
随笔分类 - mysql
摘要: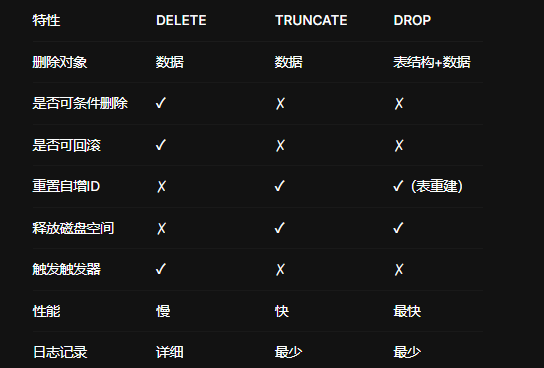
阅读全文
摘要:用户user_id=666 (666的二进制表示为:0000 0010 1001 1010)的用户生成一个订单步骤: 使用user_id%16(假设16个库)分库,决定这行数据要插入到哪个库中 分库基因是user_id的最后4个bit,即1010 在生成order_id时,先使用一种分布式ID生成算
阅读全文
摘要:B树(B-Tree) 1. **定义**:B树是一种平衡的多路搜索树,其中每个节点可以有多个子节点。一个m阶B树的所有叶子节点都位于同一层。 2. **数据存储**:B树中的每个节点都包含数据和子节点指针。数据可以存储在内部节点和叶子节点中。 3. **查询性能**:由于数据分布在所有节点中,B树的
阅读全文
摘要:1. **页大小和存储结构**: - InnoDB存储引擎以页(Page)为单位存储和管理数据,默认页大小为16KB。其中,文件头、页头、页目录等元数据占用了一部分空间,剩下的大约15KB用来存储行记录。 2. **索引页和数据页**: - 索引页主要存储索引和指针,数据页存储完整的行数据。对于索引
阅读全文
摘要:1、in是把外表和内表做hash连接,先查询内表,再把内表结果与外表匹配,对外表使用索引(外表效率高,可用大表),而内表多大都需要查询,不可避免,故外表大的使用in,可加快效率。 2、exists是对外表做loop循环,每次loop循环再对内表(子查询)进行查询,那么因为对内表的查询使用的索引(内表
阅读全文
摘要:1、全备脚本 #!/bin/bash BAK_DIR_ROOT="/mysql/backup" MYSQL_USERNAME="root" MYSQL_PASSWORD="root" MYSQL_CNF="/mysql/data/3306/my.cnf" BAK_FULL_DIR=$BAK_DIR_
阅读全文
摘要:*mysql的简单的分表分库原理 1、中间变量 = user_id%(库数量*每个库的表数量); 2、库序号 = 取整(中间变量/每个库的表数量); 3、表序号 = 中间变量%每个库的表数量; 例如:数据库有256 个,每一个库中有1024个数据表,用户的user_id=262145,按照上述的路由
阅读全文
摘要:切换到 postgres 用户:默认情况下,以 postgres 用户身份登录可以获得数据库的完全访问权限: sudo su - postgres 登录到 PostgreSQL: psql 系统会提示您输入之前设置的 postgres 用户的密码。 登录后,您可以创建新的数据库和用户,或者执行其他数
阅读全文
摘要:创建表空间 CREATE TABLESPACE my_tablespace DATAFILE 'path_to_datafile/dbf/my_tablespace.dbf' SIZE 100M AUTOEXTEND ON NEXT 10M MAXSIZE 500M LOGGING ONLINE P
阅读全文
摘要:1、首先在master上面安装插件 INSTALL PLUGIN rpl_semi_sync_master SONAME 'semisync_master.so'; Query OK, 0 rows affected (0.01 sec) 2、设置master全局变量和超时时间 SET GLOBAL
阅读全文
摘要:COUNT(1):COUNT(1)会统计符合条件的结果集的行数,表示统计结果集中的行数,而括号内的值不影响结果。 使用COUNT(1)可以更快地执行统计,因为不需要实际检查行的数据内容。 COUNT(*):COUNT(*)会统计符合条件的结果集的行数,与COUNT(1)类似,但不同的是COUNT(*
阅读全文
摘要:mysql模糊查询%我就不多说了。想要%在左边也能用到索引,可以选择加全文索引 假设我的表是wa_log记录日志的,url是访问的路径,想要查询url路径中包含admin的数据 ALTER TABLE wa_log ADD FULLTEXT(url); EXPLAIN SELECT * FROM w
阅读全文
摘要:安装,这里用的二进制源码,地址 https://www.percona.com/downloads 完全备份格式 innobackupex -uroot -p密码 备份目录 [参数] 增量备份格式 innobackupex -uroot -p密码 备份目录 --incremental 新数据存放目录
阅读全文
摘要:索引下推是Mysql5.6推出的一个查询优化方案,主要目的是减少数据库查询中不必要的数据读取和计算。 它的原理是将查询条件尽可能地推送到索引层进行过滤,减少了从磁盘读取的数据量和后续的计算开销。 简单通过一个案例说明一下实现原理 有一张用户表User,并创建了一个联合索引(name,age),现在需
阅读全文
摘要:先通过命令行进入mysql的root账户: 更改加密方式 ALTER USER 'root'@'localhost' IDENTIFIED BY 'password' PASSWORD EXPIRE NEVER; 更改密码 ALTER USER 'root'@'localhost' IDENTIFI
阅读全文
摘要:1:有账号的情况下 use mysql; update user set Host = '%' where User='root'; flush privileges; 2:无账号的情况下,grant 命令重新创建一个用户 grant all privileges on *.* to root @"
阅读全文
摘要:XA的性能很低,但是没得选的时候,也是个方案 <?PHP $dbtest1 = new mysqli("127.0.0.1","public","public","dbtest1")or die("dbtest1 连接失败"); $dbtest2 = new mysqli("127.0.0.1pub
阅读全文
摘要:mysql产生临时表的原因有哪些? 排序操作:如果查询语句中包含了ORDER BY子句,MySQL就会使用临时表来存储排序结果。 分组操作:如果查询语句中包含了GROUP BY子句,MySQL就会使用临时表来存储分组结果。 连接操作:如果查询语句中包含了JOIN子句,MySQL可能会使用临时表来存储
阅读全文
摘要:所谓两阶段提交,其实就是把 redo log 的写入拆分成了两个步骤:prepare 和 commit。 首先,存储引擎将执行更新好的新数据存到内存中,同时将这个更新操作记录到 redo log 里面,此时 redo log 处于 prepare 状态。然后告知执行器执行完成了,随时可以提交事务 然
阅读全文
 浙公网安备 33010602011771号
浙公网安备 33010602011771号