高性能并行计算-阻塞式点对点通信
阻塞式点对点通信




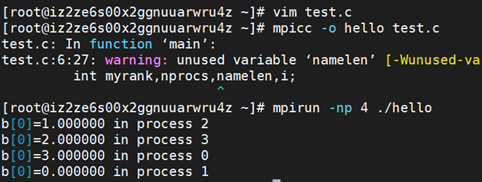
#include <stdio.h>
#include "mpi.h"
#define n 1024
int main(int argc,char *argv[]){
int myrank,nprocs,i;
double a[n],b[n];
MPI_Status status;
MPI_Init(&argc,&argv);
MPI_Comm_rank(MPI_COMM_WORLD,&myrank);
MPI_Comm_size(MPI_COMM_WORLD,&nprocs);
for(i=0;i<n;i++){
a[i] = myrank;
b[i] = 0;
}
//阻塞式消息发送
//int MPI_Send(void *buf, int count, MPI_Datatype datatype,
// int dest, int tag, MPI_Comm comm)
MPI_Send(a,n,MPI_DOUBLE,(myrank+1)%nprocs,99,MPI_COMM_WORLD);
// buf: 所要发送消息数据的首地址
// count: 发送消息数组元素的个数。不是字节数,而是指定数据类型的个数
// datatype: 发送消息的数据类型。可是原始数据类型,或为用户自定义类型
// dest: 接收消息的进程编号。取值范围是 0~np-1,或MPI_PROC_NULL (np是comm中的进程总数)
// tag: 消息标签。取值范围是 0~MPI_TAG_UB,用来区分消息
// comm: 通信器
//阻塞式消息接收
// int MPI_Recv(void *buf, int count, MPI_Datatype datatype,
// int source, int tag, MPI_Comm comm,
// MPI_Status *status)
MPI_Recv(b,n,MPI_DOUBLE,(myrank-1+nprocs)%nprocs,99,MPI_COMM_WORLD,&status);
// buf: 接收消息数据的首地址
// count: 接收消息数组元素的最大个数。是接受缓存区的大小,表示接受上界,具体接受长度可用MPI_Get_count 获得
// datatype: 接收消息的数据类型
// source: 发送消息的进程编号。取值范围是 0~np-1,或MPI_PROC_NULL和MPI_ANY_SOURCE
// tag: 消息标签。取值范围是 0~MPI_TAG_UB,或MPI_ANY_TAG
// comm: 通信器
// status: 接收消息时返回的状态
printf("b[0]=%f in process %d\n",b[0],myrank);
MPI_Finalize();
return 0;
}

注意死锁的发生

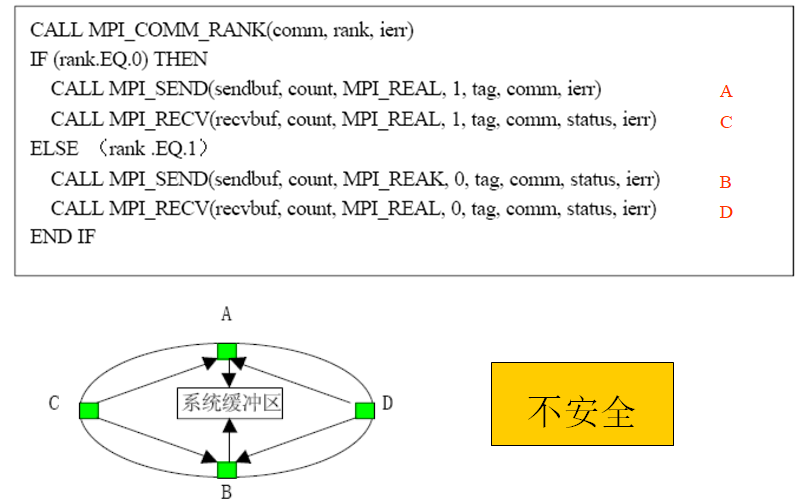
- MPI_Send 要 receive 完之后才 return,如果大家都 send 那就死锁了,
教程里解决死锁的办法是奇偶 rank 的执行顺序不同,奇的话是先收后发,偶的话是先发后收

捆绑发送和接收,收发使用同一缓存区
int MPI_Sendrecv_replace(void *buff,int count,MPI_Datatype datatype,
int dest, int sendtag,int source, int
recvtag,MPI_Comm comm, MPI_Status *status)


 浙公网安备 33010602011771号
浙公网安备 33010602011771号