一丶对之前的知识点进行补充
1.str中的join方法.把列表转换成字符串
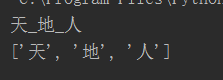
# 将列表转换成字符串,每个元素之间用_拼接
s = "_".join(["天","地","人"])
print(s)
ss = "天_地_人"
s = ss.split("_")
print(s)
2.列表和字典在循环的时候不能直接删除
需要把删除的内容记录在新列表中
然后循环新列表,删除字典或列表
lst = ["a","b","c"]
n = []
for a in lst:
n.append(a)
for b in n:
lst.remove(b)
print(lst)
lst = ["张国荣", '张铁林', '张国立', "张曼玉", "汪峰"]
# 删掉姓张的
# 记录姓张的.
zhangs = []
for el in lst:
if el.startswith("张"):
zhangs.append(el)
for el in zhangs:
lst.remove(el)
print(lst)
print(zhangs)
3.fromkeys()
1.返回新字典..对原字典没有影响
2.后面的value.是多个key共享一个value
dic = {"apple":"苹果","banana":"香蕉"}
##返回新字典,跟原来的没有关系
ret = dic.fromkeys("orange","橘子") #直接用字典去访问fromkeys不会对字典产生影响
print(ret)
ret = dic.fromkeys("ab",["哈哈","呵呵","吼吼"]) #fromkeys直接使用类名进行访问
print(ret)

二丶set集合
特点: 无序,不重复,元素必须可哈希(不可变)
作用: 去重复
本身是可变的数据类型,有增删改查操作.
增:
s = {"剑圣","剑豪","剑魔"}
s.add("剑姬")
print(s) #{'剑姬', '剑魔', '剑豪', '剑圣'}
s.add("剑圣")
print(s) #重复的添加不进去的 {'剑姬', '剑魔', '剑豪', '剑圣'}
s.update("天道酬勤") #迭代添加
print(s) #{'天', '剑豪', '剑魔', '道', '酬', '勤', '剑圣'} 无序的
删:
s = {"猎空","源氏","半藏","死神"}
ret = s.pop() #随机删除一个元素
print(ret)
s.remove("源氏") #直接删除元素
print(s) #{'死神', '猎空', '半藏'}
s.clear() #清空set集合.需要注意的是set集合如果是空的. 打印出来是set() 因为要和dict区分的.
print(s)
改:
# set集合中的数据没有索引. 也没有办法去定位⼀个元素. 所以没有办法进⾏直接修改.
# 我们可以采⽤先删除后添加的⽅式来完成修改操作
s = {"猎空","源氏","半藏","死神"}
s.remove("猎空")
print(s) #{'死神', '源氏', '半藏'}
s.add("堡垒")
print(s) #{'源氏', '半藏', '死神', '堡垒'}
查:
# set集合是一个可迭代对象,可用for循环进行查找
s = {"猎空","源氏","半藏","死神"}
for e in s:
print(e)

frozenset()冻结的集合.不可变的.可哈希的
s = frozenset(["赵本山","常贵","皮长山"])
print(s) #frozenset({'赵本山', '常贵', '皮长山'})
dic = {s:"123"} #{frozenset({'赵本山', '常贵', '皮长山'}): '123'}
print(dic)
集合的其它操作:
s1 = {"刘能","赵四","皮长山"}
s2 = {"刘科长","冯乡长","皮长山"}
# 交集
# 两个集合中的共有元素
print(s1 & s2) #{"皮长山"}
print(s1.intersection(s2)) #{"皮长山"}
# 并集
print(s1|s2) #{'冯乡长', '刘科长', '皮长山', '刘能', '赵四'}
print(s1.union(s2)) #{'冯乡长', '皮长山', '刘能', '刘科长', '赵四'}
# 差集
print(s1 - s2) # {'赵四', '刘能'} 得到第⼀个中单独存在的
print(s1.difference(s2)) #{'刘能', '赵四'}
# 反交集
print(s1^s2) #两个集合中单独存在的数据 {'刘科长', '刘能', '冯乡长', '赵四'}
print(s1.symmetric_difference(s2)) #{'刘科长', '刘能', '冯乡长', '赵四'}
s1 = {"刘能","赵四"}
s2 = {"刘能","赵四","皮长山"}
# 子集
print(s1<s2) #set1是set2的子集吗? Ture
print(s1.issubset(s2))
# 超集
print(s1>s2) #set1是set2的超集吗? False
print(s1.issuperset(s2))
s = frozenset(["赵本山","刘能","皮长山","常贵"])
dic = {s:"123"}
print(dic) #{frozenset({'常贵', '皮长山', '刘能', '赵本山'}): '123'}
三丶深浅拷贝(难点)
1.赋值.没有创建新对象.公用同一个对象
lst1 = ["金毛狮王","紫衫龙王","白眉鹰王","青翼蝠王"]
lst2 = lst1
print(lst1) #['金毛狮王', '紫衫龙王', '白眉鹰王', '青翼蝠王']
print(lst2) #['金毛狮王', '紫衫龙王', '白眉鹰王', '青翼蝠王']
lst1.append("杨逍")
print(lst1) #['金毛狮王', '紫衫龙王', '白眉鹰王', '青翼蝠王', '杨逍']
print(lst2) #['金毛狮王', '紫衫龙王', '白眉鹰王', '青翼蝠王', '杨逍']
dic1 = {"id":123,"name":"谢逊"}
dic2 = dic1
print(dic1) #{'id': 123, 'name': '谢逊'}
print(dic2) #{'id': 123, 'name': '谢逊'}
dic1["name"] = "范瑶"
print(dic1) #{'id': 123, 'name': '范瑶'}
print(dic2) #{'id': 123, 'name': '范瑶'}
2.浅拷贝.拷贝第一层内容.[:]或copy()
#浅拷贝
lst1 = ["何炅","杜海涛","周渝民"]
lst2 = lst1.copy()
lst1.append("李嘉诚")
print(lst1)
print(lst2)
print(id(lst1),id(lst2))
#结果
# ['何炅', '杜海涛', '周渝民', '李嘉诚']
# ['何炅', '杜海涛', '周渝民']
# 1653894977480 1653895005704
# 两个lst完全不一样,内存地址和内容也不一样,发现实现了内存的拷贝
lst1 = ["何炅","杜海涛","周渝民",["麻花藤","马芸","周笔畅"]]
lst2 = lst1.copy()
lst1[3].append("无敌是多么寂寞")
print(lst1)
print(lst2)
print(id(lst1[3]),id(lst2[3]))
# 结果
# ['何炅', '杜海涛', '周渝民', ['麻花藤', '马芸', '周笔畅', '无敌是多么寂寞']]
# ['何炅', '杜海涛', '周渝民', ['麻花藤', '马芸', '周笔畅', '无敌是多么寂寞']]
# 1479533238216 1479533238216
# 浅拷贝:只会拷贝第一层,第二层的内容不会拷贝,所以被称为浅拷贝
3.深拷贝.拷贝所有内容.包括内部的所有
#深拷贝
import copy
lst1 = ["何炅","杜海涛","周渝民",["麻花藤","马芸","周笔畅"]]
lst2 = copy.deepcopy(lst1)
lst1[3].append("无敌是多么寂寞")
print(lst1)
print(lst2)
print(id(lst1[3]),id(lst2[3]))
#结果
# ['何炅', '杜海涛', '周渝民', ['麻花藤', '马芸', '周笔畅', '无敌是多么寂寞']]
# ['何炅', '杜海涛', '周渝民', ['麻花藤', '马芸', '周笔畅']]
# 1589080305224 1589080421384

 浙公网安备 33010602011771号
浙公网安备 33010602011771号