

微信小程序性能测试之jmeter踩坑记录(一)
2020-06-11 21:51 第二个卿老师 阅读(8448) 评论(8) 收藏 举报接上篇,简单说说性能测试关注的性能指标,高手请飘过。。。
一,响应时间
可大致划分为呈现时间和服务端响应时间,真正用户感受到的响应时间是这两者之和,呈现时间:前端构成页面所需的时间(前端响应时间),服务端响应时间:前端从请求发出开始到客户端收到响应所消耗的时间(服务器端响应时间)。
二,并发用户
从业务角度来看:指的是同一时间段内访问系统的用户数量,从服务端承受的压力出发:指得是同时向客服端发出请求的客户,体现的的是服务端承受的最大并发访问数。
三,吞吐率
吞吐率直接体现软件系统的性能承载能力,指:单位时间内系统处理的客户请求的数量,一般来说,吞吐率用请求数/秒或页面数/秒来衡量,许多性能测试工具生成的报告都会有。
注:吞吐量是指在一次性能测试过程中网络上传输的数据量的总和,吞吐率=吞吐量/总时间(秒)
四,事务成功率/错误率
事务成功率和错误率,也存在于部分性能测试工具中,这个很好理解,指成功的事务或错误的事务与总事务的比,事务就是用户进行的一个业务操作,取决于业务场景,可以自定义,一个事务中可能包含一个或多个请求。
五,思考时间
也称为休眠时间,从业务的角度来说,该时间指:用户在进行业务操作时,每个操作的间隔时间,也可以说每个请求之间的间隔时间,一般在测试脚本中体现。
六,系统资源
也许叫性能计数器更为合适,指:描述服务器或操作系统性能的一些数据指标。为了方便比较,引出了资源利用率:资源的实际使用/总的资源可用量,如在某某情况下,服务器的CPU占用率68%,内存占用率为55%等等,其中68%和55%就是资源利用率的数值。
理解上面这些,就可以深入理解用户的实际需求了。
开始踩坑------------------------------------
当时我们最先接到的需求是元旦跨年的那天晚上,准备搞推广活动,到时人数可能几十万的访问量,运营要我们这边测试下,要求程序不能崩溃(原始需求)。
可能处于需求不稳定期,老大也没在意,先叫我们准备哈,因为这个小程序项目之前是外包的,平时流量不会很高,后端只有1个负责,测试也就我有点经验,于是我们两个就撸起袖子开搞了(也可以说两个半灌水,照葫芦画瓢)
测试分析
1,因为是扫码登录,所以首当其冲的是登录接口,所以登录接口的并发量最大,而下单的转化率低,下单的接口的并发量较低,但业务比较重要。
2,暂定对这两个业务进行压测
3,由于访问并发量不好估算,所以先对服务器目前的性能做个评估
4,业务模型分析,据了解推广活动99%用户都是新用户,线上用户行为分析:100个用户使用,下单率约25%
5,以可忍受的时间为3秒之内,来寻找最大并发用户数
测试计划
1,编写计划文档,并估计排期(包括需求调研、测试方案、环境部署、脚本设计与执行、调优及报告等)
2,搭建测试环境,这里是提前申请的阿里云ecs(深刻体会到一分一秒就是钱)
3,整理接口文档(之前是外包的接口文档,现在是仅供参考,尴尬)
4,测试工具的选择(Jmeter和Nmon监控,阿里云服务器其实自带监控)
测试设计
1, 脚本接口设计
主要进行接口设计,如果接口文档可用,就不用抓包录制这些了,Jmeter的录制真心不好用,如果接口不多,还是直接填快一些,这里目的是把登录和下单接口调通。(如果接口存在签名验证,防篡改机制这些,可能需要花费点时间,为了应付我们接口的延签规则,还花了很多时间写了个生成签名的jar包,Jmeter扩展使用,如果时间不够,可以让后端把这些验证代码关了)
2,脚本数据设计
接口调通后,需要对接口参数进行参数化分析,尽量模拟真实场景,比如登录的用户名密码之类的,而微信小程序比较特殊,你要获取部分用户信息,需要有openid和unionid唯一标识,登录流程如下(同一个用户,在你的多个应用中,openid可能都不相同;但是,unionid一定会相同的,参考来自 https://www.jianshu.com/p/865f0679ba52)

真实场景:用户微信登录时,服务器会获取登录凭证(code)然后去请求微信,再把得到的openid返回给小程序,小程序使用该openid获取用户信息,并发送给服务保存,即完成了用户的登录注册,而后面用户下单也需要该openid。
模拟场景:首先我们不可能模拟微信登录的,所以我们这样设计,先给服务器一个假的登录凭证(code)(可以写死或者参数化都可以),然后服务器使用该code去微信申请openid,这里肯定会失败,需要开发配合改下代码,失败也返回openid(这里最好随机生成),然后小程序使用该openid再加上用户信息(用户信息最好参数化)发送给服务器保存,即模拟了用户的登录注册,Jmeter工具需要关联该openid,以便后面用户下单使用到。
注:模拟场景的原则是与真实场景一致,不能达到一致时,也尽量别修改原来的代码逻辑。这里也考虑过不请求微信接口,代码直接随机休眠多少时间,但由于请求微信接口的响应时间很快,而代码随机生成openid也快,就采用此简单方案,当然更严格的也可以自己写个类似微信接口返回openid等等,大家如果有更好的设计方案欢迎交流!
3,测试场景设计
上两步基本完成了脚本设计,即多个用户依次登录下单是没有问题的(Jmeter理解为单线程),可能包含参数化,断言,关联,自定义函数等技术(是不是和LoadRunner很像),其他等待时间,集合点,吞吐量控制器跟测试场景有关,可根据具体情况自行选择。主要分三个场景:
基准测试场景:该场景的主要目的是获取单个交易在无压力的情况下的基准响应时间及环境资源使用情况,作为其他场景的参考依据。
例子:一般使用一个用户或一个线程,延时设置为0,对一个交易持续运行10分钟以上,类似下图
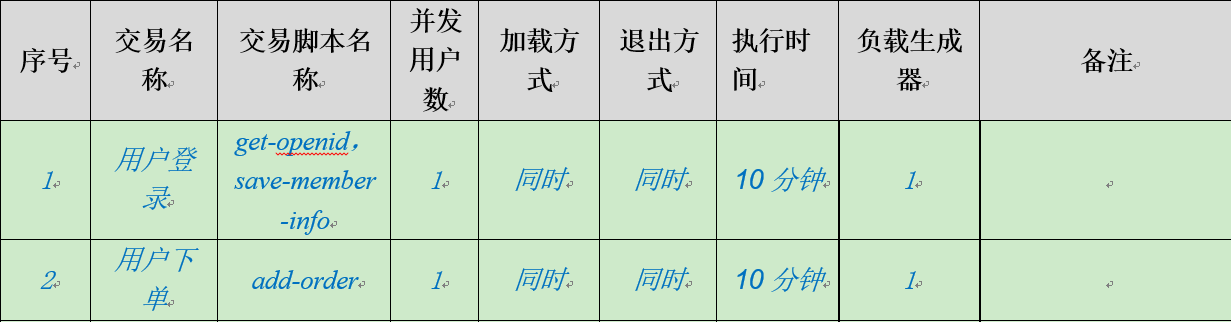
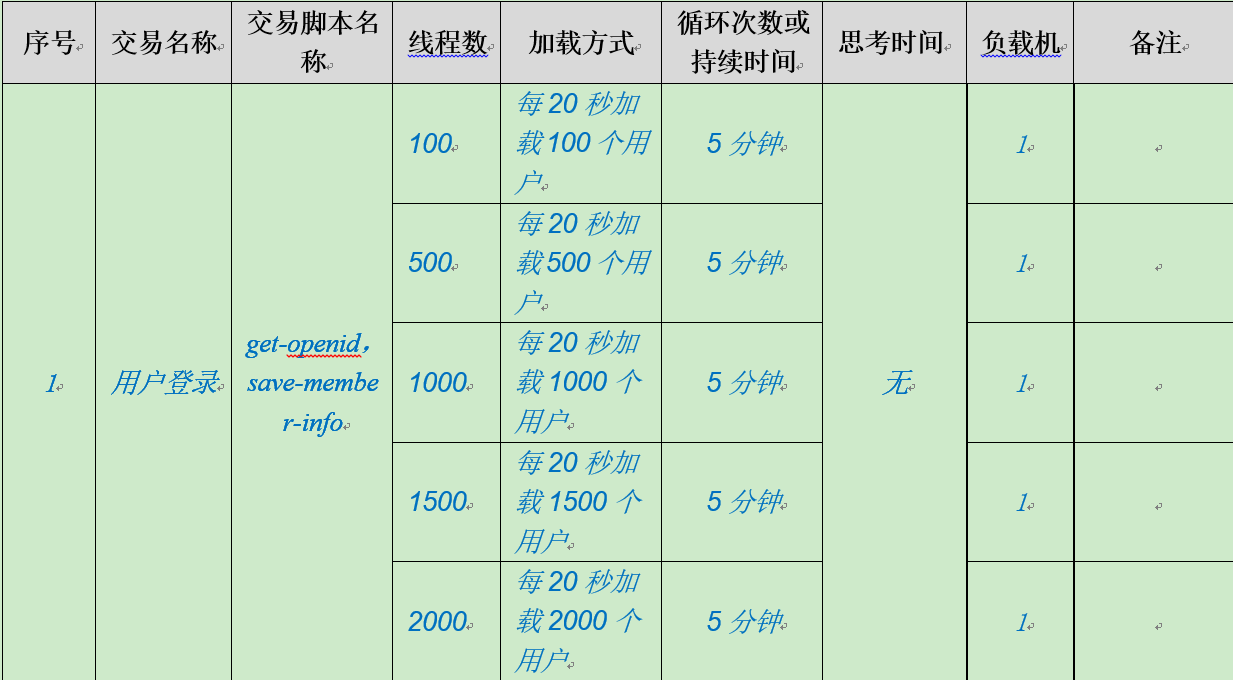
单交易测试场景:单交易负载的场景是为了找到单个交易的最优TPS,检测单交易在并发情况下是否存在性能瓶颈。
例子:分阶段依次提高并发用户或线程数,对一个交易持续运行5分钟以上,这里退出方式没有标明,一般与加载方式一致,类似下图
混合交易测试场景:多交易混合负载的目的为了找到应用的最优TPS,一般指应用CPU资源消耗在70%左右时的TPS(此时需确保数据库等其他被调用资源不成为瓶颈),此场景比较复杂,一般依据日常的业务流程占比与业务操作占比(基于线上日志和产品运营分析)。
例子:由于推广活动主要为老用户,且业务单一,业务流程这里主要分老用户与新用户流程(区别是新用户会新增地址流程),业务操作占比:登录55%,下单25%,那么场景类似如下
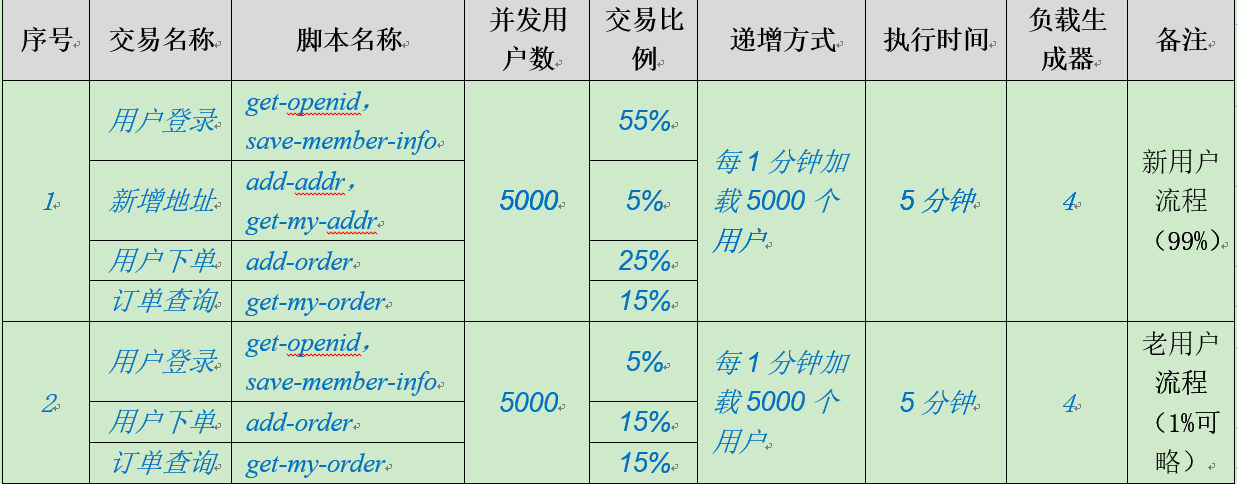
注:这三个场景主要体现的负载测试,其他容量测试(也叫压力测试),稳定性测试等可在此场景基础上延伸,部分参考:https://blog.csdn.net/chenqiuge1984/article/details/80129298。
测试执行与分析
1,执行前准备
确认测试数据已经准备好,已执行过测试后记得还原数据,这里使用的业务数据量跟线上保持一致;
确认脚本已经通过了调试,最好使参数化的数据都走过一遍,避免出现一些数据错误;
确认测试工具配置正确,禁用一些不必要的元件,比如Jmeter的聚合报告等等(Jmeter官方鼓励非GUI方式运行);
确认web等服务器已经“热身"(可能服务器需要初始化一些东西);
确认性能监控工具可用,可能需要提前上传服务器,并设置好采集时间,阿里云的ecs自带资源监控。
2,执行场景
按照设计的场景分阶段依次执行,如果存在多个负载机分布式加压,需要关注各负载机节点的执行情况
执行工具时,最好负载机和服务器都不要运行其他软件,避免干扰,还要关注下负载机的资源使用情况
注:Jmeter没有loadrunner的IP欺骗功能,即同一台负载机发送的请求,IP地址是一样的,如果服务器做了防刷机制,记得屏蔽掉
3,结果收集与分析
每次执行完毕后保存相应的执行结果与监控数据,并及时分析测试结果,以指导下一次场景设计。
如何分析测试结果?
其实Jmeter的聚合报告已经很明确告诉了吞吐量,响应时间等等,类似下图
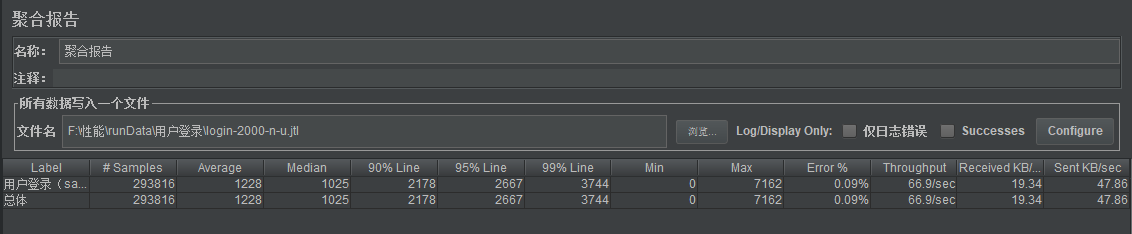
其中Samples指的是发出的取样器请求数,Average是平均响应时间,Error是失败的请求数占比,Throughput(这里指的是吞吐率)是指的每秒服务器处理的请求数,即一个用户(等同Jmeter的一个线程)进行登录业务,如果仅发送一个请求,那么该Throughput就是服务器能支持的每秒并发用户数,如果该业务是发送两个请求,那并发用户数减半。
且最大并发用户数 = 每秒并发用户数 x 用户可忍受时间 /单次业务的请求个数,按照上图吞吐率66.9的QPS,最大并发用户数= 66.9 x 3 /1 = 200.7个用户,参考:https://www.cnblogs.com/jackei/archive/2006/11/20/565527.html。
如何找到最大的并发用户数?我分了以下几步(后面才发现Jmeter有个阶梯型压测插件,可以更快的找到系统的吞吐率)。
第一,聚合报告中Error数据得为0,即不能存在失败请求。
例:可能设计的并发用户增量数据不合适,比如100的线程数,服务器响应正常,然后500的线程数,服务器就开始报错了。
解决:我们不能接受报错,就需要根据实际情况,一要么减少线程数;二要么调整服务器配置,使请求都能成功
第二,服务器报错的类型有很多,具体场景具体分析,这里的目标是配合开发使服务器配置或代码调整为最优。
例:一般常见的是请求连接超时,基本都是请求太多,服务器处理不过来了。
解决:查看服务器资源使用情况,如果CPU、内存占用不高,那么需要配合开发调整配置或代码,最终使同一测试场景下,报错数最低。
第三,上两步走下来,基本达到了最优配置,如果没有Error数,可以逐步增大线程数,如果存在Error数,就逐步减少线程数
例:如果出现没有Error数,但随着线程数增加,Throughput只是缓慢增加,甚至反而减少的情况
解决:那么恭喜你,基本上最大的吞吐率就在这附近了,在最大Throughput和Throughput开始减少的线程数区间内逐步细分,找一个最好看的数字就是了,而最大并发用户数 = Throughput / 用户单个业务的请求数
注:你是不是有多问号!比如吞吐率跟线程数呈什么线性关系?网上说的吞吐量是啥?不设置集合点么?不用定义事务?多个业务怎么设计比例?等等问题,我们后面讨论。
测试总结
虽然使用了这个笨办法找到了最大并发用户数(耗时耗力,又乐于其中),也算有个结论了,贴上测试过程与测试数据,做个测试报告就可以交差了,看起来做了很多工作,其实只是性能测试的冰山一角而已。。。而我自己摸索踩坑的日子也到此结束了
---------------------------------------------------------------------------------------未完待续-------------------------------------------------------------------------------

 浙公网安备 33010602011771号
浙公网安备 33010602011771号