
敏捷冲刺四
敏捷冲刺四
Task1:团队TSP
| 团队任务 | 预估时间 | 实际时间 | 完成日期 |
|---|---|---|---|
| 搜索引擎相关内容了解 | 300 | 500 | 11-5 |
| 数据库表的创建 | 180 | 150 | 11-8 |
| 学院网站的爬取 | 210 | 460 | 11-10 |
| 建立数据库索引 | 190 | -- | -- |
| 代码测试 | 180 | -- | -- |
| 前端页面的设计 | 240 | -- | -- |
| 前后端的交互 | 300 | -- | -- |
| 搜索引擎测试 | 260 | -- | -- |
Task2:描述项目进展
| 成员 | 任务安排 | 预期任务量/小时 |
|---|---|---|
| 秦玉(组长) | 分配任务,前端设计 | 180 |
| 陈晓菲 | 和小组人员一起编写爬虫代码,攻克难关 | 180 |
| 韩烨 | 前端模板的设计 | 180 |
| 姚雯婷 | 和小组人员一起编写爬虫代码,攻克难关 | 180 |
| 罗佳 | 完成团队TSP表格,完成第四次冲刺博客园,实践、初步编写代码 | 180 |
| 高天 | 完成团队TSP表格,完成第四次冲刺博客园,实践、初步编写代码 | 180 |
Task3:目前面临的困难
这次的困难主要出现在爬虫的问题上,主要有下面几个方面:
问题一:
在进入回调函数后,但数据库里仍然出现不了数据。
问题二:
数据库里的数据只有13条。
Task4:目前取得的成果
问题一解决方法:
- 首先先对xpath的正确性进行测试,尝试对获取到的url进行输出,发现有网址输出,排除解析错误的原因。
- 对数据库的连接进行了确定,发现可以连接成功。
- 最后发现真正的原因是因为前后修改代码的时候,有部分冗余代码忘记注释,导致写入数据库失败,注释掉冗余代码后,成功写入数据库。
问题二解决方法:
通过对能够写入数据库的网页以及写入不进数据库的网页进行查看,如下图,

发现只有红色标题的网页能够被爬取,继续对源代码进行查看,发现了根本原因:


两个网页虽然都是将标题放在class为titlestyle124904,但是!!!我们学院为了设置红色标题,居然随意的直接强行给标题加一个span标签……(我们可是正儿八经的计算机学院啊喂),然后导致xpath的设置
item_loader.add_xpath("title", "//td[@class='titlestyle124904']/span/text()")
只对span标签下有标题的内容适用了。
于是将xpath进行修改:
item_loader.add_xpath("title", "//td[@class='titlestyle124904']/text()")
于是就可以对红黑标题的内容都进行爬取了,但是对于红色标题的网页,爬取不到题目,能够爬取到其他的属性。
Task5:项目燃尽图
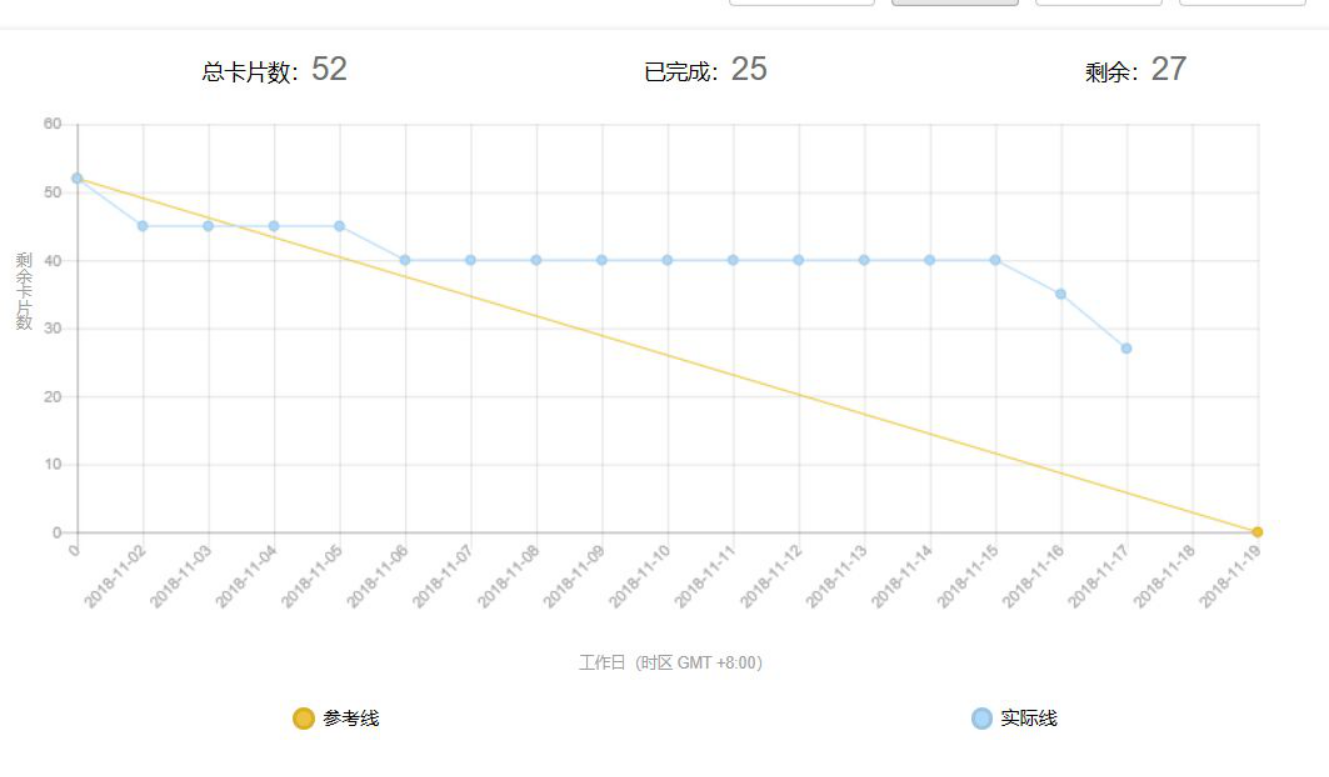
Task6:提交历史截图
Task7:站立式会议照片


 浙公网安备 33010602011771号
浙公网安备 33010602011771号