20184202路荣辉 实验四《Python程序设计》实验报告
实验四《python程序设计》实验报告
课程:《Python程序设计》
班级: 1842
姓名: 路荣辉
学号:20184202
实验教师:王志强
实验日期:2020年6月5日
必修/选修: 公选课
一、实验代码截图
代码:
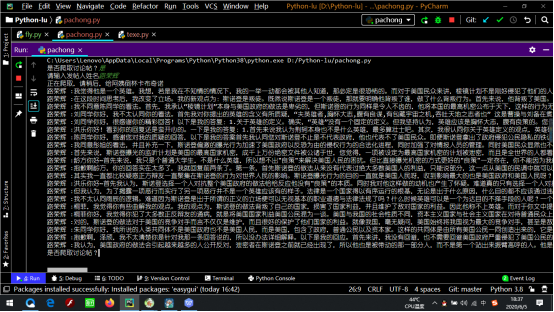
运行结果:
二、设计思路
本次实验主要分为三步:
1.爬取网页源代码
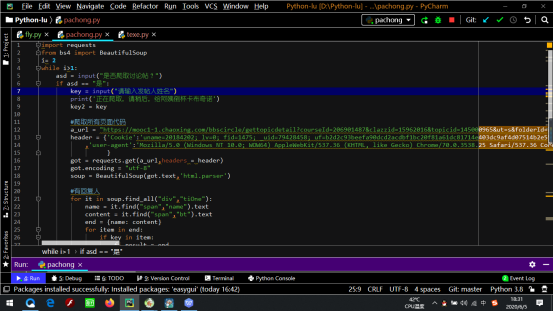
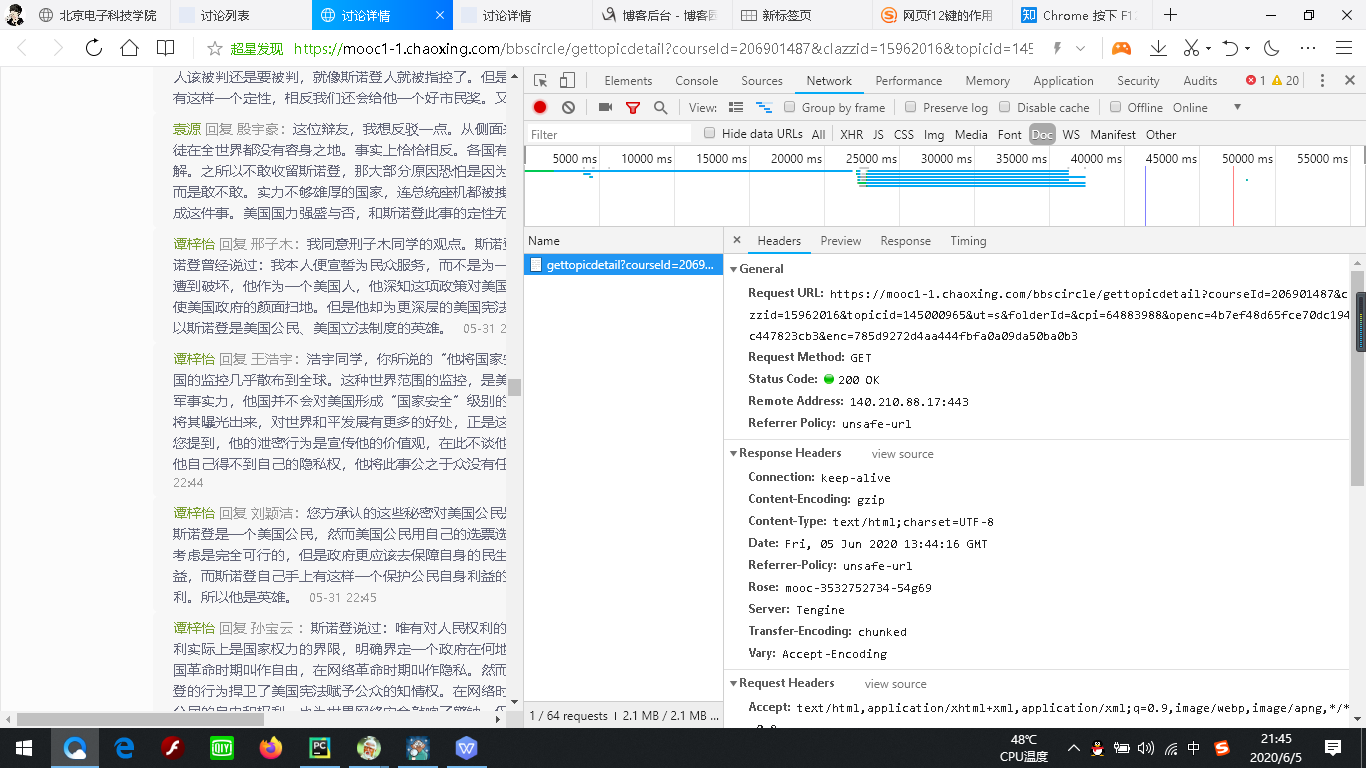
打开超星学习通,通过f12键调试网页,找到网页的URL(连接网页)、cookie(获取动态发布信息)以及user(将爬虫伪装为网页)。代码部分首先引入requests
BeautifulSoup两个库。编写代码:
a_url = "https://mooc1-1.chaoxing.com/bbscircle/gettopicdetail?courseId=206901487&clazzid=15962016&topicid=145000965&ut=s&folderId=&cpi=64883988&openc=4b7ef48d65fce70dc1949ac447823cb3&enc=785d9272d4aa444fbfa0a09da50ba0b3"
header = {'Cookie':'uname=20184202; lv=0; fid=1475; _uid=79428458; uf=b2d2c93beefa90dcd2acdbf1bc20f81a61dc81714e403dc9af4d07514b2e551f9469ea56b3f03155464b1f7b487b4b33c49d67c0c30ca5047c5a963e85f1109966fe123d0820032bfd68be96b6183b1a2f9d414f24b87d0a3ee444cafc1b08beb7fa16d299088874; _d=1590846261500; UID=79428458; vc=444FA102E2CCDEC3CAF169DDC433F446; vc2=71897EFCB1704E6320A75D0F7FC64B24; vc3=LJXG1aSeY9Qj%2BFjULbGDxGqjBHiwwp49gbK6%2BnRvZwLp7WFhei39ckTbELLOukeGk00kjOWvamCLCoGp2yXpBFrJ6Z3eIK8Y4EzBdR7xWoIMFCzpwlY%2BP2w0H6somr0vNp6OfC17kRhKk2AThx%2B4tS%2BEXsx94OZVrfD6XjNMArU%3De03acef409c7b9488c729e9d54fbe65e; xxtenc=de2bbc39b4b96e413fe4db2f4c5ef1c6; DSSTASH_LOG=C_38-UN_2146-US_79428458-T_1590846261502; tl=1; thirdRegist=0; source=""; k8s=8168719510de8752646593ff4d6c327ede1b6d44; route=f537d772be8122bff9ae56a564b98ff6; jrose=6213E16D15F4D6ABD1D4724394FA2C7C.mooc-3532752734-06dxz'
,'user-agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3741.400 QQBrowser/10.5.3863.400'
}
got = requests.get(a_url,headers = header)
got.encoding = "utf-8"
soup = BeautifulSoup(got.text,'html.parser')
2.找到发帖人姓名与内容
先在网页中选中要搜索的内容,即发帖人姓名与内容,这里的姓名与内容又分为有回复人与没有回复人。
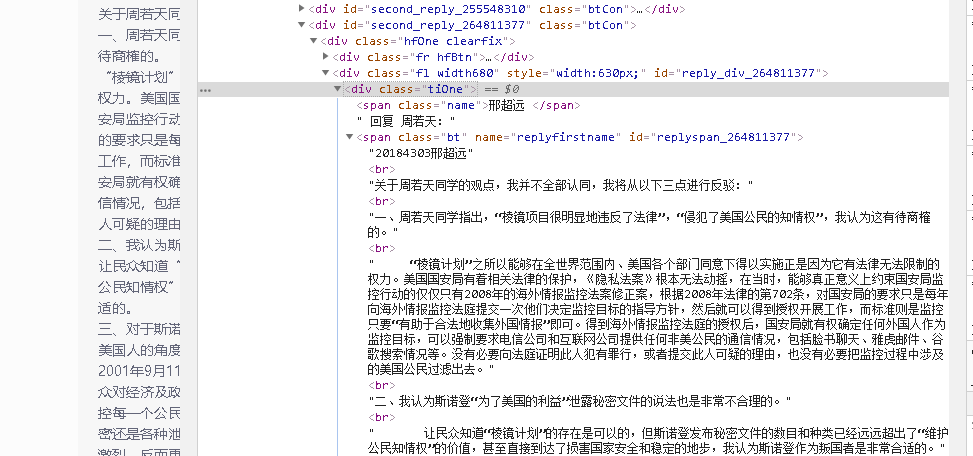
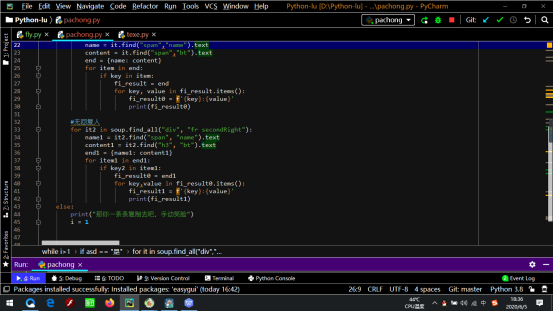
可以看到,有回复人的姓名与内容在网页源代码在<div class="tiOne">的范围内
姓名在<span class = "name">中
内容在<span class = "bt">中,因此遍历搜索代码为,随后把姓名与内容组合成字典,方便搜索

同样的方式找到无回复人的位置,然后编写代码

3.遍历输出搜索内容
我们在第二步中将所有的发帖人以及发帖内容全部以字典形式遍历了出来,接下来就是在这些内容中找到自己需要的内容。
在有回复中,通过一个判断语句,用发帖人姓名遍历出所有内容,代码如下:
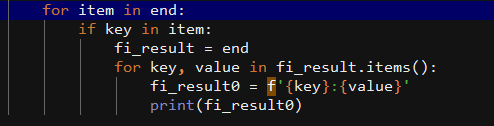
在无回复中,代码如下:
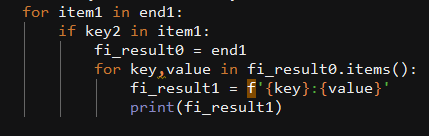
最后补一下循环和输入语句。
三、实验问题与解决方式
1.获取页面源代码失败
因为论坛的姓名与内容是动态的,所以只用user伪装只能爬取一些页面静态内容,解决方法是找到页面的cookie,就可以获取动态的内容了。
2.定位内容失败
用find找姓名与内容的位置遇到了很多问题,总是定位不到,最后看了许多视频,自己尝试后找到了方法
但在确定无回复人的帖子时,一开始的大范围定小了,所以定位不到内容。然后在不断尝试后找到了范围
3.两个遍历无法同时进行
因为我用的key变量最为搜索值,它在两个遍历中是一个公共变量,影响了代码的运行。所以又定义了一个变量key2=key作为
第二个遍历的变量
四、实验感想与课程建议
说实话,我挺喜欢自己做的这个爬虫的,因为我们的课程要求要把自己的讨论汇总,而我发了很多帖子,一条条复制
很麻烦,所以就想着做个爬虫直接帮我爬出来。这个程序我别的课也能用,换个网页的信息就行。当然,还有很大进步的空间
和其他同学做的程序依然有很大察觉。但我觉得我还是对自己这门课的学习成果挺满意,达到了我一开始选修这门课的目的。
对课程的建议是,可以在讲课的时候加一些具体的案例,或者加一些写游戏的内容,我觉得这样可以提高授课效果。
<div class="tiOne"><span class="name">邢超远 </span> 回复 周若天:<span class="bt" name="replyfirstname" id="replyspan_264811377">20184303邢超远<br>关于周若天同学的观点,我并不全部认同,我将从以下三点进行反驳:<br>一、周若天同学指出,“棱镜项目很明显地违反了法律”,“侵犯了美国公民的知情权”,我认为这有待商榷的。<br> “棱镜计划”之所以能够在全世界范围内、美国各个部门同意下得以实施正是因为它有法律无法限制的权力。美国国安局有着相关法律的保护,《隐私法案》根本无法动摇,在当时,能够真正意义上约束国安局监控行动的仅仅只有2008年的海外情报监控法案修正案,根据2008年法律的第702条,对国安局的要求只是每年向海外情报监控法庭提交一次他们决定监控目标的指导方针,然后就可以得到授权开展工作,而标准则是监控只要“有助于合法地收集外国情报”即可。得到海外情报监控法庭的授权后,国安局就有权确定任何外国人作为监控目标,可以强制要求电信公司和互联网公司提供任何非美公民的通信情况,包括脸书聊天、雅虎邮件、谷歌搜索情况等。没有必要向法庭证明此人犯有罪行,或者提交此人可疑的理由,也没有必要把监控过程中涉及的美国公民过滤出去。<br>二、我认为斯诺登“为了美国的利益”泄露秘密文件的说法也是非常不合理的。<br> 让民众知道“棱镜计划”的存在是可以的,但斯诺登发布秘密文件的数目和种类已经远远超出了“维护公民知情权”的价值,甚至直接到达了损害国家安全和稳定的地步,我认为斯诺登作为叛国者是非常合适的。<br>三、对于斯诺登是否是英雄,我认为我们角度不应该以自己——一位中国人的角度来看待,而应该从美国人的角度来看待。<br> 2001年9月11日,“911恐怖袭击事件”发生,此次事件对美国民众造成的心理影响极为深远,美国民众对经济及政治上的安全感均被严重削弱。那么如何保护美国公民的安全感,政府必须有所作为,而监控每一个公民的行为成为其中最重要的部分。美国公民是非常清楚政府的监控行为的。无论是从维基解密还是各种泄密人员如曼宁等,政府的监控早已有了很多的证据表明,而美国公民的做法并没有那么的激烈,反而更多的民众都在不断地抨击这些泄密的行为,连曼宁都是因为网友的举报被抓入狱。在采访斯诺登的记者格伦•格林沃尔德在《卫报》发表第二份关于“棱镜计划”文稿时,美国民众的看法并不是害怕和愤怒,而是惊讶,他们惊讶有人竟然泄露了如此绝密、泄露之后会非常威胁国家利益的文件,从中我们也能看出,美国绝大多数民众并没有那么抵制政府的监控行为。<br> 我认为,斯诺登成为美国人心中的英雄或许是因为他的行为在民众看来非常的正义,如漫威中的人物一样,而对于国家利益、公民利益方面来说,他是一名叛国者。</span><span style="font-size:12px;padding-left:10px">03-16 16:25</span></div>

 浙公网安备 33010602011771号
浙公网安备 33010602011771号