关于正则与函数
JSCORE JS 知识点 -新手入门
看完这篇文章能学到什么?
-
- 首先你会掌握很多 API, 其次可以封装一些你认为复用性强的 API。
-
- 你可能是基础,请先学习 JS 数据类型。 请参见: https://developer.mozilla.org/zh-CN/docs/Web/JavaScript/Guide/Regular_Expressions
我们需要了解一下什么是正则
-
- 为什么文章第一个知识点就是正则呢, 其实是因为我们在平常做用户验证的时候会大量用到正则。
-
- 什么是正则: 可以想象成就是验证字符串的一种规则
废话不多说直接开始
了解正则语法
- 正则特殊字符
> 下面是所有正则的特殊字符
> 字符 含义
> \
> 依照下列规则匹配:
在非特殊字符之前的反斜杠表示下一个字符是特殊字符,不能按照字面理解。例如,前面没有 "\" 的 "b" 通常匹配小写字母 "b",即字符会被作为字面理解,无论它出现在哪里。但如果前面加了 "\",它将不再匹配任何字符,而是表示一个字符边界。
在特殊字符之前的反斜杠表示下一个字符不是特殊字符,应该按照字面理解。详情请参阅下文中的 "转义(Escaping)" 部分。
如果你想将字符串传递给 RegExp 构造函数,不要忘记在字符串字面量中反斜杠是转义字符。所以为了在模式中添加一个反斜杠,你需要在字符串字面量中转义它。/[a-z]\s/i 和 new RegExp("[a-z]\\s", "i") 创建了相同的正则表达式:一个用于搜索后面紧跟着空白字符(\s 可看后文)并且在 a-z 范围内的任意字符的表达式。为了通过字符串字面量给 RegExp 构造函数创建包含反斜杠的表达式,你需要在字符串级别和正则表达式级别都对它进行转义。例如 /[a-z]:\\/i 和 new RegExp("[a-z]:\\\\","i") 会创建相同的表达式,即匹配类似 "C:\" 字符串。
^
匹配输入的开始。如果多行标志被设置为 true,那么也匹配换行符后紧跟的位置。
例如,/^A/ 并不会匹配 "an A" 中的 'A',但是会匹配 "An E" 中的 'A'。
当 '^' 作为第一个字符出现在一个字符集合模式时,它将会有不同的含义。反向字符集合 一节有详细介绍和示例。
$
匹配输入的结束。如果多行标志被设置为 true,那么也匹配换行符前的位置。
例如,/t$/ 并不会匹配 "eater" 中的 't',但是会匹配 "eat" 中的 't'。
- 匹配前一个表达式 0 次或多次。等价于 {0,}。
例如,/bo\*/ 会匹配 "A ghost boooooed" 中的 'booooo' 和 "A bird warbled" 中的 'b',但是在 "A goat grunted" 中不会匹配任何内容。
- 匹配前面一个表达式 1 次或者多次。等价于 {1,}。
例如,/a+/ 会匹配 "candy" 中的 'a' 和 "caaaaaaandy" 中所有的 'a',但是在 "cndy" 中不会匹配任何内容。
?
匹配前面一个表达式 0 次或者 1 次。等价于 {0,1}。
例如,/e?le?/ 匹配 "angel" 中的 'el'、"angle" 中的 'le' 以及 "oslo' 中的 'l'。
如果紧跟在任何量词 \*、 +、? 或 {} 的后面,将会使量词变为非贪婪(匹配尽量少的字符),和缺省使用的贪婪模式(匹配尽可能多的字符)正好相反。例如,对 "123abc" 使用 /\d+/ 将会匹配 "123",而使用 /\d+?/ 则只会匹配到 "1"。
还用于先行断言中,如本表的 x(?=y) 和 x(?!y) 条目所述。
.
(小数点)默认匹配除换行符之外的任何单个字符。
例如,/.n/ 将会匹配 "nay, an apple is on the tree" 中的 'an' 和 'on',但是不会匹配 'nay'。
如果 s ("dotAll") 标志位被设为 true,它也会匹配换行符。
(x)
像下面的例子展示的那样,它会匹配 'x' 并且记住匹配项。其中括号被称为捕获括号。
模式 /(foo) (bar) \1 \2/ 中的 '(foo)' 和 '(bar)' 匹配并记住字符串 "foo bar foo bar" 中前两个单词。模式中的 \1 和 \2 表示第一个和第二个被捕获括号匹配的子字符串,即 foo 和 bar,匹配了原字符串中的后两个单词。注意 \1、\2、...、\n 是用在正则表达式的匹配环节,详情可以参阅后文的 \n 条目。而在正则表达式的替换环节,则要使用像 $1、$2、...、$n 这样的语法,例如,'bar foo'.replace(/(...) (...)/, '$2 $1')。$& 表示整个用于匹配的原字符串。
(?:x)
匹配 'x' 但是不记住匹配项。这种括号叫作非捕获括号,使得你能够定义与正则表达式运算符一起使用的子表达式。看看这个例子 /(?:foo){1,2}/。如果表达式是 /foo{1,2}/,{1,2} 将只应用于 'foo' 的最后一个字符 'o'。如果使用非捕获括号,则 {1,2} 会应用于整个 'foo' 单词。更多信息,可以参阅下文的 Using parentheses 条目.
x(?=y)
匹配'x'仅仅当'x'后面跟着'y'.这种叫做先行断言。
例如,/Jack(?=Sprat)/会匹配到'Jack'仅当它后面跟着'Sprat'。/Jack(?=Sprat|Frost)/匹配‘Jack’仅当它后面跟着'Sprat'或者是‘Frost’。但是‘Sprat’和‘Frost’都不是匹配结果的一部分。
(?<=y)x
匹配'x'仅当'x'前面是'y'.这种叫做后行断言。
例如,/(?<=Jack)Sprat/会匹配到' Sprat '仅仅当它前面是' Jack '。/(?<=Jack|Tom)Sprat/匹配‘ Sprat ’仅仅当它前面是'Jack'或者是‘Tom’。但是‘Jack’和‘Tom’都不是匹配结果的一部分。
x(?!y)
仅仅当'x'后面不跟着'y'时匹配'x',这被称为正向否定查找。
例如,仅仅当这个数字后面没有跟小数点的时候,/\d+(?!\.)/ 匹配一个数字。正则表达式/\d+(?!\.)/.exec("3.141")匹配‘141’而不是‘3.141’
(?<!y)x
仅仅当'x'前面不是'y'时匹配'x',这被称为反向否定查找。
例如, 仅仅当这个数字前面没有负号的时候,/(?<!-)\d+/ 匹配一个数字。
/(?<!-)\d+/.exec('3') 匹配到 "3".
/(?<!-)\d+/.exec('-3') 因为这个数字前有负号,所以没有匹配到。
x|y
匹配‘x’或者‘y’。
例如,/green|red/匹配“green apple”中的‘green’和“red apple”中的‘red’
{n} n 是一个正整数,匹配了前面一个字符刚好出现了 n 次。
比如, /a{2}/ 不会匹配“candy”中的'a',但是会匹配“caandy”中所有的 a,以及“caaandy”中的前两个'a'。
{n,}
n 是一个正整数,匹配前一个字符至少出现了 n 次。
例如, /a{2,}/ 匹配 "aa", "aaaa" 和 "aaaaa" 但是不匹配 "a"。
{n,m}
n 和 m 都是整数。匹配前面的字符至少 n 次,最多 m 次。如果 n 或者 m 的值是 0, 这个值被忽略。
例如,/a{1, 3}/ 并不匹配“cndy”中的任意字符,匹配“candy”中的 a,匹配“caandy”中的前两个 a,也匹配“caaaaaaandy”中的前三个 a。注意,当匹配”caaaaaaandy“时,匹配的值是“aaa”,即使原始的字符串中有更多的 a。
[xyz] 一个字符集合。匹配方括号中的任意字符,包括转义序列。你可以使用破折号(-)来指定一个字符范围。对于点(.)和星号(\*)这样的特殊符号在一个字符集中没有特殊的意义。他们不必进行转义,不过转义也是起作用的。
例如,[abcd] 和[a-d]是一样的。他们都匹配"brisket"中的‘b’,也都匹配“city”中的‘c’。/[a-z.]+/ 和/[\w.]+/与字符串“test.i.ng”匹配。
[^xyz]
一个反向字符集。也就是说, 它匹配任何没有包含在方括号中的字符。你可以使用破折号(-)来指定一个字符范围。任何普通字符在这里都是起作用的。
例如,[^abc] 和 [^a-c] 是一样的。他们匹配"brisket"中的‘r’,也匹配“chop”中的‘h’。
[\b]
匹配一个退格(U+0008)。(不要和\b 混淆了。)
\b
匹配一个词的边界。一个词的边界就是一个词不被另外一个“字”字符跟随的位置或者前面跟其他“字”字符的位置,例如在字母和空格之间。注意,匹配中不包括匹配的字边界。换句话说,一个匹配的词的边界的内容的长度是 0。(不要和[\b]混淆了)
使用"moon"举例:
/\bm/匹配“moon”中的‘m’;
/oo\b/并不匹配"moon"中的'oo',因为'oo'被一个“字”字符'n'紧跟着。
/oon\b/匹配"moon"中的'oon',因为'oon'是这个字符串的结束部分。这样他没有被一个“字”字符紧跟着。
/\w\b\w/将不能匹配任何字符串,因为在一个单词中间的字符永远也不可能同时满足没有“字”字符跟随和有“字”字符跟随两种情况。
注意: JavaScript 的正则表达式引擎将特定的字符集定义为“字”字符。不在该集合中的任何字符都被认为是一个断词。这组字符相当有限:它只包括大写和小写的罗马字母,十进制数字和下划线字符。不幸的是,重要的字符,例如“é”或“ü”,被视为断词。
\B
匹配一个非单词边界。匹配如下几种情况:
字符串第一个字符为非“字”字符
字符串最后一个字符为非“字”字符
两个单词字符之间
两个非单词字符之间
空字符串
例如,/\B../匹配"noonday"中的'oo', 而/y\B../匹配"possibly yesterday"中的’yes‘
\cX
当 X 是处于 A 到 Z 之间的字符的时候,匹配字符串中的一个控制符。
例如,/\cM/ 匹配字符串中的 control-M (U+000D)。
\d
匹配一个数字。等价于[0-9]。
例如, /\d/ 或者 /[0-9]/ 匹配"B2 is the suite number."中的'2'。
\D
匹配一个非数字字符。等价于[^0-9]。
例如, /\D/ 或者 /[^0-9]/ 匹配"B2 is the suite number."中的'B' 。
\f 匹配一个换页符 (U+000C)。
\n 匹配一个换行符 (U+000A)。
\r 匹配一个回车符 (U+000D)。
\s
匹配一个空白字符,包括空格、制表符、换页符和换行符。等价于[ \f\n\r\t\v\u00a0\u1680\u180e\u2000-\u200a\u2028\u2029\u202f\u205f\u3000\ufeff]。
例如, /\s\w\*/ 匹配"foo bar."中的' bar'。
经测试,\s 不匹配"\u180e",在当前版本 Chrome(v80.0.3987.122)和 Firefox(76.0.1)控制台输入/\s/.test("\u180e")均返回 false。
\S
匹配一个非空白字符。等价于 [^ \f\n\r\t\v\u00a0\u1680\u180e\u2000-\u200a\u2028\u2029\u202f\u205f\u3000\ufeff]。
例如,/\S\w\*/ 匹配"foo bar."中的'foo'。
\t 匹配一个水平制表符 (U+0009)。
\v 匹配一个垂直制表符 (U+000B)。
\w
匹配一个单字字符(字母、数字或者下划线)。等价于 [A-Za-z0-9_]。
例如, /\w/ 匹配 "apple," 中的 'a',"$5.28,"中的 '5' 和 "3D." 中的 '3'。
\W
匹配一个非单字字符。等价于 [^a-za-z0-9_]。
例如, /\W/ 或者 /[^a-za-z0-9_]/ 匹配 "50%." 中的 '%'。
\n
在正则表达式中,它返回最后的第 n 个子捕获匹配的子字符串(捕获的数目以左括号计数)。
比如 /apple(,)\sorange\1/ 匹配"apple, orange, cherry, peach."中的'apple, orange,' 。
\0 匹配 NULL(U+0000)字符, 不要在这后面跟其它小数,因为 \0<digits> 是一个八进制转义序列。
\xhh 匹配一个两位十六进制数(\x00-\xFF)表示的字符。
\uhhhh 匹配一个四位十六进制数表示的 UTF-16 代码单元。
\u{hhhh}或\u{hhhhh}
(仅当设置了 u 标志时)匹配一个十六进制数表示的 Unicode 字符。
文档地址:https://developer.mozilla.org/zh-CN/docs/Web/JavaScript/Guide/Regular_Expressions
- 我们了解一下正则语法。
// 一. 创建一个 正则对象
let re = new RegExp("1");
// 验证是否存在 "1"如果存在返回true 如果不存在返回false
re.test("133")
// 二。 创建正则对象
/1/.test('2331')
/1/ // 就是在创建一个正则对象
"//" // 里面必须有字符否则会被解析器解析为注释
替换
-
匹配一个, 匹配到替换成参数二的字符串, 值得注意的是: replace 是字符串的方法。
"11777177171771".replace(/1/, "😄")
-
匹配所有并替换
"11777177171771".replace(/1/g, "😄")
-
匹配大小写并替换
"11777177171771".replace(/1/gi, "😄")
匹配单次
-
只匹配一次, 匹配到然后返回匹配到的数据, 值得注意的是:返回的结果是一个数组
"11777177171771".match(/1/)
-
匹配所有
"11777177171771".match(/1/g)
全局匹配并匹配大小写: "1177717717QQqqqq1".match(/q/ig)
匹配大小写
> 修饰符 `i` 忽略大小写
> 修饰符 `g` 全局匹配
> `new RegExp("q", 'ig').match("QqqssQQqsss") 可以吧修饰符写到第二个参数内`
匹配一次返回, 调用一此匹配一次
const regex1 = RegExp("foo*", "g");
const str1 = "table football, foosball";
let array1;
while ((array1 = regex1.exec(str1)) !== null) {
console.log(
`Found ${array1[0]}. 下一次开始的索引: ${regex1.lastIndex}.`,
array1
);
}
函数
函数的声明及 ES 的回调函数
- 函数的声明
// 创建一个函数对象
// ES6 新特性 函数可以声明一个默认值, 如果不传参会使用默认值
function fn1(a=1){
console.log(a)
}
> 调用及传参
fn(1)
> 箭头函数
let fn2 = (a=1) => {
console.log(a)
}
> 调用及传参
fn(1)
函数重载
此概念,来自 C 语言,根据传入的参数不同从而,进行不同的操作
在一个函数都可以打印 arguments 变量, 他先是隐藏声明的一样
// 这是一个函数自调用的写法
(function () {
console.log(arguments);
})();
声明提升
-
提升会导致 JS 可调用函数/变量的顺序
-
一个 var, let, const, function 存在声明提升
-
提升的现象是在 提词器与解析器之间的与预解析阶段进行提升的。
-
提升会分为三步:
1. 声明 2. 赋值为undefined 3. 赋值具体值var的提升 止步在第二阶段
let/const的提升 止步在第一阶段
function的提升 会完成三个阶段 -
实例
// 输出undefined 说明提升至第两个阶段
console.log(a)
var a = 1
// 报错: 不可在赋值之前调用, 提升至第一个阶段
console.log(a)
let a = 1
// 执行成功 提升了三个阶段
fn()
funtion fn(){
console.log(1)
}
作用域
- 函数内是一块独立的区域
- var声明的变量在函数内会有一块单独的区域进行存储
- 对于let声明的变量来说具有一块独立的区域进行存储script 区域 可以使用断点工具查看, 在
{}内声明的只能在{}号内调用 - 所谓的作用域其实指的是一块区域, 在这块区域的变量,可以任意调用,出了这块区域 JS 的
GC垃圾回收器就会将其清除
作用域链
-
作用域指是 JS 解析器查找变量的过程
-
如果有一个函数,函数内又有一层函数, 现在的查找的历程
比如在最函数内的那一层函数调用 window 区域的变量, 函数调用是会一层层往上级查找, 直到查找为止,如果查到window这一层还没有查到才会报错 -
代码实例
var a = 1; function fn() { function inner() { // 一层层查找, 如果fn这一层没有就会查找到 window 下 console.log(a); } inner(); }
闭包
- 所有函数你的变量会存储在 Scopes区域
var a = 1;
function fn() {
let s = 2;
function inner() {
console.dir(inner);
console.dir(s);
}
inner();
}
fn();

-
蓝色字体描述的就是为什么GC(垃圾会后机制)没有清除外层函数内声明的变量
-
其实存储到了Scopes区域, 不管如何是不会导致程序报错的, 也不会污染全局变量
-
在后续的VUE框架中, 作者在封装框架时也大量应用了闭包
-
闭包的应用场景请参见防抖与节流
防抖与节流
-
防抖的应用场景
-
实时监听input框的输入是:
oninput -
现在有这么一个场景, 想必你应该用过百度, 百度的实时搜索就用到了闭包
-
为什么呢? 你应该知道input的监听是实时的,
用户输入一个字符就会触发一次事件, 这样如果事件函数是发送请求的函数, 这不就费啦。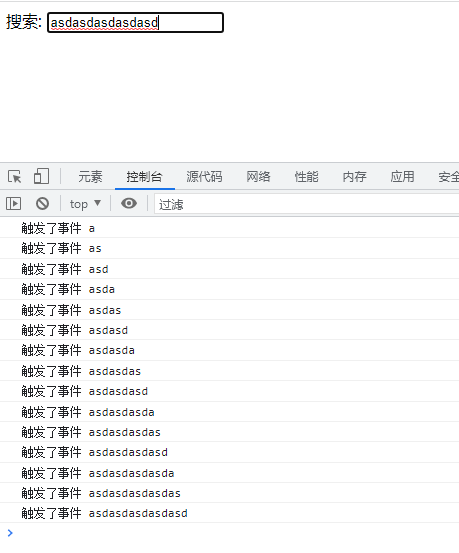
-
-
说了这么多,不废话了, 直接上码子!
- 我们要做的是:要限制用户,在请求回来之前不触发, 发送请求的代码
搜索: <input oninput="bindInputInner()" /> <script> function bindInput() { let ipt = document.querySelector("input"); let timer = null; return () => { if (timer) { clearTimeout(timer); } // 300ms内不触发函数就会发送请求, 如果触发了就会进入上层判断 清空定时器 timer = setTimeout(() => { // 发送请求代码 console.log("触发了事件", ipt.value); // 收到结果后修改为初始值 timer = null; }, 300); }; } let bindInputInner = bindInput(); </script> -
节流场景
- 搜索按钮 当请求没有回来之前做一个现在让用户点了不触发发送请求的代码
<input type="button" onclick="bindInputInner()" value="搜索" /> <script> function bindInput() { // 控制是否可以点击 let isClick = true; // 返回一个函数 调用外层函数后可以继续加()调用内层函数 // 如果第一次进来这个函数 会触发一次事件 发现isClick 为真,会发送请求, // 在请求发送成功之前是 isClick 一直等于false的 所以一直进入不了 过不了判断 return () => { if (!isClick) return; console.log("进入", isClick); isClick = false; // 模拟异步请求 setTimeout(() => { console.log("收到了请求结果", isClick); isClick = true; }, 2000); }; } let bindInputInner = bindInput(); </script>

 浙公网安备 33010602011771号
浙公网安备 33010602011771号