


垃圾回收机制:
不能被程序访问到的数据,就称之为垃圾。
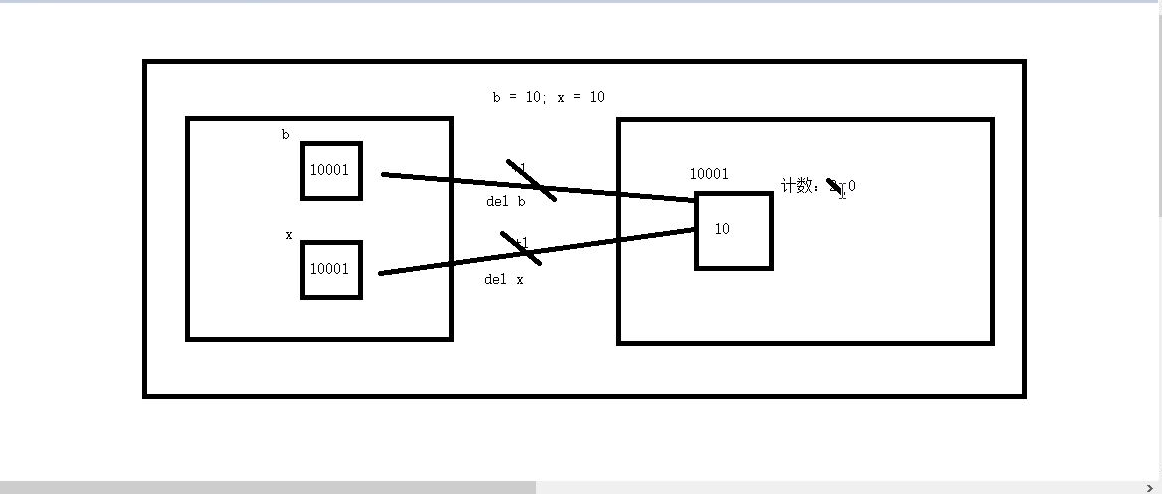
- 引用计数:引用计数是用来记录值的内存地址被记录的次数的
- 每一次对值地址的引用都可以使得该值的引用计数+1
- 每一次对值地址的释放都可以使得该值的引用计数-1
- 当一个值的引用计数为0的时候,该值就会被系统的垃圾回收机制回收
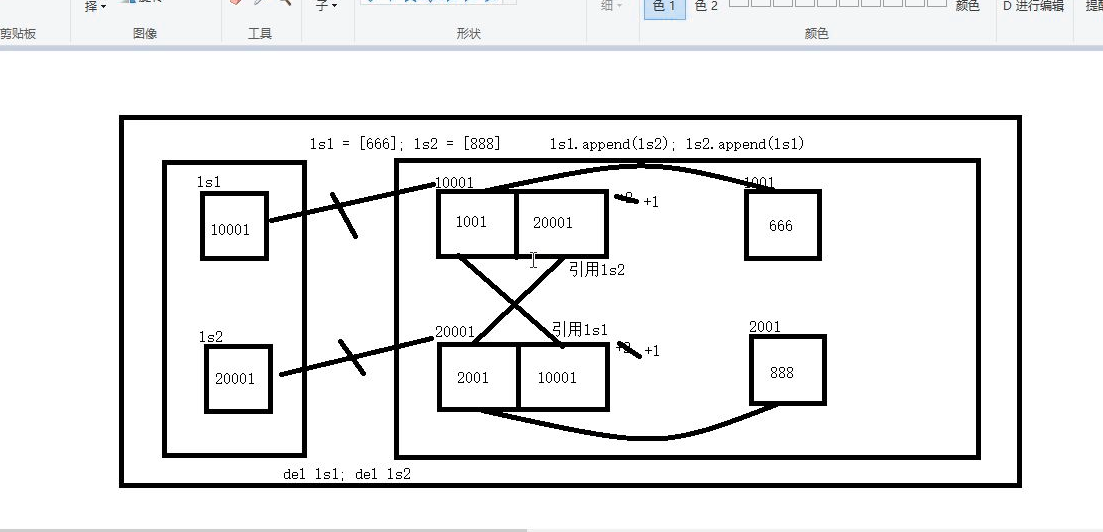
· 循环导入:循环导入会导致某些值的引用计数永远大于1-----导致内存泄漏
# 循环导入 ls1 = [666] ls2 = [888] ls1.append(ls2) # [666, [888, [...]]] ls2.append(ls1) # [888, [666, [...]]] print(ls1) print(ls2)
示意图:
标记删除:
- 标记的过程:其实就是,遍历所有的GC ROOTS对象(栈区中的所有内容,或者线程都可以作为GC Roots对象),然后将所有的GC Roots对象可以直接或间接的访问到的对象标记为存活状态对象,并且存放到新的内存空间中。
- 删除的过程:其实就是,将遍历堆中所有的对象,将之前的所有内容(标记或未标记)全部清除,此事标记为存活的对象存放在新的内存空间。
分代回收:
- 分代:指的是根据存活时间来为变量划分不同的等级(也就是不同的代)
- 回收:依然是使用引用计数作为回收的依据
'''
新定义的变量,放到新生代这个等级中,假设每隔1分钟扫描新生代一次,如果发现变量依然被引用,
那么该对象的权重(权重本质就是个整数)加一,当变量的权重大于某个设定得值(假设为3),会将它移动到更高一级的青春代,青春代的gc扫描的频率低于新生代(扫描时间间隔更长),
假设5分钟扫描青春代一次,这样每次gc需要扫描的变量的总个数就变少了,节省了扫描的总时间,
接下来,青春代中的对象,也会以同样的方式被移动到老年代中。也就是等级(代)越高,被垃圾回收机制扫描的频率越低
'''

分代过程
''' 总结 ''' """ python的内存管理使用垃圾回收机制 本质是使用引用计数 优化方法是 分代回收 解决循环导入问题,是标记清除 """

 浙公网安备 33010602011771号
浙公网安备 33010602011771号