
《性能之巅:洞悉系统、企业与云计算》笔记——方法论
2025-08-07 16:17 第二个卿老师 阅读(59) 评论(0) 收藏 举报《性能之巅:洞悉系统、企业与云计算》笔记——方法论
作者: Brendan Gregg 第一版
🧠 前言综述
这本书2022年买来的,因为比较深入底层,也就简单看看就放下了,最近有时间又拿了起来,这里记录下自己的笔记
第一章 · 绪论(Introduction)
- 测试范围: 系统性能研究整个系统中所有的硬件组件和软件栈,牵涉到多个团队角色
- 介入时机: 建议在硬件选型与软件开发之前就介入
- 分析视角: 包括负载分析与资源分析两种
- 性能挑战三要素: 主观性、复杂性、多因素叠加性,强调整体分析而非局部优化。
- “已知的已知 / 已知的未知 / 未知的未知”理念: 认识到很多性能瓶颈来源于系统边界之外的变量
第二章 · 方法论(Methodology)
-
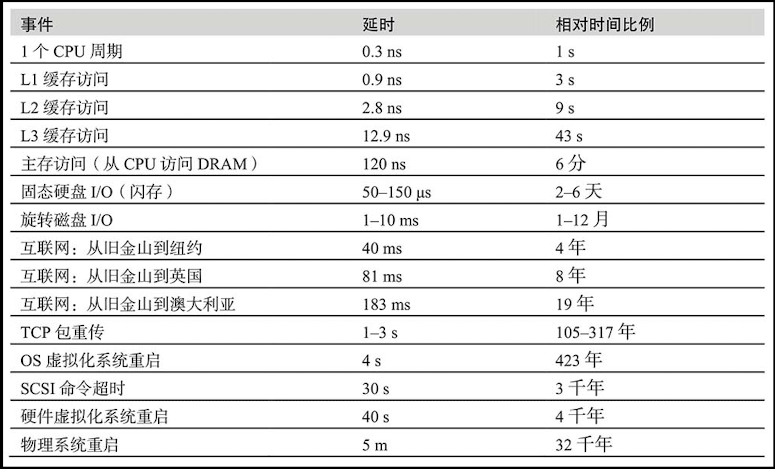
常见概念
- 时间量级
![image]()
- 权衡三角:好,快,便宜
- 在靠近工作执行的地方进行性能优化,效果最明显
- 系统环境改变可能导致性能优化无效
- 系统的性能瓶颈来源于架构或者负载
- 性能在负载持续增加时会出现非线性变化
- 时间量级
-
性能指标:
- IOPS(每秒的I/O操作数)、延时(Latency)、吞吐量(Throughput,每秒数据量会操作量)、使用率(Utilization)、饱和度(Saturation)
- 使用率:若基于时间(所给定时间区间内资源的繁忙程度),若基于容量(所消耗的容量比例)
- 饱和度:指的是某一资源无法满足服务的排队工作量
- 命中率:针对缓存的指标,特别注意缓存的热、冷、温状态
- 资源分析指标 :侧重系统资源瓶颈,如IOPS、吞吐量、使用率、饱和度
- 负载分析:聚焦用户行为施压,如吞吐量、延时、错误率
-
警示方法:
- 街灯效应(只看熟悉的工具),盲调(随机改参),甩锅(追责他人),工具法(效率低)
-
推荐方法
- Ad Hoc核对清单法: 针对系统组件性能状态的清单,进行核查
- 问题陈述法: 初步应对问题时,需要了解的问题背景
- 科学法: 步骤为:问题 > 假设 > 预测 > 试验 > 分析,未解决问题再重复新假设
- 诊断循环法: 类似于科学法,步骤为:假设 > 仪器检验 > 数据 > 假设,通过收集数据来验证假设
- USE 方法:
- 凡遇问题,遍历每个系统资源,检查 使用率(Utilization)、饱和度(Saturation )和 错误(Errors),是诊断效率很高的切入方法
- 首先列出资源列表:CPU(插槽、核、硬件线程),内存(DRAM),网络接口(以太网端口),存储设备(磁盘),控制器(存储、网络),互联(CPU、内存、I/O)
- 接着获取每个资源的三个指标,优先测量CPU饱和度、内存容量饱和度、网络接口使用率、磁盘使用率
- 针对软件资源,测量互斥锁、线程池、进程/线程容量、文件描述符容量
- 工作负载特征归纳法: 通过归纳负载的特征,一是避免不必要的工作,二是辨识负载问题,与架构问题分开,考虑是否可以通过资源限制等方式解决
- 向下挖掘分析法: 通过高层级监测,向下缩小研究范围,再做进一步检查,可使用5个why方法技巧
- 延时分析法: 检查完成一项操作所用的时间,划分时间段,然后找到最大时间段进行分析,最后定位问题的根本原因
- R方法: Oracle数据库开发的性能分析方法,意在找到延时的根源
- 事件跟踪: 跟踪系统的操作事件并检查,可发现延时离群值
- 基础线统计法: 把当前的性能指标与之前的数值做比较
- 静态性能调整法: 处理架构配置的问题,对系统的所有组件逐一检查正确性
- 缓存调优法: 检查缓存设计的正确性、是否工作正常、缓存大小是否正确等方面
- 微基准测试法: 施加简单的人造工作负载进行测试,如系统调用、文件系统读取、网络吞吐量
-
建模: 性能评估三大方法:生产系统的观测(测量)、实验性测试(仿真)、分析建模
- 现有系统分析:归纳负载特征和测量性能
- 无生产环境负载或生产环境不可见:工作负载仿真
- 分析建模基于测试和仿真的结果,用于性能预测
- 建模方式:可视化识别、Amdahl定律、通用扩展定律、排队理论(Kendall标记法)
-
容量规划: 根据负载增加来规划并扩展系统的方法,包括研究资源极限和因素分析
- 资源极限:通过施加负载,监视软硬件资源的使用率,然后再根据100%使用率来反向推算
- 硬件资源: CPU使用率、内存使用、磁盘IOPS、磁盘吞吐量 、磁盘容量(使用率)、网络吞吐量
- 软件资源:虚拟内存使用情况、进程/任务/线程、文件描述符
- 因素分析:通过组合测试组件配置,计算出用最小的成本来实现想要的性能
- 推荐步骤:先测试所有因数配置最高的性能;再逐一改变因素,测试性能;然后统计测量的结果;接着将最高的性能(和成本)作为起始点,在满足性能目标下计算节省成本的因素;最后重新测试来验证改变后的配置
- 其他扩展:云计算中水平扩展,如数据库的扩展策略为分片
- 资源极限:通过施加负载,监视软硬件资源的使用率,然后再根据100%使用率来反向推算
-
统计: 用统计的方法来量化性能,量化是需要直观的描述性能收益
- 平均值:度量的是数据集中的趋势,包括算术平均值、几何平均值、调和平均值、时间变化的平均值、衰退平均值
- 标准方差:度量的是数据离散程度,数值越大表示数据偏离均值的程度越大
- 其他:百分位数、中位数、变异系数、多模态分布(比如读/写)、异常值
-
监视: 通过监视线上一段时间的性能统计数据,可找出负载规律
-
可视化: 通过数据可视化来检查数据,包括线图、散点图、热图、表面图、其他定制化工具
📌 总结感悟
在第一次看完前两章,充斥各种概念与方法,有点毫无头绪,可能聚焦的对象更偏向于系统的下层组件。第二次看后结合自己的性能工程经验,大概总结了以下方面
性能测试对象分层
- 我理解性能测试对象由高层级到低层级分为:产品层、应用组件层、操作系统层、硬件层
- 那么对应的人员角色分为软件性能工程师、应用性能工程师、系统性能工程师、硬件性能工程师
- 国内性能测试工作主要在产品层,并随着层级的深入,专业的人员(或者所做的性能工作)依次减少
性能工程的流程
-
需求分析阶段
- 关于性能目标
- 首先性能目标是根据业务目标转化来的,业务目标可能来源于市场、运营、产品
- 业务目标可通过建模来转化成TPS,注意TPS是产品层的性能指标
- 可通过产品层的TPS指标来转化下层的指标,包括应用组件层、操作系统层、硬件层
- 作者提出性能分析有资源分析、工作负载分析两种视角,那么建议产品层采用工作负载分析,而其他层采用资源分析,即实践中TPS、响应时间、错误率作为业务指标可以对外,IOPS、吞吐量、使用率、饱和度作为技术指标主要对内
- 关于性能模型
- 我们知道性能模型包括业务模型和环境模型,其中业务模型包括用户行为模型、用户分布模型、流量转化模型,而环境模型应该包含硬件模型和软件模型
- 由于云计算与容器化的流行,云产商隐藏了硬件模型,所以我们很难深入
- 另外在产品层下进行测试,模拟的工作负载简化了业务模型
- 关于性能目标
-
测试准备阶段
- 作者没有单独提到这一阶段,我整理后有如下注意点
- 关于缓存:测试前需要注意热、冷、温状态
- 关于负载模拟:需要考虑负载的特征,以免导致结果数据的多重模态分布,简单来讲就是要考虑性能场景数据的正确性(读/写的性能差异大)
- 作者没有单独提到这一阶段,我整理后有如下注意点
-
测试执行阶段
- 作者提到使用可视化进行数据检查,目前基本已经实现,包括监控对象的可视化、监控结果的可视化
- 作者提到了剖析,不光操作系统层的剖析工具很多、产品层也有非常成熟的链路追踪工具了(如Skywalking、Pinpoint)
-
结论报告阶段
- 关于量化性能
- 目前性能结论是需要量化的,高楼老师还建议用图表的方式来直观显示性能收益
- 关于指标数据
- 平均值、标准方差、百分位数、中位数都是目前业界实践的标准了,另外不要漏掉异常值
- 关于量化性能
性能分析的方法论
上面作者给出了很多方法,这里再根据经验说下:
- Ad Hoc核对清单法:我理解就是一种checklist清单,类似业务测试中的上线检查清单,这种可以作为一个自动化的检查项目,特别是在目前AI加持下
- 问题陈述法:这个算是被动分析,列举问题相关背景,业务测试上我们之前已形成问题反馈的规范
- 科学法/诊断循环法:这是分析并解决问题的基础方法,效果取决于用户的经验
- 工具法:大概意思是新手直接上手工具看指标,即提倡先进行问题分析、再选择合适的工具
- USE法:作者创建的方法,统计并排查系统资源的状况,目前搭建性能监控平台,应该是借鉴了这个思路,非常高效,唯一的问题在于统计指标是否够全面
- 工作负载特征归纳法:这个也算被动分析,通过分析负载来源来定位问题,并给出对应解决方案,比较高效
- 向下挖掘分析/延时分析法:这两个方法思路是差不多,都是刨根问底,只是前者按照原因分析,后者的按照时间拆分(和高楼老师说的拆分响应时间是一致的),算是瓶颈分析的灵丹妙药
- R方法:对延时根源的分析,我理解和向下挖掘分析类似
- 事件跟踪法:我理解主要用于错误值/离群值的分析,技术要求与成本偏高,算是兜底的方法了
- 基础线统计法:应该也叫性能基线,目前作为了性能测试常态化的一个标志
- 静态性能调整法:对整个系统架构中的组件进行配置分析,这个类似于Ad Hoc清单,也应该被自动化
- 缓存调优法:针对当前系统各组件的缓存进行调优,算是性能优化的补充方案
- 微基准测试法:主要针对操作系统层、硬件层的测试方法,当然基准场景测试也套用了这个概念,不过是面向产品层的
- 容量规划法:这个方法用于未来系统的性能规划,通过资源极限+水平扩展进行容量规划,而其中因素分析用得较少,可能更偏向一些自建设备的硬件公司
方法论分类
| 适用场景 | 方法 |
|---|---|
| 性能测试手段 | 微基准测试法 / 基础线统计法 |
| 性能瓶颈分析(主动分析) | 科学法 / 诊断循环法 / 向下挖掘分析法 / 延时分析法 / R方法 |
| 线上问题定位(被动分析) | 问题陈述法 / 工作负载特征归纳法 |
| 缺陷预防 | Ad Hoc核对清单法 / 静态性能调整法 |
| 容量规划 | 容量规划法 |
| 性能监控 | USE方法 / 事件跟踪法 |
| 性能调优 | 缓存调优法 |
另外的建议
- 不要做无效的性能优化,比如版本迭代导致优化无效
- 性能优化要在靠近工作执行的地方效果更明显
- 性能根据公司业务不同,投入的地方也不同,需要考虑投资回报比

 浙公网安备 33010602011771号
浙公网安备 33010602011771号