

访问必应主页网页
1、Requests库概述
requests库支持非常丰富的链接访问功能,包括:国际域名和URL获取、HTTP常链接和链接缓存、HTTP会话和Cookie保持、浏览器使用风格SSL验证、基本的摘要认证、有效的键值对Cookie记录、自动解压缩、文件分块上传、HTTP(S)代理功能、链接超时处理、流数据下载等。有关requests库更多的介绍可访问:http://docs.python-requests.org
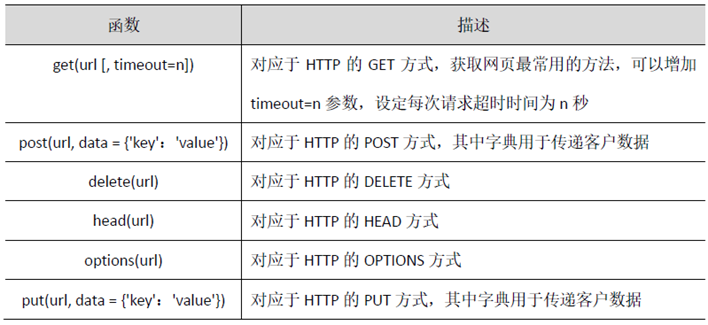
2、requests库中访问网页的请求函数
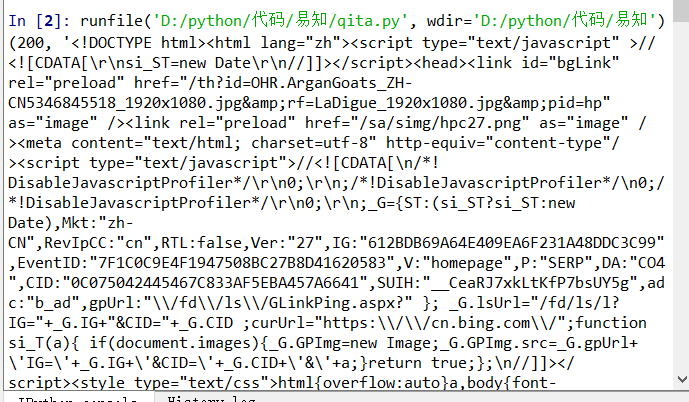
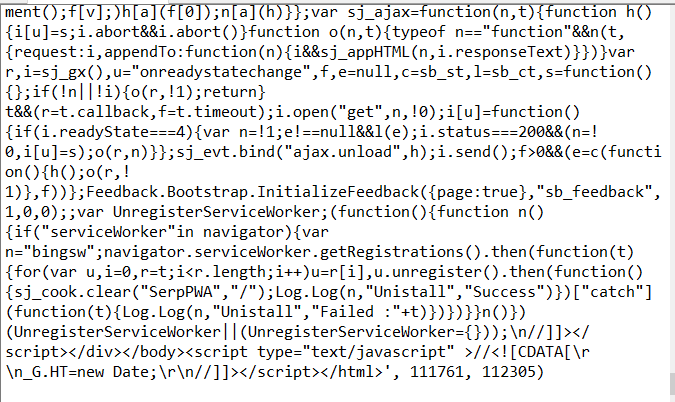
3、用requeses库的个体()函数访问必应主页20次,打印返回状态,text内容,并且计算text()属性和content属性返回网页内容的长度
import requests def getHTMLText(self): try: for i in range(0,20): #访问20次 r = requests.get(url, timeout=30) r.raise_for_status() #如果状态不是200,引发异常 r.encoding = 'utf-8' #无论原来用什么编码,都改成utf-8 return r.status_code,r.text,r.content,len(r.text),len(r.content) ##返回状态,text和content内容,text()和content()网页的长度 except: return "" url = "https://cn.bing.com/" print(getHTMLText(url))

 浙公网安备 33010602011771号
浙公网安备 33010602011771号