
实例:
dict = {'Name': 'Runoob', 'Age': 7}
# 检测键 Age 是否存在
if 'Age' in dict:
print("键 Age 存在")
else :
print("键 Age 不存在")
# 检测键 Sex 是否存在
if 'Sex' in dict:
print("键 Sex 存在")
else :
print("键 Sex 不存在")
# not in
# 检测键 Age 是否存在
if 'Age' not in dict:
print("键 Age 不存在")
else :
print("键 Age 存在")
结果:
键 Age 存在
键 Sex 不存在
键 Age 存在
items(): 以列表返回可遍历的(键, 值) 元组数组
Python 字典 items() 方法以列表返回可遍历的(键, 值) 元组数组。
语法:
dict.items()
参数:
NA。
实列:
dict = {'Name': 'Runoob', 'Age': 7}
print ("Value : %s" % dict.items())
结果:
Value : dict_items([('Age', 7), ('Name', 'Runoob')])
keys():返回一个迭代器,可以使用 list() 来转换为列表
Python3 字典 keys() 方法返回一个可迭代对象,可以使用 list() 来转换为列表。
语法:
dict.keys()
参数
NA。
实例:
>>> dict = {'Name': 'Runoob', 'Age': 7}
>>> dict.keys()
dict_keys(['Name', 'Age'])
>>> list(dict.keys()) # 转换为列表
['Name', 'Age']
>>>
结果:
字典所有的键为 : dict_keys(['Age', 'Name'])
setdefault(key, default=None): 和get()类似, 但如果键不存在于字典中,将会添加键并将值设为default
Python 字典 setdefault() 方法和 get()方法 类似, 如果键不已经存在于字典中,将会添加键并将值设为默认值。
语法:
dict.setdefault(key, default=None)
参数:
key -- 查找的键值。
default -- 键不存在时,设置的默认键值。
实列:
dict = {'Name': 'Runoob', 'Age': 7}
print ("Age 键的值为 : %s" % dict.setdefault('Age', None))
print ("Sex 键的值为 : %s" % dict.setdefault('Sex', None))
print ("新字典为:", dict)
结果:
Age 键的值为 : 7
Sex 键的值为 : None
新字典为: {'Age': 7, 'Name': 'Runoob', 'Sex': None}
update(dict2):把字典dict2的键/值对更新到dict里
Python 字典 update() 函数把字典参数 dict2 的 key/value(键/值) 对更新到字典 dict 里。
语法:
dict.update(dict2)
参数:
dict2 -- 添加到指定字典dict里的字典。
实列:
dict = {'Name': 'Runoob', 'Age': 7}
dict2 = {'Sex': 'female' }
dict.update(dict2)
print ("更新字典 dict : ", dict)
结果:
更新字典 dict : {'Name': 'Runoob', 'Age': 7, 'Sex': 'female'}
values():返回一个迭代器,可以使用 list() 来转换为列表
Python 字典 values() 方法返回一个迭代器,可以使用 list() 来转换为列表,列表为字典中的所有值。
语法:
dict.values()
参数
NA。
实例
dict = {'Sex': 'female', 'Age': 7, 'Name': 'Zara'}
print ("字典所有值为 : ", list(dict.values()))
结果:
字典所有值为 : ['female', 7, 'Zara']
pop(key[,default]): 删除字典给定键 key 所对应的值,返回值为被删除的值。key值必须给出。 否则,返回default值
Python 字典 pop() 方法删除字典给定键 key 所对应的值,返回值为被删除的值。key值必须给出。 否则,返回default值。
语法:
pop(key[,default])
参数:
key: 要删除的键值
default: 如果没有 key,返回 default 值
实例:
>>> site= {'name': '菜鸟教程', 'alexa': 10000, 'url': 'www.runoob.com'}
>>> pop_obj=site.pop('name')
>>> print(pop_obj)
菜鸟教程
popitem() : 随机返回并删除字典中的一对键和值(一般删除末尾对)
Python 字典 popitem() 方法随机返回并删除字典中的一对键和值(一般删除末尾对)。如果字典已经为空,却调用了此方法,就报出KeyError异常。
语法:
popitem()
参数:无
实列:
site= {'name': '菜鸟教程', 'alexa': 10000, 'url': 'www.runoob.com'}
pop_obj=site.popitem()
print(pop_obj)
print(site)
结果:
('url', 'www.runoob.com')
{'name': '菜鸟教程', 'alexa': 10000}
集合(Set)

集合(set):是由一个或数个形态各异的大小整体组成的,构成集合的事物或对象称作元素或是成员。基本功能是进行成员关系测试和删除重复元素。使用大括号 { } 或者 set() 函数创建集合
注意:创建一个空集合必须用 set() 而不是 { },因为 { } 是用来创建一个空字典。
创建格式:
格式:parame = {value01,value02,...} 或者:set(value)
例子:
>>>basket = {'apple', 'orange', 'apple', 'pear', 'orange', 'banana'}
>>> print(basket) # 这里演示的是去重功能
{'orange', 'banana', 'pear', 'apple'}
>>> 'orange' in basket # 快速判断元素是否在集合内
True
>>> 'crabgrass' in basket False >>> # 下面展示两个集合间的运算. ...
>>> a = set('abracadabra')
>>> b = set('alacazam')
>>> a {'a', 'r', 'b', 'c', 'd'}
>>> a - b # 集合a中包含而集合b中不包含的元素 {'r', 'd', 'b'}
>>> a | b # 集合a或b中包含的所有元素 {'a', 'c', 'r', 'd', 'b', 'm', 'z', 'l'}
>>> a & b # 集合a和b中都包含了的元素 {'a', 'c'}
>>> a ^ b # 不同时包含于a和b的元素 {'r', 'd', 'b', 'm', 'z', 'l'}
python集合内置方法
add():为集合添加元素
add() 方法用于给集合添加元素,如果添加的元素在集合中已存在,则不执行任何操作。 语法 set.add(elmnt) 参数 elmnt -- 必需,要添加的元素。 实例 fruits = {"apple", "banana", "cherry"} fruits.add("orange") print(fruits) 结果: {'apple', 'banana', 'orange', 'cherry'} fruits = {"apple", "banana", "cherry"} fruits.add("apple") print(fruits) 结果: {'apple', 'banana', 'cherry'}
clear():移除集合中的所有元素
clear() 方法用于移除集合中的所有元素。 语法: set.clear() 参数: 无。 实例: fruits = {"apple", "banana", "cherry"} fruits.clear() print(fruits) 结果: set()
copy():拷贝一个集合
copy() 方法用于拷贝一个集合。 语法 set.copy() 参数 无。 实例 fruits = {"apple", "banana", "cherry"} x = fruits.copy() print(x) 结果: {'cherry', 'banana', 'apple'}
difference():返回多个集合的差集
difference() 方法用于返回集合的差集,即返回的集合元素包含在第一个集合中,但不包含在第二个集合(方法的参数)中。 语法 set.difference(set) 参数 set -- 必需,用于计算差集的集合 实例 x = {"apple", "banana", "cherry"} y = {"google", "microsoft", "apple"} z = x.difference(y) print(z) 结果: {'cherry', 'banana'}
difference_update():移除集合中的元素,该元素在指定的集合也存在。
difference_update() 方法用于移除两个集合中都存在的元素。 difference_update() 方法与 difference() 方法的区别在于 difference() 方法返回一个移除相同元素的新集合,而 difference_update() 方法是直接在原来的集合中移除元素,没有返回值。 语法 set.difference_update(set) 参数; set -- 必需,用于计算差集的集合 实例 x = {"apple", "banana", "cherry"} y = {"google", "microsoft", "apple"} x.difference_update(y) print(x) 结果: {'cherry', 'banana'}
discard():删除集合中指定的元素
discard() 方法用于移除指定的集合元素。 该方法不同于 remove() 方法,因为 remove() 方法在移除一个不存在的元素时会发生错误,而 discard() 方法不会 语法 set.discard(value) 参数: value -- 必需,要移除的元素 实例: fruits = {"apple", "banana", "cherry"} fruits.discard("banana") print(fruits) 结果: {'cherry', 'apple'}
intersection():返回集合的交集
intersection() 方法用于返回两个或更多集合中都包含的元素,即交集。 语法 set.intersection(set1, set2 ... etc) 参数: set1 -- 必需,要查找相同元素的集合 set2 -- 可选,其他要查找相同元素的集合,可以多个,多个使用逗号 , 隔开 实例 x = {"apple", "banana", "cherry"} y = {"google", "runoob", "apple"} z = x.intersection(y) print(z) 结果: {'apple'} 计算多个集合的并集: x = {"a", "b", "c"} y = {"c", "d", "e"} z = {"f", "g", "c"} result = x.intersection(y, z) print(result) 结果: {'c'}
intersection_update():返回集合的交集。
intersection_update() 方法用于获取两个或更多集合中都重叠的元素,即计算交集。 intersection_update() 方法不同于 intersection() 方法,因为 intersection() 方法是返回一个新的集合,而 intersection_update() 方法是在原始的集合上移除不重叠的元素。 语法 set.intersection_update(set1, set2 ... etc) 参数 set1 -- 必需,要查找相同元素的集合 set2 -- 可选,其他要查找相同元素的集合,可以多个,多个使用逗号 , 隔开 实例 x = {"apple", "banana", "cherry"} y = {"google", "runoob", "apple"} x.intersection_update(y) print(x) 结果: {'apple'} 计算多个集合的并集: x = {"a", "b", "c"} y = {"c", "d", "e"} z = {"f", "g", "c"} x.intersection_update(y, z) print(x) {'c'}
isdisjoint():判断两个集合是否包含相同的元素,如果没有返回 True,否则返回 False。
isdisjoint() 方法用于判断两个集合是否包含相同的元素,如果没有返回 True,否则返回 False。。 语法: set.isdisjoint(set) 参数: set -- 必需,要比较的集合 实例 x = {"apple", "banana", "cherry"} y = {"google", "runoob", "facebook"} z = x.isdisjoint(y) print(z) 结果: True 实例: x = {"apple", "banana", "cherry"} y = {"google", "runoob", "apple"} z = x.isdisjoint(y) print(z) 结果: False
issubset():判断指定集合是否为该方法参数集合的子集
issubset() 方法用于判断集合的所有元素是否都包含在指定集合中,如果是则返回 True,否则返回 False。 语法: set.issubset(set) 参数: set -- 必需,要比查找的集合 实例 判断集合 x 的所有元素是否都包含在集合 y 中: x = {"a", "b", "c"} y = {"f", "e", "d", "c", "b", "a"} z = x.issubset(y) print(z) 结果: True 如果没有全部包含返回 False: x = {"a", "b", "c"} y = {"f", "e", "d", "c", "b"} z = x.issubset(y) print(z) 结果: False
issuperset():判断该方法的参数集合是否为指定集合的子集
issuperset() 方法用于判断指定集合的所有元素是否都包含在原始的集合中,如果是则返回 True,否则返回 False。 语法 set.issuperset(set) 参数 set -- 必需,要比查找的集合 实例 x = {"f", "e", "d", "c", "b", "a"} y = {"a", "b", "c"} z = x.issuperset(y) print(z) 结果: True 如果没有全部包含返回 False: x = {"f", "e", "d", "c", "b"} y = {"a", "b", "c"} z = x.issuperset(y) print(z) 结果: False
pop():随机移除元素
pop() 方法用于随机移除一个元素。 语法: set.pop() 参数 无 实例 fruits = {"apple", "banana", "cherry"} fruits.pop() print(fruits) 结果: {'apple', 'banana'} 输出返回值: fruits = {"apple", "banana", "cherry"} x = fruits.pop() print(x) 结果: banana
remove():移除指定元素
remove() 方法用于移除集合中的指定元素。 该方法不同于 discard() 方法,因为 remove() 方法在移除一个不存在的元素时会发生错误,而 discard() 方法不会。 语法: set.remove(item) 参数: item -- 要移除的元素 实例 fruits = {"apple", "banana", "cherry"} fruits.remove("banana") print(fruits) 结果: {'cherry', 'apple'}
symmetric_difference():返回两个集合中不重复的元素集合
symmetric_difference() 方法返回两个集合中不重复的元素集合,即会移除两个集合中都存在的元素。 语法: set.symmetric_difference(set) 参数 set -- 集合 实例 返回两个集合组成的新集合,但会移除两个集合的重复元素: x = {"apple", "banana", "cherry"} y = {"google", "runoob", "apple"} z = x.symmetric_difference(y) print(z) 结果: {'google', 'cherry', 'banana', 'runoob'}
symmetric_difference_update():移除当前集合中在另外一个指定集合相同的元素,并将另外一个指定集合中不同的元素插入到当前集合中。
symmetric_difference_update() 方法移除当前集合中在另外一个指定集合相同的元素,并将另外一个指定集合中不同的元素插入到当前集合中。 语法 set.symmetric_difference_update(set) 参数 set -- 要检测的集合 实例 x = {"apple", "banana", "cherry"} y = {"google", "runoob", "apple"} x.symmetric_difference_update(y) print(x) 结果: {'google', 'cherry', 'banana', 'runoob'}
union():返回两个集合的并集
union() 方法返回两个集合的并集,即包含了所有集合的元素,重复的元素只会出现一次。 语法 set.union(set1, set2...) 参数 set1 -- 必需,合并的目标集合 set2 -- 可选,其他要合并的集合,可以多个,多个使用逗号 , 隔开。 实例 x = {"apple", "banana", "cherry"} y = {"google", "runoob", "apple"} z = x.union(y) print(z) 结果: {'cherry', 'runoob', 'google', 'banana', 'apple'} 合并多个集合: x = {"a", "b", "c"} y = {"f", "d", "a"} z = {"c", "d", "e"} result = x.union(y, z) print(result) 结果: {'c', 'd', 'f', 'e', 'b', 'a'}
update():给集合添加元素
update() 方法用于修改当前集合,可以添加新的元素或集合到当前集合中,如果添加的元素在集合中已存在,则该元素只会出现一次,重复的会忽略。 语法: set.update(set) 参数: set -- 必需,可以是元素或集合 实例 合并两个集合,重复元素只会出现一次: x = {"apple", "banana", "cherry"} y = {"google", "runoob", "apple"} x.update(y) print(x) 结果: {'banana', 'apple', 'google', 'runoob', 'cherry'}
Python数据类型的转换
int(x [,base]):将x转换为一个整数
int() 函数用于将一个字符串或数字转换为整型。 语法: class int(x, base=10) 参数: x -- 字符串或数字。 base -- 进制数,默认十进制。 实例 >>>int() # 不传入参数时,得到结果0 0 >>> int(3) 3 >>> int(3.6) 3 >>> int('12',16) # 如果是带参数base的话,12要以字符串的形式进行输入,12 为 16进制 18 >>> int('0xa',16) 10 >>> int('10',8) 8
float(x):将x转换到一个浮点数
float() 函数用于将整数和字符串转换成浮点数。 语法: class float([x]) 参数: x -- 整数或字符串 实例: >>>float(1) 1.0 >>> float(112) 112.0 >>> float(-123.6) -123.6 >>> float('123') # 字符串 123.0
complex(real [,imag]):创建一个复数
complex() 函数用于创建一个值为 real + imag * j 的复数或者转化一个字符串或数为复数。如果第一个参数为字符串,则不需要指定第二个参数。。 语法: class complex([real[, imag]]) 参数: real -- int, long, float或字符串; imag -- int, long, float; 实例 >>>complex(1, 2) (1 + 2j) >>> complex(1) # 数字 (1 + 0j) >>> complex("1") # 当做字符串处理 (1 + 0j) # 注意:这个地方在"+"号两边不能有空格,也就是不能写成"1 + 2j",应该是"1+2j",否则会报错 >>> complex("1+2j") (1 + 2j)
str(x):将对象 x 转换为字符串
str() 函数将对象转化为适于人阅读的形式。 语法: class str(object='') 参数 object -- 对象。 实例 >>>s = 'RUNOOB' >>> str(s) 'RUNOOB' >>> dict = {'runoob': 'runoob.com', 'google': 'google.com'}; >>> str(dict) "{'google': 'google.com', 'runoob': 'runoob.com'}" >>>
repr(x):将对象 x 转换为表达式字符串
repr() 函数将对象转化为供解释器读取的形式。 语法 repr(object) 参数 object -- 对象。 实例 >>>s = 'RUNOOB' >>> repr(s) "'RUNOOB'" >>> dict = {'runoob': 'runoob.com', 'google': 'google.com'}; >>> repr(dict) "{'google': 'google.com', 'runoob': 'runoob.com'}"
eval(str):用来计算在字符串中的有效Python表达式,并返回一个对象
eval() 函数用来执行一个字符串表达式,并返回表达式的值。 语法 eval(expression[, globals[, locals]]) 参数 expression -- 表达式。 globals -- 变量作用域,全局命名空间,如果被提供,则必须是一个字典对象。 locals -- 变量作用域,局部命名空间,如果被提供,可以是任何映射对象。 实例 >>>x = 7 >>> eval( '3 * x' ) 21 >>> eval('pow(2,2)') 4 >>> eval('2 + 2') 4 >>> n=81 >>> eval("n + 4") 85
tuple(s):将序列 s 转换为一个元组
tuple 函数将列表转换为元组。 语法 tuple( seq ) 参数 seq -- 要转换为元组的序列。 实例 >>>list1= ['Google', 'Taobao', 'Runoob', 'Baidu'] >>> tuple1=tuple(list1) >>> tuple1 ('Google', 'Taobao', 'Runoob', 'Baidu')
list(s):将序列 s 转换为一个列表
list() 方法用于将元组或字符串转换为列表。 注:元组与列表是非常类似的,区别在于元组的元素值不能修改,元组是放在括号中,列表是放于方括号中 语法: list( seq ) 参数 seq -- 要转换为列表的元组或字符串。 实例 aTuple = (123, 'Google', 'Runoob', 'Taobao') list1 = list(aTuple) print ("列表元素 : ", list1) str="Hello World" list2=list(str) print ("列表元素 : ", list2) 结果: 列表元素 : [123, 'Google', 'Runoob', 'Taobao'] 列表元素 : ['H', 'e', 'l', 'l', 'o', ' ', 'W', 'o', 'r', 'l', 'd']
set(s):转换为可变集合
set() 函数创建一个无序不重复元素集,可进行关系测试,删除重复数据,还可以计算交集、差集、并集等。 语法 class set([iterable]) 参数说明: iterable -- 可迭代对象对象 实例 >>>x = set('runoob') >>> y = set('google') >>> x, y (set(['b', 'r', 'u', 'o', 'n']), set(['e', 'o', 'g', 'l'])) # 重复的被删除 >>> x & y # 交集 set(['o']) >>> x | y # 并集 set(['b', 'e', 'g', 'l', 'o', 'n', 'r', 'u']) >>> x - y # 差集 set(['r', 'b', 'u', 'n'])
dict(d):创建一个字典。d 必须是一个 (key, value)元组序列。
dict() 函数用于创建一个字典。 语法 class dict(**kwarg) class dict(mapping, **kwarg) class dict(iterable, **kwarg) 参数说明: **kwargs -- 关键字 mapping -- 元素的容器。 iterable -- 可迭代对象。 实例 >>>dict() # 创建空字典 {} >>> dict(a='a', b='b', t='t') # 传入关键字 {'a': 'a', 'b': 'b', 't': 't'} >>> dict(zip(['one', 'two', 'three'], [1, 2, 3])) # 映射函数方式来构造字典 {'three': 3, 'two': 2, 'one': 1} >>> dict([('one', 1), ('two', 2), ('three', 3)]) # 可迭代对象方式来构造字典 {'three': 3, 'two': 2, 'one': 1}
frozenset(s):转换为不可变集合
frozenset() 返回一个冻结的集合,冻结后集合不能再添加或删除任何元素。 语法 class frozenset([iterable]) 参数 iterable -- 可迭代的对象,比如列表、字典、元组等等。 实例 >>>a = frozenset(range(10)) # 生成一个新的不可变集合 >>> a frozenset([0, 1, 2, 3, 4, 5, 6, 7, 8, 9]) >>> b = frozenset('runoob') >>> b frozenset(['b', 'r', 'u', 'o', 'n']) # 创建不可变集合
chr(x):将一个整数转换为一个字符
chr() 用一个范围在 range(256)内的(就是0~255)整数作参数,返回一个对应的字符。 语法 chr(i) 参数 i -- 可以是10进制也可以是16进制的形式的数字 实例 >>>print chr(0x30), chr(0x31), chr(0x61) # 十六进制 0 1 a >>> print chr(48), chr(49), chr(97) # 十进制 0 1 a
ord(x):将一个字符转换为它的整数值
ord() 函数是 chr() 函数(对于8位的ASCII字符串)或 unichr() 函数(对于Unicode对象)的配对函数,它以一个字符(长度为1的字符串)作为参数,返回对应的 ASCII 数值,或者 Unicode 数值,如果所给的 Unicode 字符超出了你的 Python 定义范围,则会引发一个 TypeError 的异常。 语法 ord(c) 参数 c -- 字符。 实例 >>>ord('a') 97 >>> ord('b') 98 >>> ord('c') 99
hex(x):将一个整数转换为一个十六进制字符串
hex() 函数用于将10进制整数转换成16进制,以字符串形式表示。 语法 hex(x) 参数: x -- 10进制整数 实例 >>>hex(255) '0xff' >>> hex(-42) '-0x2a' >>> hex(1L) '0x1L' >>> hex(12) '0xc' >>> type(hex(12)) <class 'str'> # 字符串
oct(x):将一个整数转换为一个八进制字符串
oct() 函数将一个整数转换成8进制字符串。 语法 oct(x) 参数说明: x -- 整数。 实例 >>>oct(10) '012' >>> oct(20) '024' >>> oct(15) '017'
布尔值(Bool)


 浙公网安备 33010602011771号
浙公网安备 33010602011771号