Hystrix
Hystrix
本文主要是Hystrix官方文档的翻译, 官方文档地址:
https://github.com/Netflix/Hystrix/wiki
什么是 Hystrix?
在分布式环境中,不可避免地会遇到(调用链路中)所依赖的服务挂掉的情况,而这种在分布式系统之中容易引起服务调用不可用的雪崩效应。
Hystrix 可以通过增加 延迟容忍度 与 错误容忍度,来控制这些分布式系统的交互。Hystrix 在服务与服务之间建立了一个中间层,防止服务之间出现故障,并提供了失败时的 fallback 策略,来增加你系统的整体可靠性和弹性。
注:Hystrix统计了两个指标延迟和错误。
Hystrix 做了那些事情?
Hystrix 提供了以下服务
- 引入第三方的 client 类库,通过延迟与失败的检测,来保护服务与服务之间的调用(网络间调用最为典型)
- 阻止复杂的分布式系统中出现级联故障
- 快速失败与快速恢复机制
- 提供兜底方案(fallback)并在适当的时机优雅降级
- 提供实时监控、报警与操作控制
Hystrix 解决了什么问题?
在复杂的分布式架构中,服务之间都是相互依赖的,任何一个节点都不可避免会宕机。如果主节点不能从这些宕机节点中独立出来,那主节点将会面临被这些宕机的节点拖垮的风险。举个例子,如果一个应用依赖了 30 个服务,每个服务保证 99.99% 的时间是正常的,那可以计算出:
99.99^30 = 99.7% uptime
0.3% of 1 billion requests = 3,000,000 failures
2+ hours downtime/month even if all dependencies have excellent uptim
实际情况往往更糟糕
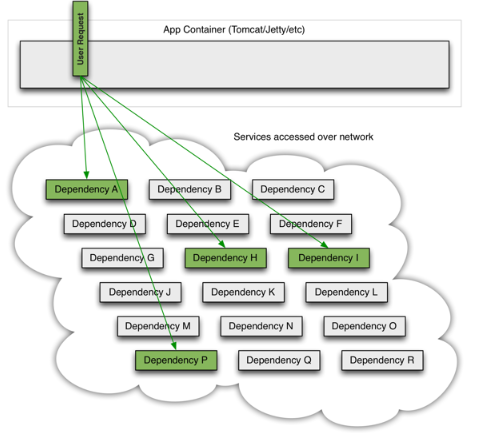
完好情况下,请求流如下:
当一个依赖的节点坏掉时,将阻塞整个的用户请求:
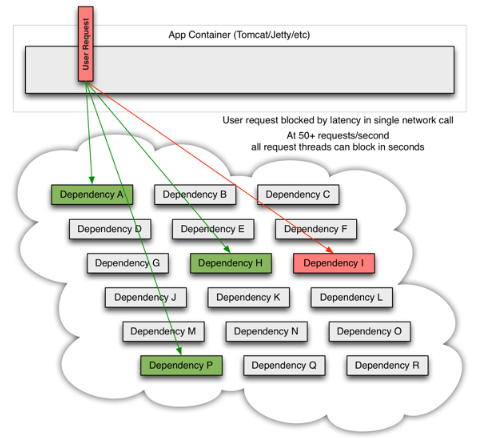
流量高峰时,一个单节点的宕机或延迟,会迅速导致所有服务负载达到饱和。应用中任何一个可能通过网络访问其他服务的节点,都有可能成为造成潜在故障的来源。更严重的是,还可能导致服务之间的延迟增加,占用队列、线程等系统资源,从而导致多系统之间的级联故障。
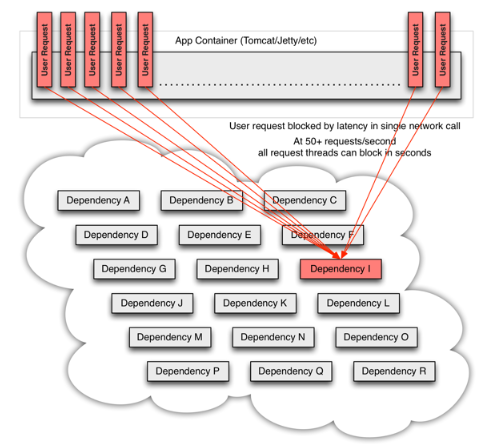
所有上述表现出来的故障或延迟,都需要一套管理机制,将节点变得相对独立,这样任何一个单节点故障,都至少不会拖垮整个系统的可用性。
Hystrix 的设计原则是什么?
Hystrix 通过以下设计原则来运作:
- 防止任何一个单节点将容器中的所有线程都占满
- 通过快速失败,取代放在队列中等待
- 提供在故障时的应急方法(fallback)
- 使用隔离技术 (如 bulkhead, swimlane, 和 circuit breaker patterns) 来限制任何一个依赖项的影响面
- 提供实时监控、报警等手段
- 提供低延迟的配置变更
- 防止客户端执行失败,不仅仅是执行网络请求的客户端
Hystrix 如何时间它的目标?
如下:
- 将远程请求或简单的方法调用包装成
HystrixCommand或者HystrixObservableCommand对象,启动一个单独的线程来运行。 - 你可以为服务调用定义一个超时时间,可以为默认值,或者你自定义设置该属性,使得99.5%的请求时间都在该时间以下。
- 为每一个依赖的服务都分配一个线程池,当该线程池满了之后,直接拒绝,这样就防止某一个依赖的服务出问题阻塞了整个系统的其他服务
- 记录成功数、失败数、超时数以及拒绝数等指标,以便打开熔断及限流开关
- 设置一个熔断器,将所有请求在一段时间内打到这个熔断器提供的方法上,触发条件可以是手动的,也可以根据失败率自动调整。
- 实时监控配置与属性的变更
当你启用 Hystrix 封装了原有的远程调用请求后,整个流程图变为下图所示。
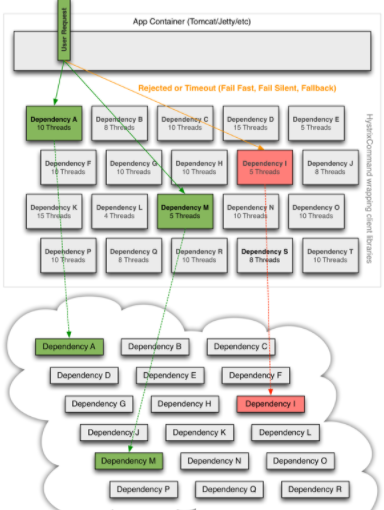
Hystrix工作原理
工作流程图
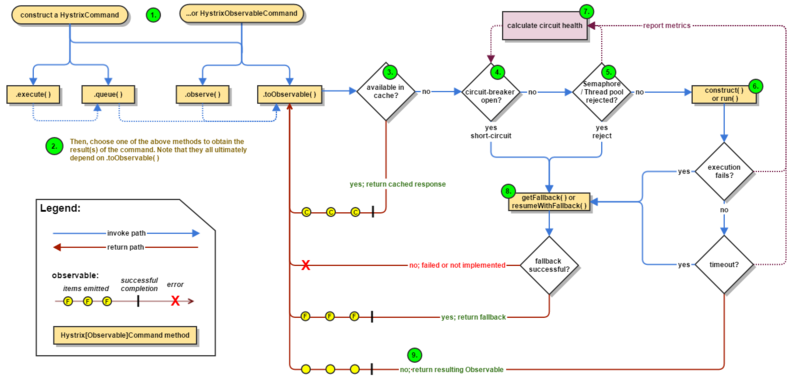
The following sections will explain this flow in greater detail:
- Construct a
HystrixCommandorHystrixObservableCommandObject - Execute the Command
- Is the Response Cached?
- Is the Circuit Open?
- Is the Thread Pool/Queue/Semaphore Full?
HystrixObservableCommand.construct()orHystrixCommand.run()- Calculate Circuit Health
- Get the Fallback
- Return the Successful Response
下面详细分析下各个步骤
1. 构建一个HystrixCommand或者HystrixObservableCommand对象。
第一步就是构建一个HystrixCommand或者HystrixObservableCommand对象,该对象将代表你的一个依赖请求,向构造函数中传入请求依赖所需要的参数。
如果构建HystrixCommand中的依赖返回单个响应,例如:
HystrixCommand command = new HystrixCommand(arg1, arg2);
如果依赖需要返回一个Observable来产生响应,就需要通过构建HystrixObservableCommand对象来完 成,例如:
HystrixObservableCommand command = new HystrixObservableCommand(arg1, arg2);
问题:SpringBoot之中是如何将请求构造成HystrixCommand的?
2. 执行命令
有4种方式可以执行一个Hystrix命令。
execute()— 该方法是阻塞的,从依赖请求中接收到单个响应(或者出错时抛出异常)。queue()— 从依赖请求中返回一个包含单个响应的Future对象。observe()— 订阅一个从依赖请求中返回的代表响应的Observable对象。toObservable()— 返回一个Observable对象,只有当你订阅它时,它才会执行Hystrix命令并发射响应。
K value = command.execute();
Future<K> fValue = command.queue();
Observable<K> ohValue = command.observe(); //hot observable
Observable<K> ocValue = command.toObservable(); //cold observable
同步调用方法execute()实际上就是调用queue().get()方法,queue()方法的调用的是toObservable().toBlocking().toFuture().也就是说,最终每一个HystrixCommand都是通过Observable来实现的,即使这些命令仅仅是返回一个简单的单个值。
3. 响应是否被缓存
如果这个命令的请求缓存已经开启,并且本次请求的响应已经存在于缓存中,那么就会立即返回一个包含缓存响应的Observable(下面将Request Cache部分将对请求的cache做讲解)。
4. 回路器是否打开
当命令执行执行时,Hystrix会检查回路器是否被打开。
如果回路器被打开(或者tripped),那么Hystrix就不会再执行命名,而是直接路由到第8步,获取fallback方法,并执行fallback逻辑。
如果回路器关闭,那么将进入第5步,检查是否有足够的容量来执行任务。(其中容量包括线程池的容量,队列的容量等等)。
5. 线程池、队列、信号量是否已满
如果与该命令相关的线程池或者队列已经满了,那么Hystrix就不会再执行命令,而是立即跳到第8步,执行fallback逻辑。
6. HystrixObservableCommand.construct() 或者 HystrixCommand.run()
在这里,Hystrix通过你写的方法逻辑来调用对依赖的请求,通过下列之一的调用:
-
HystrixCommand.run()—返回单个响应或者抛出异常。 -
HystrixObservableCommand.construct()—返回一个emit响应的Observable或者发送一个
onError()的通知。
如果执行
run()方法或者construct()方法的执行时间大于命令所设置的超时时间值,那么该线程将会抛出一个TimeoutException异常(或者如果该命令没有运行在它自己的线程中,[or a separate timer thread will, if the command itself is not running in its own thread])。在这种情况下,Hystrix将会路由到第8步,执行fallback逻辑,并且如果run()或者construct()方法没有被取消或者中断,会丢弃这两个方法最终返回的结果。请注意,没有任何方式可以强制终止一个潜在[latent]的线程的运行,Hystrix能够做的最好的方式是让JVM抛出一个
InterruptedException异常,如果你的任务被Hystrix所包装,并不意味着会抛出一个InterruptedExceptions异常,该线程在Hystrix的线程池内会进行执行,虽然在客户端已经接收到了TimeoutException异常,这个行为能够渗透到Hystrix的线程池中,[though the load is 'correctly shed'],绝大多数的Http Client不会将这一行为视为InterruptedExceptions,所以,请确保正确配置连接或者读取/写入的超时时间。如果命令最终返回了响应并且没有抛出任何异常,Hystrix在返回响应后会执行一些log和指标的上报,如果是调用
run()方法,Hystrix会返回一个Observable,该Observable会发射单个响应并且会调用onCompleted方法来通知响应的回调,如果是调用construct()方法,Hystrix会通过construct()方法返回相同的Observable对象。
7. 计算回路指标[Circuit Health]
Hystrix会报告成功、失败、拒绝和超时的指标给回路器,回路器包含了一系列的滑动窗口数据,并通过该数据进行统计。
它使用这些统计数据来决定回路器是否应该熔断,如果需要熔断,将在一定的时间内不在请求依赖[短路请求](译者:这一定的时候可以通过配置指定),当再一次检查请求的健康的话会重新关闭回路器。
8. 获取FallBack
当命令执行失败时,Hystrix会尝试执行自定义的Fallback逻辑:
- 当
construct()或者run()方法执行过程中抛出异常。 - 当回路器打开,命令的执行进入了熔断状态。
- 当命令执行的线程池和队列或者信号量已经满容。
- 命令执行超时。
写一个fallback方法,提供一个不需要网络依赖的通用响应,从内存缓存或者其他的静态逻辑获取数据。如果再fallback内必须需要网络的调用,更好的做法是使用另一个HystrixCommand或者HystrixObservableCommand。
如果你的命令是继承自HystrixCommand,那么可以通过实现HystrixCommand.getFallback()方法返回一个单个的fallback值。
如果你的命令是继承自HystrixObservableCommand,那么可以通过实现HystrixObservableCommand.resumeWithFallback()方法返回一个Observable,并且该Observable能够发射出一个fallback值。
Hystrix会把fallback方法返回的响应返回给调用者。
如果你没有为你的命令实现fallback方法,那么当命令抛出异常时,Hystrix仍然会返回一个Observable,但是该Observable并不会发射任何的数据,并且会立即终止并调用onError()通知。通过这个onError通知,可以将造成该命令抛出异常的原因返回给调用者。
失败或不存在回退的结果将根据您如何调用Hystrix命令而有所不同:
execute():抛出一个异常。queue():成功返回一个Future,但是如果调用get()方法,将会抛出一个异常。observe():返回一个Observable,当你订阅它时,它将立即终止,并调用onError()方法。toObservable():返回一个Observable,当你订阅它时,它将立即终止,并调用onError()方法。
返回成功的响应
如果Hystrix命令执行成功,它将以Observable形式返回响应给调用者。根据你在第2步的调用方式不同,在返回Observablez之前可能会做一些转换。
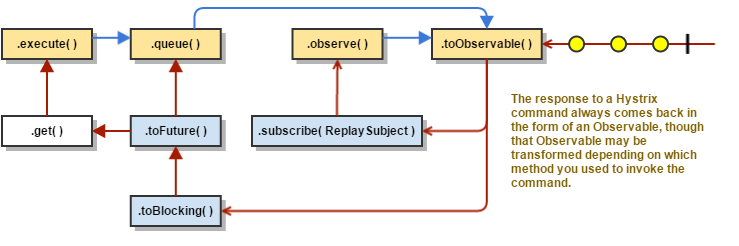
execute():通过调用queue()来得到一个Future对象,然后调用get()方法来获取Future中包含的值。queue():将Observable转换成BlockingObservable,在将BlockingObservable转换成一个Future。observe():订阅返回的Observable,并且立即开始执行命令的逻辑,toObservable():返回一个没有改变的Observable,你必须订阅它,它才能够开始执行命令的逻辑。
回路器
下面的图展示了HystrixCommand和HystrixObservableCommand如何与HystrixCircuitBroker进行交互。
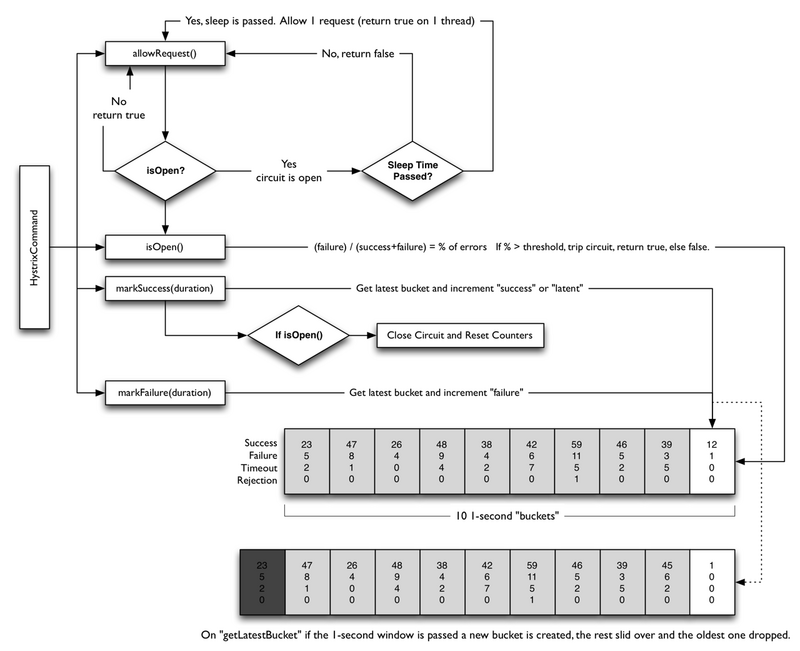
回路器打开和关闭有如下几种情况:
- 假设回路中的请求满足了一定的阈值(
HystrixCommandProperties.circuitBreakerRequestVolumeThreshold()) - 假设错误发生的百分比超过了设定的错误发生的阈值
HystrixCommandProperties.circuitBreakerErrorThresholdPercentage() - 回路器状态由
CLOSE变换成OPEN - 如果回路器打开,所有的请求都会被回路器所熔断。
- 一定时间之后
HystrixCommandProperties.circuitBreakerSleepWindowInMilliseconds(),下一个的请求会被通过(处于半打开状态),如果该请求执行失败,回路器会在睡眠窗口期间返回OPEN,如果请求成功,回路器会被置为关闭状态,重新开启1步骤的逻辑。
隔离
Hystrix采用舱壁模式来隔离相互之间的依赖关系,并限制对其中任何一个的并发访问。
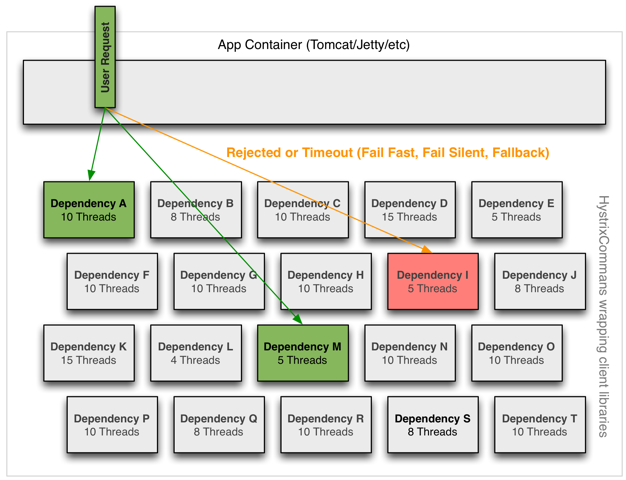
线程和线程池
客户端(第三方包、网络调用等)会在单独的线程执行,会与调用的该任务的线程进行隔离,以此来防止调用者调用依赖所消耗的时间过长而阻塞调用者的线程。
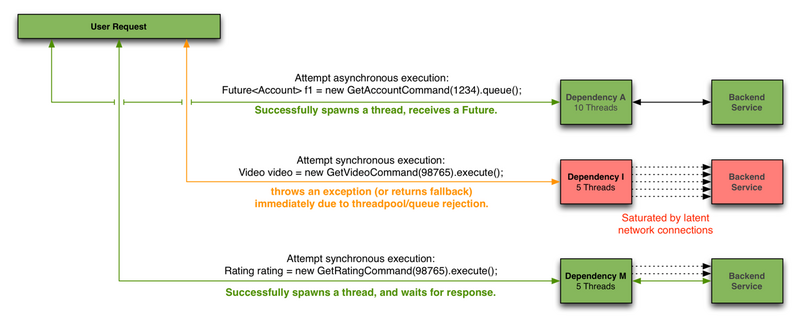
您可以在不使用线程池的情况下防止出现故障,但是这要求客户端必须能够做到快速失败(网络连接/读取超时和重试配置),并始终保持良好的执行状态。
Netflix,设计Hystrix,并且选择使用线程和线程池来实现隔离机制,有以下几个原因:
- 很多应用会调用多个不同的后端服务作为依赖。
- 每个服务会提供自己的客户端库包。
- 每个客户端的库包都会不断的处于变更状态。
- [Client library logic can change to add new network calls]
- 每个客户端库包都可能包含重试、数据解析、缓存等等其他逻辑。
- 对用户来说,客户端库往往是“黑盒”的,对于实现细节、网络访问模式。默认配置等都是不透明的。
- [In several real-world production outages the determination was “oh, something changed and properties should be adjusted” or “the client library changed its behavior.]
- 即使客户端本身没有改变,服务本身也可能发生变化,这些因素都会影响到服务的性能,从而导致客户端配置失效。
- 传递依赖可以引入其他客户端库,这些客户端库不是预期的,也许没有正确配置。
- 大部分的网络访问是同步执行的。
- 客户端代码中也可能出现失败和延迟,而不仅仅是在网络调用中。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号