adversarial learing for constrained image splicing detection and localization based on atrous convolution 阅读
论文题目 基于Atrous卷积的约束图像拼接检测与定位对抗学习
年份出处 2018 IEEE
作者 Yaqi Liu, Xianfeng Zhao, Xiaobin Zhu, and Yun Cao
数据集
训练:使用MS COCO合成数据集
测试:The generated datasets,The paired CASIA datasetThe MFC2018 datasets,The Reddit dataset,The PS-Battles dataset
实验配置
Intel(R) Core(TM) i7-5930K CPU @ 3.50GHz, 64GB RAM and a single GPU (TITAN X).
评价指标
评估定位性能:像素级IoU分数、MCC、NMM
评估测试性能:precision、recall、f1 score、AUC、EER、detection rate、False Alarm rate
摘要
本文设计了一个网络,基于对抗学习的方式生成篡改mask。整体包括3部分:
- 基于空洞卷积的深度匹配网络DMAC,输入两个图像,输出两幅图的可疑区域。
- 检测网络(detection)找出两个对应候选mask的不一致
- 区分网络(discriminative)驱动DMAC生成与groundtruth难以区分的mask
介绍
CISDL任务是,输入查询图像P和原图D,检测D是否被拼接到P。
DMVN首先提出了CISDL的方法,在CASIA和nimble 2017上的检测表现不错。但是,定位表现没有定性讨论,只从视觉效果上比较。DMVN仅比较VGG的高级低分辨率特征图,检测准确边界和小区域的能力不太好。标签变量由视野受限的卷积滤波器进行局部预测,难以利用大范围信息和多尺度特征
相关工作
- 密集匹配
CISDL实际是密集匹配任务。传统的密集匹配是通过比较在兴趣点周围提取的局部描述符来实现的。DMVN直接与26-29的方法比较。
近年来,许多工作使用卷积神经网络提取全局特征进行密集匹配,30-32提出许多网络来估计inter-frame motion 或者 instance-level homography。虽然这些方法试图寻找图像之间的高精度对应,但它们只需要搜索外观变化和背景杂波background clutter非常有限的周边区域。33-35远程非精确类目录级匹配long-range inexact category-level matchin,目的是寻找具有相似外观的同一类对象。
而CISDL任务需要发现远程高精度对应long-range high-precision correspondences。 - 全卷积网络
- 对抗生成网络
网络结构
DMAC有3部分: 图2是整体结构
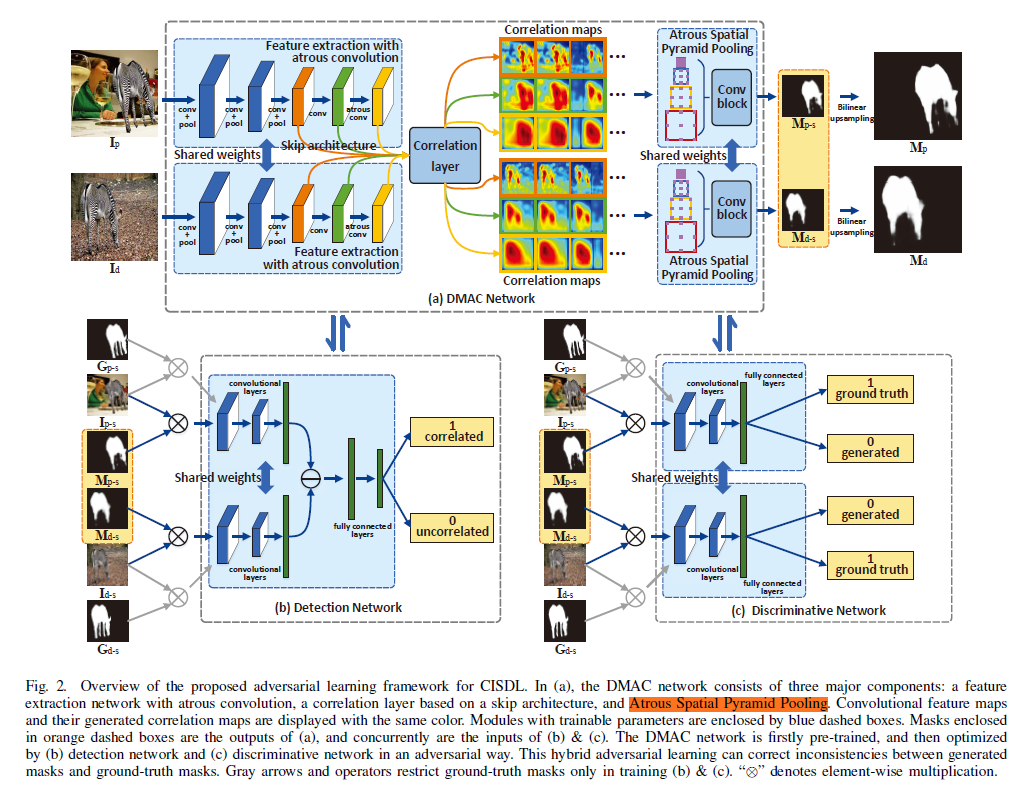
a 可看做生成器,b、c看做是判别器。
a 是DMAC网络,包括特征提取,相关性计算,生成mask。
蓝色虚线框内的模型具有可训练参数。
橘色虚线框是a的输出结果,同时是b、c的输入。首先对DMAC网络进行预处理,然后通过(b)检测网络和(c)判别网络进行对抗性优化。这种混合的对抗性学习可以纠正生成的mask和groundtruth之间的不一致性。灰色箭头和运算符只在训练时约束b、c。
采用滑动窗口匹配解决高分辨率图像匹配。
DMAC网络
1. 特征提取
利用稀疏卷积丰富卷积特征的空间信息。
图3 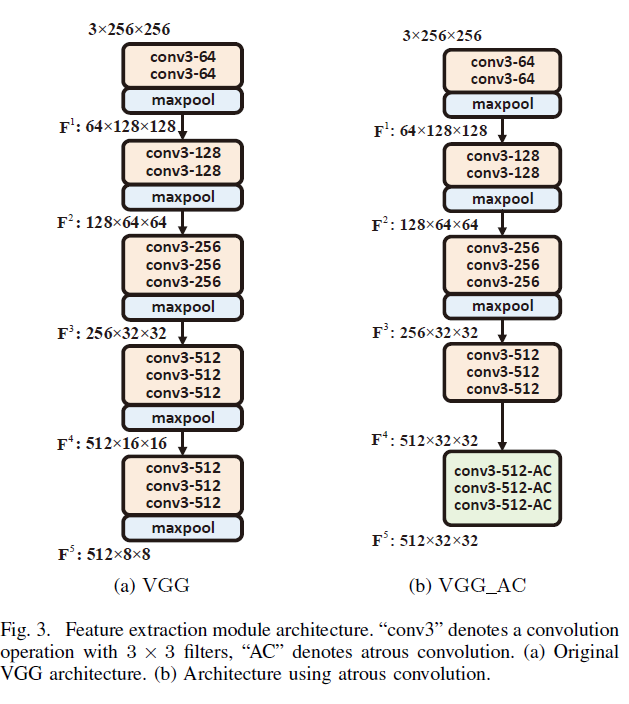
2. 相关性计算
correlation计算是deep matching 的关键问题。使用跳跃结构的相关性计算算法如算法1

相关与卷积
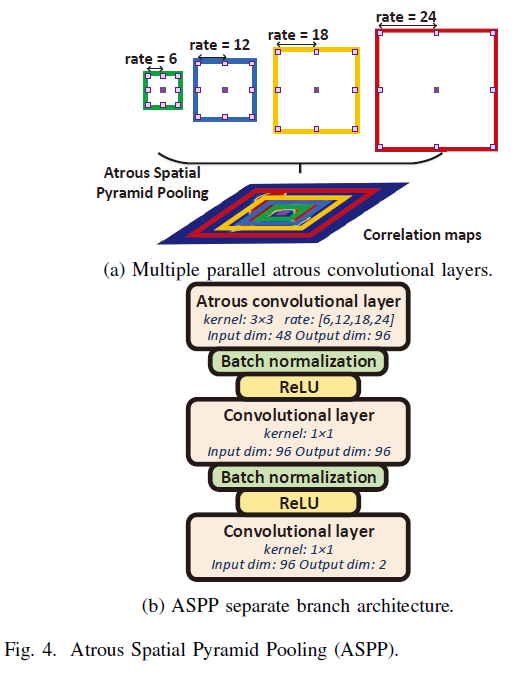
3. mask生成
稀疏空间金字塔池化捕获多尺度信息
篡改区域是在多尺度下的,使用ASPP捕捉相关图不同尺度的信息,然后生成最终mask。如图4
检测网络&判别网络
基于跳跃结构的相关层 初始特征比较
空洞空间金字塔池化 多尺度目标区域问题
dis和det在结构上是孪生网络,权重和参数共享。如图5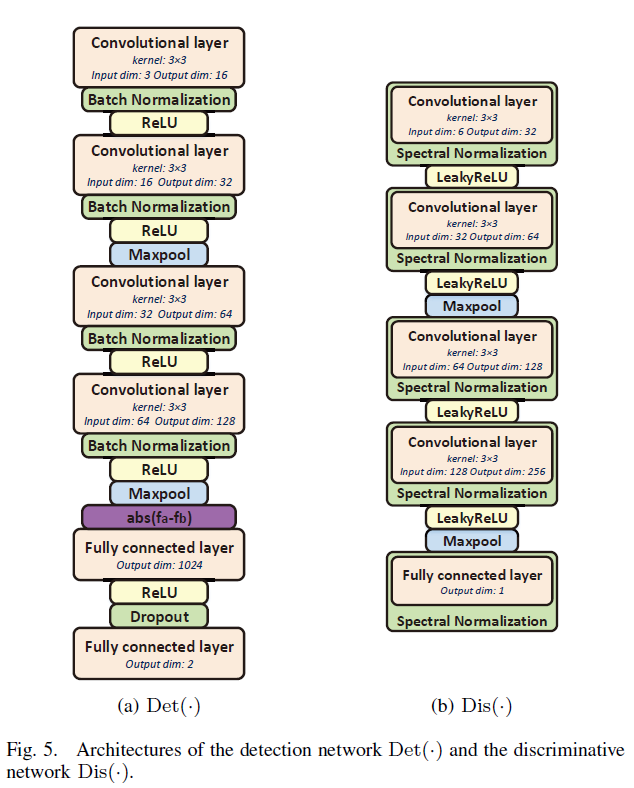
det网络:特征提取部分包括四个卷积层,batch normalize层,relu层。使用maxpool层对特征图下采样,提高特征图的稳定性。紫色部分是对两个展开的特征逐像素相减,使用绝对值作为新特征。两个全连接层生成相关分数。
dis网络:包括四个卷积层,spectral normalize层,leaky relu,一个全连接层。
使用 spectral normalize稳定网络训练,spectral normalize[55]具有计算量小、易于集成到现有实现中的特点,在实验中表现出良好的性能。
LeakyRelu可以让一小部分负梯度值通过,使得来自鉴别器的梯度更强地流入发生器。
对抗学习loss
多任务损失函数 公式8

Lce 公式9

det网络的loss 公式11
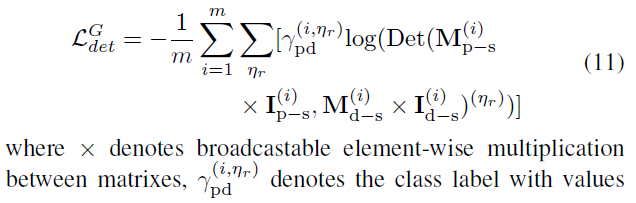
优化det的loss 公式12
dis网络的binary cross entropy loss 公式13
优化dis网络的binary cross entropy loss 公式14
dis网络的hinge loss 公式15
优化dis网络的hinge loss 公式16
算法2

minibatch:在每一代训练之前,对数据进行随机混洗,然后创建 mini-batches,对每一个mini-batch,用梯度下降训练网络权重。因为这些 batches 是随机的,你其实是在对每个 batch 做随机梯度下降(SGD)
样本分成minibatch-->DMAC生成预测mask-->随机梯度下降更新det网络-->随机梯度下降更新dis网络(分别使LdetD、LdisD最小化)
样本分成minibatch-->DMAC生成预测mask-->随机梯度下降更新DMAC(最后最小化Lce)
基于滑动窗口的匹配
图6 是基于滑动窗口的匹配策略流程图

把输入图像resize成B1乘B1,窗口大小为Bs,共有Nsw个窗口,进行Nsw乘Nsw次deep matching 操作。
实验
训练数据集
使用MS COCO合成了1035255个训练对。
MS COCO是用于目标检测,语义分割的数据集。包括82783训练图像,40504测试图像。本文合成训练和测试的图像对,图像大小为512×512。输入网络的图像大小为256×256。
合成训练&测试图像:在不同的变换下随机选择一个带注释的区域(占整幅图的1~50%),并将其粘贴到另一个随机选择的训练图像中。得到2正1负训练对。有移动、旋转、缩放、光照、变形变换。
测试数据集
- The generated datasets,共有63000图像对。根据篡改区域大小分为难中易三组,6个子类,每类有3000图像对。 (合成图像的代码 )
- The paired CASIA dataset:DMVN合成的数据集,本文用于检测测试。
- The MFC2018 datasets:
Media forensicschallenge 2018 包含1327正样本对和16673负样本对 - The Reddit dataset:本文收集9947个可用的图像对。(Image provenance analysis at scale 的作者从在线社区收集了reddit 数据集)
- The PS-Battles dataset:共102028图像,11142个子类。(The ps-battles dataset - an image collection for image manipulation detection的作者收集而来)
评价指标
评估定位性能:像素级IoU分数、MCC、NMM
评估测试性能:precision、recall、f1 score、AUC、EER
交并比(Intersection-over-Union,IoU)是产生的候选框(candidate bound)与原标记框(ground truth bound)的交叠率即它们的交集与并集的比值。最理想情况是完全重叠,即比值为1
MCC(Matthews correlation coefficient)马修斯相关系数,描述实际分类与预测分类之间的相关系数,它的取值范围为[-1,1],取值为1时表示对受试对象的完美预测,取值为0时表示预测的结果还不如随机预测的结果,-1是指预测分类和实际分类完全不一致
EER(Equal Error Rate)等错误率
exirFAR= FP/(FP+TN)错误接受率(不该接受的样本里你接受的比例) 假正例/(假正例+真反例)
FRR=FN/(TP+FN)错误拒绝率(不该拒绝的样本里你拒绝的比例) 假反例/(真正例+假反例)
画出FFR和FAR的坐标图,交点就是EER值。
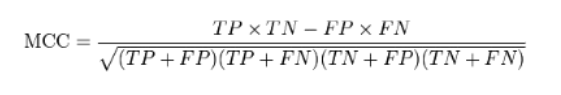
detection rate 命中率:D=TP/(TP+FN) 真正例/(真正例+假反例)
False Alarm rate 误报率:F=FP/(FP+TN) 假正例/(假正例+真反例)
在generated sets
一步步分析
1 DMVN
2 DMVN-BN 在DMVN的InceptionBlocks加入BatchNormalize层,来加速收敛速度,比1好
DMVN-BN code
3 DMVN-ASPP-S 用ASPP with smaller atrous rates代替DMVN-BN的反卷积层
4 DMAC-ASPP-S-noskip 无跳跃结构
5 DMAC-ASPP-L 用ASPP with larger atrous rates代替DMVN-BN的反卷积层,two output masks with softmax,比6好
6 DMAC-ASPP-L-sigmoid ,a single output with sigmoid
因此,在下文中采用DMAC-ASPP-L,记作DMAC
图7 the combination sets的IoU分数结果。表1 the combination sets的定位测试结果
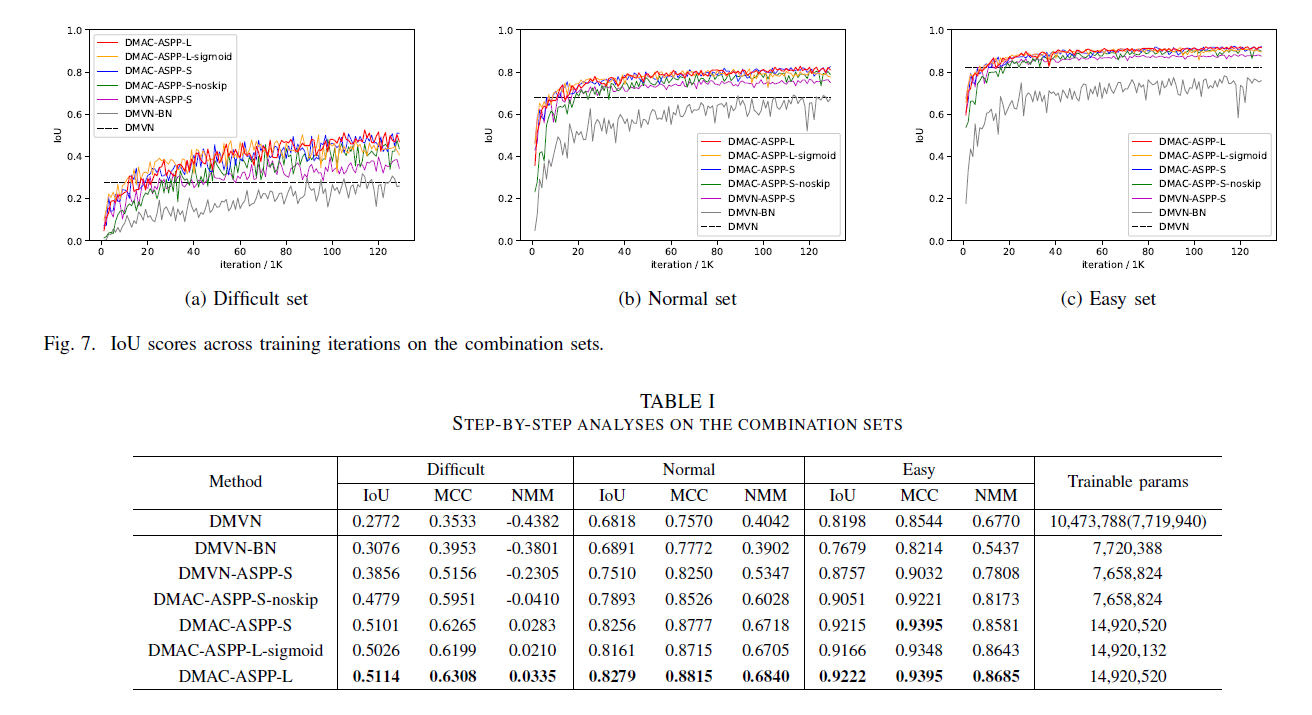
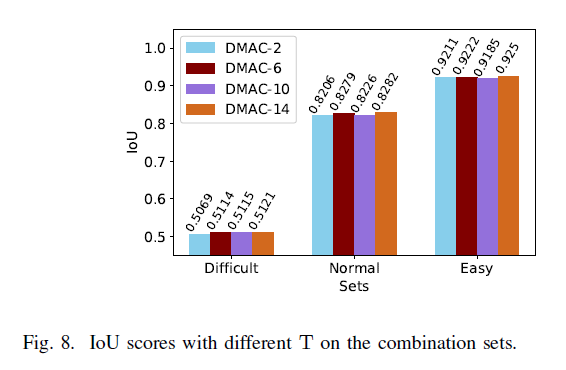
图8结果表明DMVN的T=2时,iou高
对抗学习参数分析
研究 λdet, λdis in formula (8)和learning rate (LR),
做实验选择discriminative loss,(binary cross entropy(bce),the hinge loss (hin))。
结果为DMAC+adv-bce with λdet, λdis=0.01,LR = 10e-5, 记作DMAC+adv。图10
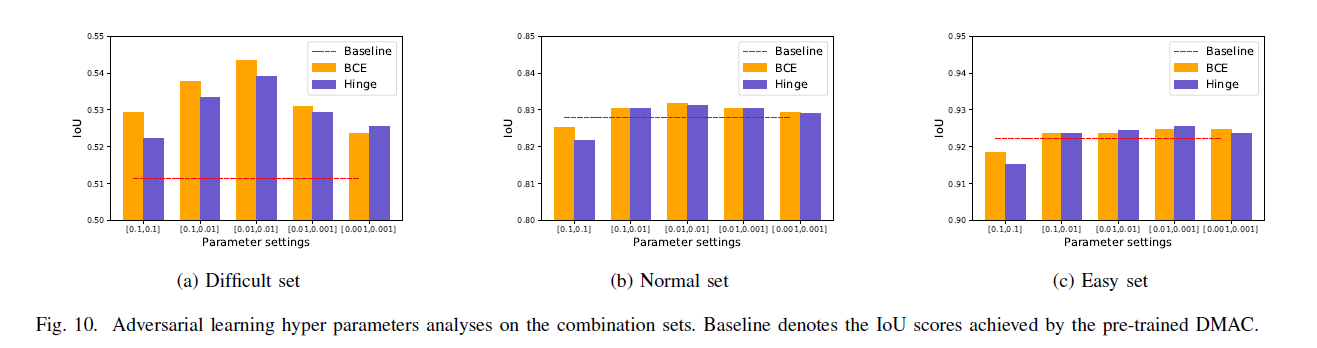
做验证实验证明the detection and discriminative losses都有效果。
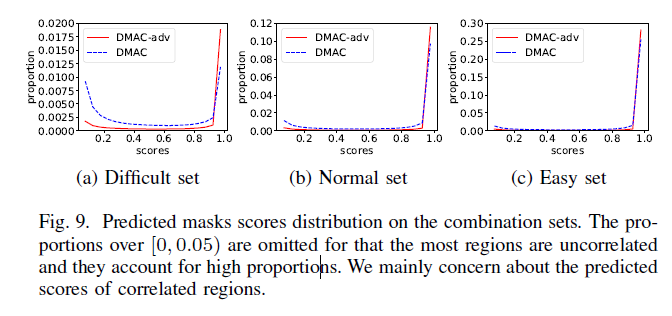
做实验证明对抗学习的效果,对比DMAC和DMAC-adv在combination sets的分数分布,看到相关区域预测得分最高,高于0.95分,在[0.05,0.95]范围内得分较少。图9
不变性分析
三种模型中,DMAC-adv效果最好。六种变换中,scale变换效果最差。
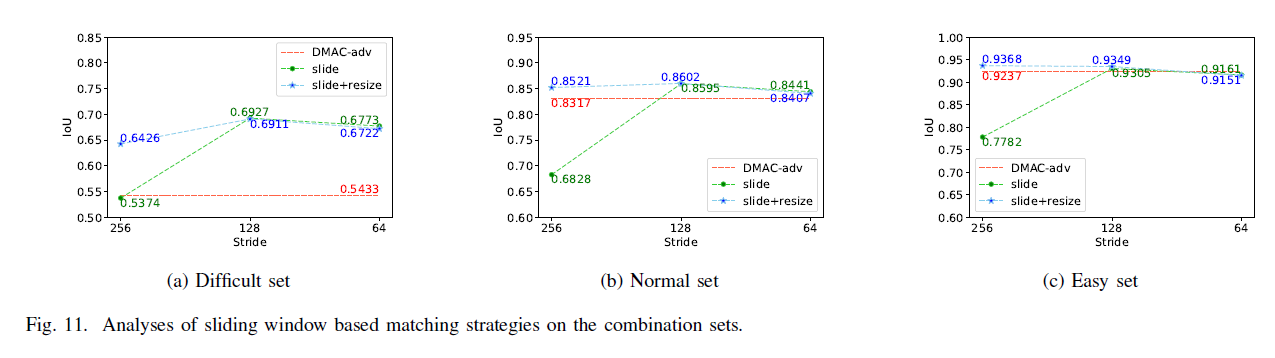
滑动窗口策略分析
结合滑动窗口匹配结果和调整大小的匹配结果,图11,slide+resize效果好。
复杂性分析
相比DMVN,DMAC的训练参数更多,时间更长。
在 CASIA 和 MFC2018
图13、14
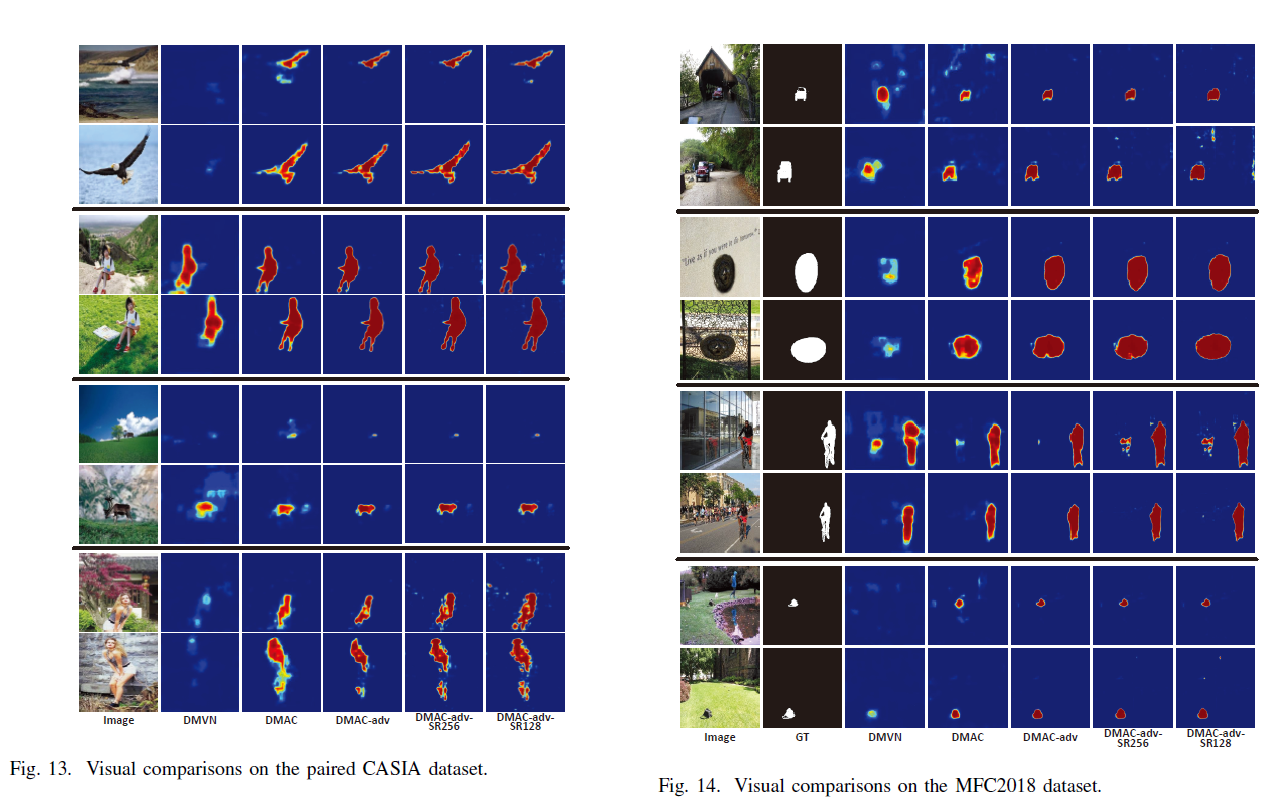
结合指标分析,推荐DMAC-adv
在 reddit 和 ps-battles
经过分析,推荐DMAC-adv
结论
1实时的
2对于一般变换鲁棒性好
3复杂变换不好检测,如challenging scale, flip, deformation 等。
4受相关性计算的限制,只能处理固定大小的图像,高分辨率图像的小区域不好检测
5滑动窗口可解决4,但计算开销大
6实际应用时,未篡改图像占多数,可能会出现大量虚假警报
7DMVN的作者改进了他们的模型,表明了DMAC在复制粘贴的前景

 浙公网安备 33010602011771号
浙公网安备 33010602011771号