

AWVS介绍
1.1什么是AWVS(Acunetix Web Vulnarability Scanner)
是一款知名的网络漏洞扫描工具,它通过网络爬虫测试你的网站安全,检测流行安全漏洞
1.2功能以及特点:
- 自动的客户端脚本分析器,允许对 Ajax 和 Web 2.0 应用程序进行安全性测试。
- 业内最先进且深入的 SQL 注入和跨站脚本测试
- 高级渗透测试工具,例如 HTTP Editor 和 HTTP Fuzzer
- 可视化宏记录器帮助您轻松测试 web 表格和受密码保护的区域
- 支持含有 CAPTHCA 的页面,单个开始指令和 Two Factor(双因素)验证机制
- 丰富的报告功能,包括 VISA PCI 依从性报告
- 高速的多线程扫描器轻松检索成千上万个页面
- 智能爬行程序检测 web 服务器类型和应用程序语言
- Acunetix 检索并分析网站,包括 flash 内容、SOAP 和 AJAX
- 端口扫描 web 服务器并对在服务器上运行的网络服务执行安全检查
- 可导出网站漏洞文件
1.3.AWVS界面介绍:
AWVS的界面主要分为六个部分,分别是:标题栏、菜单栏、工具栏、主要操作区域、主界面、状态区域。


----详细介绍:

AWVS的菜单栏,工具栏简介:

u 菜单栏
File——New——Web Site Scan :新建一次网站扫描
File——New——Web Site Crawl:新建一次网站爬行
File——New——Web Services Scan:新建一个WSDL扫描
Load Scan Results:加载一个扫描结果
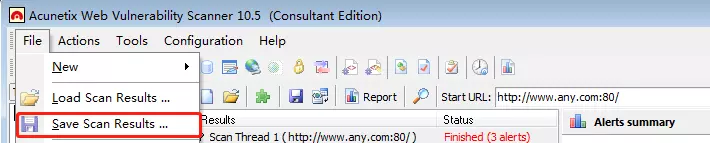
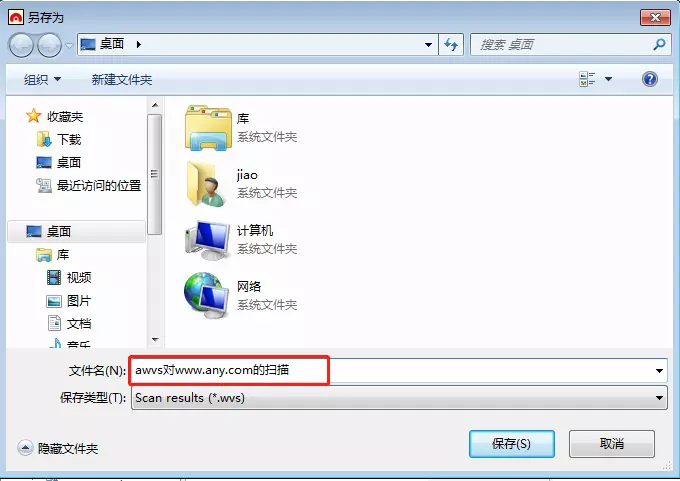
Sava Scan Results:保存一个扫描结果
Exit:退出程序
Tools:参考主要操作区域的tools
Configuration——Application Settings:程序设置
Configuration——Scan Settings:扫描设置
Configuration——Scanning Profiles:侧重扫描的设置
Help——Check for Updates:检查更新
Help——Application Directories——Data Directory:数据目录
Help——Application Directories——User Directory:用户目录
Help——Application Directories——Scheduler Sava Directory:计划任务保存目录
Help——Schedule Wen Interface:打开WEB形式计划任务扫描处
Help——Update License:更新AWVS的许可信息
Help——Acunetix Support——User Mannul(html):用户HTML版手册
Help——Acunetix Support——User Mannul(PDF):用户PDF版手册
Help——Acunetix Support——Acunetix home page:AWVS官网
Help——Acunetix Support——HTTP Status:HTTP状态码简介
1.4 AWVS基本功能介绍
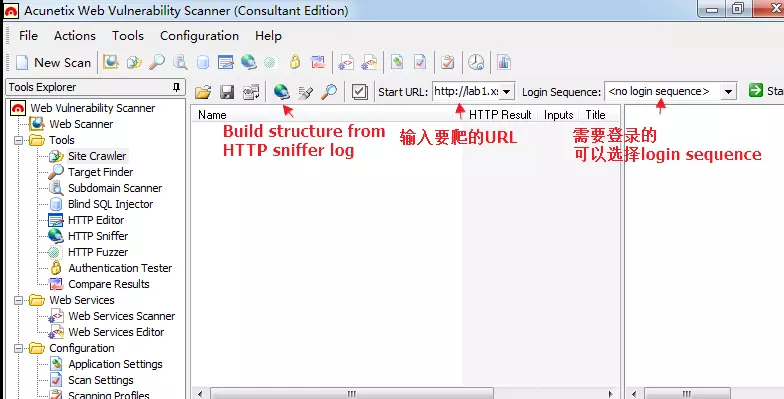
1.4.1 AWVS的蜘蛛爬虫功能
Site Crawler
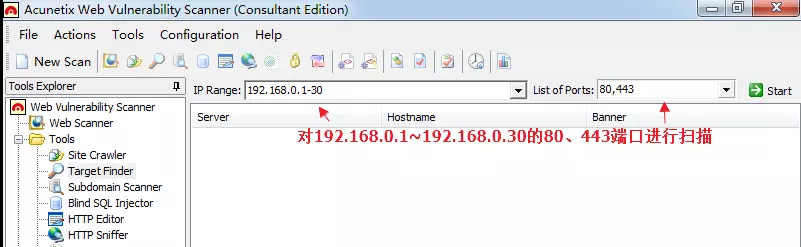
1.4.2 AWVS目标探测工具
Target Finder
相当于一款加强版(针对WEB渗透测试)的端口、banner探测工具功能:
1、探测指定IP/IP段开放特定端口的IP
2、探测出IP后,探测该端口的banner信息,可探测出该端口上运行的WEB服务的中间件的版本信息
3.可以指定IP地址段进行端口扫描(类似于Nmap),可以用与信息收集。
4.进行了端口扫描后会进行服务发现,得到端口上对应的服务。
Subdomain Scanner
用DNS进行域名解析,找域名下的子域及其主机名(用于信息收集)
可选择使用操作系统默认配置的DNS服务器或自定义的一个DNS服务器(谷歌:8.8.8.8)

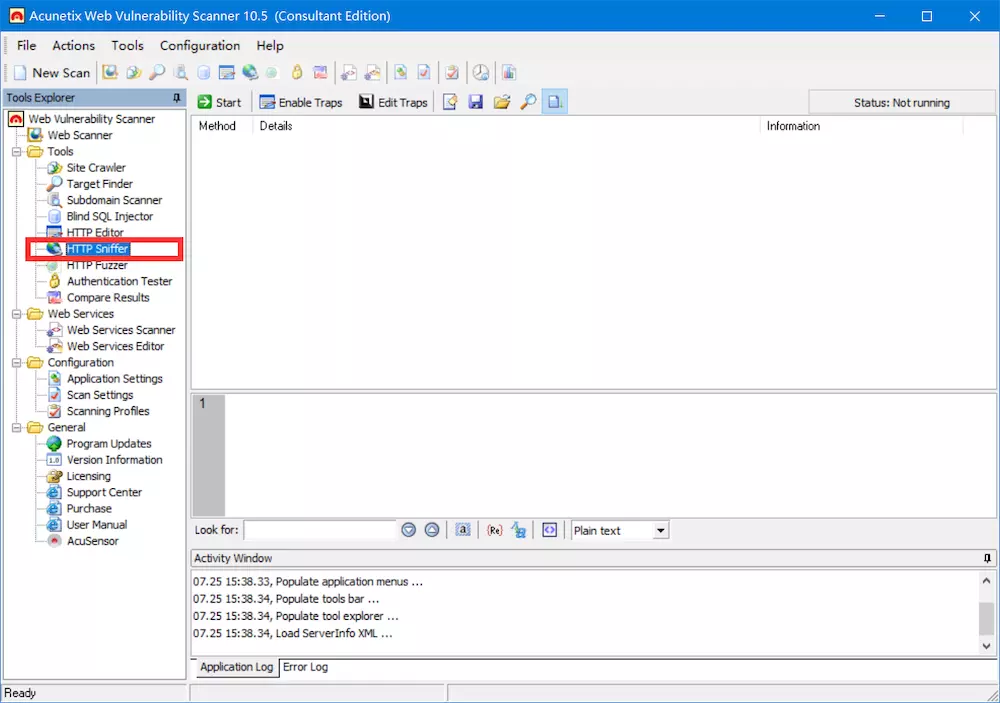
1.4.4 AWVS的HTTP嗅探工具
HTTP Sniffer
和BP proxy类似,首先要设置代理(Application Settings->HTTP Sniffer),截取数据包,修改数据包提交或者丢弃。
利用代理功能进行手动爬网(保存为slg文件,在Site Crawler页面点击Build structure from HTTP sniffer log),得到自动爬网爬取不到的文件。
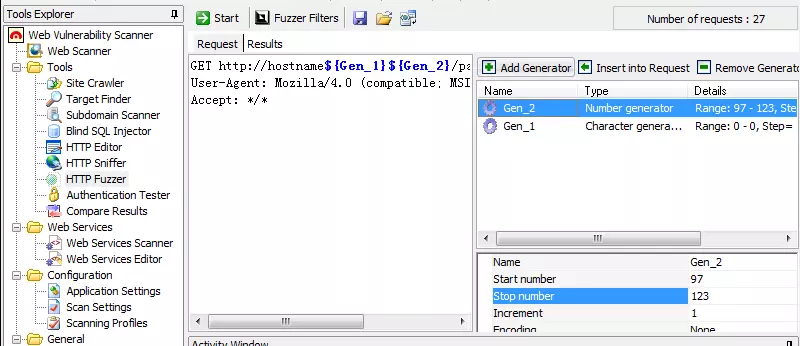
1.4.5 AWVS的HTTP模糊测试工具
HTTP Fuzzer
类似于BP intruder,进行暴力破解,点击+选择类型,点击insert插入。
注意:插入字母的时候选取字母的范围填写的是字母对应的ASCII码。
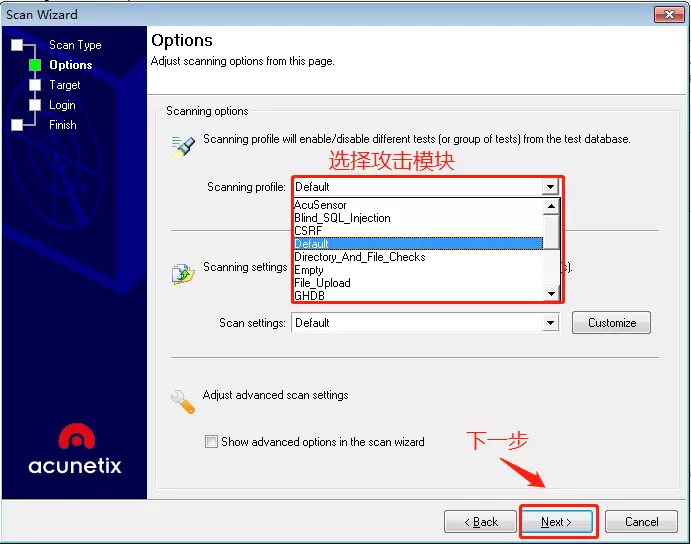
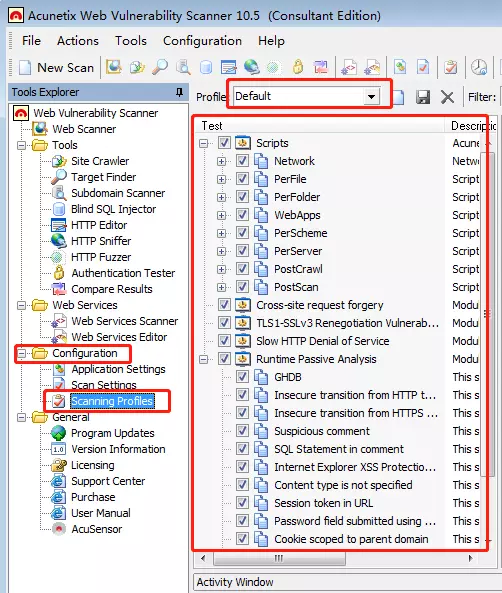
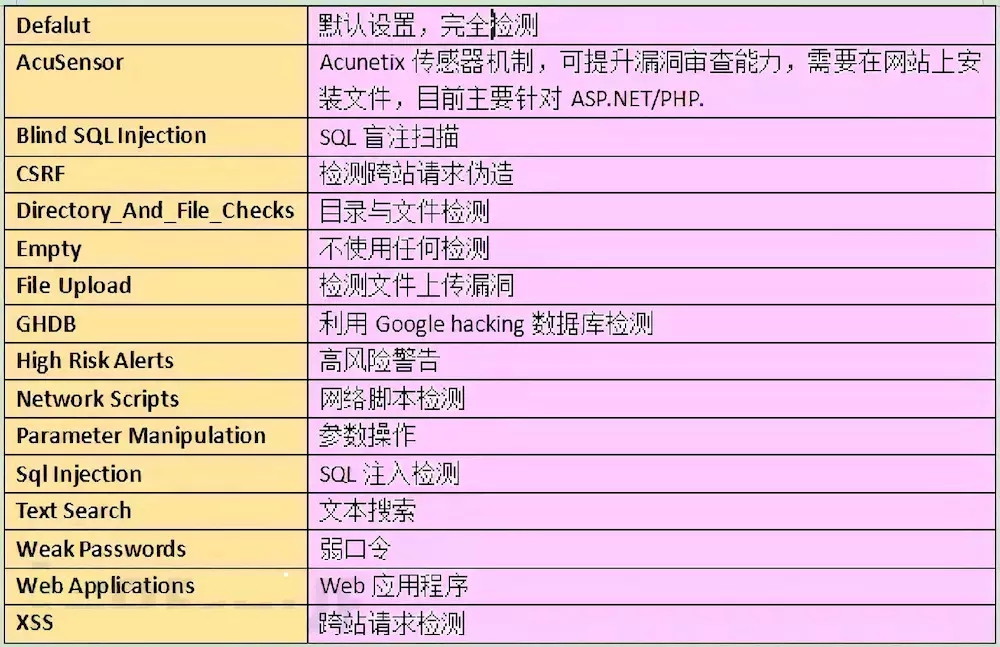
awvs一共有提供16种攻击模块,如下表:
Defalut默认,全部检测
AcuSensorAcunetix传感器机制,可提升漏洞审查能力,需要在网站上安装文件,目前针对ASP.NET/PHP
Blind SQL InjertionSQL盲注检测
CSRF检测跨站请求伪造
Directory_And_File_Checks目录与文件检测
Empty不使用任何检测
GHDB利用Google hacking数据库检测
High Risk Alerts高风险警告
Network Scripts网络脚本检测
Parameter Manipulations参数操作
Sql InjectionSQL注入检测
Text Search文本搜索
Weak Passwords检测弱口令
Web Applicationsweb应用检测
XSS跨站请求伪造
File Upload检测文件上传漏洞
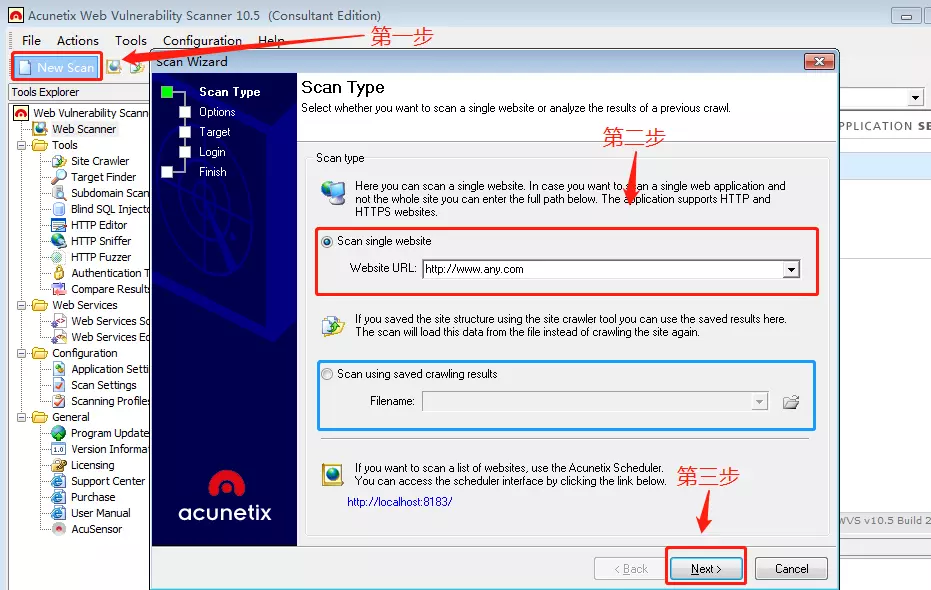
第三步:
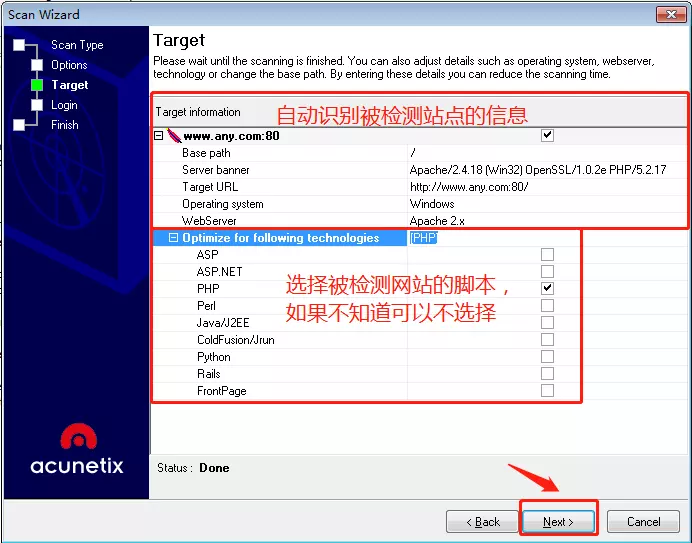
awvs会自动识别被检测站点的信息,在这个页面显示出来,还可以选择目标网站的脚本语言,如果不知道,可以不选择,直接点击下一步即可。
- 其中target information中的内容是:
- base path:扫描目标的根路径
- server banner:服务的banner
- target URL:目标url
- operating system:目标操作系统
- webserver:目标的web服务器
第四步:

根据需求,可以录入或者填写登录信息,如果没有的话,直接按照默认设置,然后点击“Next”
PS:如果网站需要登录,则需要提供登录信息,否则有些需要登录才能操作的页面就无法探测到。
1) Use pre-recorded login sequence选项,第一个红圈:
黄色圈内:可直接打开AWVS的内置浏览器,录制登录被测网站的脚本
蓝色圈内:可导入已经录制好的登录脚本
2) Try to auto-login into the site选项,第二个红圈:
可直接输入登录网站所需的账户名和密码,然后AWVS用自动探测技术进行识别,不需要手工录入登录过程。
这里因为我们将要访问的网站是不需要直接登录就能访问的网站,所以这里就不在细说。
第五步:
直接点击Finish即可。之后awvs就会对目标网站进行扫描,然后需要耐心等待扫描完成。
1.5 使用awvs检测扫描结果
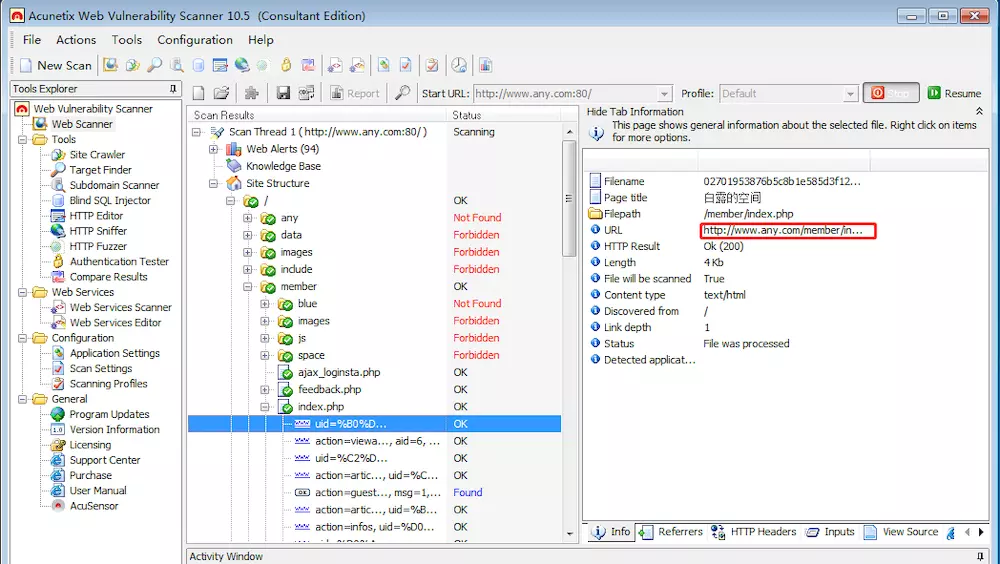
1.1.1查看扫描结果
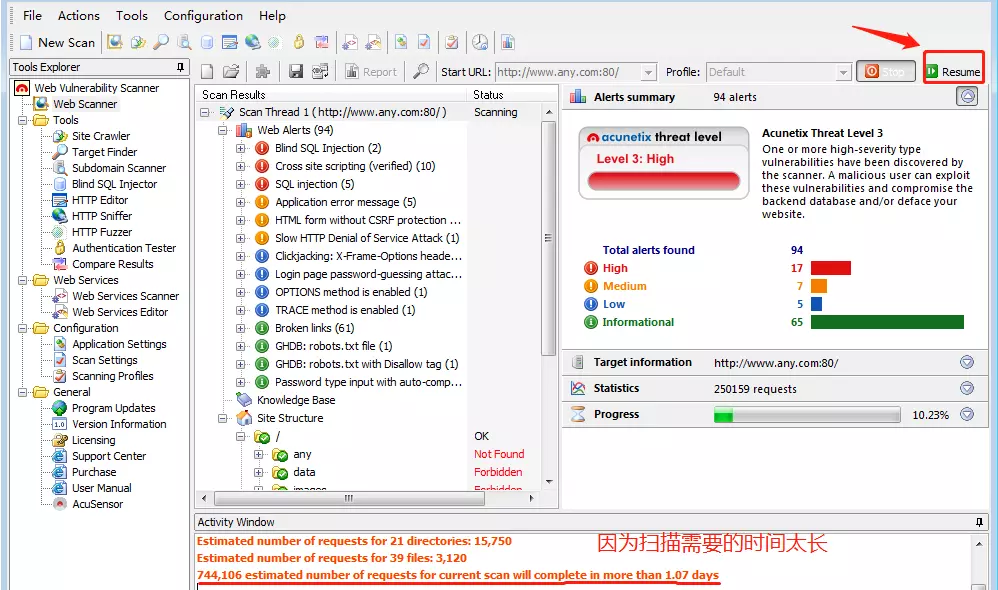
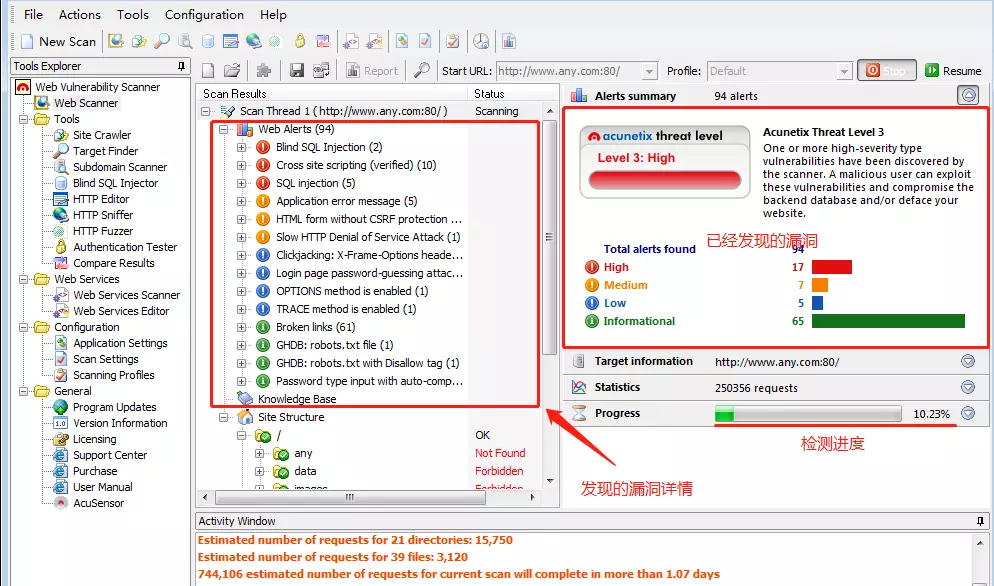
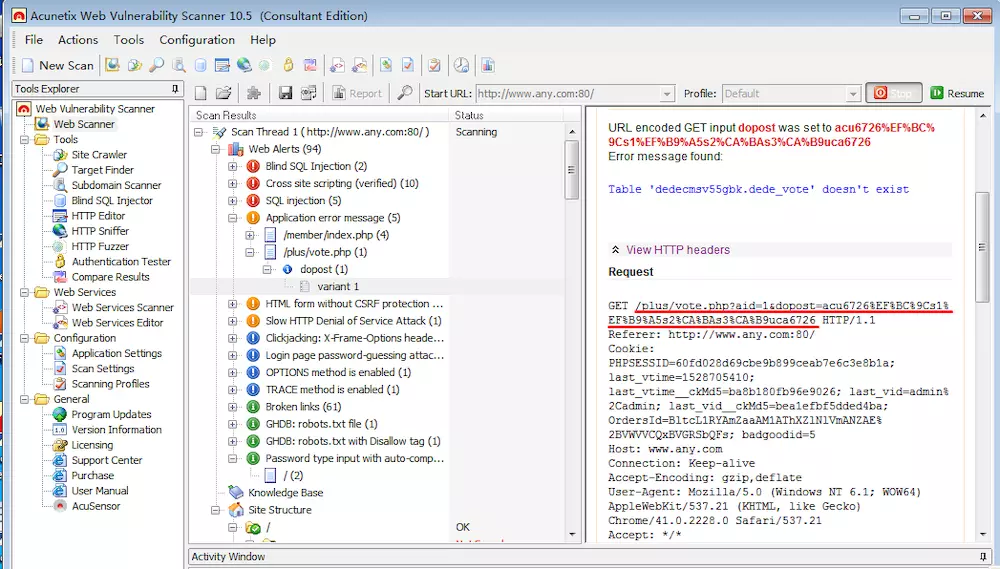
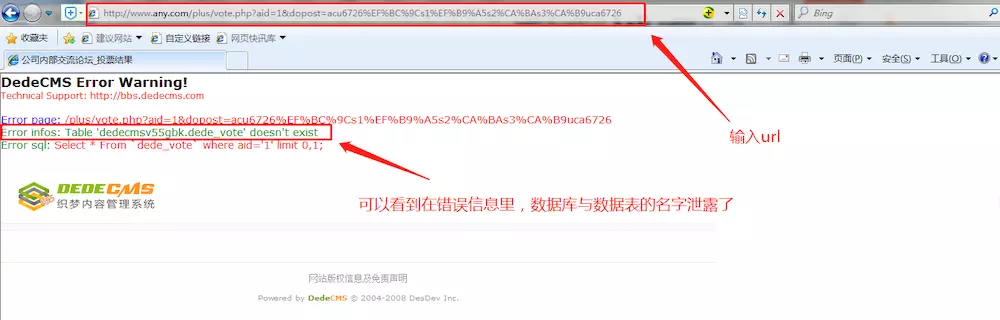
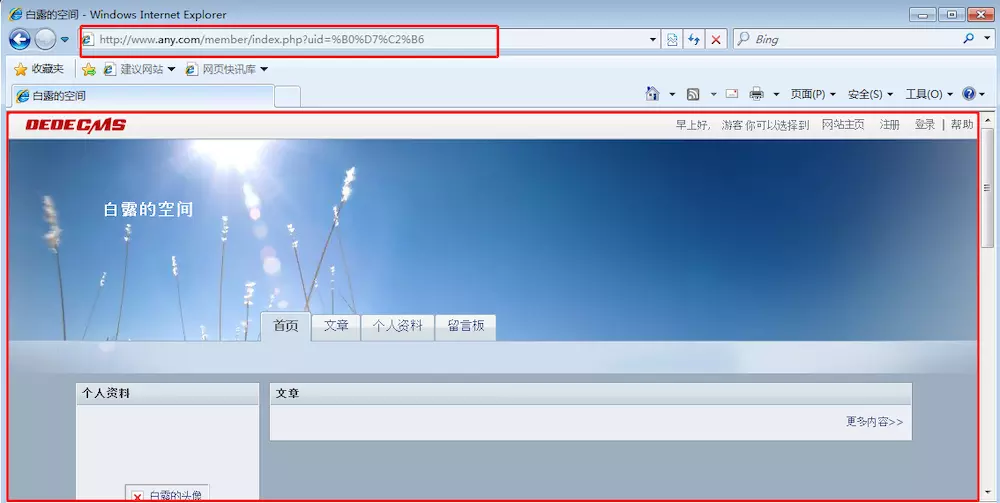
验证漏洞:我们随便点开一个漏洞,然后将划红线的写入浏览器的url中,可以看到,在错误信息中,该系统使用的数据库与数据表的名字泄露了,而这些本来应该是非常机密的信息。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号