
网络爬虫
在用requests扒网页的时候,发现一个很严重的问题:python2.x版本总是出现莫名其妙的编码无法解析问题,后来在助教的帮助下,知道版本默认的编码不一样,用3.x妥妥的(但我其实还是很疑惑,就算默认的不一样,手动修改还不行么。在网上查了半天解决方案也没查到清晰易懂的方式,这个问题就略过了。)之后,就顺水推舟了。
在写python爬虫的时候,以为是个与互联网的发展同步接轨的技术,能高效处理大数据。但看同学写的之后才发现这什么玩意,能直接用F12看到的网页元素,还用的着这种对付大数据的爬虫技术么,牛刀小试有意思?(总感觉是在用已知的东西去推理一个也是已知的东西,逗我呢?)还有那个作业提交表单,分明是个动态语言,对于我这种小白简直是个难上天的处理操作,后来发现python库确实强大,动态就动态,你只要会用库的方法和属性,所有的难关python自动在底层一一实现了(不过这样的话也没意思哈,一直这样用,以后还有谁会写那些生涩的底层语言呢,到底是进步,还是退步)
完成这个作业后,深刻认知到自己对python语言的认知度还是基本上为0,python果然有其独特的魅力。
以下是代码:
import requests
import json
r = requests.get('https://edu.cnblogs.com/Homework/GetAnswers?homeworkId=2420')
r.encoding = r.apparent_encoding
datas = json.loads(r.text)['data']
print(datas)
with open('C:\\Users\\Administrator\\Desktop\\ppp\\hwlist.csv','w') as f:
for i in datas:
f.write(str(i['StudentNo'])+','+i['RealName']+','+i['Title']+','+i['Url']+','+i['DateAdded']+'\n')
一下是运行的结果成品:
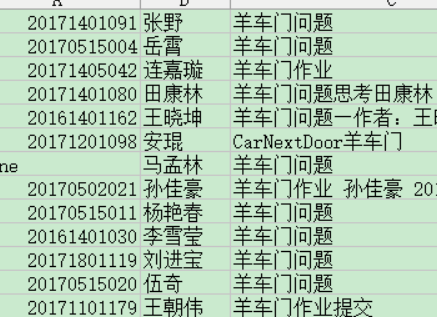
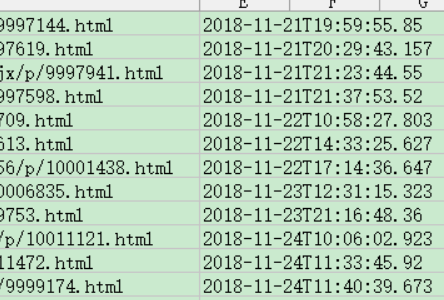
注意到时间点列表有个问题,总有个 ’T‘不知道为什么,只能字符串替换了:
在把字典‘data’对应的列表值保存为datas后,用‘i’索引列表里的['DateAdded']字典对应值时 写上 str (i['DateAdded'] ) . replace['T',',']就可以了

 浙公网安备 33010602011771号
浙公网安备 33010602011771号