使用df.to_sql将DataFrame导入到sql中
一、背景
虽然已经有了一些导入到数据库的方式,但是代码量大,而且碰到特殊字符,比如单引号等,就会出错。
可参考:https://www.cnblogs.com/qianslup/p/17694731.html
https://www.cnblogs.com/qianslup/p/12567284.html
于是发现了to_sql这个功能。
也算是对之前的一个更新迭代
二、数据准备

三、代码展示
1 import pandas as pd 2 import pymssql 3 from sqlalchemy import create_engine 4 5 # 链接sql server数据库 注意:此处的连接信息,要改成你自己的 6 conn = pymssql.connect(server="qiansl", user="sa", password="666666", database="Test") # 这段代码没用,只是给engine做说明的 7 # 创建sql server引擎 注意:此处的连接信息,要改成你自己的 参照上面的写 8 # engine = create_engine('mssql+pymssql://user:password@server/database') 9 engine = create_engine('mssql+pymssql://sa:666666@qiansl/Test') 10 11 path_file = r"E:\Test\InsertSql.xlsx" 12 sheet_name = "Sheet1" 13 14 15 if path_file[-4:] == "xlsx": 16 df = pd.read_excel(io=path_file, sheet_name=sheet_name, dtype=str) 17 elif path_file[-3:] == "csv": 18 df = pd.read_csv(filepath_or_buffer=path_file, dtype=str) 19 20 """ 21 if_exists 的三个值 22 'fail':表存在时引发错误, 默认值。 23 'replace':表存在时删除旧表并创建新表。 24 'append':表存在时追加数据,不存在时创建新表。 25 """ 26 df.to_sql(name='test', con=engine, schema='test', if_exists='replace', index=False, chunksize=1000)
四、结果展示
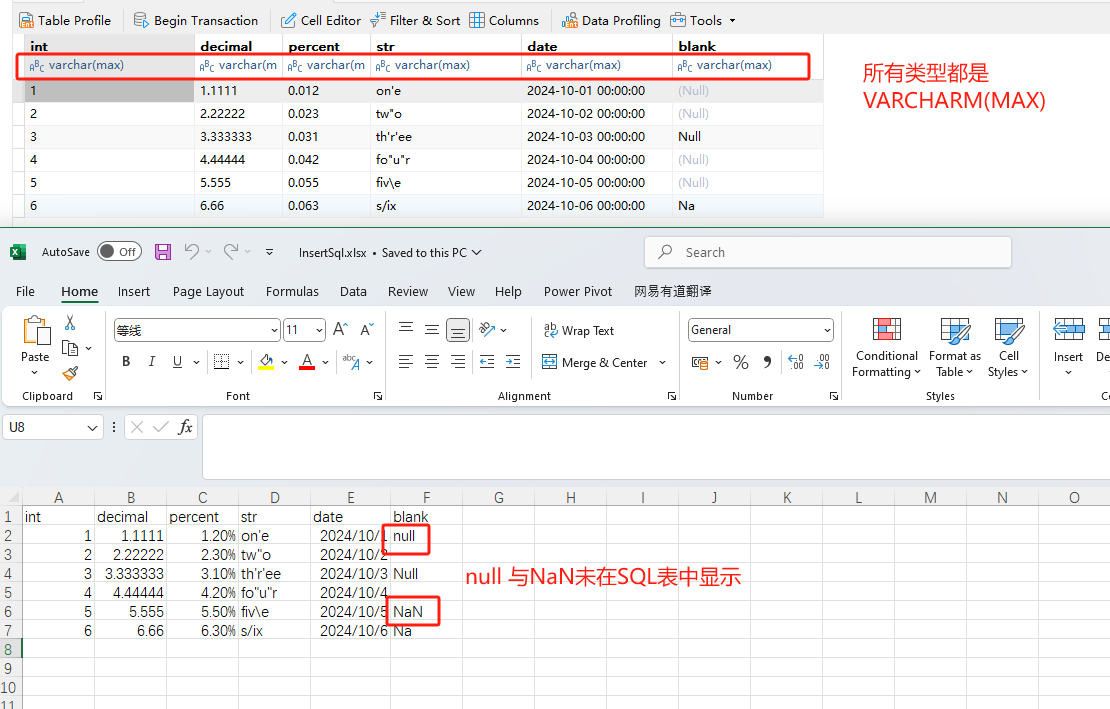
五、总结
总体上比之前好用太多了。
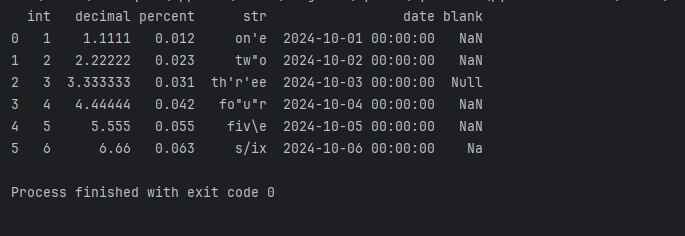
至于null和NaN,因为Python读取时,将其设为了NaN。
可参考:https://www.cnblogs.com/qianslup/p/18388847

 浙公网安备 33010602011771号
浙公网安备 33010602011771号