
Elasticsearch-入门
1. 分词算法概述
词是表达语义的最小单位. 分词对搜索引擎的帮助很大, 可以帮助搜索引擎程序自动识别语句的含义, 从而使搜索结果的匹配程度达到最高, 因此分词的质量也就直接影响了搜索结果的精确度. 分词在文档索引的建立过程和用户提交检索过程中都存在.
2. 英文分词的原理
输入文本 -> 词汇分隔 -> 词汇过滤(过滤停留词) -> 词干提取(形态还原) -> 大写转为小写 输出结果
3. 中文分词原理
基于词典匹配的分词法
基于语义理解的分词
基于词频统计的分词
4. 词典匹配分词法
doc1 : 中国, 美国, 韩国
doc2 : 英国, 中国, 美国, 德国

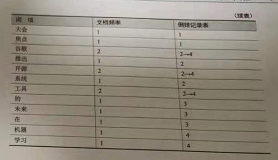
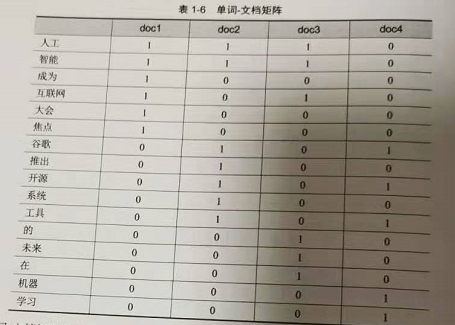
5. 对一组文档进行倒排索引
doc1 : 人工智能成为互联网大会焦点
doc2 : 谷歌推出开源人工智能系统
doc3 : 互联网的未来在人工智能
doc4 : 谷歌开源机器学习工具
对于文档内容, 先要进过词条化处理. 和英文不同, 英文是通过空格分隔单词, 中文的词语词之间没有明确的分隔符号, 经过分词系统进行中文分词以后会把矩阵分成一个一个词条, doc4 会被分成 : 谷歌, 开源, 机器, 学习, 工具 5个词项. 这个词在 doc2 和 doc4 中各出现一次, 文档评率为 2 , 倒排记录表记做 2 ->4. 文档评率也是倒排记录表的长度. 依次统计各词的文档评率和倒排记录表
倒排记录表和倒排索引是两个东西

6. 复合查询最常见的的bool检索模型
即 AND, OR, NOT 三种逻辑运算, 优先级顺序为 NOT > AND > OR
例如查询包含 谷歌, 开源 但不包含 大会的文档, 构造bool查询:
谷歌 AND 开源 NOT 大会
谷歌 : 0 1 0 1
开源 : 0 1 0 1
大会 : 1 0 0 0 ( 取反 : 0 1 1 1)
0 1 0 1 AND 0 1 0 1 AND 0 1 1 1 = 0 1 0 1;
权重 : BMF5 算法
7. Lucene
Lucene 层面主要有两大任务: 索引文档和搜索文档, 索引文档的过程完成由原始文档到倒排索引的构建过程, 搜索文档用以处理用户查询. 对于用于输入的内容进行分词 包含 或匹配 最后根据 分词, 匹配, 评分, 排序 返回给用户想要的文档.
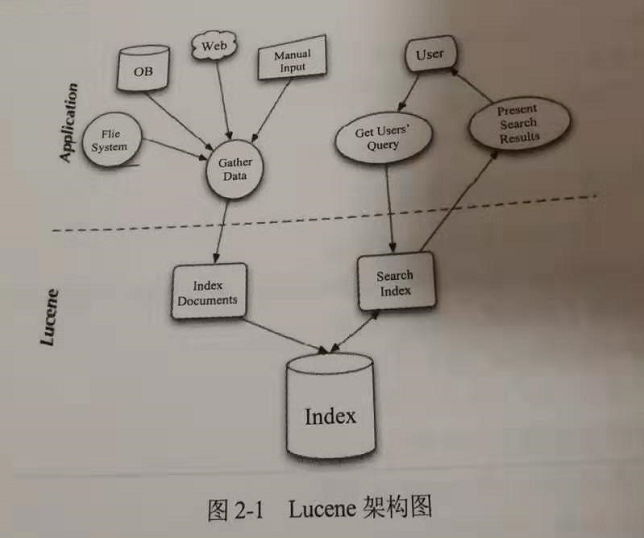
8. 一次查询的过程可以拆解为
对用户的输入进行分词
关键词检索
搜索排序
9. Elasticsearch 基于 Lucene
Lucene 对于 Elasticsearch 堪比发动机之于汽车, Elasticsearch 的底层使用的仍然是 Lucene 的 API, Lucene 专注于底层搜索的建设, Elasticsearch 专注于企业应用.
10. Es 版本 5.0 开始, 组件版本统一, 强一致.
11. Elasticsearch 架构
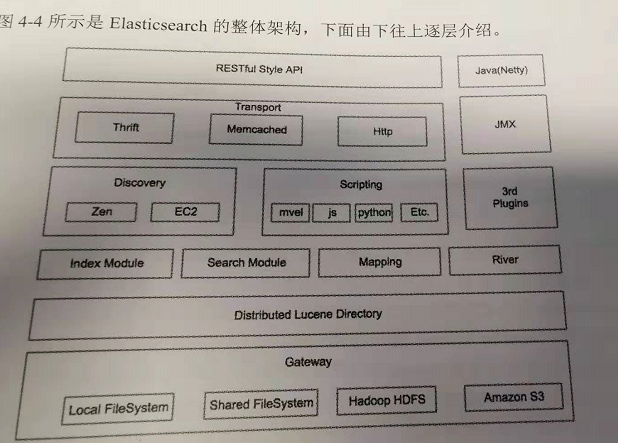
GateWay 是 Elasticsearch用来存储索引的文件系统, 支持多种文件类型,
Local FIleSystem : 本地存储
Shard FileSystem : 共享存储
Hadoop HDFS: 分布式存储
Amazon S3 : 云服务器
GetWay 的上层是一个分布式的 Lucene 框架, Elasticsearch 的底层 API 是由 Lucene 提供的, 每一个 Elasticsearch 节点上都有一个 Lucene 引擎的支持.
Lucene 之上是一 Elasticsearch 模块, 包括索引模块, 搜索模块, 映射解析模块等.
Elasticsearch 模块之上是 Discovery, Scripting 和第三方插件. Discovery 是 Elasticsearch 的节点发现模块, 不同机器上的 Elasticsearch 节点要组成集群需要进行信息通信, 集群内部需要选举 master节点, 这些工作都是由 Discovery 模块完成的. Scripting 用来支持 JavaScript, Python 等多种脚本, 可以在查询语句中嵌入, 但是会使 Script 语句性能稍低. 也支持第三方插件, 例如 SQL
再上层是 Transport 代表 Elasticsearch 内部节点, 代表跟集群的客户端交互. 包括 Thrift, Memcached, Http 等协议
JMX 监控
3dr Plugins
RESTful Style API, 通过 RESTful 方式来实现 API编程.
12. Elasticsearch 优点 / 特点
分布式: Elasticsearch 横向扩展非常灵活, 当数据规模比较小的时候可以使用小规模的集群. 随着数据的增长, 需要更大的容量和更高的性能, 此时只需要增加更多的节点, Elasticsearch 的自动发现机制会识别新增的节点并重新平衡分类数据.
全文检索: Apache Lucene 是一个用 Java 编写的高性能的功能齐全的信息检索库, Elasticsearch 在后台使用 Lucene 来提供最强大的全文检索, 提供任何开源产品的能力.自带多种语言支持, 强大的查询语言, 地理位置支持, 上下文感知的建议, 自动完成和搜索片段.
近实时搜索和分析 : 数据从进入 Elasticsearch, 可达到近实时搜索. 除了搜索, Elasticsearch 也可以进行聚合分析操作.
高可用 : 高可用主要体现在容错机制上, Elasticsearch 集群会自动发现新的或失败的节点, 从组和重新平衡数据, 确保数据是安全的和可访问的.
模式自由 : Elasticsearch 的动态 Mapping 机制可以自动检测数据系统的结构和类型, 创建索引, 并使数据可搜索.
RESTful API : Elasticsearch 是 API 驱动, 几乎任何操作都可以用一个简单的 RESTful API 使用 JSON 基于 HTTP 请求来实现, 客户端也可以使用多种编程语言.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号