Pandas:apply方法与lambda、groupby结合、apply多参数传递
Pandas的apply函数用起来很方便,特别是与groupby、lambda结合使用时更简便。
1. 首先创建DataFrame数据:
import pandas as pd import numpy as np df = pd.DataFrame({'name':['Jack','Alex','Bob','Nancy','Mary','Alice','Jerry','Wolf'], 'course':['Chinese','Math','Math','Chinese','Math','English','Chinese','English'], 'grade':[1,1,2,2,2,2,3,3], 'score':[85,95,91,78,89,60,87,79]})
2. 单独使用lambda:
vv = df.apply(lambda x:x['score'],axis=1) #axis用于指定每次传入的是行数据 print('vv:',vv)

3. 进行groupby分组聚合:
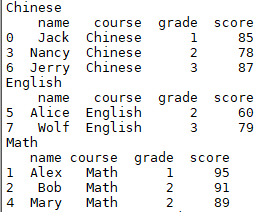
group_data = df.groupby('course') #groupby分组方法 for course,group in group_data: print(course) print(group)
4. 结合apply和lambda函数:
# apply方法也可用在Series上 # 对结果应用apply方法,则会对每一组执行describe() ss = group_data.apply(lambda x:x.describe()) #相当于执行function print(ss)

5. 对组合块结果进行操作运算:lambda(分别每个块)
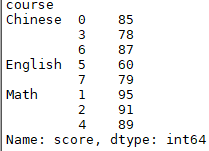
# 对组合块结果进行操作运算 tt = group_data.apply(lambda y:np.mean(y['score'])) print(tt)

6. 可使用自定义函数
def test_apply(x, column='score'): return x[column] uu = group_data.apply(test_apply) print(uu)
7. 当自定义函数是多参数,且无默认值时,有三种方法传递参数,df 数据来自上面 ~~
i = 0 def test_apply(x,column,mean_v): global i print(i+1) print(mean_v) i = i+1 return x[column] print('fffffff') # 方法一,关键字传递 # axis=1,表示对每行apply作用; uu = df.apply(test_apply,axis=1,column='score',mean_v=100) # axis=0 default,表示对每列apply作用; print('uu:',uu) print('sssssss') # 方法二,参数收集之元组传递 uu = df.apply(test_apply,axis=1,args=('score',100)) print('uu:',uu) print('tttttttt') # 方法三,参数收集之字典收集 dict_ = {'column':'score','mean_v':100} uu = df.apply(test_apply,axis=1,**dict_) #也可以直接:**{'column':'score', 'mean_v':100} print('uu:',uu)

参考:
https://www.cnblogs.com/happymeng/p/11056437.html


 浙公网安备 33010602011771号
浙公网安备 33010602011771号