Go语言基础 -- 派生/复杂数据类型(指针和map)
1. 指针(pointer)
1. 基本介绍
Go语言中的函数传参都是值拷贝,当我们想要修改某个变量的时候,我们可以创建一个指向该变量地址的指针变量。传递数据使用指针,而无须拷贝数据。类型指针不能进行偏移和运算。Go语言中的指针操作非常简单,只需要记住两个符号:&(取地址)和*(根据地址取值)。
2. 取指针(内存地址)
- 基本数据类型,变量存的是值,也叫值类型
- 获取变量的地址,用
&
package main
import "fmt"
func main() {
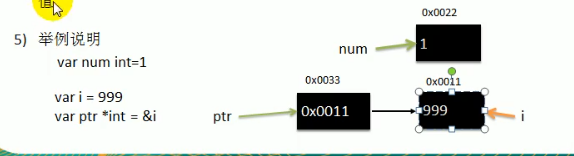
var i int = 100
fmt.Println("i的指针(内存地址)为", &i)
j := 3
var ptr *int = &j
fmt.Println("j的指针(内存地址)为: ", ptr)
}
// 打印结果:
i的指针(内存地址)为: 0xc00000a0a8
j的指针(内存地址)为: 0xc00000a0d0
上面代码的内存图
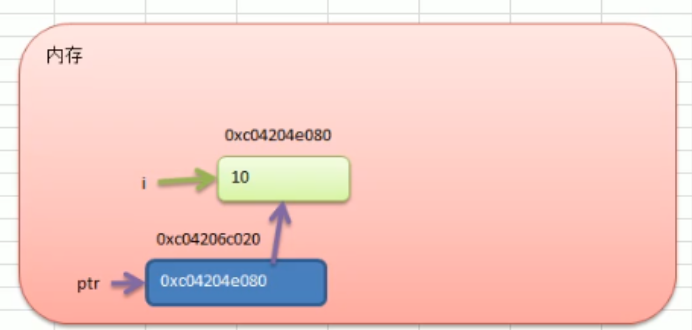
指针变量
// 指针类型,变量存的是一个地址,这个地址指向的空间存的才是值,比如var ptr *int=&num
package main
import "fmt"
func main() {
var i int = 100
fmt.Printf("i的内存地址为%v\n",&i)
// xx是一个指针变量,类型是*int,并且指向i的内存地址,内存地址指向的才是值
var xx *int = &i
// 指针变量也是有自己的内存地址的
fmt.Printf("xx指向的内存地址为%v\n",xx,)
fmt.Printf("xx指针变量的内存地址为",&xx)
}
3. 指针取值
package main
import "fmt"
func main() {
a := 10
b := &a // 取变量a的地址,将指针保存到b中
fmt.Printf("b的内存地址为 %v\n", b)
fmt.Printf("b的类型为: %T\n", b)
c := *b // *b 指针取值
fmt.Printf("c的类型为: %T\n", c)
fmt.Printf("c的值为: %v\n", c)
}
// 打印结果:
b的内存地址为 0xc00000a0a8
b的数据类型为: *int
c的数据类型为: int
c的值为: 10
图解:
4. 变量,指针,取值,取地址之间的关系
变量、指针地址、指针变量、取地址、取值的相互关系和特性如下:
- 对变量进行取地址(&)操作,可以获得这个变量的指针变量。
- 指针变量的值是指针地址。
- 对指针变量进行取值(*)操作,可以获得指针变量指向的原变量的值。
5. 指针传值
func modify1(x int) {
x = 100
}
func modify2(x *int) {
*x = 100
}
func main() {
a := 10
modify1(a)
fmt.Println(a) // 10
modify2(&a)
fmt.Println(a) // 100
}
6. 注意事项
- 值类型,都有对应的指针类型,形式为
*数据类型,比如int的对应的指针就是*int,float32对应的指针类型就是*float32,依次类推 - 值类型包括:基本数据类型
int系列,float系列,bool,string,数组和结构体(struct)
7. 空指针
当一个指针被定义后没有分配到任何变量时,它的值为 nil
1. 空指针的判断
package main
import "fmt"
func main() {
var a *string
if a != nil {
fmt.Println("不是空指针")
} else {
fmt.Println("空指针")
}
}
// 运行结果
空指针
8. new
new是一个内置的函数,它的函数签名如下:
func new(Type) *Type
其中,
1.Type表示类型,new函数只接受一个参数,这个参数是一个类型
2.*Type表示类型指针,new函数返回一个指向该类型内存地址的指针。
new函数不太常用,使用new函数得到的是一个类型的指针,并且该指针对应的值为该类型的零值。举个例子:
func main() {
a := new(int)
b := new(bool)
fmt.Printf("%T\n", a) // *int
fmt.Printf("%T\n", b) // *bool
fmt.Println(*a) // 0
fmt.Println(*b) // false
}
本节开始的示例代码中var a *int只是声明了一个指针变量a但是没有初始化,指针作为引用类型需要初始化后才会拥有内存空间,才可以给它赋值。应该按照如下方式使用内置的new函数对a进行初始化之后就可以正常对其赋值了:
func main() {
var a *int
a = new(int)
*a = 10
fmt.Println(*a)
}
9. make
make也是用于内存分配的,区别于new,它只用于slice、map以及chan的内存创建,而且它返回的类型就是这三个类型本身,而不是他们的指针类型,因为这三种类型就是引用类型,所以就没有必要返回他们的指针了。make函数的函数签名如下:
func make(t Type, size ...IntegerType) Type
make函数是无可替代的,我们在使用slice、map以及channel的时候,都需要使用make进行初始化,然后才可以对它们进行操作。这个我们在上一章中都有说明,关于channel我们会在后续的章节详细说明。
本节开始的示例中var b map[string]int只是声明变量b是一个map类型的变量,需要像下面的示例代码一样使用make函数进行初始化操作之后,才能对其进行键值对赋值:
func main() {
var b map[string]int
b = make(map[string]int, 10)
b["测试"] = 100
fmt.Println(b)
}
10. new与make的区别
1.二者都是用来做内存分配的。
2.make只用于slice、map以及channel的初始化,返回的还是这三个引用类型本身;
3.而new用于类型的内存分配,并且内存对应的值为类型零值,返回的是指向类型的指针。
2. Map
map是一种无序的基于key-value的数据结构,Go语言中的map是引用类型,必须初始化才能使用
1. 初始化
map[KeyType]ValueType
// 参数说明
KeyType:表示键的类型。
ValueType:表示键对应的值的类型。
**map类型的变量默认初始值为nil,需要使用make()函数来分配内存
//其中cap表示map的容量,该参数虽然不是必须的,但是我们应该在初始化map的时候就为其指定一个合适的容量。
make(map[KeyType]ValueType, [cap])
错误一:未初始化
Go 语言中 map 和 slice 不同,map 对象必须在使用之前初始化。
如果不初始化就直接赋值的话,就会出现 panic 异常,比如下面的代码:
var m map[int]int
m[1]=1
执行后会报错:
$ go run map.go
panic: assignment to entry in nil map
goroutine 1 [running]:
main.main()
/Users/kun/Desktop/课件/bingfa-demo/map.go:6 +0x27
exit status 2
非常好玩的是,不能赋值,但是却可以取值:
var m map[int]int
fmt.Println(m[1])
执行的结果是:
$ go run map.go
造成这个好玩的现象是因为:
从一个 nil 的 map 对象中获取值,并不会 panic,而是会得到一个零值。
所以切记 在使用 map 这个数据类型时,一定一定要初始化,目前还没有工具可以检查是否初始化了,所以我们只能疯狂的记住它!
2. 基本使用
1. 基本使用
package main
import "fmt"
func main() {
d := make(map[string]int, 10)
d["小明"] = 18
d["小白"] = 20
fmt.Println(d)
}
// 运行结果,map是无序的
map[小明:18 小白:20]
2. map也支持在声明的时候填充元素,会自动分配内存并赋值
package main
import "fmt"
func main() {
userInfo := map[string]string{
"username": "user1",
"password": "123456",
"password2": "123456",
}
fmt.Println(userInfo)
for k, v := range userInfo {
fmt.Println(k, v)
}
}
// 运行结果,map是无序的
map[password:123456 password2:123456 username:user1]
username user1
password 123456
password2 123456
3. 切片中元素为map类型
package main
import "fmt"
func main() {
var mapSlice = make([]map[string]string, 3)
fmt.Println(mapSlice)
// 对切片中的map元素进行初始化
mapSlice[0] = make(map[string]string, 10)
mapSlice[0]["name"] = "王五"
mapSlice[0]["password"] = "123456"
mapSlice[0]["address"] = "红旗大街"
fmt.Println(mapSlice)
}
// 打印结果:
[map[] map[] map[]]
[map[address:红旗大街 name:王五 password:123456] map[] map[]]
4. map中的value为切片
func main() {
var sliceMap = make(map[string][]string, 3)
fmt.Println(sliceMap)
fmt.Println("after init")
key := "中国"
value, ok := sliceMap[key]
if !ok {
value = make([]string, 0, 2)
}
value = append(value, "北京", "上海")
sliceMap[key] = value
fmt.Println(sliceMap)
}
3. 判断键是否存在
Go语言中有个判断map中键是否存在的特殊写法,格式如下:
value, ok := map[key]
例如:
package main
import "fmt"
func main() {
var map1 = map[string]int{
"小明":20,
"小红":18,
}
// 1. map中有 小明 这个键
value,ok := map1["小明"]
fmt.Println(value,ok)
// 2. map中没有 小白 这个键,没有键时value为对应 value 的类型结构的空值, 这里为0, ok为fasle
value,ok = map1["小白"]
fmt.Println(value,ok)
}
// 打印结果: 没有键时value为为对应 value 的类型结构的空值, 这里为0, ok为fasle
20 true
0 false
4. 遍历
1. 无序遍历
由于map是无序的,所以每次遍历打印出来的值的顺序不一样
package main
import "fmt"
func main() {
var map1 = map[string]int{
"小明":20,
"小红":18,
"小绿":24,
"小黄":26,
}
for k,v := range map1{
fmt.Println(k,v)
}
}
// 打印结果:
小绿 24
小黄 26
小明 20
小红 18
注意: 遍历map时的元素顺序与添加键值对的顺序无关。
2. 只遍历key
package main
import "fmt"
func main() {
var map1 = map[string]int{
"小明":20,
"小红":18,
"小绿":24,
"小黄":26,
}
for k:= range map1{
fmt.Println(k)
}
}
// 打印结果:
小明
小红
小绿
小黄
3. 指定顺序遍历
package main
import (
"fmt"
"math/rand"
"sort"
"time"
)
func test1() {
// 初始化随机种子
rand.Seed(time.Now().UnixNano())
var scoreMap = make(map[string]int, 200)
// 添加100条随机数据到Map中
for i := 0; i < 100; i++ {
key := fmt.Sprintf("stu_%02d", i)
value := rand.Intn(100)
scoreMap[key] = value
}
// 将Map的所有key 存到Slice中
var keysSlice = make([]string, 0, 200)
for s := range scoreMap {
keysSlice = append(keysSlice, s)
}
// 对字符串切片升序排序
sort.Strings(keysSlice)
for _, v := range keysSlice {
fmt.Println(v, scoreMap[v])
}
}
func main() {
test1()
}
5. delete()
使用 delete()内建函数从map中删除一组键值对
delete(map,key)
// 参数说明
map:表示要删除键值对的map
key:表示要删除的键值对的键
例如:
func main(){
scoreMap := make(map[string]int)
scoreMap["张三"] = 90
scoreMap["小明"] = 100
scoreMap["王五"] = 60
delete(scoreMap, "小明")//将小明:100从map中删除
for k,v := range scoreMap{
fmt.Println(k, v)
}
}
6. map并发下的问题处理
1. 问题模拟
这是一个非常让人头大的问题,经常会出现本地调试OK,上线一出现并发就 panic,先来看一段代码:
var m = make(map[int]string,10) // 初始化一个map
go func() {
for {
m[1] = "hello" //设置key
}
}()
go func() {
for {
_ = m[2] //访问这个map
}
}()
select {}
解释下:
我初始化了一个定长 map 类型,然后我起了两个协程,一个去赋值,一个去取值。
看似没什么问题,但是你执行下,就会发现,他崩溃了!
$ go run map.go
fatal error: concurrent map read and map write
goroutine 18 [running]:
runtime.throw({0x10648e9, 0x0})
/usr/local/go/src/runtime/panic.go:1198 +0x71 fp=0xc00002af90 sp=0xc00002af60 pc=0x102b9d1
runtime.mapaccess1_fast64(0x0, 0x0, 0x2)
/usr/local/go/src/runtime/map_fast64.go:21 +0x172 fp=0xc00002afb0 sp=0xc00002af90 pc=0x100d672
main.main.func2()
/Users/kun/Desktop/课件/bingfa-demo/map.go:14 +0x2e fp=0xc00002afe0 sp=0xc00002afb0 pc=0x10556ce
runtime.goexit()
/usr/local/go/src/runtime/asm_amd64.s:1581 +0x1 fp=0xc00002afe8 sp=0xc00002afe0 pc=0x1052921
created by main.main
/Users/kun/Desktop/课件/bingfa-demo/map.go:12 +0x97
goroutine 1 [select (no cases)]:
main.main()
/Users/kun/Desktop/课件/bingfa-demo/map.go:17 +0x9c
goroutine 17 [runnable]:
main.main.func1()
/Users/kun/Desktop/课件/bingfa-demo/map.go:8 +0x35
created by main.main
/Users/kun/Desktop/课件/bingfa-demo/map.go:6 +0x65
exit status 2
因为 Go 内建的 map 对象并不是线程安全的,在并发读写时他会进行检查,就会出现错误!
但是庆幸的是,这个报错相对来说还是比较好定位的,通过错误提示基本都能快速找到报错点!
2. 解决方案
1. 加读写锁
为了解决并发情况下 map 的操作,我们必须得自己去实现一个线程安全的结构体!
// RWMap 一个读写锁保护的线程安全的map
type RWMap struct {
sync.RWMutex // 读写锁保护下面的map字段
m map[int]int
}
// NewRWMap 新建一个RWMap
func NewRWMap(n int) *RWMap {
return &RWMap{
m: make(map[int]int, n),
}
}
// Get 获取值
func (m *RWMap) Get(k int) (int, bool) {
m.RLock()
defer m.RUnlock()
v, existed := m.m[k] // 在锁的保护下从map中读取
return v, existed
}
// Set 写值
func (m *RWMap) Set(k int, v int) {
m.Lock() // 锁保护
defer m.Unlock()
m.m[k] = v
}
// Delete 删除值
func (m *RWMap) Delete(k int) { //删除一个键
m.Lock() // 锁保护
defer m.Unlock()
delete(m.m, k)
}
// Len 获取长度
func (m *RWMap) Len() int { // map的长度
m.RLock() // 锁保护
defer m.RUnlock()
return len(m.m)
}
// Each 循环遍历
func (m *RWMap) Each(f func(k, v int) bool) { // 遍历map
m.RLock() //遍历期间一直持有读锁
defer m.RUnlock()
for k, v := range m.m {
if !f(k, v) {
return
}
}
}
因为 Go 目前为止并不支持泛型,所以我们并不能实现一个通用的加锁 map。
当然我们也可以通过 interface{} 来模拟泛型,但是成本太高,性能也会大打折扣。
我们一般在开发中,对 map 对象的操作无非就是 增删改查和遍历等几种操作。
我们在并发时,只需要对他进行加读写锁,就能防止 map 并发读写报的问题!
2. 内置的 sync.map (协程安全 map)
package main
import (
"fmt"
"sync"
)
func main() {
// 1. 创建协程安全的 map
var m sync.Map
var wg sync.WaitGroup
wg.Add(2)
// 2. 协程1: 并发写
go func() {
for true {
m.Store(0, "小明")
}
wg.Done()
}()
// 2. 协程2: 并发读
go func() {
for true {
a, _ := m.Load(0)
fmt.Println(a)
}
wg.Done()
}()
wg.Wait()
fmt.Println("结束")
}
3. 总结
虽然读写锁可以提供一个线程安全的 map,但是在大量并发情况下,锁的竞争会非常激烈,于是也就有了 锁是性能下降的万恶之源 的说法。
于是我们在并发编程中的原则就是:尽量少的使用锁,如果要用,尽量做到减少锁的粒度和锁的持有时间。
基于这个思路,线程安全的 map 方案: 加读写锁、分片加锁、sync.Map方案等
7. Map 使用流程
直接用代码描述,直观,简单,易理解
// map初始化并赋值
var mapInit = map[string]string {"xiaoli":"湖南", "xiaoliu":"天津"}
// 声明一个map类型变量,
// map的key的类型是string,value的类型是string
var mapTemp map[string]string
// 使用make函数初始化这个变量,并指定大小(也可以不指定)
mapTemp = make(map[string]string,10)
// 存储key ,value
mapTemp["xiaoming"] = "北京"
mapTemp["xiaowang"]= "河北"
// 根据key获取value,
// 如果key存在,则ok是true,否则是flase
// v1用来接收key对应的value,当ok是false时,v1是nil
v1,ok := mapTemp["xiaoming"]
fmt.Println(ok,v1)
// 当key=xiaowang存在时打印value
if v2,ok := mapTemp["xiaowang"]; ok{
fmt.Println(v2)
}
// 遍历map,打印key和value
for k,v := range mapTemp{
fmt.Println(k,v)
}
// 删除map中的key
delete(mapTemp,"xiaoming")
// 获取map的大小
l := len(mapTemp)
fmt.Println(l)
看了上面的map创建,初始化,增删改查等操作,我们发现go的api其实挺简单易学的
8. 底层原理
1. 什么是Map
key,value存储
最通俗的话说Map是一种通过key来获取value的一个数据结构,其底层存储方式为数组,在存储时key不能重复,当key重复时,value进行覆盖,我们通过key进行hash运算(可以简单理解为把key转化为一个整形数字)然后对数组的长度取余,得到key存储在数组的哪个下标位置,最后将key和value组装为一个结构体,放入数组下标处,看下图:
length = len(array) = 4
hashkey1 = hash(xiaoming) = 4
index1 = hashkey1% length= 0
hashkey2 = hash(xiaoli) = 6
index2 = hashkey2% length= 2
2. hash冲突
如上图所示,数组一个下标处只能存储一个元素,也就是说一个数组下标只能存储一对key,value, hashkey(xiaoming)=4占用了下标0的位置,假设我们遇到另一个key,hashkey(xiaowang)也是4,这就是hash冲突(不同的key经过hash之后得到的值一样),那么key=xiaowang的怎么存储? hash冲突的常见解决方法
开放定址法:也就是说当我们存储一个key,value时,发现hashkey(key)的下标已经被别key占用,那我们在这个数组中空间中重新找一个没被占用的存储这个冲突的key,那么没被占用的有很多,找哪个好呢?常见的有线性探测法,线性补偿探测法,随机探测法,这里我们主要说一下线性探测法
线性探测,字面意思就是按照顺序来,从冲突的下标处开始往后探测,到达数组末尾时,从数组开始处探测,直到找到一个空位置存储这个key,当数组都找不到的情况下回扩容(事实上当数组容量快满的时候就会扩容了);查找某一个key的时候,找到key对应的下标,比较key是否相等,如果相等直接取出来,否则按照顺寻探测直到碰到一个空位置,说明key不存在。如下图:首先存储key=xiaoming在下标0处,当存储key=xiaowang时,hash冲突了,按照线性探测,存储在下标1处,(红色的线是冲突或者下标已经被占用了) 再者key=xiaozhao存储在下标4处,当存储key=xiaoliu是,hash冲突了,按照线性探测,从头开始,存储在下标2处 (黄色的是冲突或者下标已经被占用了)
拉链法:何为拉链,简单理解为链表,当key的hash冲突时,我们在冲突位置的元素上形成一个链表,通过指针互连接,当查找时,发现key冲突,顺着链表一直往下找,直到链表的尾节点,找不到则返回空,如下图:
开放定址(线性探测)和拉链的优缺点
由上面可以看出拉链法比线性探测处理简单
线性探测查找是会被拉链法会更消耗时间
线性探测会更加容易导致扩容,而拉链不会
拉链存储了指针,所以空间上会比线性探测占用多一点
拉链是动态申请存储空间的,所以更适合链长不确定的
3. 底层原理
知其然,更得知其所以然,会使用map了,多问问为什么,go底层map到底怎么存储呢?接下来我们一探究竟。map的源码位于 src/runtime/map.go中 笔者go的版本是1.12在go中,map同样也是数组存储的的,每个数组下标处存储的是一个bucket,这个bucket的类型见下面代码,每个bucket中可以存储8个kv键值对,当每个bucket存储的kv对到达8个之后,会通过overflow指针指向一个新的bucket,从而形成一个链表,看bmap的结构,我想大家应该很纳闷,没看见kv的结构和overflow指针啊,事实上,这两个结构体并没有显示定义,是通过指针运算进行访问的。
//bucket结构体定义 b就是bucket
type bmap{
// tophash generally contains the top byte of the hash value
// for each key in this bucket. If tophash[0] < minTopHash,
// tophash[0] is a bucket evacuation state instead.
//翻译:top hash通常包含该bucket中每个键的hash值的高八位。
// 如果tophash[0]小于mintophash,则tophash[0]为桶疏散状态 //bucketCnt 的初始值是8
tophash [bucketCnt]uint8
// Followed by bucketCnt keys and then bucketCnt values.
// NOTE: packing all the keys together and then all the values together makes the // code a bit more complicated than alternating key/value/key/value/... but it allows // us to eliminate padding which would be needed for, e.g., map[int64]int8.// Followed by an overflow pointer. //翻译:接下来是bucketcnt键,然后是bucketcnt值。
注意:将所有键打包在一起,然后将所有值打包在一起, 使得代码比交替键/值/键/值/更复杂。但它允许//我们消除可能需要的填充, 例如map[int64]int8./后面跟一个溢出指针}
看上面代码以及注释,我们能得到bucket中存储的kv是这样的,tophash用来快速查找key值是否在该bucket中,而不同每次都通过真值进行比较;还有kv的存放,为什么不是k1v1,k2v2..... 而是k1k2...v1v2...,我们看上面的注释说的 map[int64]int8,key是int64(8个字节),value是int8(一个字节),kv的长度不同,如果按照kv格式存放,则考虑内存对齐v也会占用int64,而按照后者存储时,8个v刚好占用一个int64,从这个就可以看出go的map设计之巧妙。
最后我们分析一下go的整体内存结构,阅读一下map存储的源码,如下图所示,当往map中存储一个kv对时,通过k获取hash值,hash值的低八位和bucket数组长度取余,定位到在数组中的那个下标,hash值的高八位存储在bucket中的tophash中,用来快速判断key是否存在,key和value的具体值则通过指针运算存储,当一个bucket满时,通过overfolw指针链接到下一个bucket。
go的map存储源码如下,省略了一些无关紧要的代码
func mapassign(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {
//获取hash算法
alg := t.key.alg
//计算hash值
hash := alg.hash(key, uintptr(h.hash0))
//如果bucket数组一开始为空,则初始化
if h.buckets == nil {
h.buckets = newobject(t.bucket) // newarray(t.bucket, 1)
}
again:
// 定位存储在哪一个bucket中
bucket := hash & bucketMask(h.B)
//得到bucket的结构体
b := (*bmap)(unsafe.Pointer(uintptr(h.buckets) +bucket*uintptr(t.bucketsize)))
//获取高八位hash值
top := tophash(hash)
var inserti *uint8
var insertk unsafe.Pointer
var val unsafe.Pointer
bucketloop:
//死循环
for {
//循环bucket中的tophash数组
for i := uintptr(0); i < bucketCnt; i++ {
//如果hash不相等
if b.tophash[i] != top {
//判断是否为空,为空则插入
if isEmpty(b.tophash[i]) && inserti == nil {
inserti = &b.tophash[i]
insertk = add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
val = add( unsafe.Pointer(b),
dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.valuesize) )
}
//插入成功,终止最外层循环
if b.tophash[i] == emptyRest {
break bucketloop
}
continue
}
//到这里说明高八位hash一样,获取已存在的key
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
if t.indirectkey() {
k = *((*unsafe.Pointer)(k))
}
//判断两个key是否相等,不相等就循环下一个
if !alg.equal(key, k) {
continue
}
// 如果相等则更新
if t.needkeyupdate() {
typedmemmove(t.key, k, key)
}
//获取已存在的value
val = add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.valuesize))
goto done
}
//如果上一个bucket没能插入,则通过overflow获取链表上的下一个bucket
ovf := b.overflow(t)
if ovf == nil {
break
}
b = ovf
}
if inserti == nil {
// all current buckets are full, allocate a new one.
newb := h.newoverflow(t, b)
inserti = &newb.tophash[0]
insertk = add(unsafe.Pointer(newb), dataOffset)
val = add(insertk, bucketCnt*uintptr(t.keysize))
}
// store new key/value at insert position
if t.indirectkey() {
kmem := newobject(t.key)
*(*unsafe.Pointer)(insertk) = kmem
insertk = kmem
}
if t.indirectvalue() {
vmem := newobject(t.elem)
*(*unsafe.Pointer)(val) = vmem
}
typedmemmove(t.key, insertk, key)
//将高八位hash值存储
*inserti = top
h.count++
return val
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号