

04.Java8中stream
0.参考文档:
Java Stream的API使用:https://www.cnblogs.com/jimoer/p/10995574.html
Java8只stram:https://www.cnblogs.com/andywithu/p/7404101.html
官网文档: https://docs.oracle.com/javase/8/docs/api/java/util/stream/Stream.html
1.常用的知识库
1.1 范式: 类名::方法名
定义: 双冒号运算操作符是类方法的句柄,lambda表达式的一种简写,这种简写的学名叫eta-conversion或者叫η-conversion。
说明:
把 x -> System.out.println(x) 简化为 System.out::println 的过程称之为 eta-conversion
把 System.out::println 简化为 x -> System.out.println(x) 的过程称之为 eta-expansion
案例:
查看代码
person -> person.getAge();
可以替换成
Person::getAge
x -> System.out.println(x)
可以替换成
System.out::println
out是一个PrintStream类的对象,println是该类的方法,依据x的类型来重载方法
创建对象
() -> new ArrayList<>();
可以替换为
ArrayList::new
new关键字实际上调用的是ArrayList的构造方法1.2 Lambda表达式
基本语法: (parameters) -> expression 或
2.初识stream
stream以一种声明性方式处理数据集合(侧重对于源数据计算能力的封装,并且支持序列与并行两种操作方式)
总纲:
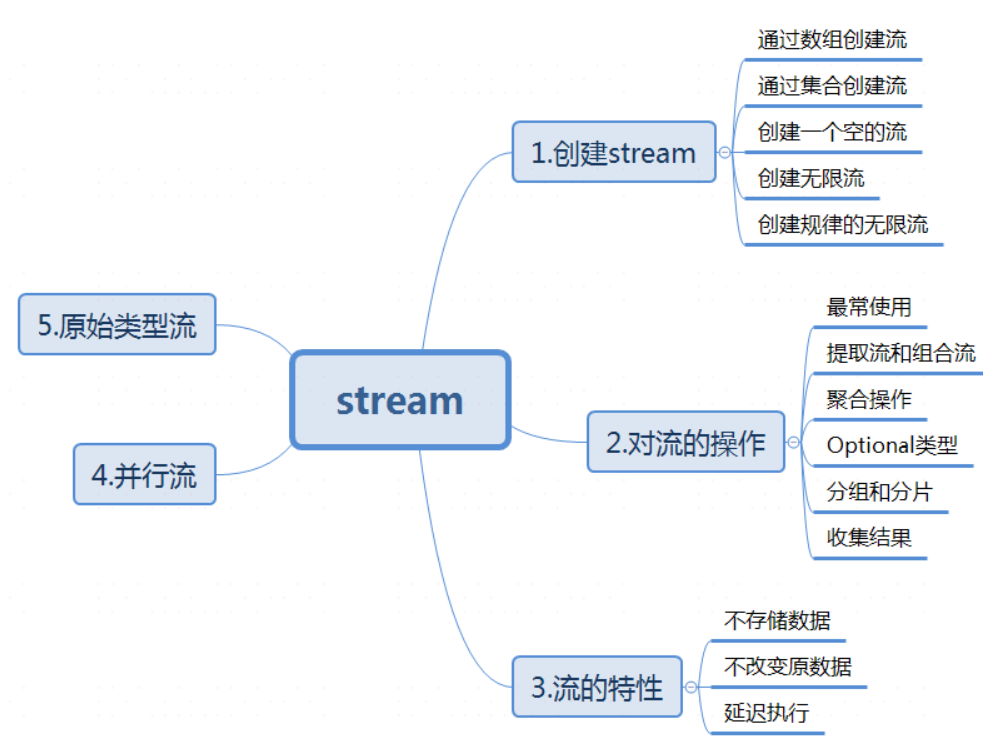
Stream的特性:
1.stream不存储数据
2.stream不改变源数据
3.Stream 流的正常使用
3.1创建流
-
数组
- Arrays.stream(T array);
- stream.of(array)
-
Collection
- Collection.stream()
- Collection.parallelStream()
- 其他常用流
1. 空流:Stream.empty()
2. 无限数据流:Stream.generate()
3.规律的无限数流:Stream.iterate()
查看代码
@Test
public void testArrayStream(){
//1.通过Arrays.stream
//1.1基本类型
int[] arr = new int[]{1,2,34,5};
IntStream intStream = Arrays.stream(arr);
//1.2引用类型
Student[] studentArr = new Student[]{new Student("s1",29),new Student("s2",27)};
Stream<Student> studentStream = Arrays.stream(studentArr);
//2.通过Stream.of
Stream<Integer> stream1 = Stream.of(1,2,34,5,65);
//注意生成的是int[]的流
Stream<int[]> stream2 = Stream.of(arr,arr);
stream2.forEach(System.out::println);
//3.通过数组创建
List<String> strs = Arrays.asList("11212","dfd","2323","dfhgf");
//3.1创建普通流
Stream<String> stream = strs.stream();
//3.2创建并行流
Stream<String> stream1 = strs.parallelStream();
//4.创建一个空的stream
Stream<Integer> stream = Stream.empty();
//5.创建无限流,通过limit提取指定大小
Stream.generate(()->"number"+new Random().nextInt()).limit(100).forEach(System.out::println);
Stream.generate(()->new Student("name",10)).limit(20).forEach(System.out::println);
//6.产生规律的数据
Stream.iterate(0,x->x+1).limit(10).forEach(System.out::println);
Stream.iterate(0,x->x).limit(10).forEach(System.out::println);
//Stream.iterate(0,x->x).limit(10).forEach(System.out::println);与如下代码意思是一样的
Stream.iterate(0, UnaryOperator.identity()).limit(10).forEach(System.out::println);
}3.2 对流的操作
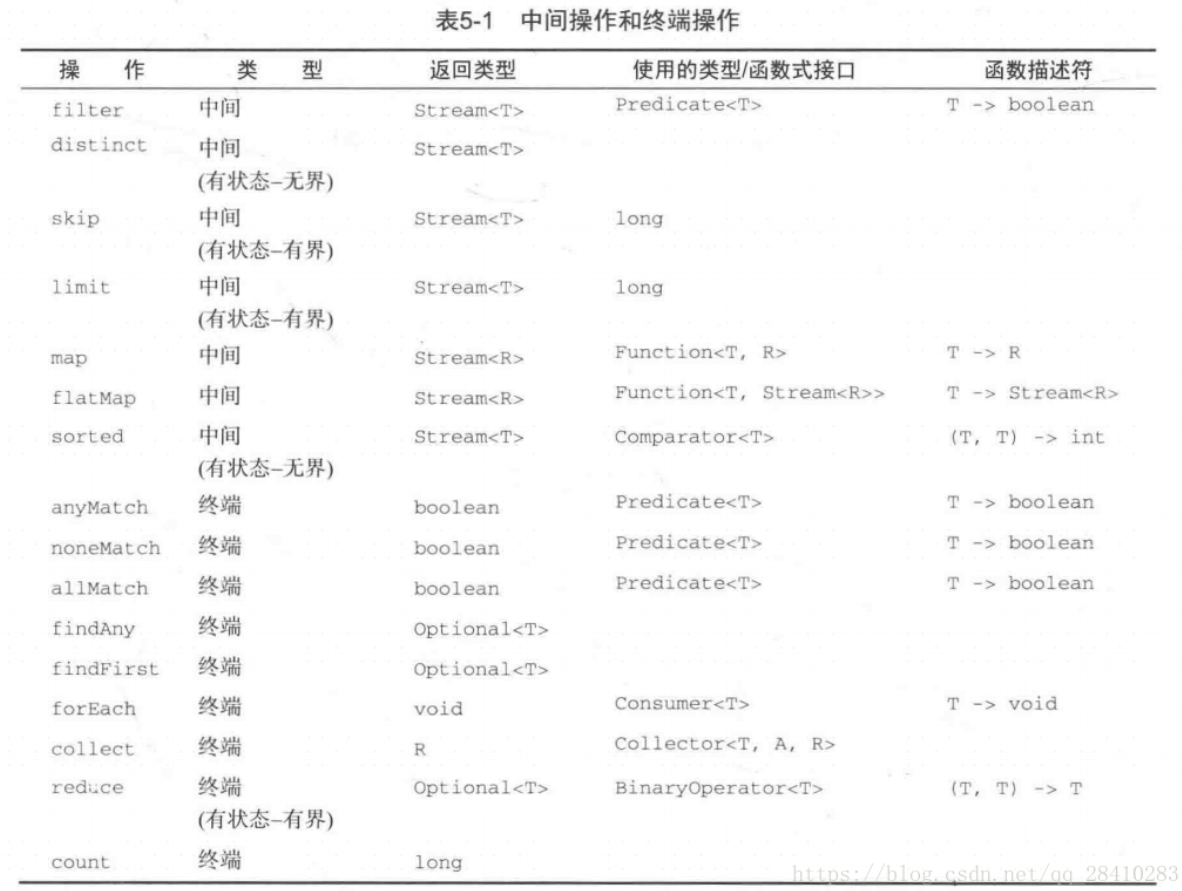
中间操作(中间操作链)
流中间操作在应用到流上,返回一个新的流。下面列出了常用的流中间操作:
-
- 【转换】map:通过一个 Function 把一个元素类型为 T 的流转换成元素类型为 R 的流。
- 【转换合并】flatMap:通过一个 Function 把一个元素类型为 T 的流中的每个元素转换成一个元素类型为 R 的流,再把这些转换之后的流合并。
- filter:过滤流中的元素,只保留满足由 Predicate 所指定的条件的元素。
- distinct:使用 equals 方法来删除流中的重复元素。
- limit:截断流使其最多只包含指定数量的元素。
- skip:返回一个新的流,并跳过原始流中的前 N 个元素。
- sorted:对流进行排序。
- peek:返回的流与原始流相同。当原始流中的元素被消费时,会首先调用 peek 方法中指定的 Consumer 实现对元素进行处理。
- dropWhile:从原始流起始位置开始删除满足指定 Predicate 的元素,直到遇到第一个不满足 Predicate 的元素。
- takeWhile:从原始流起始位置开始保留满足指定 Predicate 的元素,直到遇到第一个不满足 Predicate 的元素。
- concat :可以把两个stream合并成一个stream(合并的stream类型必须相同),只能两两合并
终结操作(终结操作产生最终的结果)
-
- max、min: 需要一下比较函数。
- count:计数。
- findFirst:查找第一个 。
- findAny:对并行流十分有效,只要在任何片段发现了第一个匹配元素就会结束整个运算。
- match: 匹配所有元素。
- anyMatch:是否含有匹配元素。
- forEach、 forEachOrdered 对流中的每个元素执行由 Consumer 给定的实现。在使用 forEach 时,并没有确定的处理元素的顺序;forEachOrdered 则按照流的相遇顺序来处理元素,如果流有确定的相遇顺序的话(这种方法保证了在顺序流和并行流中都按顺序执行。)。
- reduce:进行递归计算。
- collect:生成新的数据结构。
3.3并行流
-
- parallel():可以将普通顺序执行的流转变为并行流,只需要调用顺序流的parallel() 方法即可
3.4原始类型流
-
- Optional.of()创建指定值的Optional,聚合操作会返回一个Optional类型。 不能为空
- Optional.ofNullable
- orElse() optional 无论是否为null 都为被执行。
- orElseGet() optional 为nulll 时被执行。
- orElseThrow() 为空时直接抛异常。
3.5 stream 类使用场景案例
查看代码
@Test
public void testStreamMap1() {
//1.flatMap:拆解流
String[] arr1 = {"a", "b", "c", "d"};
String[] arr2 = {"e", "f", "c", "d"};
String[] arr3 = {"h", "j", "c", "d"};
// Stream.of(arr1, arr2, arr3).flatMap(x -> Arrays.stream(x)).forEach(System.out::println);
//1.1 拆解流
Stream.of(arr1, arr2, arr3).flatMap(Arrays::stream).forEach(System.out::println);
//1.2 类型转换 map()
Arrays.stream(arr1).map(o-> {
return new Person(1,o ,12,"1年级");
}).forEach(System.out::println);
//2.比较函数 sort()
//
//2.1按照字符长度排序
Arrays.stream(arr1).sorted((x,y)->{
if (x.length()>y.length())
return 1;
else if (x.length()<y.length())
return -1;
else
return 0;
}).forEach(System.out::println);
//2.2 倒序
/**
* 倒序
* reversed(),java8泛型推导的问题,所以如果comparing里面是非方法引用的lambda表达式就没办法直接使用reversed()
* Comparator.reverseOrder():也是用于翻转顺序,用于比较对象(Stream里面的类型必须是可比较的)
* Comparator. naturalOrder():返回一个自然排序比较器,用于比较对象(Stream里面的类型必须是可比较的)
*/
Arrays.stream(arr1).sorted(Comparator.comparing(String::length).reversed()).forEach(System.out::println);
Arrays.stream(arr1).sorted(Comparator.reverseOrder()).forEach(System.out::println);
Arrays.stream(arr1).sorted(Comparator.naturalOrder()).forEach(System.out::println);
//2.3 Comparator.comparing 现有的比较函数
/**
* thenComparing
* 先按照首字母排序
* 之后按照String的长度排序
*/
Arrays.stream(arr1).sorted(Comparator.comparing(this::com1).thenComparing(String::length)).forEach(System.out::println);
//3.forEach 遍历操作
//3.1 forEach在并行流中forEach不保证按顺序执行。
Stream.of("A","B","C", "D")
.parallel()
.forEach(e -> System.out.println(e));
//3.2 forEachOrdered 方法总是保证按顺序执行
Stream.of("A","B","C", "D")
.parallel()
.forEachOrdered(e -> System.out.println(e));
// 4. reduce() 归约:(可以理解为递归,也是终止操作)
List<Integer> list = Arrays.asList(1,2,3,4,5,6,7,8,9);
//这里0是初始值,第一次执行规约应该是0+1,其中1是第一个值
Integer sum = list.stream().reduce(0, (x,y) -> x + y);
System.out.println("sum:"+sum);
//计算累加值
Optional<Integer> reduce = personList.stream().map(Person::getAge).reduce(Integer::sum);
System.out.println("sum2:"+reduce.get());
//5. collect 收集 :将流转换为其他形式,接收一个collection接口的实现,用于给stream元素做汇总的方法
// 5.1 生成List
List<Person> personList1= personList.stream().collect(Collectors.toList());
// 5.2 生成 set
Set<Person> personList2= personList.stream().collect(Collectors.toSet());
//5.3 生成数组
Person [] personList3= personList.stream().toArray(Person[]::new);
//5.4 指定生成的类型
HashSet<Person> personList4= personList.stream().collect(Collectors.toCollection(HashSet::new));
//5.5 统计 IntSummaryStatistics 统计分析类,其中的
IntSummaryStatistics summaryStatistics = personList.stream().collect(Collectors.summarizingInt(Person::getAge));
System.out.println("getAverage->"+summaryStatistics.getAverage());
System.out.println("getMax->"+summaryStatistics.getMax());
System.out.println("getMin->"+summaryStatistics.getMin());
System.out.println("getCount->"+summaryStatistics.getCount());
System.out.println("getSum->"+summaryStatistics.getSum());
// Collectors.counting(), Collectors.averagingInt进行单次统计
Long count = personList.stream().collect(Collectors.counting());
Double avgAge = personList.stream().collect(Collectors.averagingInt(Person::getAge));
//6 转换成为Map 分组和分片的意义是,将collect的结果集展示位Map<key,val>的形式
//6.1
Map<String,Integer> map = personList.stream().collect(Collectors.toMap(Person::getName,Person::getAge,(s,a)->s));
//Map的value为对象本身 Function.identity() 或者t->t
Map<String,Person> map = personList.stream().collect(Collectors.toMap(Person::getName,t->t,(s,a)->s));
//6.2 groupingBy 分组
Map<String,List<Person>> map2 = personList.stream().collect(groupingBy(Person::getName));
//6.3 partitioningBy 分类只有两类的结果
Map<Boolean,List<Person>> map3= personList.stream().collect(partitioningBy(x->x.getAge()>9));
//6.4 downstream指定类型
Map<String,Set<Person>> map4 = personList.stream().collect(groupingBy(Person::getName,toSet()));
//6.5 downstream 聚合操作
Map<String,Long> map5 = personList.stream().collect(groupingBy(Person::getName,counting()));
Map<String,Integer> map6 = personList.stream().collect(groupingBy(Person::getName,summingInt(Person::getAge)));
Map<String,Optional<Person>> map7 = personList.stream().collect(groupingBy(Person::getName,maxBy(Comparator.comparing(Person::getAge))));
//mapping收集器跟stream中间操作中的map基本上功能一致,进行属性转换并且按照指定的格式返回集合
Map<String,Set<Integer>> map8 = personList.stream().collect(groupingBy(Person::getName,mapping(Person::getAge,toSet())));
//6.6多级分组
Map<String, Map<String, List<Person>>> collect = personList.stream().collect(Collectors.groupingBy(
Person::getGrade, Collectors.groupingBy(u -> {
if(((Person)u).getAge() <= 9) {
return "happy";
} else {
return "very happy";
}
})));
//7.原始类型流 (在数据量比较大的情况下,将基本数据类型(int,double...)包装成相应对象流的做法是低效的)
// 7.1 初始化 (IntStream,DoubleStream,LongStream) 目前是三种原始类型流
DoubleStream doubleStream = DoubleStream.of(0.1,0.2,0.3,0.8);
IntStream intStream = IntStream.of(1,3,5,7,9);
IntStream stream1 = IntStream.rangeClosed(0,100);
IntStream stream2 = IntStream.range(0,100);
//7.2 原始类型流转换与实际类型流之间的转换
Stream<Double> stream = doubleStream.boxed();
doubleStream = stream.mapToDouble(Double::new);
//8.peek方法顾名思义,就是偷窥流内的数据 其中的 peek1,2,3 为Stream<T> peek(Consumer<? super T> action);
Stream<Integer> streamPeek= Stream.iterate(1, x -> x + 1).limit(10).parallel();
// streamPeek.peek(this::peek1).filter(x -> x > 5)
// .peek(this::peek2).filter(x -> x < 8)
// .peek(this::peek3)
// .forEach(System.out::println);
//9.Optional类型 聚合操作会返回一个Optional类型
//9.1 Optional 创建, optional.get() 返回正常的值
Optional<Person> studentOptional = Optional.of(personList.get(0));
Optional<String> optionalStr = studentOptional.map(Person::getName);
Optional<Double> revert= studentOptional.get().getAge()== 0 ? Optional.empty() : Optional.of(1 / (double)studentOptional.get().getAge());
//9.2 Optional默认值
Integer[] arr = new Integer[]{4,5,6,7,8,9};
Integer result = Stream.of(arr).filter(x->x>9).max(Comparator.naturalOrder()).orElse(-1);
Integer result1 = Stream.of(arr).filter(x->x>9).max(Comparator.naturalOrder()).orElseGet(()->-1);
Integer result2 = Stream.of(arr).filter(x->x>9).max(Comparator.naturalOrder()).orElseThrow(RuntimeException::new);
//9.3 //ifPresent(Consumer<? super T> consumer)在结果部位空时进行消费操作
String a= optionalStr.ifPresent(); 为空时,执行正常的操作。
//10.流操作中判断是否为空的问题
}为空判断:
参考链接:https://www.cnblogs.com/zhangboyu/p/7580262.html
查看代码
// 1.null 是否能正常的装换成stream ,数组不能为空,为空编译器直接报错。集合转换成流,集合为空运行时报空指针。
Integer[] arr=new Integer[]{4,5,6};
List<Integer> strzint= Stream.of(arr).filter(o->o>6).collect(toList()); // 编译器直接报错
Assert.assertNotNull(strzint);
Stream<Person> personStream2= personList.stream().filter(o->o.getAge()>10);
List<Person> personStream3=personStream2.collect(toList()); //执行之后不为NULL;size=0
Assert.assertNotNull(personStream3);
personList=null;
Stream<Person> personStream= personList.stream().filter(o->o.getAge()>1); //NullPointerException
List<Person> personStream1=personStream.collect(toList());
// 2.optional 空对象的正常使用
personList=null;
//1.get(), 为空时不能直接进行调动。
Optional<Person> emptyOpt = Optional.empty();
emptyOpt.get(); //NoSuchElementException
boolean bool=emptyOpt.isPresent();// 使用前验证是否为NUll值的判断。
//2.of() 和 ofNullable() 方法创建包含值的 Optional。两个方法的不同之处在于如果你把 null 值作为参数传递进去,
// of() 方法会抛出 NullPointerException:
//对象即可能是 null 也可能是非 null,你就应该使用 ofNullable() 方法
Optional<List<Person>> testOpt1 = Optional.of(personList); // NullPointerException
Optional<List<Person>> testOpt2 = Optional.ofNullable(personList); //正常的调用情况
//3.orElse(),orElseGet() 正常的使用状况
//orElse() optional 无论是否为null 都为被执行,
//orElseGet() optional 为nulll 时被执行。
List<Person> result = Optional.ofNullable(personList).orElse(Init());
List<Person> result2 = Optional.ofNullable(personList).orElseGet(() -> Init());
personList=new ArrayList<>();
List<Person> result3 = Optional.ofNullable(personList).orElse(Init());
List<Person> result4 = Optional.ofNullable(personList).orElseGet(() -> Init());经典的使用场景:
查看代码
List<ImportDeviceReq> list = new ArrayList<>();
//根据device_code去重,取出重复值
List<String> dupList = list.stream().collect(Collectors.groupingBy(ImportDeviceReq::getDeviceCode, Collectors.counting()))
.entrySet().stream().filter(e -> e.getValue() > 1)
.map(Map.Entry::getKey).collect(Collectors.toList());
List<String> telephoneList = new ArrayList<>();
//字符串取出重复值
List<String> repeatList = telephoneList.stream().collect(Collectors.groupingBy(e -> e, Collectors.counting()))
.entrySet().stream().filter(e -> e.getValue() > 1)
.map(Map.Entry::getKey).collect(Collectors.toList());
List<FeYltTicketBatchReq.IssueTicketInfo> issueTicketInfo = issueTicket.getIssueTicketInfo();
//每个人的服务券数量相加
int sum = issueTicketInfo.stream().mapToInt(FeYltTicketBatchReq.IssueTicketInfo::getTicketCount).sum();
3.6 map 的使用
参考:https://www.jianshu.com/p/b2d78544df64
3.6.1map的4种遍历
查看代码
public static void main(String[] args) {
Map<String, String> map = new HashMap<String, String>();
map.put("1", "value1");
map.put("2", "value2");
map.put("3", "value3");
//第一种:普遍使用,二次取值
System.out.println("通过Map.keySet遍历key和value:");
for (String key : map.keySet()) {
System.out.println("key= "+ key + " and value= " + map.get(key));
}
//第二种
System.out.println("通过Map.entrySet使用iterator遍历key和value:");
Iterator<Map.Entry<String, String>> it = map.entrySet().iterator();
while (it.hasNext()) {
Map.Entry<String, String> entry = it.next();
System.out.println("key= " + entry.getKey() + " and value= " + entry.getValue());
}
//第三种:推荐,尤其是容量大时
System.out.println("通过Map.entrySet遍历key和value");
for (Map.Entry<String, String> entry : map.entrySet()) {
System.out.println("key= " + entry.getKey() + " and value= " + entry.getValue());
}
//第四种
System.out.println("通过Map.values()遍历所有的value,但不能遍历key");
for (String v : map.values()) {
System.out.println("value= " + v);
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号