MySQL数据库学习笔记(三)----基本的SQL语句
【声明】
欢迎转载,但请保留文章原始出处→_→
生命壹号:http://www.cnblogs.com/smyhvae/
文章来源:http://www.cnblogs.com/smyhvae/p/4028178.html
【正文】
主要内容:
- 一、cmd命令行的常用命令
- 二、数据定义语言(DDL)
- 三、数据操纵语言(DML)
- 四、数据查询语言(DRL)
- 五、事务控制语言(TCL)
一、cmd命令行的常用命令:
当我们使用MySQL 5.5 Command Line Client这个客户端登陆时,只能登陆root用户。如果今后创建了别的用户,就很麻烦了,所以我们不用MySQL 5.5 Command Line Client这个客户端,而是直接使用cmd。
登录MySQL数据库:
因为在这之前安装MySQL的时候,已经将环境变量配置好了,所以可以直接在cmd中输入如下命令进行登陆:
mysql -u root -p
紧接着输入密码就行了。
上方代码中,-u表示username,即用户名。-p表示password,即密码。

查看数据库:
show databases;
使用数据库:(此命令后面可以不加分号)
use 数据库名;
查看当前数据库表:
show tables;
注:命令后面的分号表示结束。
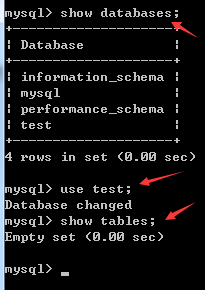
注:上图中,先输入show databases;显示出了四个库,前三个表示系统的库,第四个test是系统自带的测试库。然后我们使用test这个数据库,显示:Database changed,表示当前的数据库处于激活状态。紧接着可以对其进行其他相关的命令了。这里我们输入show tables,可以看到test这个数据库的表里面是空的。
所以要开始建表了,于是就涉及到了SQL语句。
SQL全称是:结构化查询语言(Structured Query Language)。既然是语言,就涉及到了语法。下面来看一下常见的语法。
二、数据定义语言(DDL)
数据定义语言:Data Definition Language。如CREATE, DROP,ALTER等语句。需要注意的是,数据库中的命令不区分大小写。
创建数据库(CREATE DATABASE语句):
【举例】新建数据库,命名为mydb:
CREATE DATABASE mydb;
注:如若要删除数据库,将“create”改为“drop”即可。
创建表(CREATE TABLE语句):
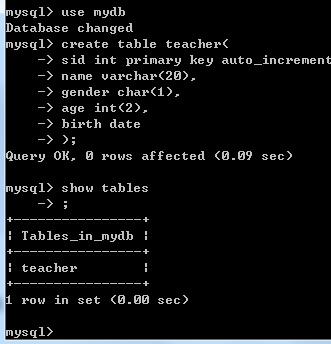
【举例】创建一个名为teacher的表:
CREATE TABLE teacher( id int primary key auto_increment, name varchar(20), gender char(1), age int(2), birth date,
description varchar(100) );
上面所有的代码其实是同一行。
定义字段的格式:字段的名字+字段的类型+属性
注:每个字段定义完后,要用逗号隔开,最后一个字段没有逗号。
一般情况下,每个表都要有一个主键。
命令运行的效果如下:
查看表结构:
desc teacher;
效果如下:
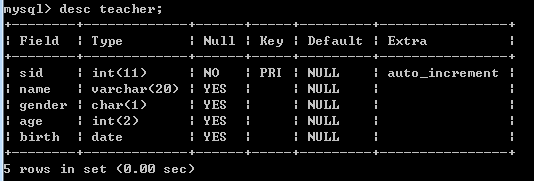
需要注意的是:主键是用来唯一代表一条记录的字段(主键值必须是唯一)
删除表(DROP TABLE语句):
DROP TABLE teacher;
注:drop table 语句会删除该的所有记录及表结构
修改表结构(ALTER TABLE语句):(假设表名为test)
- alter table test add column job varchar(10); --添加表列
- alter table test rename test1; --修改表名
- alter table test drop column name; --删除表列
- alter table test modify address char(10) --修改表列类型(改类型)
- alter table test change address address1 char(40) --修改表列类型(改名字和类型,和下面的一行效果一样)
- alter table test change column address address1 varchar(30)--修改表列名(改名字和类型)
举例:将主键修改为自动增长:alter table tab_teacher change id id int auto_increment;
三、数据操纵语言(DML):
数据操纵语言:Data Manipulation Language。如:INSERT(增), UPDATE(改), DELETE(删)语句
添加数据(INSERT INTO…语句):(即添加表的记录)
INSERT INTO 表名(字段1,字段2,字段3) values(值,值,值);
举例:
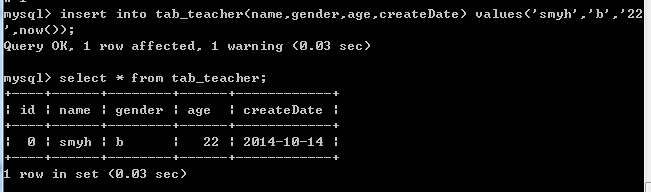
insert into tab_teacher(name,gender,age,createDate) values('smyh','b',22,now());
注:上方的now()函数可以调出当前系统的时间。
然后通过如下命令进行查询表的所有记录:
select * from tab_teacher;
其中,通配符“*”表示所有字段,即从tab_teacher这个表中查所有字段的记录。
显示效果如下:
修改数据(UPDATE … SET语句):
UPDATE 表名 SET 字段1名=值,字段2名=值,字段3名=值 where 字段名=值;
注:where后面的部分表示修改的条件。修改时,按照字段1、字段2、字段3的先后顺序修改。
删除数据:(DELETE FROM…语句)
删除所有记录:
DELETE FROM 表名;
删除ID为1的记录:
DELETE FROM 表名 where id=1;
四、数据查询语言(DRL):
数据查询语言(Data Retrieval Language --DRL):SELECT语句。
在实际开发中,数据查询语言用的是最多的。我们现在以下面的这张表格为例:
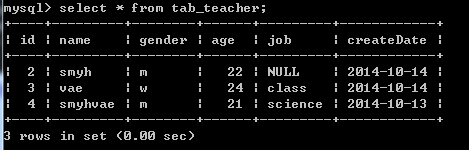
注:实际开发中,要避免使用通配符"*"(通配符代表所有字段),因为系统要先解析出所有的字段名,将其还原为真实的名字,然后再进行操作。如果记录数据库内容特别多,会影响效率。
查询所有老师的信息:
select * from tab_teacher;
或者:(推荐)
select id,name,gender,age,job,createDate from tab_teacher;
在没有表被引用的情况下,允许指定DUAL作为一个假的表名:
DUAL是虚拟表。也就是说,表中没有这个数据,但是要执意使用sql语句,系统就会用这个虚拟表来满足你。举例效果如下:

查询ID为2的老师信息:
select * from tab_teacher where id=2;
查询职业为空的老师信息:
select * from tab_teacher where job is null;
注意,上方代码中,字段为空用“job is null”来表示,而不是“job=null”。
查询ID为2的老师的姓名和性别:
select name,gender from tab_teacher where id=2;
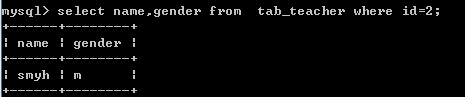
查询性别为女和指定日期的老师信息:
select $ from tab_teacher where gender='w' and ceateDate='2014-10-14';
注:并且用“and”,或用“or”。
查询性别为男或者ID小于2的老师:
select * from tab_teacher where gender='m' or id<2;

查询姓名的最后一个字符为“e”的老师:(关键字:like '%+指定字符')
select * from tab_teacher where name like '%e';
查询姓名以指定字符开头的老师:
select * from tab_teacher where name like 's%';
查询姓名中包含“m”的老师:
select * from tab_teacher where name like '%m%';
查询所有老师信息,并按日期降序或者升序排列:(ORDER BY 字段,+默认为升序:ASC/降序:DESC)
- 升序:
select * from tab_teacher order by createDate;
注:最后一个单词ASC可写可不写,因为默认为升序。
- 降序:
select * from tab_teacher order by createDate desc;
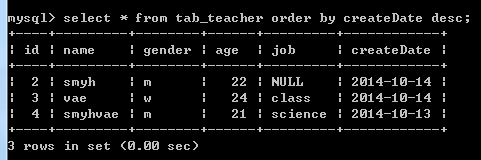
多个排序条件:(当第一个条件相同时,按照第二个条件排序)
例如:上面图片的排序中,是按照日期降序排序的,但是id为2和id为3的日期相同,这两条记录按照默认顺序排序。
举例:现在排序的第一条件为:日期降序,第二条件为:年龄降序。多个排序条件用逗号隔开。命令为:
select * from tab_teacher order by createDate desc,age desc;
按性别分组查询男女老师的人数(GROUP BY ):
select gender,count(gender) from tab_teacher group by gender;
上面的命令表示,查找gender这个字段;并计算gender有多少个(count(gender));然后按照gender里的内容将个数进行分组(group by gender)。
问题:我觉得应该是先分组,再查询性别,再数性别的个数。
注:这里面用到了count()这个内置的函数。关于count()这个聚合函数,将在下一篇文章中讲到。
正确的效果和错误的效果如下:
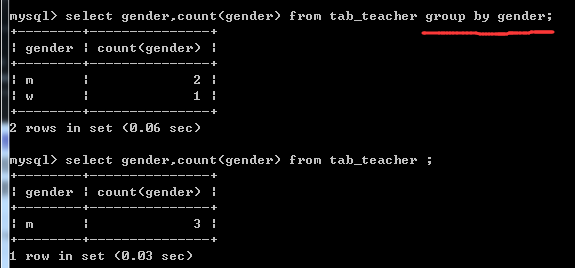
按性别分组,查询出女老师人数的总数:
select gender,count(gender) from tab_teacher group by gender having gender='m';
这里在上一个命令的基础上,增加了一个关键字:having。having关键字专门用来在分组之后添加的条件。意思是:先求总数,然后进行分组,然后再从分组里找到字段等于“m”的个数。注:不能用where作为关键字,因为where是加在分组之前的条件。
显示效果如下:
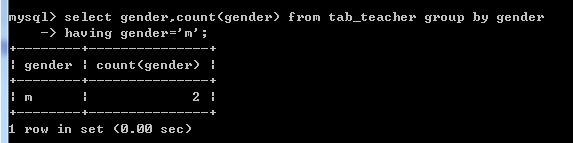
注:这种写法操作繁琐,效率较低,having语句尽量少用,可以用其他语句代替,例如:
select gender,count(gender) from tab_teacher where gender='m';
效果是一样的。
查询表的总记录数:
- 方式一:(不推荐)
select count(*) from tab_teacher;
- 方式二:(使用主键的方式查询)
select count(id) from tab_teacher;
方式一将空记录也包含进来了。所以采用方式二,因为主键唯一,且不能为空,此时id总数则代表总记录数。
别名的用法:
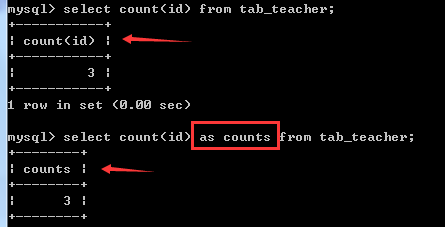
- 使用别名查询表的总记录数:
select count(id) as counts from tab_teacher;
不用别名和用别名的效果对比如下:(命令中的"as"可以省略)
- 使用别名来代替表的名字:
举例:将表的名字起为t。
select t.name,t.age from tab_teacher t;
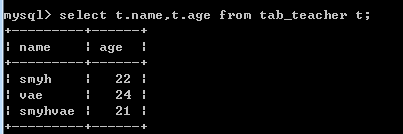
当表名比较长,或者同时有多个表存在时,用别名就显得非常方便了。
查询老师记录的前三条(从0位置开始找出3条):(非常有用)
select * from tab_teacher limit 0,3;
命令解释:limit后面有两个参数:第一个参数是起始位置,第二个参数是偏移量。声明:第一条记录的id不管为多少,索引位置都是0。
注:这种分页查询方式非常有用,例如使用百度搜索时,告诉你总记录数,但是会分页显示。
五、事务控制语言(TCL):
事务控制语言:Transaction Control Language--TCL。如COMMIT,ROLLBACK语句。
1、事务:
事务(Transaction)的概念:事务(Transaction)是访问并可能更新数据库中各种数据项的一个程序执行单元(unit)。在关系数据库中,一个事务可以是一条SQL语句,一组SQL语句或整个程序。
事务的属性:原子性(atomicity)、一致性(consistency)、隔离性(isolation)、持续性(durability)。这四个属性通常称为ACID特性。
事务的特点:事务就是对数据库的多步操作,要么一起成功,要么一起失败。
总结:事务就是可以把多步操作看成一个整体,这个整体要么一起成功,要么一起失败。
2、事务的提交和回滚命令:
设置默认事务提交方式:(默认为true)
- 设置事务提交方式为“手动提交”:
set autocommit = false;
- 设置事务提交方式为“自动提交”:
set autocommit = true;
手动提交事务:
commit;
回滚事务:
rollback;
注:只要还没手动commit提交,一旦回滚,之前的修改操作都将清零。
注:commit命令和rollback命令只有在提交方式为“手动提交”时,才可以用。
3、保存还原点的命令:
当数据未commit之前,增删改查的操作都是暂时保存在内存之中的,当我们修改操作进行到某一步时,可以给这一步设置一个还原点,方便以后回滚到此还原点(类似于PS当中的快照)。
保存还原点:
savepoint name_point;
回滚到指定还原点:
rollback to name_point;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号