

数据采集第一次作业
第一次大作业
作业①
1.1实验题目
要求:用urllib和re库方法定向爬取给定网址(https://www.shanghairanking.cn/rankings/bcsr/2020/0812 )的数据。
输出信息:
| 2020排名 | 全部层次 | 学校类型 | 总分 |
|---|---|---|---|
| 1 | 前2% | 中国人民大学 | 1069.0 |
| 2...... |
1.2思路
因为所需要的信息都在<td>标签中,所以首先将每个<td>标签通过re库中的findall()函数找到并存储下来。
d = re.findall(r'<td data-v-68e330ae>(.*)</td></tr>', html, re.S)[0]
然后再使用re语句对排名、层次、学校类型、总分等分别进行查找。
排名:r'<div class="ranking" data-v-68e330ae>(.*?)</div>',但是得到的结果会有空格不仅仅是数字,所以通过下面的语句得到数字:
ranklt = str(ranklt)
rankl = re.findall(r'\d+',ranklt,re.S)
层次r'前\d+%'
学校类型:r'<a.*? class="name-cn".*?>(.*?)</a>'
总分:r'\d+\.\d+'
通过循环语句将四个分别存入一个列表里,再对输出格式定义,通过循环语句输出结果。

1.3代码
https://gitee.com/q_kj/crawl_project/tree/master/first
1.4总结
一开始就一直得不到正确的四个结果,在使用re语句匹配结果时一直为空。在看了书上1.9的例子后,了解了可以一层一层的去得到结果,所以想到可以先得到所有的<td>标签,再进行下面的匹配就可以得到结果。同样的对排名的获得也是参考这种思想,虽然第一步得到的排名有其他东西,但是可以通过再次筛选得到正确的结果。而且通过这个实验也使得我对re库的使用更加了解。
作业②
2.1实验题目
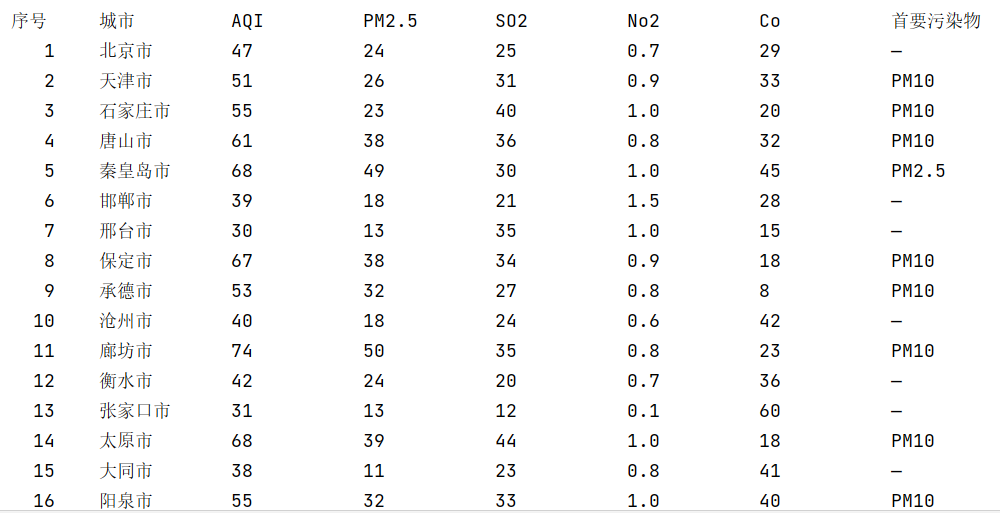
- 要求:用requests和Beautiful Soup库方法设计爬取https://datacenter.mee.gov.cn/aqiweb2/ AQI实时报。
- 输出信息:
| 序号 | 城市 | AQI | PM2.5 | SO2 | No2 | Co | 首要污染物 |
|---|---|---|---|---|---|---|---|
| 1 | 北京 | 55 | 6 | 5 | 1.0 | 225 | — |
| 2...... |
2.2思路
首先通过访问所给网址发现一个城市的数据都是存储在<tbody>标签下的<tr>标签中,而每个指标则是在<tr>标签下的<td>中,如图

因为其中有一部分的数据是我们不需要的,所以要对数据进行选择:
ilt.append([tds[0].text.strip(), tds[1].text.strip(), tds[2].text.strip(), tds[5].text.strip(),
tds[6].text.strip(), tds[7].text.strip(),tds[8].text.strip()])
然后就是对输出格式进行定义:
tplt = "{:4}\t{:8}\t{:8}\t{:8}\t{:8}\t{:8}\t{:8}\t{:8}"
运行代码结果:
2.3代码
https://gitee.com/q_kj/crawl_project/blob/master/first/2.py
2.4总结
这道题和之前对大学排名的爬取是一样的,主要在于对数据的选择以及最后输出的格式化,如果不对输出进行格式化得到的结果可能不整齐。
作业③
3.1实验题目
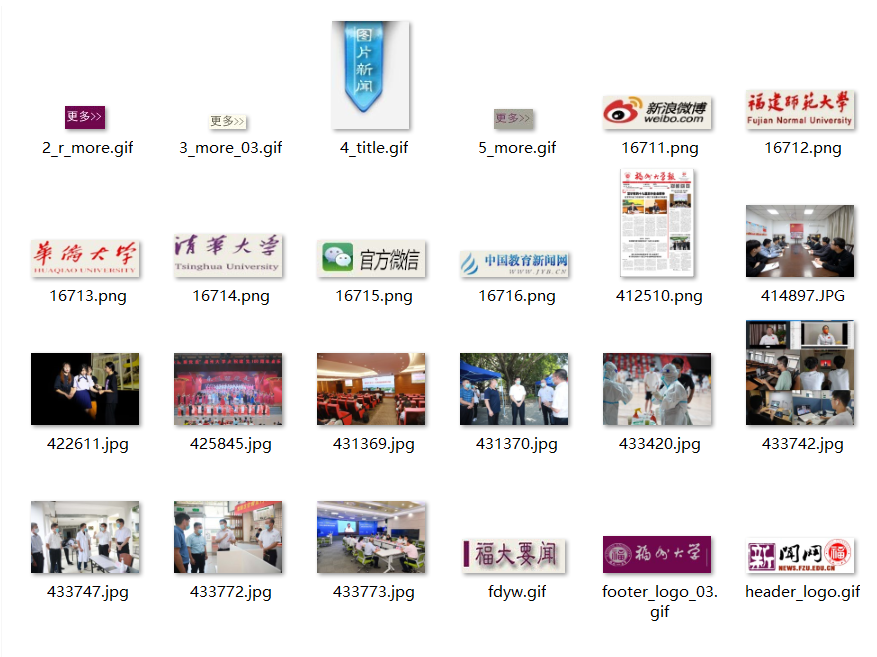
- 要求:使用urllib和requests爬取(https://news.fzu.edu.cn/),并爬取该网站下的所有图片
- 输出信息:将网页内的所有图片文件保存在一个文件夹中
3.2思路
主要在于对图片的爬取以及存储问题上。
首先对于图片的爬取,刚开始我只选择了.jpg格式的图片,发现不能得到所有的图片,再次检查网页源代码后发现有些图片并不是以.jpg结尾的,所以使用下面的匹配方式可以得到所有的图片:
l = re.findall(r'<img.*?src="(.*?)"', html)
最后是存储图片,一开始我使用了urllib.request.urlretrieve()方法,没有结果。然后上网查找了关于如何存储的问题,在https://blog.csdn.net/qq_43066675/article/details/107969238中找到了方法。
运行代码后结果:
3.3代码
https://gitee.com/q_kj/crawl_project/blob/master/first/3.py
3.4总结
从这道题中学会了如何将爬取的图片写入本地文件夹中,之前都是使用urllib.request.urlretrieve()方法来存储,这是第一次专门去查找如何存储的问题。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号