2020软工实践第一次个人编程作业
| 这个作业属于哪个课程 | https://edu.cnblogs.com/campus/fzu/SE2020 |
|---|---|
| 这个作业要求在哪里 | https://edu.cnblogs.com/campus/fzu/SE2020/homework/11167 |
| 这个作业的目标 | github使用,json解析,arg解析,测试项目,性能优化分析 |
| 学号 | 031802513 |
一、PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 60 | 70 |
| Estimate | 估计这个任务需要多少时间 | 150 | 180 |
| Development | 开发 | 100 | 150 |
| Analysis | 需求分析 (包括学习新技术) | 250 | 300 |
| Design Spec | 生成设计文档 | 25 | 30 |
| Design Review | 设计复审 | 15 | 70 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 10 | 20 |
| Design | 具体设计 | 50 | 80 |
| Coding | 具体编码 | 25 | 70 |
| Code Review | 代码复审 | 50 | 130 |
| Test | 测试(自我测试,修改代码,提交修改) | 30 | 50 |
| Reporting | 报告 | 25 | 50 |
| Test Report | 测试报告 | 10 | 20 |
| Size Measurement | 计算工作量 | 5 | 20 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 5 | 20 |
| 合计 | 810 | 1260 |
二、解题过程
分析需求:
python 读取文件夹内的所有文件,解析json,统计json字段 ,python 命令行参数 , 单元测试
json解析用python自带json库,json.loads(json字符串),命令行参数用argparse库,单元测试用unittest库
json库 https://www.runoob.com/python/python-json.html
argparse库 https://www.cnblogs.com/cuhm/p/10643765.html
unittest库 https://www.cnblogs.com/lsdb/p/10444943.html
三、实现过程、流程图
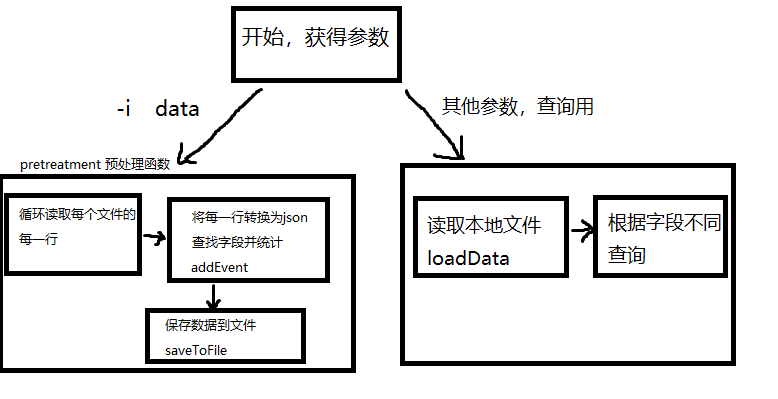
四、代码说明
命令行参数注册
def initArgparse(self):
# 初始化Arg
self.parser = argparse.ArgumentParser()
self.parser.add_argument('-i', '--init')
self.parser.add_argument('-u', '--user')
self.parser.add_argument('-r', '--repo')
self.parser.add_argument('-e', '--event')
#根据参数执行
if self.parser.parse_args().init:
读取目录下所有文件
for root, dic, files in os.walk(Address): #获取文件夹内所有文件
for file in files:
if file[-5:] == '.json': #筛选后缀为.json的文件
findFile=True
json_path = file
filedir = open(Address+'\\'+json_path,
'r', encoding='utf-8')
while True: #对单个文件逐行读取
line = filedir.readline()
if line :
if line.strip() == '': # 如果读到的是空行
continue # 跳过该行
jsondata=json.loads(line)
if not jsondata["type"] in ['PushEvent', 'IssueCommentEvent', 'IssuesEvent', 'PullRequestEvent']: #筛选事件
continue # 跳过无关事件
self.addEvent(jsondata)# 统计事件数量
else:
break
filedir.close()
分析json,统计
if not jsondata["actor"]["login"] in self.__User.keys():
self.__User[jsondata["actor"]["login"]] = {'PushEvent': 0, 'IssueCommentEvent': 0, 'IssuesEvent': 0,
'PullRequestEvent': 0}
if not jsondata["repo"]["name"] in self.__Repo.keys():
self.__Repo[jsondata["repo"]["name"]] = {'PushEvent': 0, 'IssueCommentEvent': 0, 'IssuesEvent': 0,
'PullRequestEvent': 0}
if not jsondata["actor"]["login"] in self.__UserAndRepo.keys():
self.__UserAndRepo[jsondata["actor"]["login"]] = {}
self.__UserAndRepo[jsondata["actor"]["login"]][jsondata["repo"]["name"]] ={'PushEvent': 0, 'IssueCommentEvent': 0, 'IssuesEvent': 0,
'PullRequestEvent': 0}
elif not jsondata["repo"]["name"] in self.__UserAndRepo[jsondata["actor"]["login"]].keys():
self.__UserAndRepo[jsondata["actor"]["login"]][jsondata["repo"]["name"]] = {'PushEvent': 0, 'IssueCommentEvent': 0, 'IssuesEvent': 0,
'PullRequestEvent': 0}
self.__User[jsondata["actor"]["login"]][jsondata['type']] += 1
self.__Repo[jsondata["repo"]["name"]][jsondata['type']] += 1
self.__UserAndRepo[jsondata["actor"]["login"]][jsondata["repo"]["name"]][jsondata['type']] += 1
查询
def getEventsByUsersAndRepos(self, username: str, reponame: str, event: str) -> int:
#通过用户名和仓库名获取事件数量
if not self.__User.get(username,0):
return 0
elif not self.__UserAndRepo[username].get(reponame,0):
return 0
else:
return self.__UserAndRepo[username][reponame].get(event,0)
五、单元测试

测试了预处理、读取预处理文件以及三种查询
覆盖率72%,主要是命令行参数处理部分未测试到,执行时间1.217s
六、性能优化
考虑到可能具有多文件读取,因此增加多线程功能来同时读取多个文件。引用了python的concurrent.futures库
参考资料https://www.cnblogs.com/zhang293/p/7954353.html
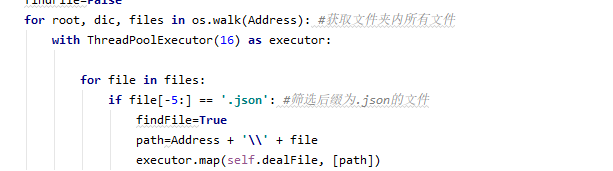
经过多次测试,发现性能并未提升,反而有所下降。经查询,python的多线程因GIL全局解释器锁的原因,在计算密集型任务中效果甚微,更适合用在io密集型任务中
七. 代码规范链接
https://github.com/qewpqewp/2020-personal-python/blob/master/codestyle.md
八、总结
此次作业选择使用python的原因是对于python的代码量不如其他两种语言,希望能借此提高自己python水平。
收获最大的是关于python的多线程的应用,虽然最终没有起到作用。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号