数据采集作业2
作业2
仓库链接:https://gitee.com/jyppx000/crawl_project
作业①
要求:在中国气象网(http://www.weather.com.cn)给定城市集的7日天气预报,并保存在数据库。
仓库链接:https://gitee.com/jyppx000/crawl_project/tree/master/作业2/1
1.1 代码和图片
import pymysql
import requests
from bs4 import BeautifulSoup
db_config = {
'host': '127.0.0.1', # 数据库主机地址
'user': 'root', # 数据库用户名
'password': '123', # 数据库密码
'database': 'weather', # 数据库名称
'charset': 'utf8' # 字符集
}
def get_weather_data(city_code):
"""根据城市代码获取天气数据
:param city_code: 城市的代码
:return: 天气数据列表
"""
url = f'http://www.weather.com.cn/weather/{city_code}.shtml' # 构建请求的URL
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
response = requests.get(url, headers=headers) # 发送HTTP请求
response.encoding = 'utf-8' # 设置编码
# 使用 BeautifulSoup 解析网页内容
soup = BeautifulSoup(response.text, 'html.parser')
forecast = soup.find_all('li', class_='sky') # 找到天气预报的标签
weather_data = [] # 初始化天气数据列表
for day in forecast:
date = day.h1.text
weather = day.find('p', class_='wea').text
temp = day.find('p', class_='tem').text.strip()
wind = day.find('p', class_='win').find('i').text
weather_data.append({ # 将天气信息添加到列表
'date': date,
'weather': weather,
'temperature': temp,
'wind': wind
})
return weather_data # 返回天气数据列表
# 将天气数据保存到数据库
def save_weather_to_db(weather_data, city_name):
"""将天气数据保存到数据库
:param weather_data: 天气数据列表
:param city_name: 城市名称
"""
conn = None
cursor = None
try:
# 连接数据库
conn = pymysql.connect(**db_config)
cursor = conn.cursor() # 创建游标
# 创建表(如果不存在)
create_table_sql = f"""
CREATE TABLE IF NOT EXISTS {city_name}_weather (
id INT AUTO_INCREMENT PRIMARY KEY,
date VARCHAR(50),
weather VARCHAR(50),
temperature VARCHAR(50),
wind VARCHAR(50)
)
"""
cursor.execute(create_table_sql)
# 插入天气数据
for data in weather_data: #
insert_sql = f"""
INSERT INTO {city_name}_weather (date, weather, temperature, wind)
VALUES (%s, %s, %s, %s)
"""
cursor.execute(insert_sql, (data['date'], data['weather'], data['temperature'], data['wind']))
# 提交事务
conn.commit()
except Exception as e:
print(f"Error: {e}")
if conn:
conn.rollback()
finally:
if cursor:
cursor.close()
if conn:
conn.close()
city_code = '101230101'
city_name = 'fuzhou'
weather_data = get_weather_data(city_code)
save_weather_to_db(weather_data, city_name)
print("保存成功")
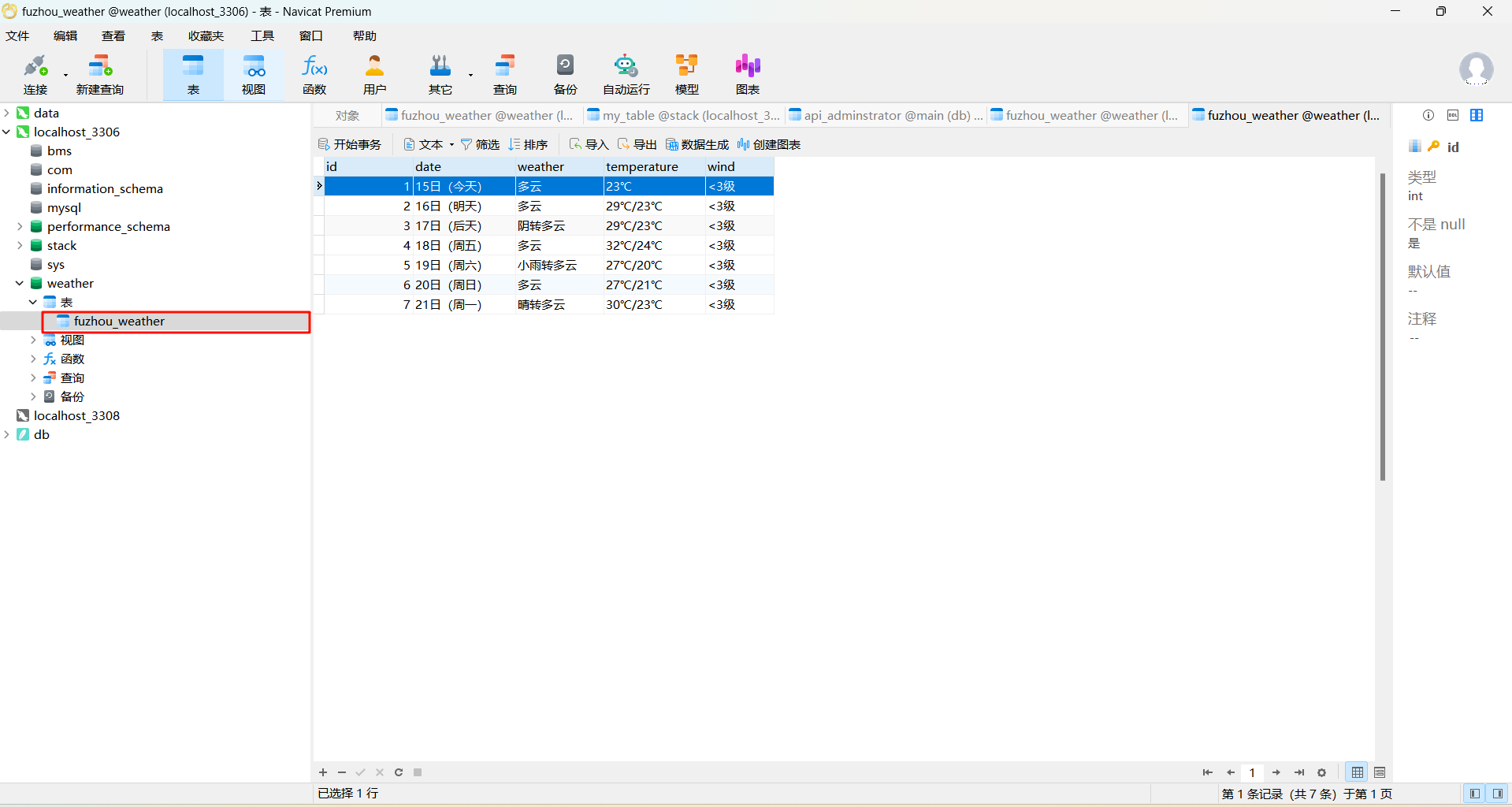
1.2 作业心得
- 巩固了我在数据库写原生sql的相关知识,eg:连接、查询和数据插入操作
- 巩固了
BeautifulSoup库的使用 - 最后仍然是代码中处理异常
作业②
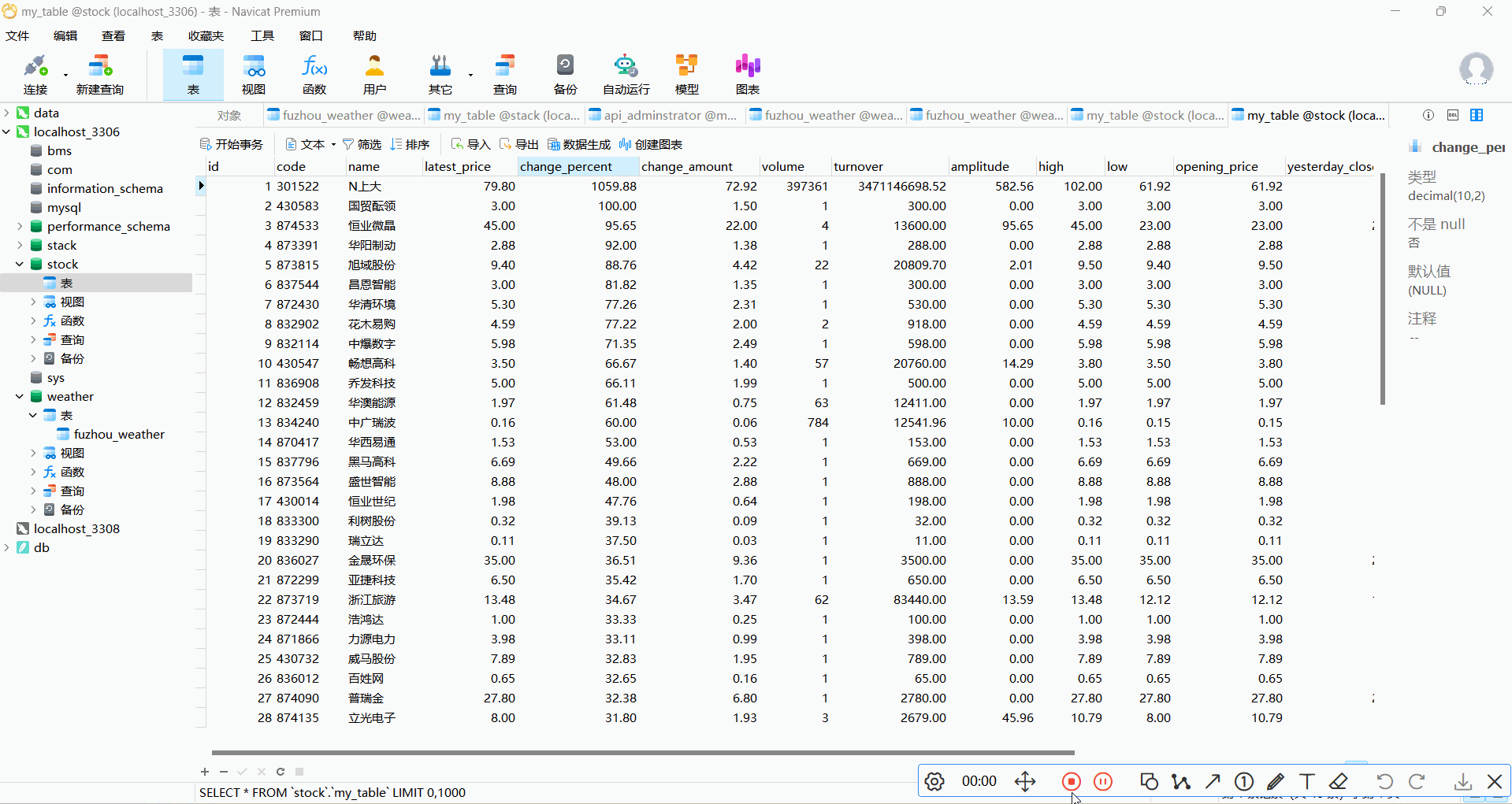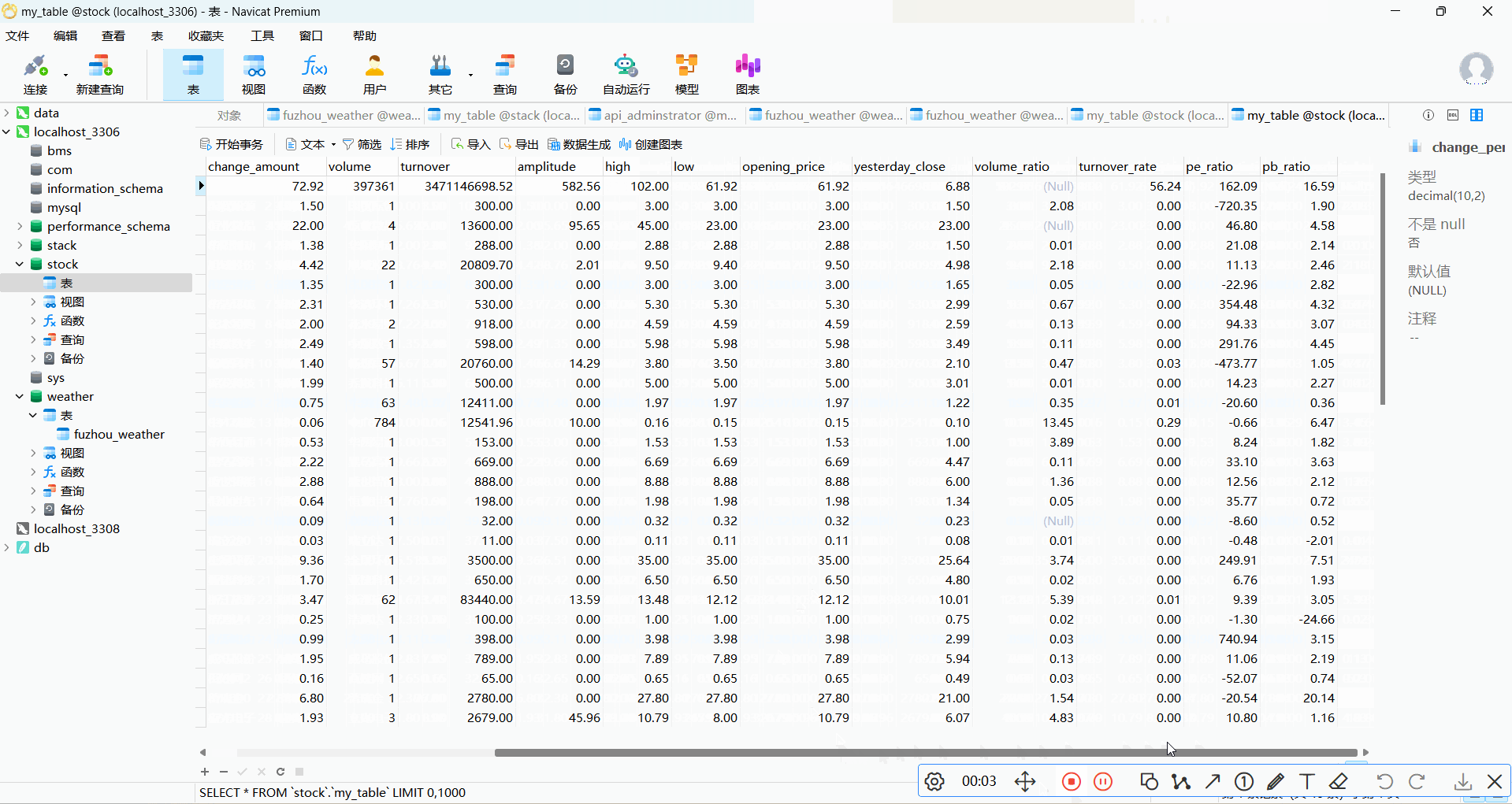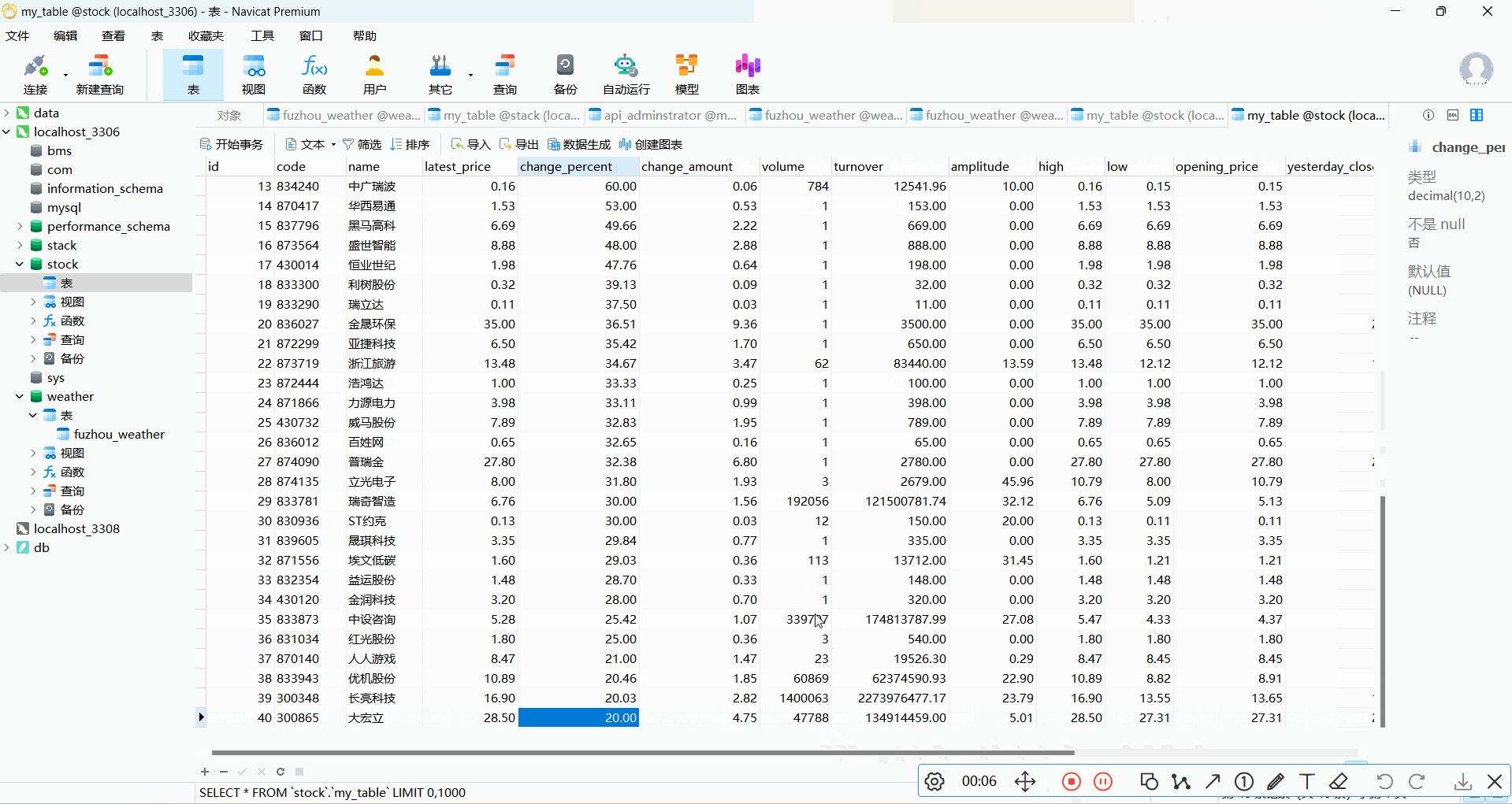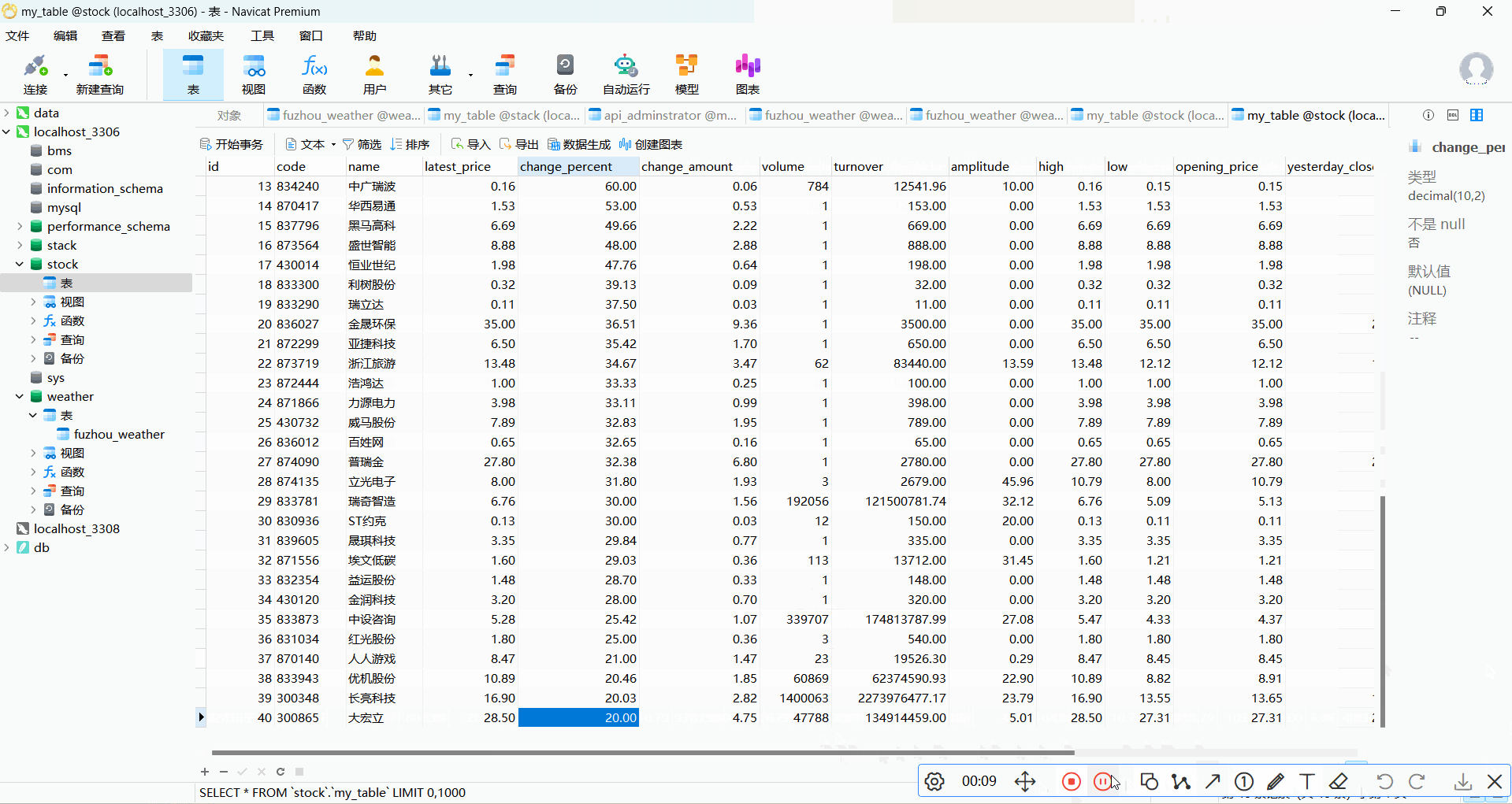
要求:用requests和BeautifulSoup库方法定向爬取股票相关信息,并存储在数据库中。
仓库链接:作业2/2 · 高涛/2024数据采集与融合技术 - 码云 - 开源中国 (gitee.com)
2.1 代码和图片
import json
import pymysql
import requests
# 数据库配置
db_config = {
'host': '127.0.0.1',
'user': 'root',
'password': '123',
'database': 'stock',
'charset': 'utf8'
}
def create_database_connection():
"""创建并返回数据库连接和游标"""
conn = pymysql.connect(**db_config)
cursor = conn.cursor()
return conn, cursor
def setup_database(cursor):
"""设置数据库表结构"""
cursor.execute('''
CREATE TABLE IF NOT EXISTS my_table (
id INT PRIMARY KEY AUTO_INCREMENT,
code VARCHAR(20),
name VARCHAR(100),
latest_price DECIMAL(10, 2),
change_percent DECIMAL(10, 2),
change_amount DECIMAL(10, 2),
volume BIGINT,
turnover DECIMAL(15, 2),
amplitude DECIMAL(10, 2),
high DECIMAL(10, 2),
low DECIMAL(10, 2),
opening_price DECIMAL(10, 2),
yesterday_close DECIMAL(10, 2),
volume_ratio DECIMAL(10, 2),
turnover_rate DECIMAL(10, 2),
pe_ratio DECIMAL(10, 2),
pb_ratio DECIMAL(10, 2)
)
''')
def fetch_data(page):
"""从指定页面获取数据"""
url = f'http://76.push2.eastmoney.com/api/qt/clist/get?cb=jQuery112405166990298085778_1696666115151&pn={page}&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&wbp2u=|0|0|0|web&fid=f3&fs=m:0+t:6,m:0+t:80,m:1+t:2,m:1+t:23,m:0+t:81&s:2048&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152&_=1696666115152'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36 Edg/117.0.2045.47',
'Cookie': 'qgqp_b_id=a7c5d47be8ad882fee56fc695bab498d; st_si=17803153105309; st_asi=delete; HAList=ty-0-300045-%u534E%u529B%u521B%u901A; st_pvi=56620321867111; st_sp=2023-10-07%2015%3A19%3A51; st_inirUrl=https%3A%2F%2Fwww.eastmoney.com%2F; st_sn=52; st_psi=20231007155656228-113200301321-9129123788'
}
response = requests.get(url, headers=headers)
data = response.text
start = data.find('(')
end = data.rfind(')')
json_data = json.loads(data[start + 1:end])
return json_data['data']['diff']
def insert_data(cursor, data):
"""将获取的数据插入到数据库中"""
# 根据实际API数据结构调整plist
plist = ['f12', 'f2', 'f3', 'f4', 'f5', 'f6', 'f7', 'f15', 'f16', 'f17', 'f18', 'f10', 'f8', 'f9', 'f23']
for item in data:
row = []
# 提取每一项的数据
for j in plist:
value = item.get(j, None)
if value in ['-', 'N上大', 'N/A']:
row.append(None)
else:
try:
row.append(float(value))
except ValueError:
row.append(None)
name = item.get('f14', None)
row.insert(1, name)
if len(row) == 16:
cursor.execute('''
INSERT INTO my_table (code, name, latest_price, change_percent, change_amount, volume, turnover, amplitude, high, low, opening_price, yesterday_close, volume_ratio, turnover_rate, pe_ratio, pb_ratio)
VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)
''', row)
else:
print(f"插入失败,数据长度不匹配: {row},长度: {len(row)}")
def main():
"""入口"""
# 创建数据库连接
conn, cursor = create_database_connection()
setup_database(cursor)
keypage = input(">>>>>>>>>>请输入爬取页面:")
searchlist = list(map(int, keypage.split()))
try:
for page in searchlist:
data = fetch_data(page)
insert_data(cursor, data)
conn.commit()
except Exception as e:
print(f"发生错误: {e}")
finally:
print("保存成功")
cursor.close()
conn.close()
if __name__ == '__main__':
main()
2.2 作业心得
- 我学习到通过分析 API 返回的数据结构,如何使用 JSON 格式解析数据,并将其存入数据库
- 异常处理既好用,又很重要!
作业③:
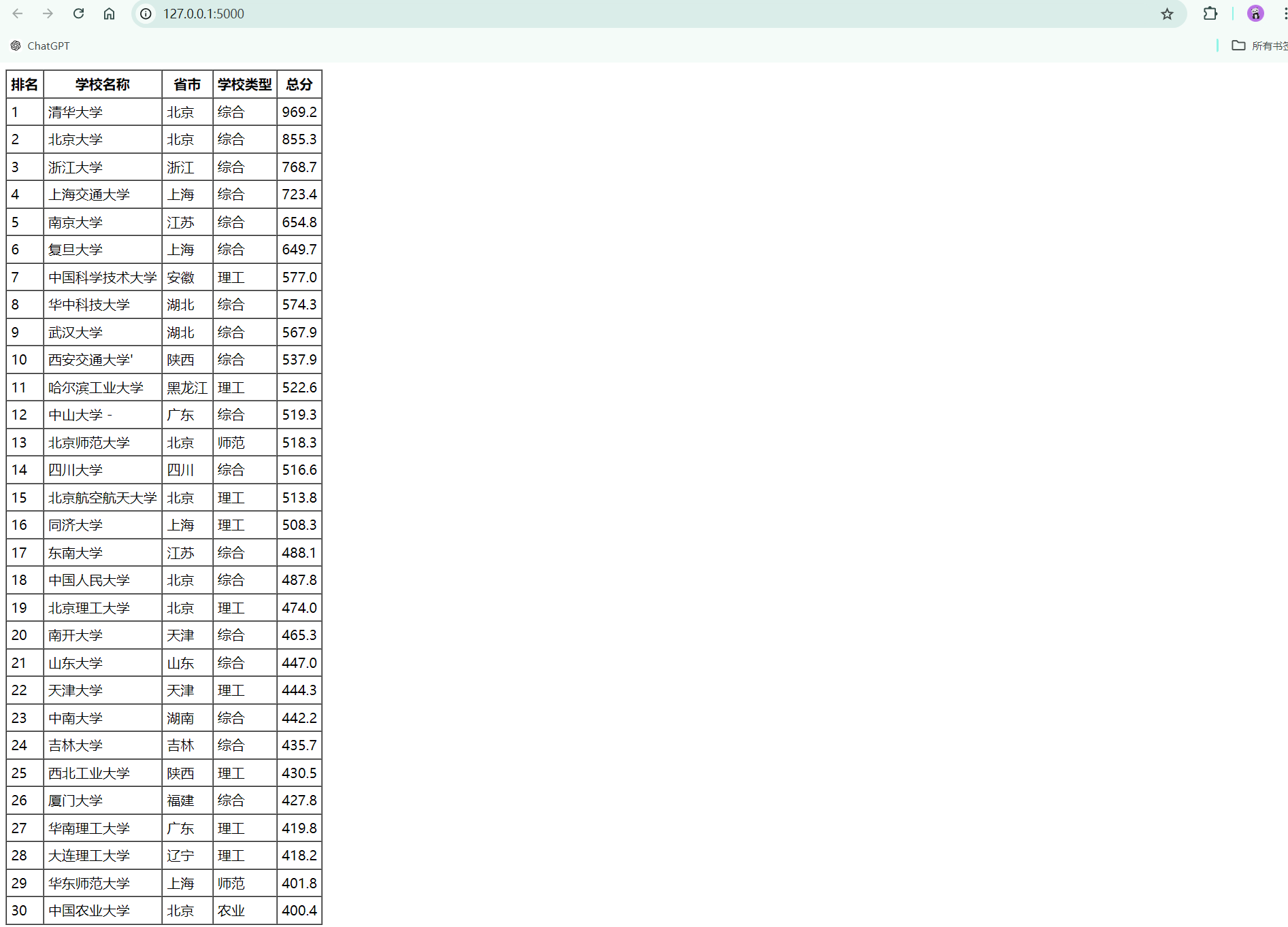
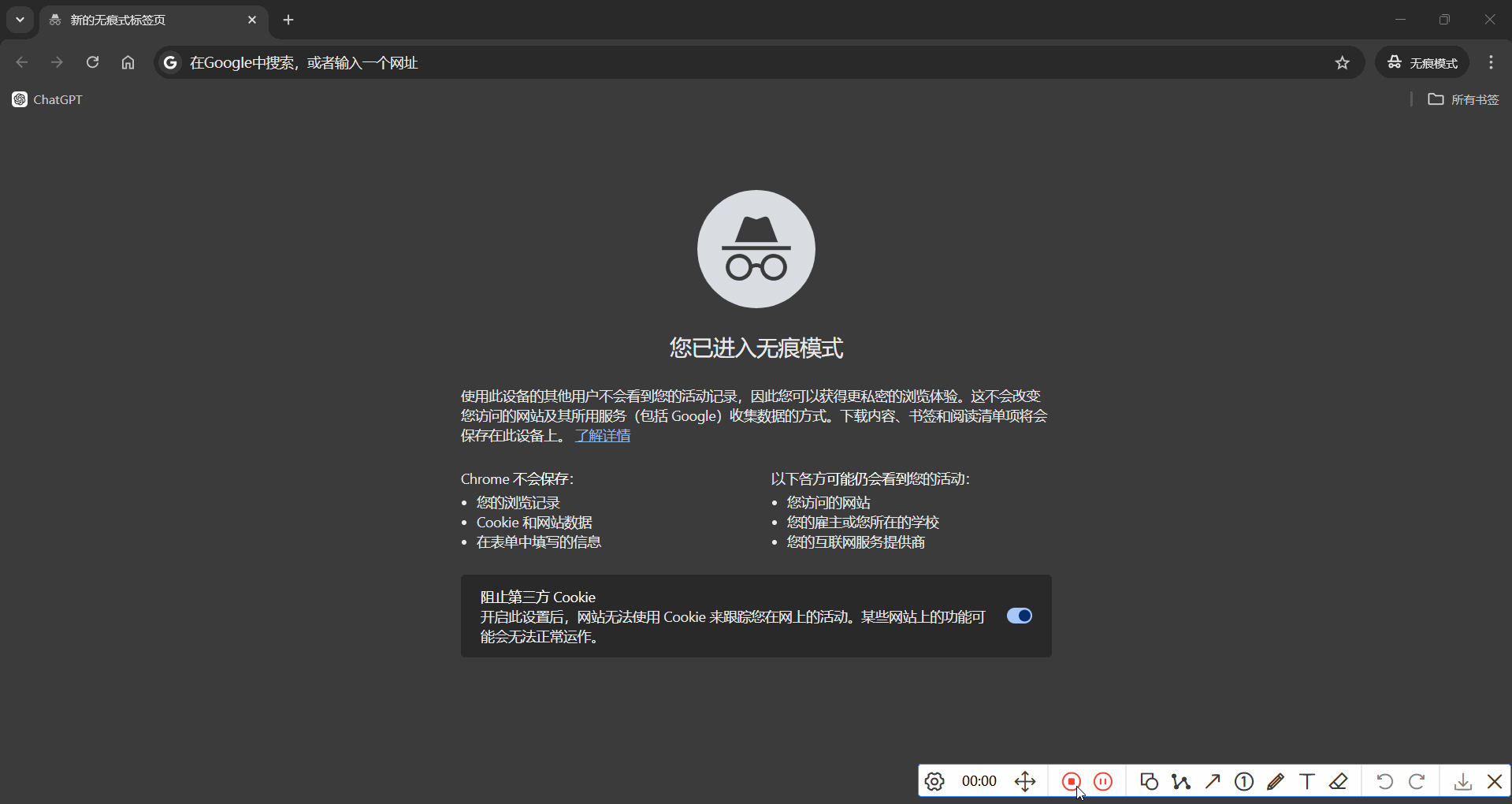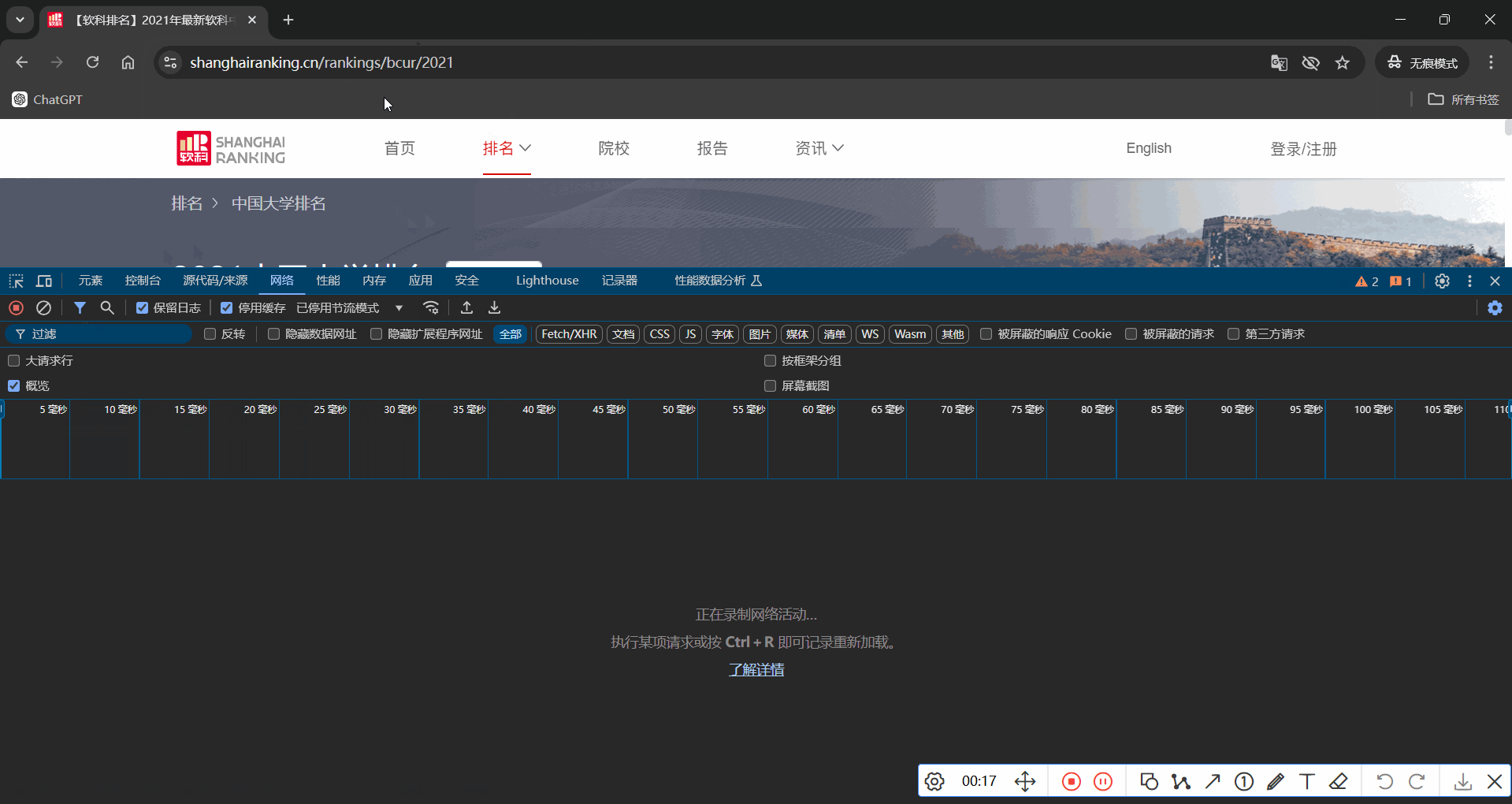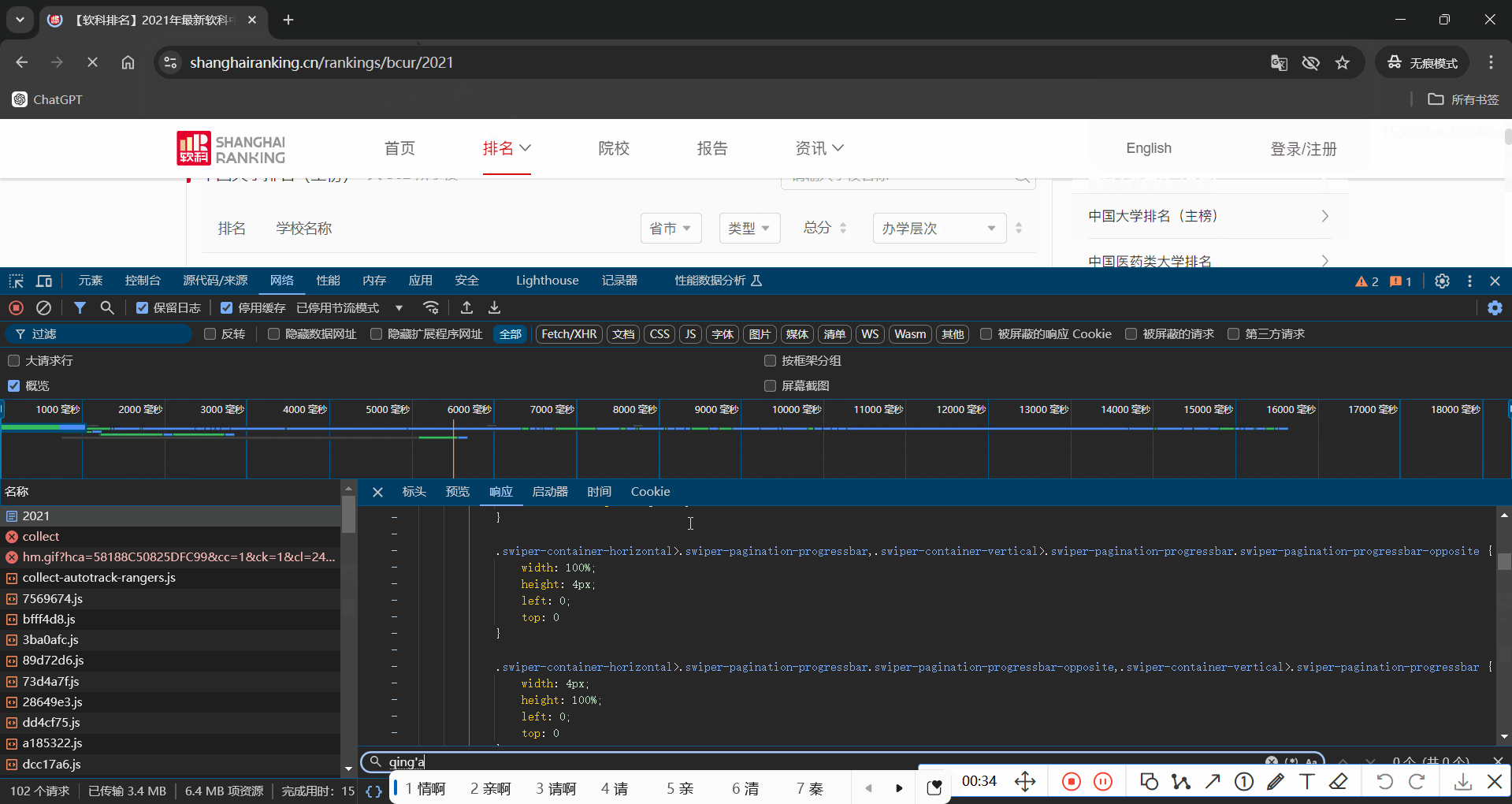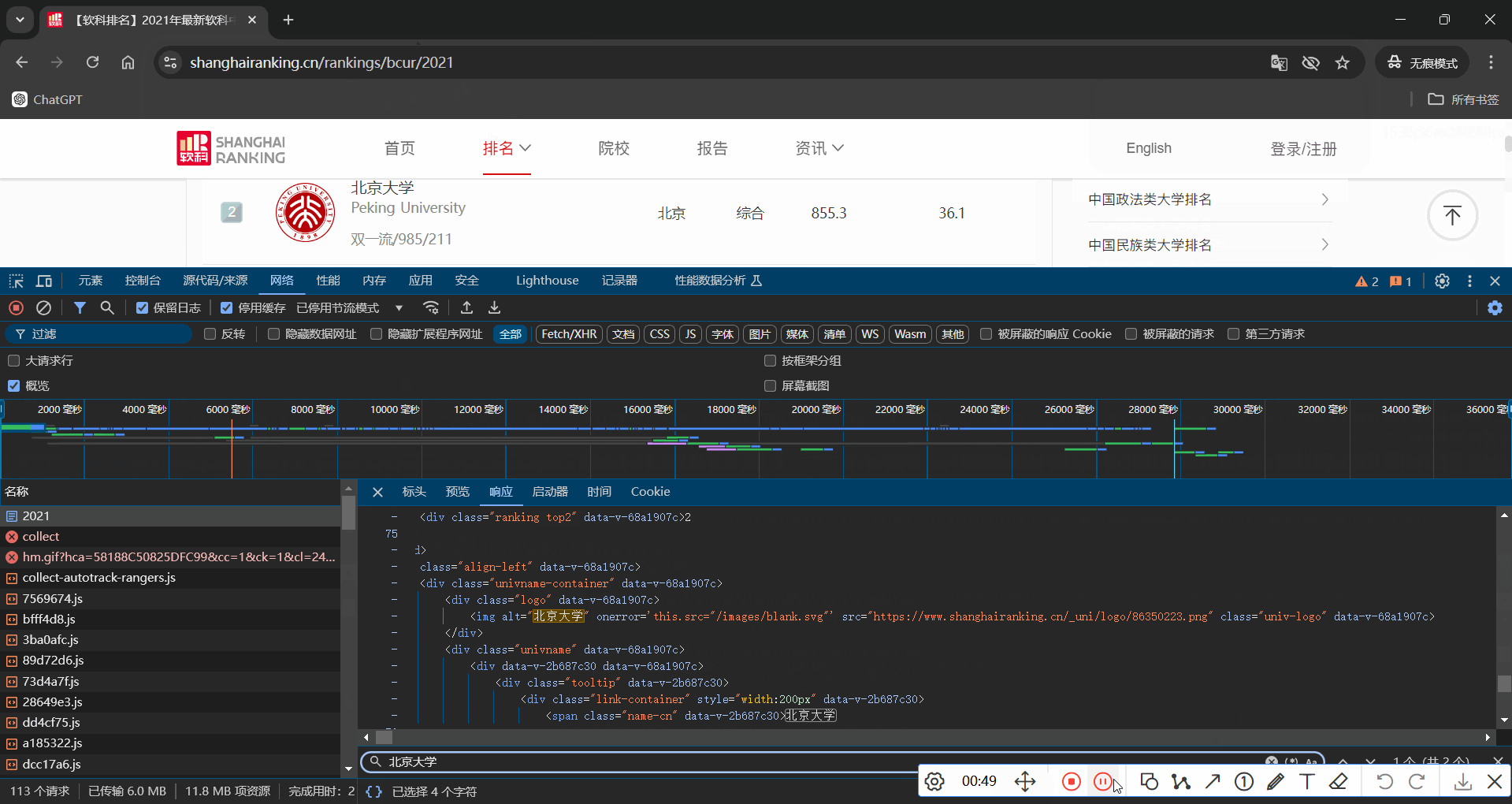
要求:爬取中国大学2021主榜( https://www.shanghairanking.cn/rankings/bcur/2021 )所有院校信息,并存储在数据库中,同时将浏览器F12调试分析的过程录制Gif加入至博客中。
仓库链接:https://gitee.com/jyppx000/crawl_project/tree/master/作业2
3.1代码和图片
import re
import urllib.request
from bs4 import BeautifulSoup
from flask import Flask, render_template_string
class UniversityRankingScraper:
"""处理大学排名数据的抓取和HTML表格生成"""
def __init__(self, url):
self.url = url
self.table_html = None
def fetch_data(self):
"""获取网页内容并进行解析"""
response = urllib.request.urlopen(self.url)
web_content = response.read()
soup = BeautifulSoup(web_content, 'html.parser')
return soup
def generate_html_table(self, soup):
"""生成HTML表格"""
table = soup.find('table')
html_table = '<table border="1" cellspacing="0" cellpadding="5">\n'
html_table += ' <tr><th>排名</th><th>学校名称</th><th>省市</th><th>学校类型</th><th>总分</th></tr>\n'
for row in table.find_all('tr')[1:]:
cols = row.find_all('td')
rank = cols[0].get_text(strip=True)
school_name = re.sub(r'[A-Za-z]|(双一流|985|211)|/+', '', cols[1].get_text(strip=True)).strip()
province = cols[2].get_text(strip=True)
school_type = cols[3].get_text(strip=True)
score = cols[4].get_text(strip=True)
html_table += f' <tr><td>{rank}</td><td>{school_name}</td><td>{province}</td><td>{school_type}</td><td>{score}</td></tr>\n'
html_table += '</table>'
# 存储生成的HTML表格
self.table_html = html_table
# 返回HTML表格
return self.table_html
def get_html_table(self):
"""提供生成HTML表格的接口"""
soup = self.fetch_data()
return self.generate_html_table(soup)
class UniversityRankingApp:
"""Flask应用类"""
def __init__(self, scraper):
"""
:param scraper: 爬虫对象
"""
self.scraper = scraper
self.app = Flask(__name__)
# 设置路由
@self.app.route('/')
def index():
# 获取HTML表格
table_html = self.scraper.get_html_table()
# 返回渲染的HTML内容
return render_template_string(table_html)
# 运行Flask应用
def run(self):
self.app.run(debug=True)
# 创建爬虫类并启动应用
if __name__ == '__main__':
# 传入排名页面的URL
url = "https://www.shanghairanking.cn/rankings/bcur/2021"
# 创建爬虫对象
scraper = UniversityRankingScraper(url)
# 创建Flask应用对象
app = UniversityRankingApp(scraper)
app.run()
抓包过程
3.2 作业心得
- 再次巩固了使用
urllib.request和BeautifulSoup进行网页抓取和解析 - 学习到flask通过
render_template_string直接渲染HTML表格,之前django是用render渲染HTML表格

 浙公网安备 33010602011771号
浙公网安备 33010602011771号