

Python笔记——Python基础
前述:
这里就是记录一下自己学习的内容,因为是个小白,所以很多基础的东西也会记录一下,主要还是加深一下自己的印象。
资料来源于廖雪峰老师的官网,还有哔站的教学视频。
数据类型
在Python中,能够直接处理的数据类型有以下几种:整数、浮点数、字符串、布尔值、空值、变量、常量。主要找几个写写
字符串
字符串是以单引号'或双引号"括起来的任意文本,比如'abc',"xyz"等等。
如果字符串内部既包含'又包含"可以用转义字符\来标识,比如:
'I\'m \"OK\"!'表示的字符串内容是:I'm "OK"!
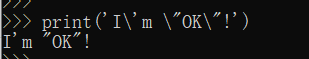
转义字符\可以转义很多字符,比如\n表示换行,\t表示制表符,字符\本身也要转义,所以\\表示的字符就是\

如果字符串内部有很多换行,用\n写在一行里不好阅读,为了简化,Python允许用'''...'''的格式表示多行内容,当输入完结束符'''和括号)后,执行该语句并打印结果。

布尔值
布尔值和布尔代数的表示完全一致,一个布尔值只有True、False两种值,布尔值可以用and、or和not运算。
空值
空值是一个特殊的值,不是0,要用None来表示。
变量
变量不仅可以是数字,还可以是任意数据类型。
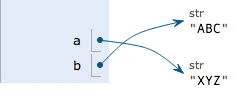
可以把一个变量a赋值给另一个变量b,这个操作实际上是把变量b指向变量a所指向的数据,例如:
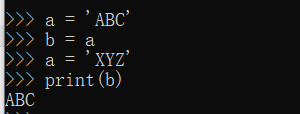
而现在 a 变成了 XYZ

因为执行a = 'ABC',解释器创建了字符串'ABC'和变量a,并把a指向'ABC':
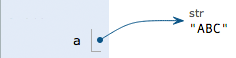
执行b = a,解释器创建了变量b,并把b指向a指向的字符串'ABC':
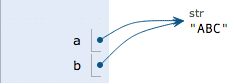
执行a = 'XYZ',解释器创建了字符串'XYZ',并把a的指向改为'XYZ',但b并没有更改:
字符编码
刚说过了字符串也是一种字符类型,但是,字符串比较特殊的是还有一个编码问题。
最早只有127个字符被编码到计算机里,也就是大小写英文字母、数字和一些符号,这个编码表被称为ASCII编码。但是处理中文显然一个字节是不够的,至少需要两个字节,而且还不能和ASCII编码冲突,全世界有上百种语言,在多语言混合的文本中,显示出来会有乱码。为了不发生冲突Unicode应运而生。Unicode把所有语言都统一到一套编码里,这样就不会再有乱码问题了。
ASCII编码和Unicode编码的区别:ASCII编码是1个字节,而Unicode编码通常是2个字节。
如果统一成Unicode编码,乱码问题从此消失了。但是,如果你写的文本基本上全部是英文的话,用Unicode编码比ASCII编码需要多一倍的存储空间,在存储和传输上就十分不划算。
又出现了把Unicode编码转化为“可变长编码”的UTF-8编码。UTF-8编码把一个Unicode字符根据不同的数字大小编码成1-6个字节,常用的英文字母被编码成1个字节,汉字通常是3个字节,只有很生僻的字符才会被编码成4-6个字节。如果你要传输的文本包含大量英文字符,用UTF-8编码就能节省空间。
UTF-8编码有一个额外的好处,就是ASCII编码实际上可以被看成是UTF-8编码的一部分,所以,大量只支持ASCII编码的历史遗留软件可以在UTF-8编码下继续工作。
以上就是这三种编码之间的关系。现在计算机系统通用的字符编码工作方式:
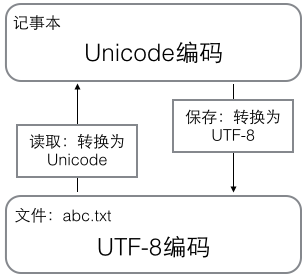
在计算机内存中,统一使用Unicode编码,当需要保存到硬盘或者需要传输的时候,就转换为UTF-8编码。
用记事本编辑的时候,从文件读取的UTF-8字符被转换为Unicode字符到内存里,编辑完成后,保存的时候再把Unicode转换为UTF-8保存到文件:
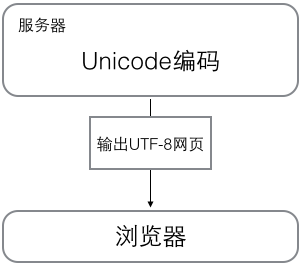
浏览网页的时候,服务器会把动态生成的Unicode内容转换为UTF-8再传输到浏览器:
Python的字符串
在最新的Python 3.x版本中,字符串是以Unicode编码的,也就是说,Python的字符串支持多语言,比如:
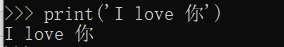
对于单个字符的编码,Python提供了ord()函数获取字符的整数表示,chr()函数把编码转换为对应的字符:

由于Python的字符串类型是str,在内存中以Unicode表示,一个字符对应若干个字节。如果要在网络上传输,或者保存到磁盘上,就需要把str变为以字节为单位的bytes。
Python对bytes类型的数据用带b前缀的单引号或双引号表示:
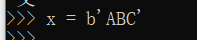
'ABC'和b'ABC',前者是str,后者虽然内容显示得和前者一样,但bytes的每个字符都只占用一个字节。
以Unicode表示的str通过encode()方法可以编码为指定的bytes,

要计算str包含多少个字符,可以用len()函数:

可见,1个中文字符经过UTF-8编码后通常会占用3个字节,而1个英文字符只占用1个字节。
在操作字符串时,我们经常遇到str和bytes的互相转换。为了避免乱码问题,应当始终坚持使用UTF-8编码对str和bytes进行转换。
格式化:
在Python中,采用的格式化方式和C语言是一致的,用%实现,例如:

常见的占位符:
%d——整数
%f——浮点数
%s——字符串
%x——十六进制整数
用%%来表示一个%
其中,格式化整数和浮点数还可以指定是否补0和整数与小数的位数:
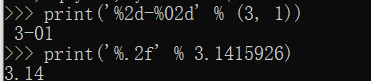
注意:如果你想不起来用什么了%s永远起作用,它会把任何数据类型转换为字符串。
format()
另一种格式化字符串的方法是使用字符串的format()方法,它会用传入的参数依次替换字符串内的占位符,不过要麻烦很多:

list和tuple
list
Python内置的一种数据类型是列表:list。list是一种有序的集合,可以随时添加和删除其中的元素。
比如,列举一个班级里的名字:

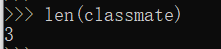
变量classmates就是一个list。用len()函数可以获得list元素的个数:
用索引来访问list中每一个位置的元素,记得索引是从0开始的,当索引超出了范围时,Python会报一个错误。

如果要取最后一个元素,除了计算索引位置外,还可以用-1做索引,直接获取最后一个元素,依此类推,-2,-3等等

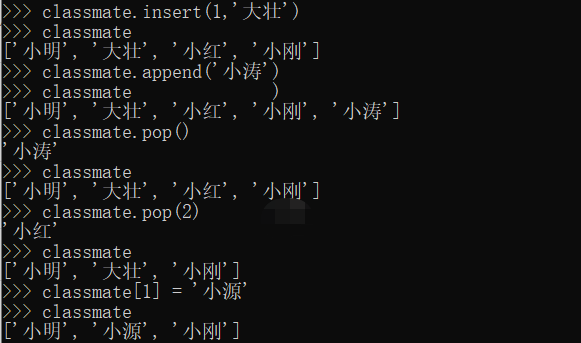
把元素插入到指定的位置,比如索引号为1的位置;可以往list中追加元素到末尾;要删除list末尾的元素,用pop()方法;要删除指定位置的元素,用pop(i)方法,其中i是索引位置; 要把某个元素替换成别的元素,可以直接赋值给对应的索引位置
list元素也可以是另一个list,可以看成是一个二维数组:
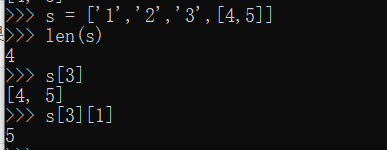
tuple
另一种有序列表叫元组:tuple。tuple和list非常类似,但是tuple一旦初始化就不能修改,比如:

如果要定义一个空的tuple,可以写成(),要定义一个只有1个元素的tuple,不能写 t = (1),因为定义的不是tuple,是1这个数,要加个逗号消除歧义
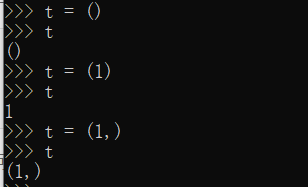
还可以这么写。。tuple变成“可变的”了。。

表面上看,tuple的元素确实变了,但其实变的不是tuple的元素,而是list的元素。
条件判断
在Python程序中,用if语句实现。
根据Python的缩进规则,如果if语句判断是True,就把缩进的两行print语句执行了,否则,什么也不做。
也可以给if添加一个else语句,意思是,如果if判断是False,不要执行if的内容,去把else执行了。
可以用elif做更细致的判断。elif是else if的缩写,可以有多个elif。
if <条件判断1>: <执行1> elif <条件判断2>: <执行2> elif <条件判断3>: <执行3> else: <执行4>
注意:不要少写了冒号 :
if语句执行是从上往下判断了,如果在某个地方判断正确就不会再往下判断了。
结合前面的东西做了个练习:
小明身高1.75,体重80.5kg。请根据BMI公式(体重除以身高的平方)帮小明计算他的BMI指数,并根据BMI指数: 低于18.5:过轻 18.5-25:正常 25-28:过重 28-32:肥胖 高于32:严重肥胖
答案:
name = input('请输入你的名字:') height = input('请输入你的身高(m):') weight = input('请输入你的体重(kg):') h = float(height) w = float(weight) bmi = (float(w/(h*h))) if bmi > 32.0: print('严重肥胖') elif bmi >= 28.0: print('肥胖') elif bmi >= 25.0: print('过重') elif bmi >= 18.5: print('正常') else: print('过轻')
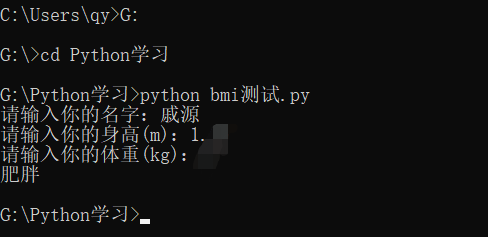
身高体重就不给出来,哎,肥胖,难受哎。。。。。
循环
为了让计算机能计算成千上万次的重复运算,我们就需要循环语句。所以for x in ...循环就是把每个元素代入变量x,然后执行缩进块的语句。比如:
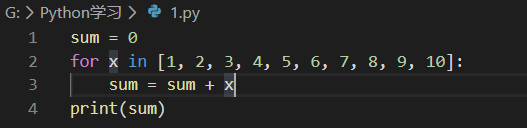

Python提供一个range()函数,可以生成一个整数序列,再通过list()函数可以转换为list。比如range(101)生成的序列是从0开始小于101的整数,即0-100:
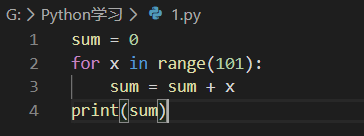
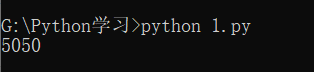
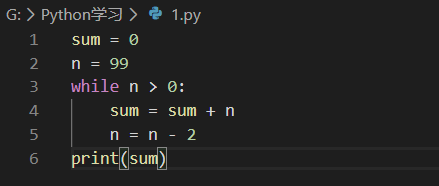
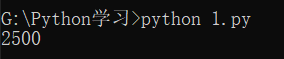
第二种循环是while循环,只要条件满足,就不断循环,条件不满足时退出循环。比如我们要计算100以内所有奇数之和,可以用while循环实现:
在循环内部变量n不断自减,直到变为-1时,不再满足while条件,循环退出。
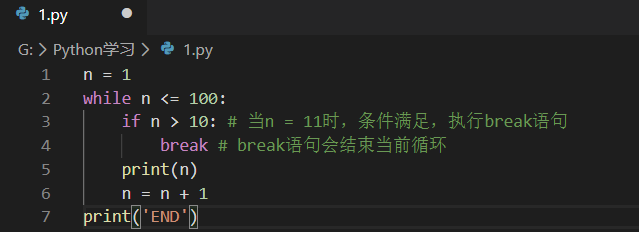
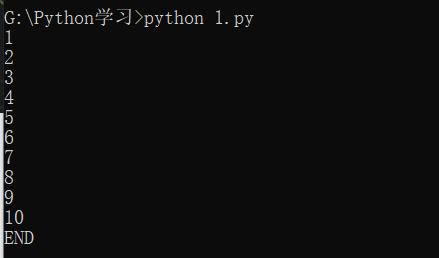
break
在循环中,break语句可以提前退出循环。
我们让它打印出1~10后,紧接着打印END,程序结束。
continue
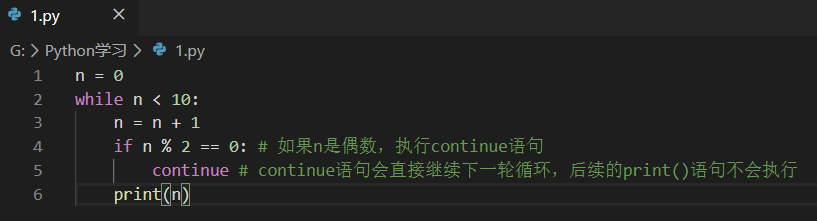
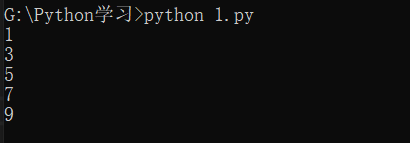
在循环过程中,也可以通过continue语句,跳过当前的这次循环,直接开始下一次循环。
在0-10中,只打印奇数,可以用continue语句跳过某些循环:
一个小测试:
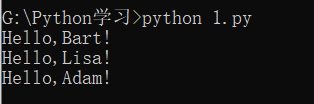
请利用循环依次对list中的每个名字打印出Hello, xxx!:
names = ['Bart', 'Lisa', 'Adam']
答案:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号