第四章 线性判据与回归
4.1 线性判据的基本概念
生成模型:给定训练样本{Xn},直接在输入空间内学习其概率密度函数p(x)。
生成模型的优劣势:
优势
可以根据p(x)采样新的样本数据(synthetic data)
可以检测出较低概率的数据,实现离群点检测(outlierdetection)
劣势
高维下,需要大量的训练样本才能准确估计p(x),否则出现维度灾难问题
判别模型
判别模型:给定训练样本{𝑥𝑛},直接在输入空间内估计后验概率$p(C_i|x)
优势
快速直接、省去了耗时的高维观测似然概率估计
线性判据
定义
如果判别模型f(x)是线性函数,则f (x)为线性判据
优势
计算量少,适用于训练样本较少的情况下
模型

判别式
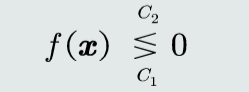
决策边界
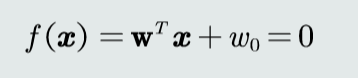
其中w是决策边界法向量,样本到决策边界的距离𝑟=𝑓(𝑥)||𝑤||
并行感知机算法
目标
学习参数w和𝑤0
预处理
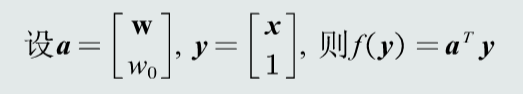

目标函数:针对所有被错误分类的训练样本,其输出取反求和:

目标函数求极值,由于偏导不含a,所以使用梯度下降法迭代更新参数。
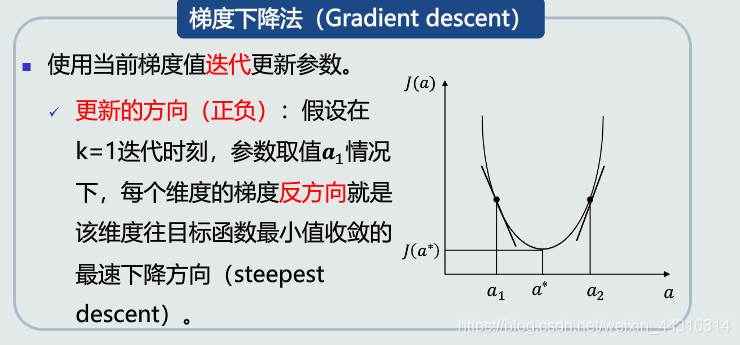

并行感知机的算法流程:

串行感知机算法
训练样本串行给出
目标函数
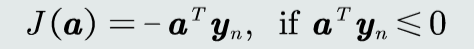
算法流程

Fisher线性判据
Fisher判据的基本原理:找到一个最合适的投影轴,使两类样本在该轴上投影的重叠部分最少,从而使分类效果达到最佳。
目标函数:

优化后的目标函数的新表达:

目标函数的求解:

w与w0的解:


Fisher线性判据:
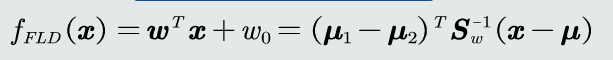
Fisher判据训练过程:

支持向量机(SVM)
给定一组训练样本,使得两个类中与决策边界最近的训练样本到决策边界之间的间隔最大
间隔的定义
在两个类的训练样本中,分别找到与决策边界最近的两个训练样本,记作𝑥+和𝑥−
𝑥+和𝑥−到决策边界的垂直距离叫作间隔,记作𝑑+和𝑑−
支持向量(support vector)
决策边界记作Π,平行于11且分别通过𝑥+和𝑥−的两个超平面记作Π+和Π−,称为间隔边界
位于Π+和Π−上的样本则称为支持向量
目标函数
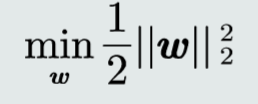
约束条件
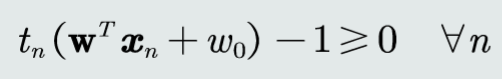
拉格朗日乘数法
等式约束问题的转换
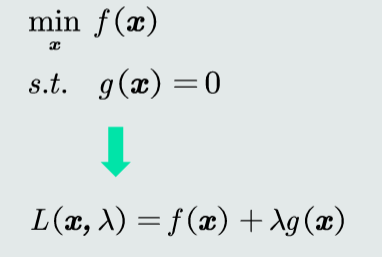
不等式约束问题的转换

拉格朗日对偶问题
Lagrange对偶函数:
定义拉格朗日对偶函数或者对偶函数g为拉格朗日函数关于x取得的最小值,即对α,β,有:

对于任意一组(α,β),其中α≥0,拉格朗日对偶函数给出了原问题的最优值的一个下界,因此,我们可以得到和参数α,β相关的一个下界。一个自然问题是:从Lagrange函数能得到的最好下界是什么?可以将这个问题表述为优化问题:

弱对偶性:

强对偶性:


支持向量机学习算法
目标函数:

拉格朗日函数:
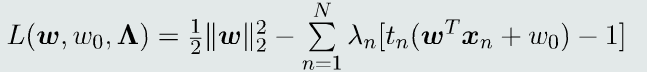
对偶函数:
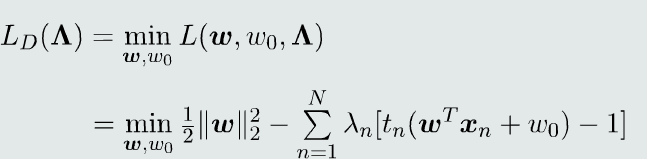
求解支持向量:

参数的最优解:


支持向量机的决策过程:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号