re模块
一、说明
模式和被搜索的字符串既可以是 Unicode 字符串 (str) ,也可以是8位字节串 (bytes)。
但是,Unicode 字符串与8位字节串不能混用:也就是说,你不能用一个字节串模式去匹配 Unicode 字符串,反之亦然;
类似地,当进行替换操作时,替换字符串的类型也必须与所用的模式和搜索字符串的类型一致。
正则表达式使用反斜杠字符 ('\') 来表示特殊形式或是允许在使用特殊字符时不引发它们的特殊含义。
这会与 Python 的字符串字面值中对相同字符出于相同目的的用法产生冲突;例如,要匹配一个反斜杠字面值,用户可能必须写成 '\\\\' 来作为模式字符串,因为正则表达式必须为 \\,而每个反斜杠在普通 Python 字符串字面值中又必须表示为 \\。
而且还要注意,在 Python 的字符串字面值中使用的反斜杠如果有任何无效的转义序列,现在将会产生 DeprecationWarning 并将在未来改为 SyntaxError。 此行为即使对于正则表达式来说有效的转义字符同样会发生。
解决办法是对于正则表达式样式使用 Python 的原始字符串表示法;在带有 'r' 前缀的字符串字面值中,反斜杠不必做任何特殊处理。
因此 r"\n" 表示包含 '\' 和 'n' 两个字符的字符串,而 "\n" 则表示只包含一个换行符的字符串。 样式在 Python 代码中通常都会使用这种原始字符串表示法来表示。
二、模块内容
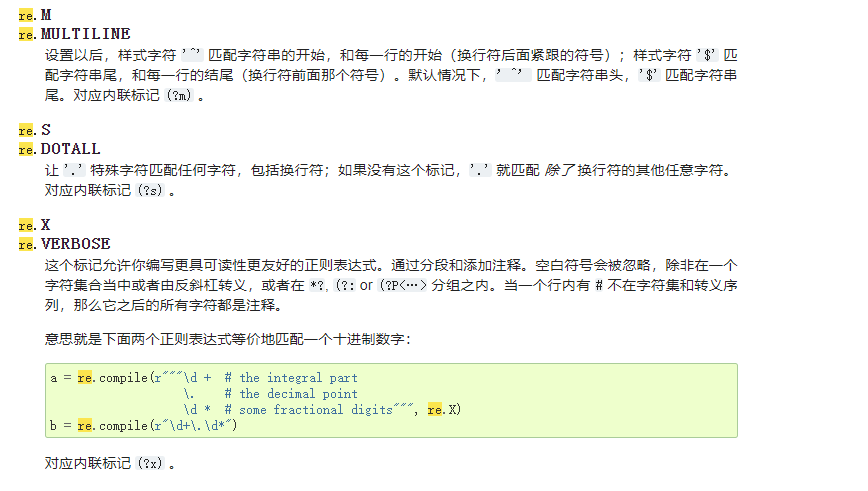
2.1 flag标志位
| 简写 | 全写 | 解释 |
| re.I | re.IGNORECASE | 行忽略大小写匹配 |
| re.A | re.ASCLL | 只匹配ASCII,而不是Unicode |
| re.L | re.LOCALE | 做本地化识别(locale-aware)匹配 |
| re.M | re.MULTILINE | 多行匹配,影响 ^ 和 $ |
| re.S | re.DOTALL | 使 . 匹配包括换行在内的所有字符 |
| re.X | re.VERBOSE | 这个标记允许你编写更具可读性更友好的正则表达式 |

2.2 常用方法
| 方法 | 解释 | 备注 |
| re.compile(pattern, flags=0) | 返回的是一个匹配对象,它单独使用就没有任何意义 | ,需要和findall(), search(), match()搭配使用 |
| re.search(pattern, string, flags=0) | 扫描整个 字符串 找到匹配样式的第一个位置,并返回一个相应的 匹配对象。如果没有匹配,就返回一个 None ; |
注意这和找到一个零长度匹配是不同的。 |
| re.match(pattern, string, flags=0) | 如果 string 开始的0或者多个字符匹配到了正则表达式样式,就返回一个相应的 匹配对象 。 如果没有匹配,就返回 None |
注意这跟零长度匹配是不同的。 |
| re.fullmatch(pattern, string, flags=0) | 如果整个 string 匹配到正则表达式样式,就返回一个相应的 匹配对象 。 否则就返回一个 None |
注意这跟零长度匹配是不同的。 |
| re.findall(pattern, string, flags=0) | 对 string 返回一个不重复的 pattern 的匹配列表, string 从左到右进行扫描,匹配按找到的顺序返回。 如果样式里存在一到多个组,就返回一个组合列表; |
空匹配也会包含在结果里。 |
| re.finditer(pattern, string, flags=0) | pattern 在 string 里所有的非重复匹配,返回为一个迭代器 iterator 保存了 匹配对象 。 string 从左到右扫描,匹配按顺序排列 | 空匹配也包含在结果里。 |
| re.split(pattern, string, maxsplit=0, flags=0) | 用 pattern 分开 string 。 如果在 pattern 中捕获到括号,那么所有的组里的文字也会包含在列表里。 如果 maxsplit 非零, 最多进行 maxsplit 次分隔, 剩下的字符全部返回到列表的最后一个元素。 |
|
| re.sub(pattern, repl, string, count=0, flags=0) | 返回通过使用 repl 替换在 string 最左边非重叠出现的 pattern 而获得的字符串。 如果样式没有找到,则不加改变地返回 string。 |
repl 可以是字符串或函数;如为字符串,则其中任何反斜杠转义序列都会被处理, 未知的 ASCII 字符转义序列保留在未来使用,会被当作错误来处理。 其他未知转义序列例如 |
| re.subn(pattern, repl, string, count=0, flags=0) | 行为与 sub() 相同,但是返回一个元组 (字符串, 替换次数). |
|
| re.escape(pattern) | 转义 pattern 中的特殊字符。如果你想对任意可能包含正则表达式元字符的文本字符串进行匹配,它就是有用的 |
在 3.7 版更改: 只有在正则表达式中具有特殊含义的字符才会被转义。 因此, |
| re.purge() | 清除正则表达式缓存。 |
2.3 一个例外
exception re.error(msg, pattern=None, pos=None)
raise:一个例外。当传递到函数的字符串不是一个有效正则表达式的时候(比如,包含一个不匹配的括号)或者其他错误在编译时或匹配时产生。如果字符串不包含样式匹配,是不会被视为错误的。错误实例有以下附加属性:
msg:未格式化的错误消息。
pattern:正则表达式样式。
pos:编译失败的 pattern 的位置索引(可以是None)。
lineno:对应 pos (可以是None) 的行号。
colno:对应 pos (可以是None) 的列号。
2.4 代码演示
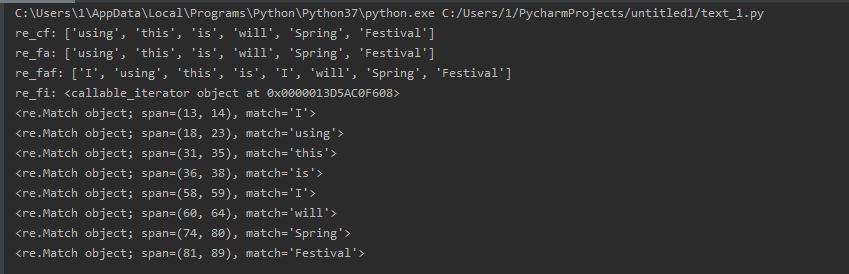
import re str_1 = 'hello world, I am using Python\n' \ 'this is year of the mouse, I will have the Spring Festival\n' \ 'good good study, day day up ' re_com = re.compile('\w*i\w*') re_cf = re_com.findall(str_1) re_fa = re.findall('\w*i\w*', str_1) re_faf = re.findall('\w*i\w*', str_1, re.I) re_fi = re.finditer('\w*i\w*', str_1, re.I) print("re_cf:", re_cf) print("re_fa:", re_fa) print("re_faf:", re_faf) print("re_fi:", re_fi) for i in re_fi: print(i)
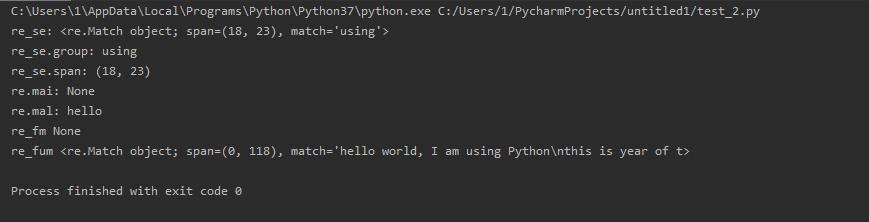
import re str_1 = 'hello world, I am using Python\n' \ 'this is year of the mouse, I will have the Spring Festival\n' \ 'good good study, day day up ' re_se = re.search('\w*i\w*', str_1) # 搜索匹配第一个符合pattern的对象 re_mai = re.match('\w*i\w*', str_1) # 如果符合patter不在开头,则返回none re_mal = re.match('\w*l\w*', str_1) re_fm = re.fullmatch('\w*l\w*', str_1) # pattern需要和string一样 re_fum = re.fullmatch(str_1, str_1) # pattern需要和string一样 print("re_se:", re_se) print("re_se.group:", re_se.group()) # 搜索匹配第一个符合pattern的对象,返回对应的字符串 print("re_se.span:", re_se.span()) # 搜索匹配第一个符合pattern的对象,返回对应的字符串位置 print("re.mai:", re_mai) # 如果返回None, 则无法使用.group:'NoneType' object has no attribute 'group' print("re.mal:", re_mal.group()) print("re_fm", re_fm) print("re_fum", re_fum)
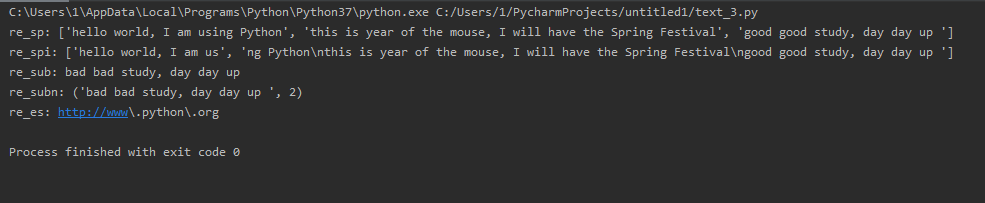
import re str_1 = 'hello world, I am using Python\n' \ 'this is year of the mouse, I will have the Spring Festival\n' \ 'good good study, day day up ' str_2 = 'good good study, day day up ' str_3 = 'http://www.python.org' re_spn = re.split('\n', str_1) re_spi = re.split('i', str_1, maxsplit=1) re_sub = re.sub("good", "bad", str_2) re_subn = re.subn("good", "bad", str_2) re_es = re.escape(str_3) print("re_sp:", re_spn) print("re_spi:", re_spi) print("re_sub:", re_sub) print("re_subn:", re_subn) print("re_es:", re_es)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号