20202110 实验四 《Python程序设计》实验报告
20202110 2021-2022-2 《Python程序设计》实验四报告
课程:《Python程序设计》
班级: 2021
姓名: 胡睿
学号:20202110
实验教师:王志强
实验日期:2020年5月28日
必修/选修: 公选课
1.实验内容
在Python的综合运用中自主选题:爬虫、数据处理、可视化、机器学习、神经网络、游戏、网络安全等。
并在华为ECS服务器(OpenOuler系统)和物理机(Windows/Linux系统)上使用VIM、PDB、IDLE、Pycharm等工具编程实现。
2. 实验过程及结果
(1)选题
接触Python的时候,我对爬虫比较感兴趣,所以在Python的综合作业中选择了爬虫项目。现在每天大家几乎都会用微信聊天,每每向对方传递自己的情感的时候都会使用到表情包,所以各种表情包供不应求。我就想写一个Python程序,爬取百度上的各种新奇的表情包。
(2)代码设计:
-
先找到需要爬取的表情包网站( https://www.fabiaoqing.com/biaoqing )
![]()
-
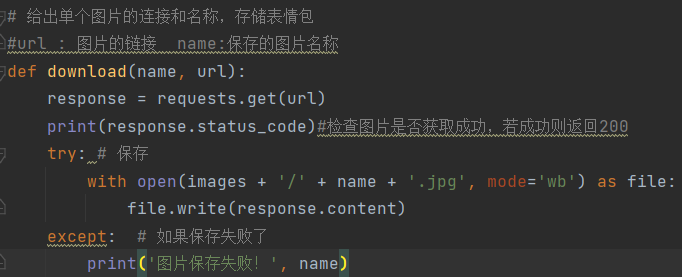
存储单个图片的步骤:获取网页中图片的链接,并将其保存在电脑存储中
with open(文件名称,文件类型) as file:#图片文件类型是二进制的'wb'
file.write(response.content)
将其封装为函数download:参数:输入name--文件名称,url--图片的链接
![]()
-
存储一页图片的步骤:获取这一页中所有图片的链接存储在元组中,并引用download函数
re.findall(链接, 查找范围)//查找范围用网页链接表示
找到网页连接需要查找网页的html代码部分,观察到每个图片的链接和名称都在统一的格式之中,
我们只需要找到所有图片通用格式中的图片链接和名字用(.*?)来代替需要抓取的内容并且用元组来存储即可。
![]()
将存储一页的代码封装成函数download_onepage(danye_url)
参数:网页的链接
功能:就能爬取整页的表情包
完整代码段如下:
![]()
-
存储每一页的图片的步骤:
先在浏览器中打开观察每一页的链接
![]()
![]()
![]()
观察到每一页的html代码中只有最后/page/2.html的数字不同因此我们只需要改变链接中的数字就可以实现任意爬取0-n页的表情包了
完整代码段如下:
![]()
(3)利用Pycharm实现:
-建立文件夹:
给文件夹命名:
如果成功就创建
如果命名失败就重新命名直至成功为止
![]()
-
终端运行









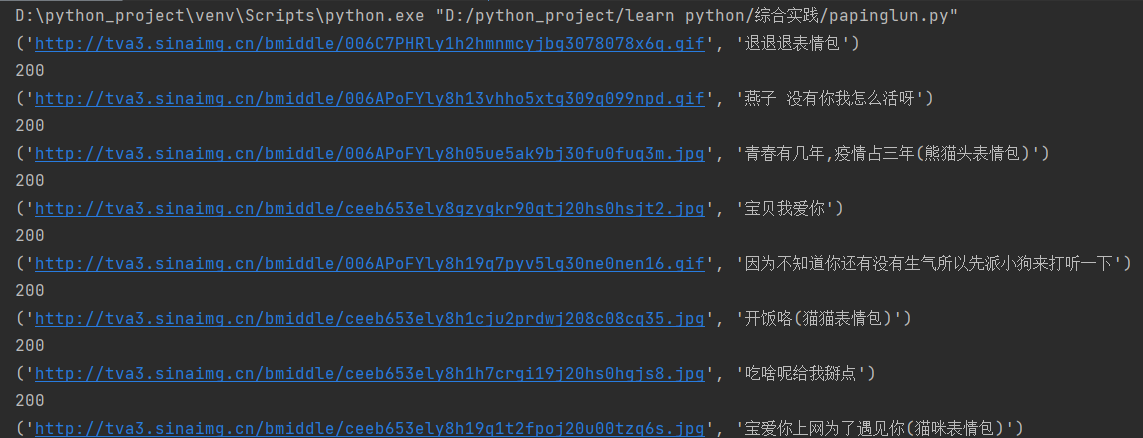
(4)利用ECS实现:
- 购买华为云服务器
- 开启华为云服务器
以下为使用CloudShell开启华为云服务器的截图,显示字体先点击全屏后退出即可恢复正常格式
![]()
- 使用vim运行Python程序:
a.首先创建一个Python文件
代码如下:
--------------创建爬虫文件运行的目录-----------
mkdir Python_Image_Downloads
mkdir Python_Image_Downloads/images
--------------创建爬虫文件--------------------
touch ./Python_Image_Downloads/spider.py
b.再利用vim编辑Python,并保存
vim spider.py(文件名)
按I键进行编辑
按esc键退出编辑
输入:wq保存文件
c.运行Python文件
python spider.py
运行结果:

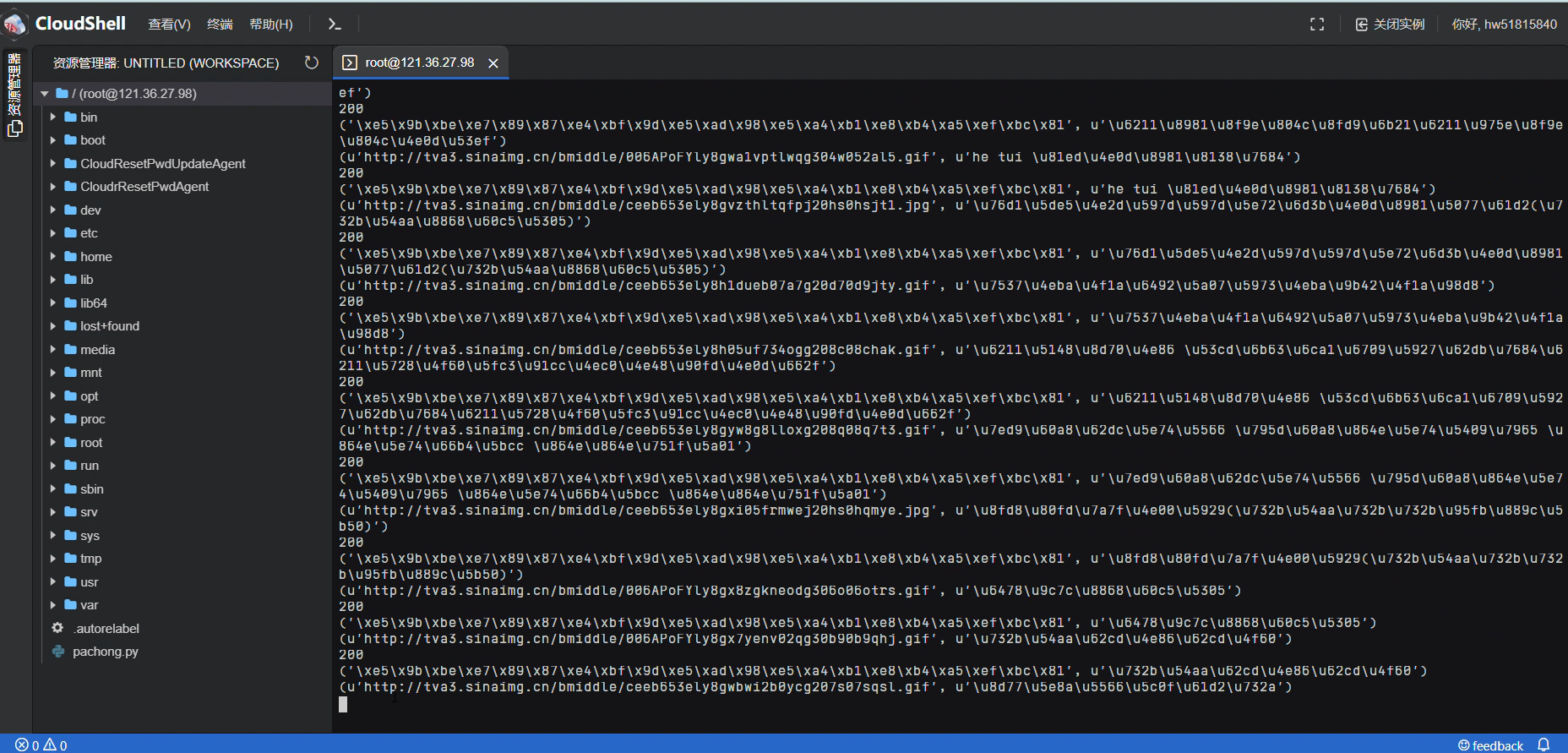
点击连接之后查看图片:

3. 实验过程中遇到的问题和解决过程
- 问题1:Pycharm下载好的库无法使用,发现Python编辑器为空
- 问题1解决方案:上网查资料后发现将.idea文件夹删除再重启Pycharm就可以解决这个问题。
- 问题2:无法在ECS中安装requests库
- 问题2解决方案:原因是下载时使用的命令是 pips3命令,而ECS默认的为Python环境,将指令换成pip就好
- 问题3:ECS中无法查看自己爬取的图片
- 问题3解决方案:云端运行比较慢,需要耐心等待
- 问题4:根据a标签无法z抓取每张图片的链接
- 问题4解决:应该根据image标签
实验总结
这次实验让我收获颇丰。通过这次python综合实践我对爬虫知识的掌握更上一层楼,可以运用代码将网页上的表情包保存下来留为己用,大大提高了效率。这次网络爬虫还需要用到web网页开发的工具,让我熟悉了html代码以及网页中图片的存储形式。将所学的知识的综合运用对我来说就像一名建筑师将自己想要实现的功能分布分块逐个击破一一实现。我运用华为云服务器实现python代码的运行,让我对linux系统的工作原理有了更深入的了解。这一次次的实验锻炼了我信息检索的能力,我在百度的时候筛选信息的效率日渐提升,提取需要解决问题的关键词更加精准。但我任有很多不足之处,做实验的时候遇到困难应及时交流与沟通,由于性格原因,我经常会选择闭门造车,导致一个问题常常需要花费大量的时间解决,在以后的实验过程中,我要善于交流提问,在与同学和老师的交流中不断进步。
课程总结
Python相对来说是一门较为简单易学的编程语言,更着重于代码功能的实现,拥有丰富的库资源,为编程解决问题提供了强大的帮助使得代码变得更加简洁。正如那句至理名言所说的:“人生苦短,我用Python”。Python语言的应用十分广泛,比如Web应用开发、自动化运维、人工智能领域、网路爬虫、科学计算、游戏开发等等。在进行Python编程学习的同时将本学期的计算机网络和web前端开发的知识综合运用,有一种融会贯通的感觉。Python的学习分为基础知识和实践运用两个部分。在有基础知识的情况下采用类比学习的方法掌握就迅速投入实例学习。
在实践运用中通过实例在轻松有趣的氛围下学到了不少Python库的使用方法。比如用socket库实现服务器与客户端的加密对话,用requests、os等库实现爬取网络中你想获取的资源、以及matplotlib库用于绘制你想要的图形等等,在此就不一 一列举了。
课程感想和体会
初选Python公选课的时候是想多掌握一门语言提高自己的编程水平。在听完王老师第一堂课之后,被他列举的Python的实例以及讲课风格所吸引。python的强大功能和如人脸识别、绘图、制作小游戏等让我对这门编程语言产生了浓厚的兴趣。而加之老师上课时十分通俗易懂,使用生活化的例子将抽象的知识具象化利于我们接受。这门课不仅增加了我的编程知识的水平,在Python强大的库功能的时候,面对五花八门的编程实践例子,让我一度对编程兴趣高涨。上大学初始由于我对编程知之甚少,在学习的过程中也是抱着完成任务的态度,有时会被无穷的bug影响得心态崩溃。但在兴趣的驱使以及更深专业学习的影响下我的学习变得更加主动,使得我面对bug也多了不少耐心。老师的课堂有趣又干货满满可以节省不少课下学习时间,解答问题的时候十分耐心,改变了我平时不太爱提问的毛病,让我知道交流的重要性。
当然,Python的知识博大精深,我只是学习到的也只是冰山一角,希望自己能一直保持着这份学习热情,更加深入地学习Python知识,在不断实践中提升自己。这学期的实验让我锻炼了能力,提高了自信。我十分理解程序员最幸福的时刻就是看自己写出的代码完美运行的时候,就满满的成就感!
意见和建议
- 特别喜欢老师分享的Python资料,可以多多益善比如有趣的Python实践项目等
- 建议可以将上课讲的代码提前发到群里,坐太靠后看不清黑板没跟上老师的速度,会影响听课效率(超小声)
参考资料
-
[https://blog.csdn.net/Mculover666/article/details/92360302?ops_request_misc=&request_id=&biz_id=102&utm_term=华为云运行python程序&utm_medium=distribute.pc_search_result.none-task-blog-2allsobaiduweb~default-6-92360302.142v11control,157v12control&spm=1018.2226.3001.4187
]() -
[(53条消息) Linux系统vim编辑器使用方法:编辑、保存和退出_夏茗xm的博客-CSDN博客_linux vim怎么保存文件和退出文件
https://blog.csdn.net/qq_52671517/article/details/124673951
]()
- [(53条消息) vim基础使用方法_南方以南_的博客-CSDN博客_vim使用方法
https://blog.csdn.net/weixin_43366437/article/details/123295845
]()
- [(53条消息) python 代码创建文件夹_看,这有一只小强~的博客-CSDN博客_python创建文件夹代码
https://blog.csdn.net/weixin_34132725/article/details/103860572?spm=1001.2101.3001.6650.5&utm_medium=distribute.pc_relevant.none-task-blog-2~default~BlogCommendFromBaidu~default-5-103860572-blog-109947359.pc_relevant_aa&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2~default~BlogCommendFromBaidu~default-5-103860572-blog-109947359.pc_relevant_aa&utm_relevant_index=10
]()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号