DataFrame增加行与列
一、背景
DataFrame中有时需要加入行与列,需要加入的行与列格式是多种多样的,可能是DataFrame、Series、list、dict等形式。
不同形式也需要不同的方法。
- windos系统
- Python版本 python3.11.8
二、加入行
2.1 建一个空的DataFrame
import pandas as pd df = pd.DataFrame(columns=['name','age' ,'weight']) print(df)
2.2 通过_append加入
import pandas as pd df = pd.DataFrame(columns=['name','age' ,'weight']) # print(df) # 通过append加入,app默认加入到最后位置 dict_1 = {'name': '钱五一', 'weight': 61, 'age': 51} # 顺序可以打乱 df = df._append(dict_1,ignore_index=True) # print(df) list_1 = ['钱五四', 54, 64] Series_1 = pd.Series(['钱五二', 52, 62]) Series_2 = pd.Series(['钱五三', 53, 63], index=['name', 'weight', 'age']) df = df._append(list_1, ignore_index=True) df = df._append(Series_1, ignore_index=True) df = df._append(Series_2, ignore_index=True) print(df)

通过_append中加入需要主要的点:
- _append是从现有的df的后面插入
- 通过dict与Series格式需要指定索引
- list与Series如果不指定索引,则出现的结果不是我们想要的。
- 可以将另外一个df插入到df中,注意索引。
2.3 通过loc插入数据
import pandas as pd df = pd.DataFrame(columns=['name','age' ,'weight']) # print(df) dict_1 = {'name': '钱五一', 'weight': 61, 'age': 51} # 顺序可以打乱 Series_1 = pd.Series(['钱五二', 52, 62]) Series_2 = pd.Series(['钱五三', 53, 63], index=['name', 'weight', 'age']) list_1 = ['钱五四', 54, 64] data = {'name':["张三", "李四", "王二"], 'age':[30, 40, 20], "weight": [50, 60 , 70]} df2 = pd.DataFrame(data=data) df.loc[len(df)] = dict_1 df.loc[len(df)] = Series_1 df.loc[len(df)] = Series_2 df.loc[len(df)] = list_1 print(df) print("*"*20) df.loc[0] = list_1 print(df)

- 通过loc进行插入,没有对应的数据则增加,又对应的数据则替换
- 插入的类型如果为Series,dict需要指定索引,List无需指定索引
- 一般一次只插入一行
2.3 通过concat插入。
import pandas as pd df = pd.DataFrame(columns=['name','age' ,'weight']) # print(df) data = {'name':["张三", "李四", "王二"], 'age':[30, 40, 20], "weight": [50, 60 , 70]} df2 = pd.DataFrame(data=data) df = pd.concat(objs=[df,df2], ignore_index=True) print(df)
- 通过concat可以拼接两个DataFrame
三、加入列
3.1 通过映射加入相关列
import pandas as pd data = {'name':["张三", "李四", "王二"], 'age':[30, 40, 20], "weight": [50, 60 , 70]} df = pd.DataFrame(data=data) def get_x(weight): return weight*2 df["w2"] = df['weight'].map(get_x) df['a2'] = df['age']*2 df['wa'] = df['weight']+df['age'] print(df)
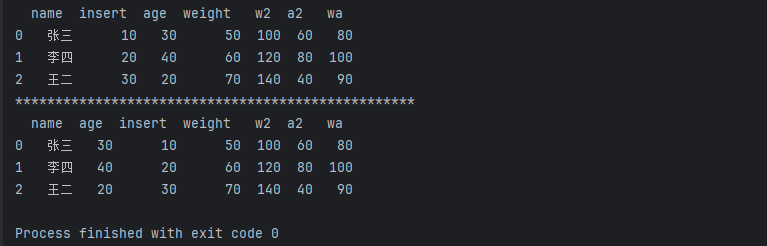
3.2 通过insert加入列与调整列的位置
import pandas as pd data = {'name':["张三", "李四", "王二"], 'age':[30, 40, 20], "weight": [50, 60 , 70]} df = pd.DataFrame(data=data) def get_x(weight): return weight*2 # 移动列的位置 def move_column(df, cn, cp): # 定义移动的列 m_column = df.pop(cn) # 关键代码(位置, 列名, 要移动的列) df.insert(cp, cn, m_column) df["w2"] = df['weight'].map(get_x) df['a2'] = df['age']*2 df['wa'] = df['weight']+df['age'] # df.insert(1, 'insert',[10, 20, 30]) df.insert(loc=1, column='insert',value =[10, 20, 30]) print(df) print('*'*50) move_column(df, cn='age', cp=1) print(df)
3.3 通过map与apply
import pandas as pd data = {'name':["张三", "李四", "王二"], 'age':[30, 40, 20], "weight": [50, 60 , 70]} df = pd.DataFrame(data=data) def get_x(age): return age/2 def get_y(age, n): y = age+n return y def get_z(age, weight): z = weight / age / age return z # map 用来处理Series, df['x1'] = df['age'].map(get_x) age_dict = {30:15, 40:20, 20:10} df['x2'] = df['age'].map(age_dict) # apply 用来处理Series和DataFrame # 从某一列中取数 df['x'] = df['age'].apply(lambda x : get_x(x) ) # 从某一列中取数,并增加一个参数 df['y'] = df['age'].apply(lambda x : get_y(x, 10)) # 从两列中取数 df['z'] = df.apply(lambda row: get_z(row['age'], row['weight']) if row['age'] > 20 else '', axis=1) print(df)


 浙公网安备 33010602011771号
浙公网安备 33010602011771号