
接着上一篇博客接着来讲如何用scrapy来爬取房源信息
scrapy官方文档:https://scrapy-chs.readthedocs.io/zh_CN/latest/index.html (随便翻翻就可以,我开始看了好几天也没弄明白什么意思)不推荐!!
网络课程:https://study.163.com/course/courseMain.htm?courseId=1003666043
个人博客:https://cuiqingcai.com/3472.html(强烈推荐哎呀卧槽哥的文章,写的超级详细,对新手很友好)推荐!!!!!!!
关于如何创建项目,请参考上面的大神博客。
创建好的项目长这样:
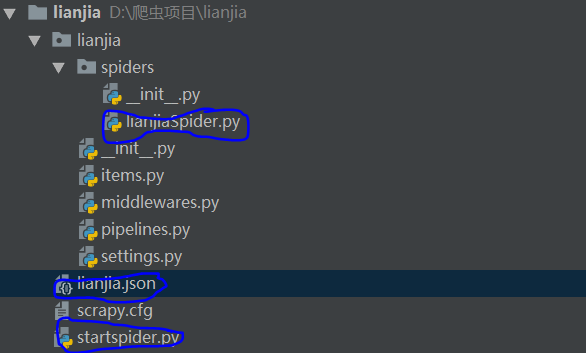
这三个圈圈里面的内容是后来生成的。
步骤如下:
一:准备工作
因为Scrapy默认是不能在IDE中调试的,我们在根目录中新建一个py文件叫startspider,作为整个爬虫的启动程序
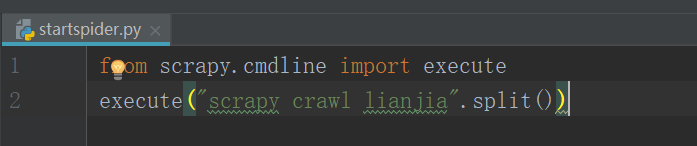
只有两行,很简单。。
然后在spiders目录下创建一个名叫lianjiaspider文件,里面放的是爬虫的解析网页提取指定内容的程序。
二:编写items文件
import scrapy class LianjiaItem(scrapy.Item): # define the fields for your item here like: name = scrapy.Field() huxing = scrapy.Field() area = scrapy.Field() totalprice = scrapy.Field()
里面主要定义我们想提取的内容,注意只有等号前面不一样,后面的都是一样的,不要问为什么,框架就是类似一个架子,只需要往里面填充东西即可。
三:编写lianjiaspider文件
注意:这是整个爬虫文件的重点。
提取指定内容用的是xpath
import scrapy from lianjia.items import LianjiaItem class LianjiaSpider(scrapy.Spider): name = "lianjia" #设置name ,name必须唯一 url = "https://bj.lianjia.com/ershoufang/pg" offset = 1 start_urls = [url+str(offset)] #这三行是描述启动的Url def parse(self, response): for each in response.xpath("//li[@class='clear LOGCLICKDATA']"): #提取所有的li标签 item = LianjiaItem() #固定写法 item["name"] = each.xpath(".//div[@class='houseInfo']/a/text()").extract()[0] item["huxing"] = each.xpath(".//div[@class='houseInfo']/text()").extract()[0] item["area"] = each.xpath(".//div[@class='houseInfo']/text()").extract()[1] item["totalprice"] = each.xpath(".//div[@class='totalPrice']/span/text()").extract()[0] yield item if self.offset < 100: self.offset += 1 yield scrapy.Request(self.url+str(self.offset),callback=self.parse) #yield作为回调函数
四: 编写pipelines文件
import json class LianjiaPipeline(object): def __init__(self): self.file = open("lianjia.json","wb") #打开文件 def process_item(self, item, spider): content = json.dumps(dict(item),ensure_ascii=False)+",\n" self.file.write(content.encode("utf-8")) return item def spider_close(self,spider): #关闭文件 self.file.close()
五:设置setting

设置header头
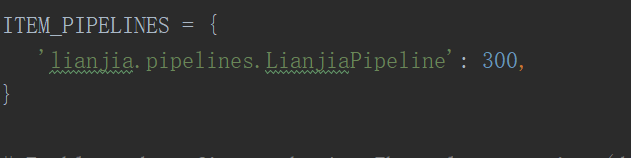
注销pipelines注释
这样的话,整个爬虫就可以顺利的进行。
但是本人第一次爬取的时候出问题了,因为scrapy是严格遵守robots协议的,但是链家除了有限的几个爬虫,其他爬虫全部禁止爬取内容
所以我们需要在setting 里面将
ROBOTSTXT_OBEY = True 的true改为False
即不遵守机器人协议
最终爬取的内容如下(只显示了一部分内容,数据太多了):
{"name": "新桥路小区 ", "huxing": "2室1厅", "area": "63.87平米", "totalprice": "239"},
{"name": "舒至嘉园 ", "huxing": "2室1厅", "area": "100.53平米", "totalprice": "900"},
{"name": "远洋一方润园2号院 ", "huxing": "2室1厅", "area": "86.04平米", "totalprice": "508"},
{"name": "望京花园西区 ", "huxing": "2室1厅", "area": "85.27平米", "totalprice": "585"},
{"name": "风景club ", "huxing": "3室1厅", "area": "124.03平米", "totalprice": "918"},
{"name": "天兆家园 ", "huxing": "4室2厅", "area": "171.59平米", "totalprice": "1790"},
{"name": "天通苑北一区 ", "huxing": "2室1厅", "area": "112.74平米", "totalprice": "460"},
{"name": "新龙城 ", "huxing": "3室1厅", "area": "113.19平米", "totalprice": "615"},
{"name": "望京新城 ", "huxing": "3室1厅", "area": "96.8平米", "totalprice": "710"},
{"name": "南露园 ", "huxing": "2室1厅", "area": "78.3平米", "totalprice": "860"},
这个实例可以给新手练下手。。。
不足之处还望不吝赐教。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号