


c#环境使用yolov8
1. 训练及模型生成环境搭建
windows安装conda,下载地址Download Success | Anaconda。
打开Anaconda Prompt
创建虚拟环境,python版本选择3.8.10:
conda create -n yolov8_onnx python=3.8.10
查当前有的环境:
conda info --envs
切换到新建的虚拟环境 yolov8_onnx:
conda activate yolov8_onnx
安装必要的python库:
pip install ultralytics onnx onnxruntime
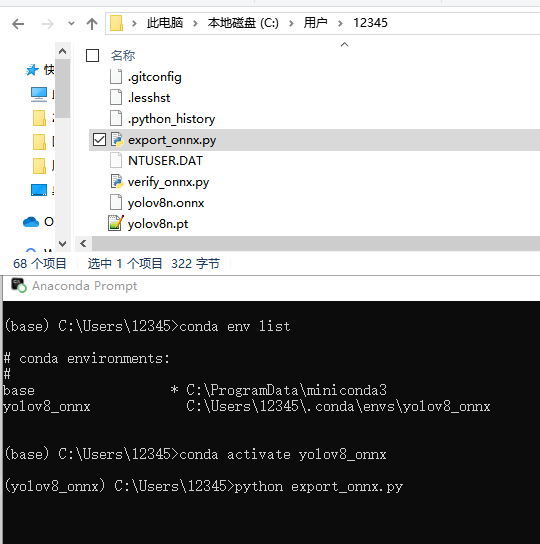
构建下面python脚本,脚本名为export_onnx.py:
from ultralytics import YOLO
# 加载模型。你可以替换为你自定义模型的路径
model = YOLO("yolov8n.pt") # 使用官方预训练模型
# 或者使用你自定义训练的模型
# model = YOLO("path/to/your/best.pt")
# 导出模型为ONNX格式
model.export(format="onnx", imgsz=640, simplify=True)
运行export_onnx.py脚本生成yolov8n.onnx模型文件,可以在conda用户名路径下找到yolov8n.onnx文件。
2. c#环境配置
.net版本切换:
.net Framwork 4.6.1
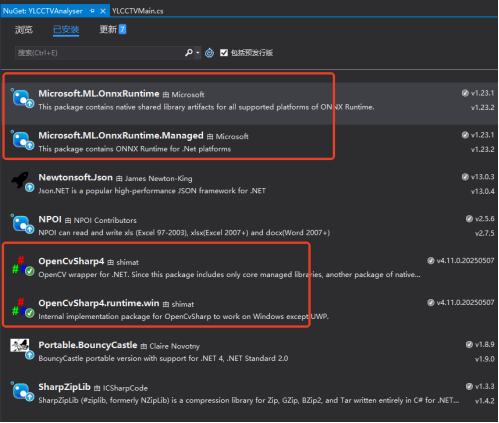
NuGet三方库安装:
Microsoft.ML.OnnxRuntime:用于运行ONNX模型的核心库。
OpenCvSharp4:用于图像处理,例如调整图像尺寸、色彩空间转换等。
OpenCvSharp4.runtime.win:OpenCvSharp的Windows运行时依赖。
性能考量:在GPU环境下,可以尝试使用Microsoft.ML.OnnxRuntime.Gpu包,并通过SessionOptions配置CUDA执行提供程序,以加速推理
//初始化YOLOv8实例 using (var yolo = new Yolov8OnnxDetector("best.onnx", "best.names")) // "yolov8n.onnx", "coco.names" { string testImage = "test_image.jpg"; OpenFileDialog openFileDialog = new OpenFileDialog(); openFileDialog.FileName = ""; string tmp1 = Resources.String16_ProjF; openFileDialog.Filter = tmp1 + "(*.png)|*.png|" + tmp1 + "(*.jpg)|*.jpg"; // tmp + "(*.CTS)|*.CTS|" + tmp1 + "(*.CTP)|*.CTP" if (openFileDialog.ShowDialog() == DialogResult.Cancel) return; _isLoadPileFiles = true; string suf = openFileDialog.FileName.Substring(openFileDialog.FileName.Length - 4).ToUpper(); if (suf.Equals(".PNG") || suf.Equals(".JPG")) { //工程文件 testImage = openFileDialog.FileName; } // 加载待检测图像 using (var image = new Mat(testImage)) { // 进行推理 List<Prediction> predictions = yolo.Predict(image); Console.WriteLine(predictions.Count); // 在图像上绘制检测结果 foreach (var pred in predictions) { Cv2.Rectangle(image, pred.Box, Scalar.Red, 2); string label = $"{pred.Label} ({pred.Confidence:P2})"; Cv2.PutText(image, label, new OpenCvSharp.Point(pred.Box.X, pred.Box.Y - 5), HersheyFonts.HersheySimplex, 0.5, Scalar.Red, 1); } // 显示或保存结果图像 Cv2.ImShow("YOLOv8 Detection", image); Cv2.WaitKey(0); Cv2.DestroyAllWindows(); } }
using Microsoft.ML.OnnxRuntime; using OpenCvSharp; using System; using System.Collections.Generic; using System.Linq; using System.Text; using System.Threading.Tasks; using Microsoft.ML.OnnxRuntime.Tensors; using System.IO; namespace YLCCTVAnalyser.yolov8 { /// <summary> /// YOLOv8 ONNX 目标检测器类 /// 专为 .NET Framework 4.6.1 环境设计的 YOLOv8 模型推理封装 /// 实现完整的图像预处理、模型推理、后处理流程 /// </summary> public class Yolov8OnnxDetector : IDisposable { private InferenceSession _session; // ONNX Runtime 推理会话实例 private readonly string[] _labels; // 类别标签数组(从coco.names等文件加载) private readonly Size _modelSize = new Size(640, 640); // YOLOv8标准输入尺寸 /// <summary> /// 构造函数 - 初始化 YOLOv8 ONNX 检测器 /// 功能:创建ONNX推理会话,加载类别标签,准备模型运行环境 /// 注意:此构造函数会加载整个模型到内存,耗时操作应在程序初始化时执行 /// </summary> /// <param name="modelPath">ONNX模型文件路径(.onnx文件)</param> /// <param name="labelsPath">类别标签文件路径(每行一个类别名称的文本文件)</param> public Yolov8OnnxDetector(string modelPath, string labelsPath) { // 初始化ONNX Runtime推理会话,加载模型文件 _session = new InferenceSession(modelPath); // 从文本文件加载所有类别名称到内存数组 _labels = System.IO.File.ReadAllLines(labelsPath); } /// <summary> /// 主预测函数 - 执行完整的目标检测流程 /// 功能:协调预处理、模型推理、后处理三个核心步骤 /// 这是类的主要对外接口,接收原始图像返回检测结果 /// </summary> /// <param name="image">输入的OpenCV Mat图像对象</param> /// <returns>检测结果列表,包含边界框、置信度、类别标签</returns> public List<Prediction> Predict(Mat image) { // 步骤1:图像预处理 - 将原始图像转换为模型输入格式 var input = PreprocessImage(image); // 步骤2:准备模型输入 - 创建ONNX Runtime可识别的输入对象 var inputs = new List<NamedOnnxValue> { NamedOnnxValue.CreateFromTensor("images", input) // 输入名称必须与模型匹配 }; // 步骤3:模型推理 - 执行ONNX模型前向计算 using (IDisposableReadOnlyCollection<DisposableNamedOnnxValue> results = _session.Run(inputs)) { // 步骤4:后处理 - 解析模型输出,应用过滤和优化 return Postprocess(results, image); } } /// <summary> /// 图像预处理函数 /// 功能:将原始BGR图像转换为YOLOv8模型期望的输入格式 /// 处理流程: /// 1. 调整图像尺寸到640x640(保持长宽比可能会丢失,实际应用可改进) /// 2. 转换色彩空间BGR→RGB(模型训练通常使用RGB格式) /// 3. 像素值归一化到[0,1]范围(提高模型数值稳定性) /// 4. 转换为NCHW格式张量[1,3,640,640](模型标准输入格式) /// </summary> /// <param name="image">原始OpenCV图像(BGR格式,任意尺寸)</param> /// <returns>预处理后的4维张量,可直接输入ONNX模型</returns> private DenseTensor<float> PreprocessImage(Mat image) { // 步骤1:调整图像尺寸到模型输入大小(640x640) // 注意:此处直接缩放可能失真,生产环境建议保持宽高比 Mat resized = new Mat(); Cv2.Resize(image, resized, _modelSize); // 步骤2:转换色彩空间 BGR → RGB // OpenCV默认BGR格式,但大多数模型训练使用RGB格式 Mat rgb = new Mat(); Cv2.CvtColor(resized, rgb, ColorConversionCodes.BGR2RGB); // 步骤3:创建4维张量 [batch_size=1, channels=3, height=640, width=640] var tensor = new DenseTensor<float>(new[] { 1, 3, _modelSize.Height, _modelSize.Width }); // 步骤4:逐像素处理,填充张量数据 // 使用嵌套循环确保数据布局正确,避免内存拷贝错误 for (int y = 0; y < rgb.Height; y++) { for (int x = 0; x < rgb.Width; x++) { // 获取RGB像素值 Vec3b pixel = rgb.At<Vec3b>(y, x); // 归一化到[0,1]并按照NCHW格式填充 tensor[0, 0, y, x] = pixel[0] / 255.0f; // R通道 tensor[0, 1, y, x] = pixel[1] / 255.0f; // G通道 tensor[0, 2, y, x] = pixel[2] / 255.0f; // B通道 } } return tensor; } /// <summary> /// 后处理函数 - 解析模型原始输出并提取有意义信息 /// 功能:将模型输出的数值张量转换为实际检测结果 /// 处理流程: /// 1. 提取模型输出张量([1,84,8400]格式) /// 2. 解析每个检测框的坐标和类别置信度 /// 3. 应用置信度阈值过滤低质量检测 /// 4. 将归一化坐标转换回原始图像像素坐标 /// 5. 应用非极大值抑制去除重复检测 /// </summary> /// <param name="results">ONNX Runtime推理结果集合</param> /// <param name="originalImage">原始图像(用于坐标映射)</param> /// <returns>结构化检测结果列表</returns> private List<Prediction> Postprocess(IDisposableReadOnlyCollection<DisposableNamedOnnxValue> results, Mat originalImage) { var predictions = new List<Prediction>(); // 步骤1:获取模型输出张量(假设第一个输出包含检测结果) var output = results.First().AsTensor<float>(); // YOLOv8输出维度解析:[batch_size, dimensions, num_proposals] // [1, 84, 8400] - 1:批大小, 84:4坐标+80类别, 8400:锚点数量 int dimensions = output.Dimensions[1]; // 84 = 4(box) + 80(coco classes) int numProposals = output.Dimensions[2]; // 8400个检测提议 float confidenceThreshold = 0.5f; // 置信度阈值,过滤不可靠检测 // 步骤2:遍历所有检测提议(8400个) for (int i = 0; i < numProposals; i++) { // 步骤2.1:提取类别置信度,找到最大置信度类别 float maxConfidence = 0f; int classId = -1; // 遍历所有类别,找到置信度最高的类别 for (int j = 4; j < dimensions; j++) { float confidence = output[0, j, i]; if (confidence > maxConfidence) { maxConfidence = confidence; classId = j - 4; // 减去4个坐标维度得到类别索引 } } // 步骤2.2:应用置信度阈值过滤 if (maxConfidence > confidenceThreshold && classId >= 0) { // 步骤2.3:解析边界框坐标 [center_x, center_y, width, height] float cx = output[0, 0, i]; // 边界框中心x坐标(归一化) float cy = output[0, 1, i]; // 边界框中心y坐标(归一化) float w = output[0, 2, i]; // 边界框宽度(归一化) float h = output[0, 3, i]; // 边界框高度(归一化) // 步骤2.4:将归一化坐标转换为原始图像像素坐标 // 从中心点格式转换为左上角坐标格式 float x1 = (cx - w / 2) * originalImage.Width / _modelSize.Width; float y1 = (cy - h / 2) * originalImage.Height / _modelSize.Height; float x2 = (cx + w / 2) * originalImage.Width / _modelSize.Width; float y2 = (cy + h / 2) * originalImage.Height / _modelSize.Height; // 步骤2.5:确保坐标在图像边界内(防止越界错误) x1 = Math.Max(0, Math.Min(x1, originalImage.Width)); y1 = Math.Max(0, Math.Min(y1, originalImage.Height)); x2 = Math.Max(0, Math.Min(x2, originalImage.Width)); y2 = Math.Max(0, Math.Min(y2, originalImage.Height)); // 步骤2.6:创建检测结果对象并添加到列表 predictions.Add(new Prediction { Box = new Rect((int)x1, (int)y1, (int)(x2 - x1), (int)(y2 - y1)), Confidence = maxConfidence, Label = _labels[classId] }); } } // 步骤3:应用非极大值抑制去除重叠检测框 return ApplyNMS(predictions); } /// <summary> /// 非极大值抑制函数 (NMS - Non-Maximum Suppression) /// 功能:消除重叠的检测框,保留每个物体最好的检测结果 /// 算法原理: /// 1. 按置信度降序排序所有检测框 /// 2. 选择置信度最高的框作为基准 /// 3. 计算其他框与基准框的IoU(交并比) /// 4. 移除IoU超过阈值的框(认为检测的是同一物体) /// 5. 重复2-4步骤直到处理完所有框 /// </summary> /// <param name="predictions">原始检测结果列表(可能包含重叠框)</param> /// <param name="iouThreshold">IoU阈值,默认0.5(超过此值认为重叠需要抑制)</param> /// <returns>过滤后的检测结果列表(无重叠框)</returns> private List<Prediction> ApplyNMS(List<Prediction> predictions, float iouThreshold = 0.5f) { // 步骤1:按置信度降序排序(置信度高的优先处理) var sorted = predictions.OrderByDescending(p => p.Confidence).ToList(); var selected = new List<Prediction>(); // 最终选择的检测框 // 步骤2:迭代处理,直到所有框都被检查 while (sorted.Count > 0) { // 取出当前置信度最高的框(总是列表第一个) var current = sorted[0]; selected.Add(current); // 添加到最终结果 sorted.RemoveAt(0); // 从待处理列表移除 // 步骤3:检查剩余框与当前框的重叠度 // 倒序遍历避免索引错位问题 for (int i = sorted.Count - 1; i >= 0; i--) { // 计算当前框与待检查框的IoU if (CalculateIoU(current.Box, sorted[i].Box) > iouThreshold) { // IoU超过阈值,认为检测的是同一物体,移除置信度较低的框 sorted.RemoveAt(i); } } } return selected; } /// <summary> /// 交并比计算函数 (IoU - Intersection over Union) /// 功能:计算两个矩形框的重叠程度,用于衡量检测框的相似性 /// 数学公式:IoU = 交集面积 / 并集面积 /// 取值范围:[0, 1],0表示无重叠,1表示完全重叠 /// </summary> /// <param name="a">第一个矩形框</param> /// <param name="b">第二个矩形框</param> /// <returns>IoU值,范围0-1,值越大表示重叠越多</returns> private float CalculateIoU(Rect a, Rect b) { // 步骤1:计算两个矩形的交集区域 var inter = a.Intersect(b); // 步骤2:检查是否有有效交集(宽度或高度为0表示无交集) if (inter.Width <= 0 || inter.Height <= 0) return 0; // 无重叠,IoU为0 // 步骤3:计算交集面积 float interArea = inter.Width * inter.Height; // 步骤4:计算并集面积 = 面积A + 面积B - 交集面积 float unionArea = a.Width * a.Height + b.Width * b.Height - interArea; // 步骤5:计算IoU比率 return interArea / unionArea; } /// <summary> /// 资源释放函数 - 实现IDisposable接口 /// 功能:正确释放ONNX Runtime占用的非托管资源 /// 重要性:防止内存泄漏,确保推理会话正确关闭 /// 使用模式:推荐使用using语句或确保在程序退出时调用 /// </summary> public void Dispose() { _session?.Dispose(); // 安全释放ONNX Runtime会话资源 } } /// <summary> /// 检测结果数据封装类 /// 功能:以结构化形式存储单个检测结果的所有信息 /// 设计目的:便于数据传递、序列化和可视化处理 /// </summary> public class Prediction { /// <summary> /// 检测框位置和尺寸 /// 使用OpenCvSharp的Rect结构,包含X,Y,Width,Height属性 /// 坐标单位为像素,相对于原始图像 /// </summary> public Rect Box { get; set; } /// <summary> /// 检测置信度 /// 取值范围:[0,1],表示模型对该检测结果的置信程度 /// 通常用于过滤低质量检测(如阈值0.5) /// </summary> public float Confidence { get; set; } /// <summary> /// 检测到的物体类别名称 /// 从标签文件加载,如"person", "car", "dog"等 /// 对应COCO数据集或其他自定义数据集的类别 /// </summary> public string Label { get; set; } } }
3. 模型调整适配
安装Netron:
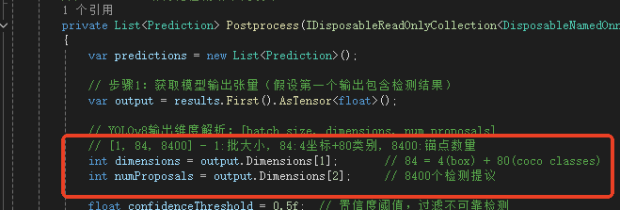
借助Netron查看模型,模型输出解析:YOLOv8不同任务(检测、分割、分类)和不同导出方式的模型输出格式可能有差异。请务必使用 Netron 等工具打开你的ONNX模型,核对输入和输出层的名称与维度,并据此调整代码中的Preprocess和Postprocess方法,下图标注为调整这两函数的重要参数。
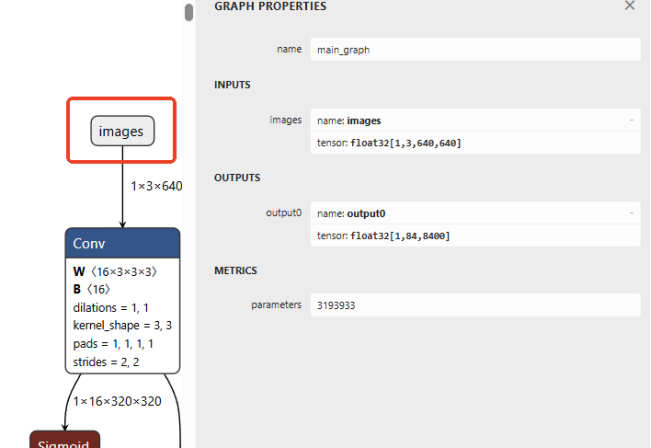
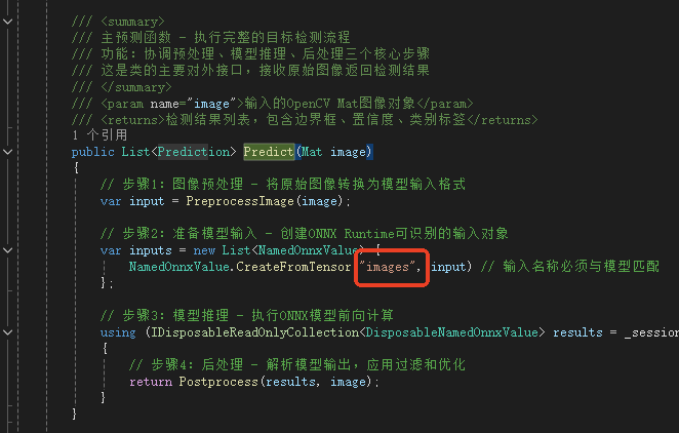
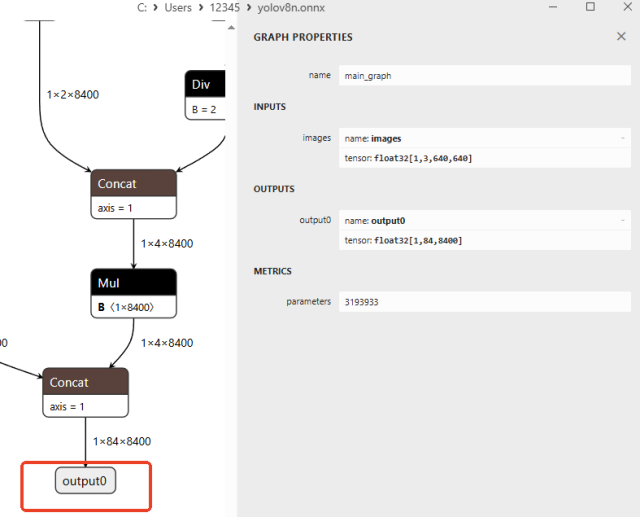
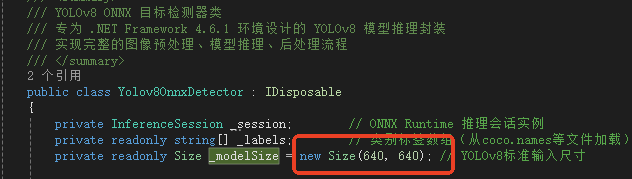
4. 训练你自己的YOLOv8模型
训练流程
flowchart TD
A[开始: 准备自定义数据集] --> B{数据准备工作}
B --> C[收集原始图像]
B --> D[使用LabelImg标注]
B --> E[组织标准目录结构]
E --> F[创建数据集配置文件]
F --> G[配置关键训练参数]
G --> H[执行训练命令]
H --> I[评估训练效果]
I --> J[导出ONNX模型]
J --> K[完成: 获得yolov8n.onnx]
第一步:准备数据集
这是最关键的一步,高质量的数据集是模型性能的保障。
收集与整理图片
收集包含你所需检测目标的图片,确保每类目标至少有500-1000张图片,覆盖不同的角度、光照和背景。
将图片按约定比例(如80%训练集,20%验证集)分别放入dataset/images/train和dataset/images/val文件夹。
标注图片
安装标注工具:推荐使用 LabelImg,可以通过pip安装:pip install labelImg==1.8.6。
标注数据:在命令行输入 labelImg 打开工具。
打开图片目录 (Open Dir):指向你的 images/train 或 images/val 文件夹。
设置保存目录 (Change Save Dir):指向对应的 labels/train 或 labels/val 文件夹。
关键:将标注格式设置为 YOLO(点击 Format 菜单选择)。
使用快捷键 W 划出目标边界框,并输入类别名称(如 cat, dog)。标注后,每个图片会生成一个同名的 .txt 文件。
在labelImg中预设多个可选标签需要创建并配置predefined_classes.txt文件。具体操作步骤如下:
首先找到labelImg的安装目录,如果使用Anaconda环境,路径通常为D:\anaconda\Lib\site-packages\labelImg,如果是其他虚拟环境则需要进入对应环境的site-packages目录。
在该目录下创建data文件夹,并将predefined_classes.txt文件放入其中。例如:
C:\Users\12345\.conda\envs\yolov8_onnx\Lib\site-packages\labelImg\data
将需要预设的标签逐行写入该文件,每个标签必须单独占据一行,不能放在同一行内
注意事项
- 若需支持 YOLO 格式标注,需确保标签文件夹中存在
classes.txt文件,且内容与predefined_classes.txt一致。 - 通过命令行启动时,可通过
--class_file参数指定自定义标签文件路径
组织数据集结构
确保你的数据集文件夹结构如下所示:
text
your_custom_dataset/
├── images/
│ ├── train/ # 存放训练集图片
│ └── val/ # 存放验证集图片
└── labels/
├── train/ # 存放训练集标注文件 (.txt)
└── val/ # 存放验证集标注文件 (.txt)
注意:图片文件(如 001.jpg)和其对应的标注文件(001.txt)必须同名。
第二步:创建数据集配置文件
你需要创建一个YAML文件(例如 my_data.yaml),来告诉YOLOv8你的数据集在哪里以及有哪些类别。
文件内容示例:
yaml
# 数据集根目录路径(根据你的实际情况修改)
path: /path/to/your_custom_dataset
# 训练集和验证集图片路径(相对于path的路径)
train: images/train
val: images/val
# 类别数量 (nc) 和 类别名称列表 (names)
nc: 2 # 例如,假设你有2个类别
names: ['cat', 'dog'] # 类别名称,顺序必须与标注文件中的类别ID保持一致[citation:10]
重要提示:names列表中的顺序至关重要。例如,你在LabelImg中将猫标注为"cat",那么这个列表里"cat"的索引(0)就必须对应标注文件.txt中的类别ID0。
第三步:训练模型
环境准备好之后,就可以开始训练了。
基本训练命令
打开终端或命令行,进入你的项目目录,运行以下命令开始训练:
bash
yolo detect train data=my_data.yaml model=yolov8n.pt epochs=50 imgsz=640 device=0
data: 指定你刚创建的数据集配置文件。
model: 指定预训练模型,从预训练模型开始训练效果更好。
epochs: 训练轮数,50是一个常见的起始值。
imgsz: 输入模型的图片尺寸。
device: 指定GPU进行训练,例如device=0。如果使用CPU,则设置为device=cpu。
| 参数 | 作用 | 推荐值 | 注意事项 |
|---|---|---|---|
| batch | 批次大小 | 4-64 | 越大训练越快,但需要更多显存 |
| workers | 数据加载线程数 | 2-8 | CPU核心数的一半 |
| device | 指定GPU | 0,1 或 cpu | 多GPU用逗号分隔:device=0,1 |
| 显存大小 | 推荐batch size (imgsz=640) | 推荐workers |
|---|---|---|
| 4GB | 4-8 | 2 |
| 6GB | 8-16 | 4 |
| 8GB | 16-24 | 6 |
| 11GB | 24-32 | 8 |
| 24GB+ | 32-64 | 8-16 |
yolo detect train data=tiger.yaml model=yolov8n.pt epochs=50 imgsz=640 batch=4 workers=1 device=0
训练过程监控
训练开始后,终端会显示损失曲线等指标。训练好的模型会默认保存在 runs/detect/train/ 目录下,其中 weights/best.pt 就是性能最好的模型权重。
第四步:导出ONNX模型
训练完成后,就可以将最佳的模型权重(best.pt)导出为ONNX格式了。
使用Python脚本导出
python
from ultralytics import YOLO
# 加载训练得到的最佳模型
model = YOLO('runs/detect/train/weights/best.pt')
# 导出模型为ONNX格式
model.export(format='onnx')
执行后,你会在 best.pt 相同的目录下找到导出的 .onnx 文件。
关键导出参数(可选)
imgsz: 指定导出模型的输入图像尺寸。
simplify: 默认为True,用于简化ONNX模型,通常建议开启。
dynamic: 如果希望模型支持动态输入尺寸(例如用于不同分辨率的图片),可以设置此参数。
补充说明:
从预训练模型开始:使用 yolov8n.pt 等预训练权重进行迁移学习,可以显著提高训练速度和模型精度。
合理设置训练轮数:初始训练时, epochs 设置为50-100轮观察效果,避免过拟合或欠拟合。
注意硬件资源:根据你的GPU显存调整 batch-size,如果显存较小,可以设置较小的值(如4, 8)。
GPU 训练模型配置,部分GPU训练时任务管理器看到GPU使用率非常低,怀疑配置错误!不要慌,切换任务管理器细节到Cuda使用率会发现Cuda和显存使用率都非常高。
# 对于NVIDIA GPU nvidia-smi # 或者在Python中检查 import torch print(f"可用GPU数量: {torch.cuda.device_count()}") print(f"当前GPU: {torch.cuda.get_device_name(0)}") print(f"GPU显存: {torch.cuda.get_device_properties(0).total_memory / 1024**3:.1f} GB")
python -c "import torch; print(f'CUDA可用: {torch.cuda.is_available()}, GPU: {torch.cuda.get_device_name(0) if torch.cuda.is_available() else None}')"
# 使用正确的CUDA 12.1版本(兼容您的12.6) conda install pytorch torchvision torchaudio pytorch-cuda=12.1 -c pytorch -c nvidia
# 卸载当前的CPU版本 pip uninstall torch torchvision torchaudio -y # 安装支持CUDA 12.1的版本 pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121
>python -c "import torch; print(f'CUDA可用: {torch.cuda.is_available()}')" OMP: Error #15: Initializing libiomp5md.dll, but found libiomp5md.dll already initialized. OMP: Hint This means that multiple copies of the OpenMP runtime have been linked into the program. That is dangerous, since it can degrade performance or cause incorrect results. The best thing to do is to ensure that only a single OpenMP runtime is linked into the process, e.g. by avoiding static linking of the OpenMP runtime in any library. As an unsafe, unsupported, undocumented workaround you can set the environment variable KMP_DUPLICATE_LIB_OK=TRUE to allow the program to continue to execute, but that may cause crashes or silently produce incorrect results. For more information, please see http://www.intel.com/software/products/support/.
这是一个常见的OpenMP库冲突警告,不影响CUDA功能!
# 设置环境变量忽略这个警告 set KMP_DUPLICATE_LIB_OK=TRUE # 然后验证CUDA python -c "import torch; print(f'CUDA可用: {torch.cuda.is_available()}')"
import os os.environ['KMP_DUPLICATE_LIB_OK'] = 'True' import torch print(f'CUDA可用: {torch.cuda.is_available()}')

 浙公网安备 33010602011771号
浙公网安备 33010602011771号