【笔记】深度学习第一课2.3-2.4
logistic 回归损失函数
损失函数 loss function
$L(\hat{y}, y) = -ylog(\hat{y}) - (1 - y)log(1 - \hat{y})$
其中,$\hat{y}$是由sigmoid函数得来的,因此它的范围为$[0,1]$,由损失函数,我们很容易得到:
当$y = 1$时,要使$L$最小,则$\hat{y}$要无限接近1
当$y = -1$时,要使$L$最小,则$\hat{y}$要无限接近0
成本函数 cost function
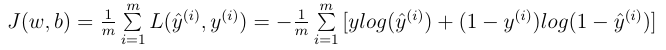
损失函数只适用于像这样的单个训练样本,而代价函数是参数的总代价
梯度下降法
如图,代价函数(成本函数)是一个凸函数(convex function),有唯一最小值
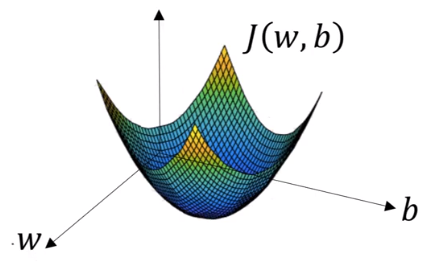
我们要做的就是:我们朝最陡的下坡方向走,直到走到全局最优解或者接近全局最优解的地方
以单个参数为例:
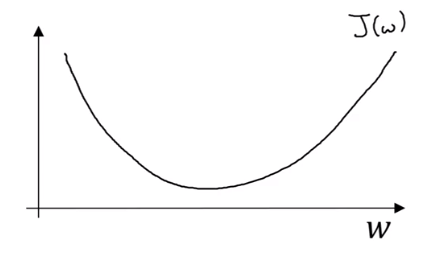
我们通过迭代公式得到结果:
$$w := w - \alpha \frac{dJ(w)}{w}$$
其中,$:=$表示更新参数,$\alpha$表示学习率,在代码中,我们通常用$dw$表示导数。
有关高数的问题:略。
作者:Roki_
-------------------------------------------
キミが笑うだけで 全回復だもん!
只要能看到你的笑容 就能完全恢复!
努力做一个灵魂有趣的人!
如果觉得这篇文章对你有小小的帮助的话,记得在右下角点个“推荐”哦,博主在此感谢!( ̄▽ ̄)~*
要是打赏一点就更好了(〜 ̄△ ̄)〜(前微信后支付宝)



 浙公网安备 33010602011771号
浙公网安备 33010602011771号