
Python正则元字符,贪婪模式,非贪婪模式
这篇文章详解一下正则中会用到的元字符,按如下顺序讲
1. . [ ] \d \D \s \S \w \W 2. * + ? {m} {m,} {m,n} 3. ^ $ \b \B 4. | 5.额外例子 6.贪婪/非贪婪模式
1.单字符匹配
(1) .
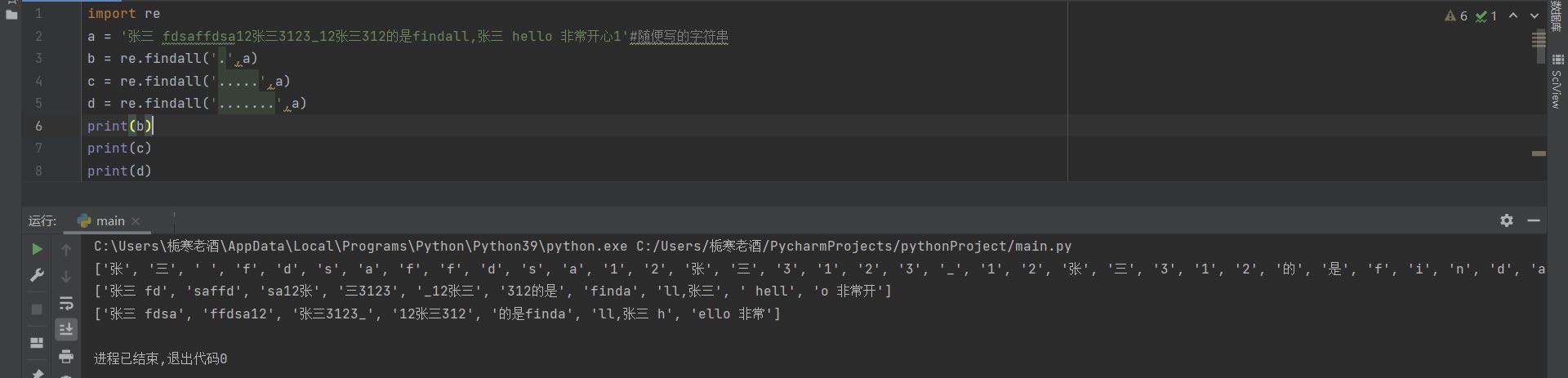
. 的作用是匹配原字符串中的任意,任何一个字符,包括逗号,包括空格,只有\n不匹配,有几个点,就以几个为一组输出,如果匹配到最后一组,最后一组里的元素个数小于. 的个数,则最后一组不输出
(2)[ ]
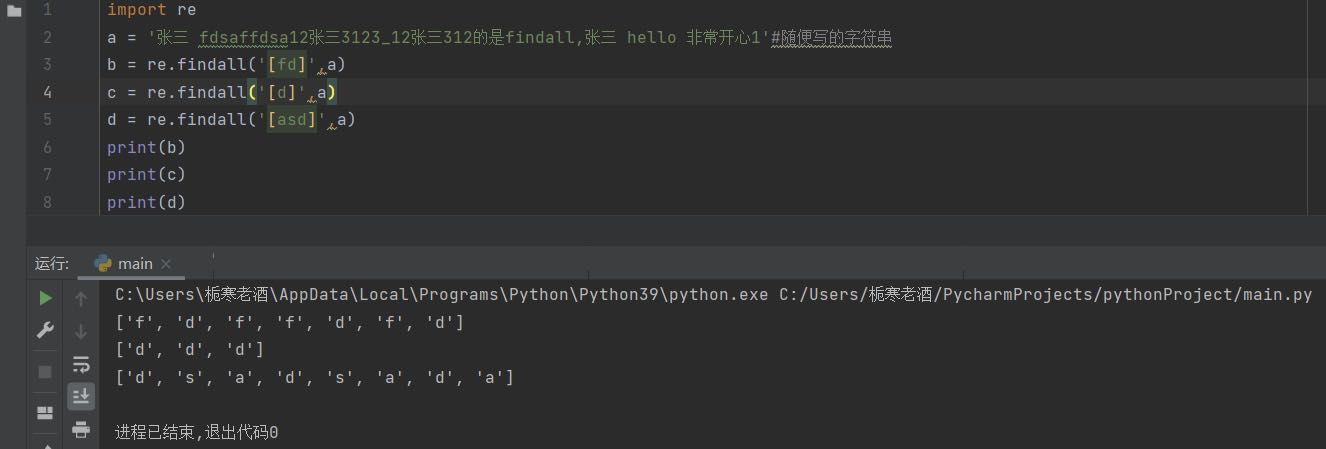
[]里不能为空,必须有元素,里面写几个元素无所谓,它不会以整体去找,会单个单个找,单个单个返回,里面元素的顺序也无所谓,例:[3-9]:匹配3,4,5,6,7,8,9所有数字
(3)\d
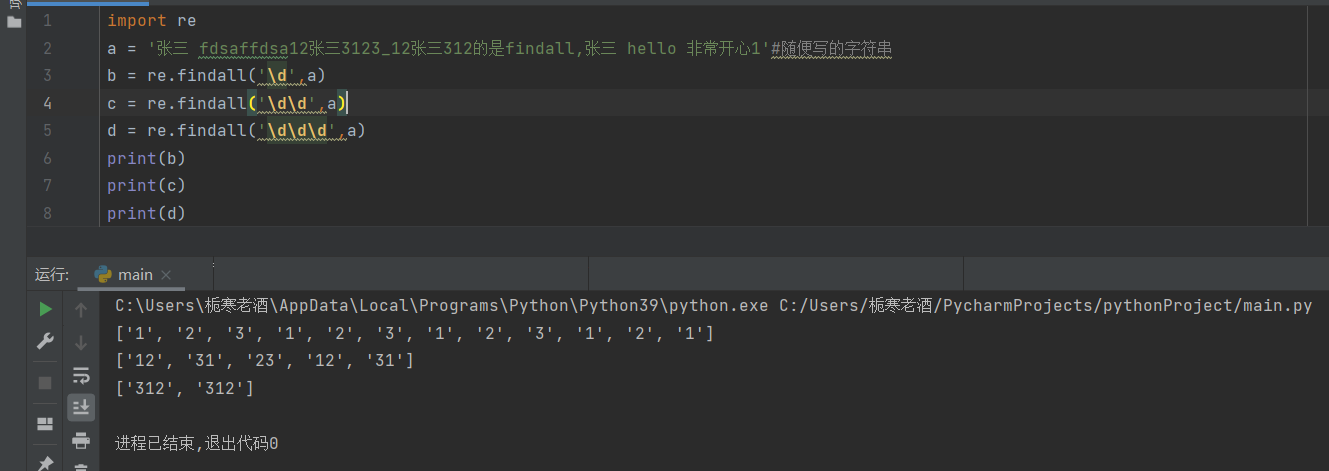
\d的作用是匹配数字,即0-9,有几个\d就几个为一组输出,但是\的个数个数字连在一起才能输出,如果匹配到最后一组,最后一组里的元素个数小于\d的个数,则最后一组不输出
(4)\D
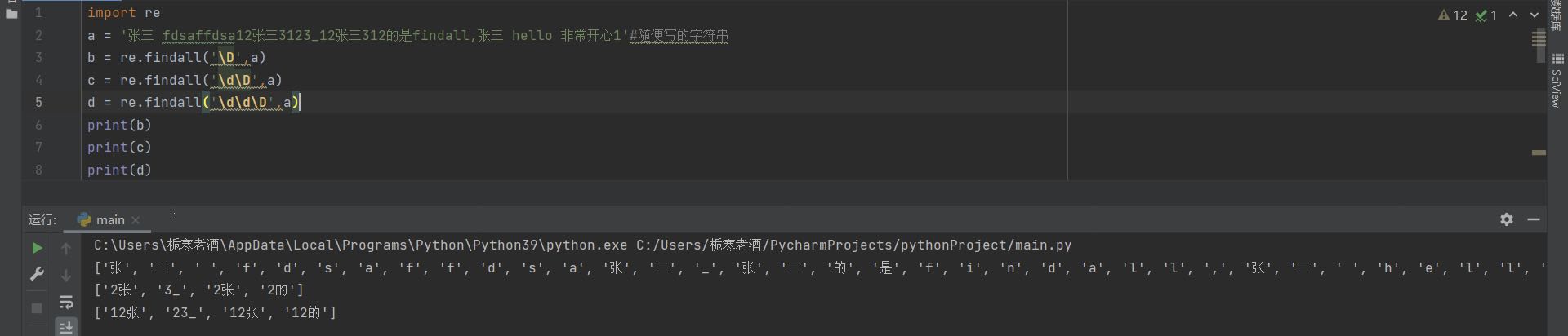
\D匹配非数字,必须严格遵守你写的形式去找,比如\d\D,必须是数字+非数字,两个挨在一起才能匹配成功并输出
(5)\s,\S,\w,\W
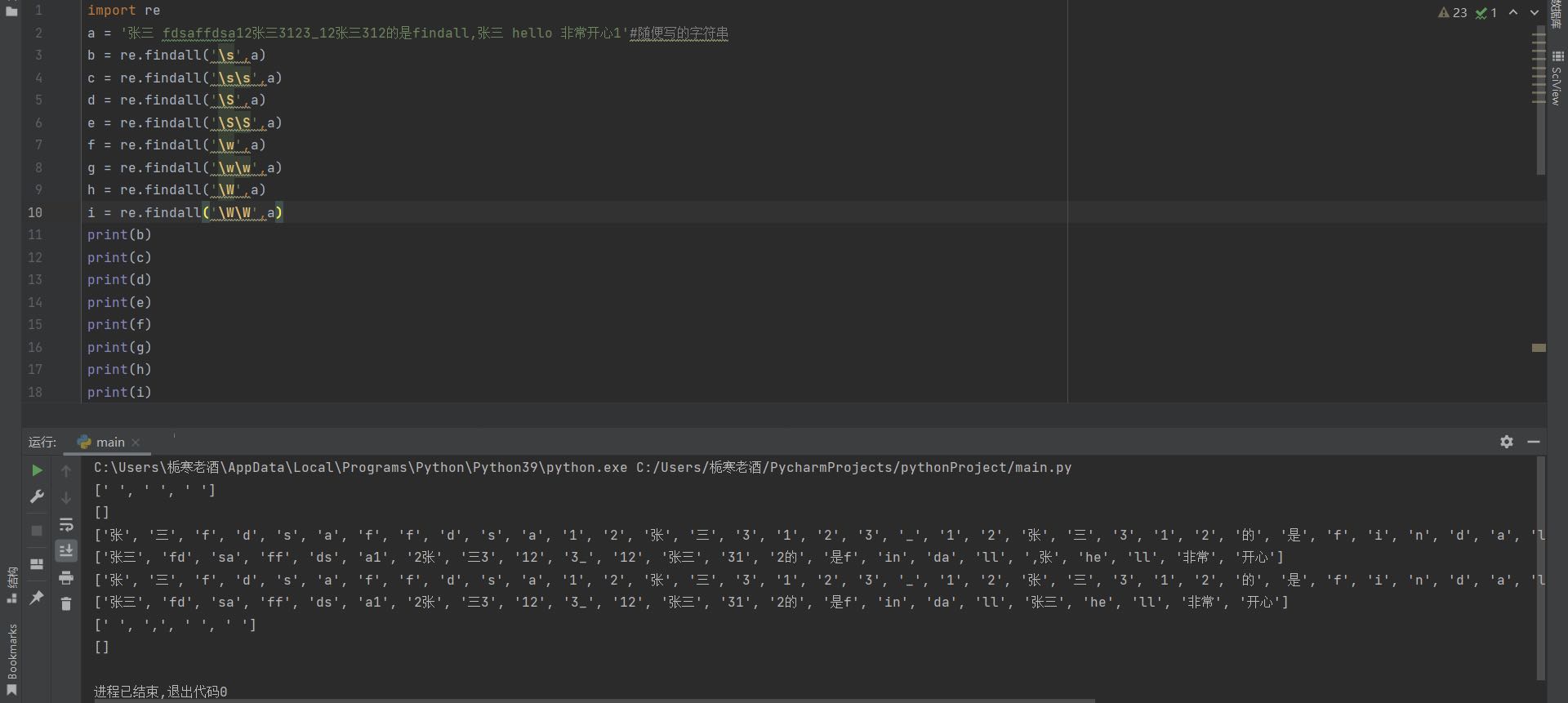
\s匹配空白,即空格、tab键,几个\s就几个空格为一组输出,没有则返回空列表,\S匹配非空格,如果匹配到最后一组,最后一组里的元素个数小于\S的个数,则最后一组不输出,\w匹配单词符,即a-z,A-Z,0-9,_,几个\w就几个为一组输出,最后一组里的元素个数小于\w的个数,则最后一组不输出,\W匹配非单词符,如空格,标点符号
2.代表数量的元字符
(1)*
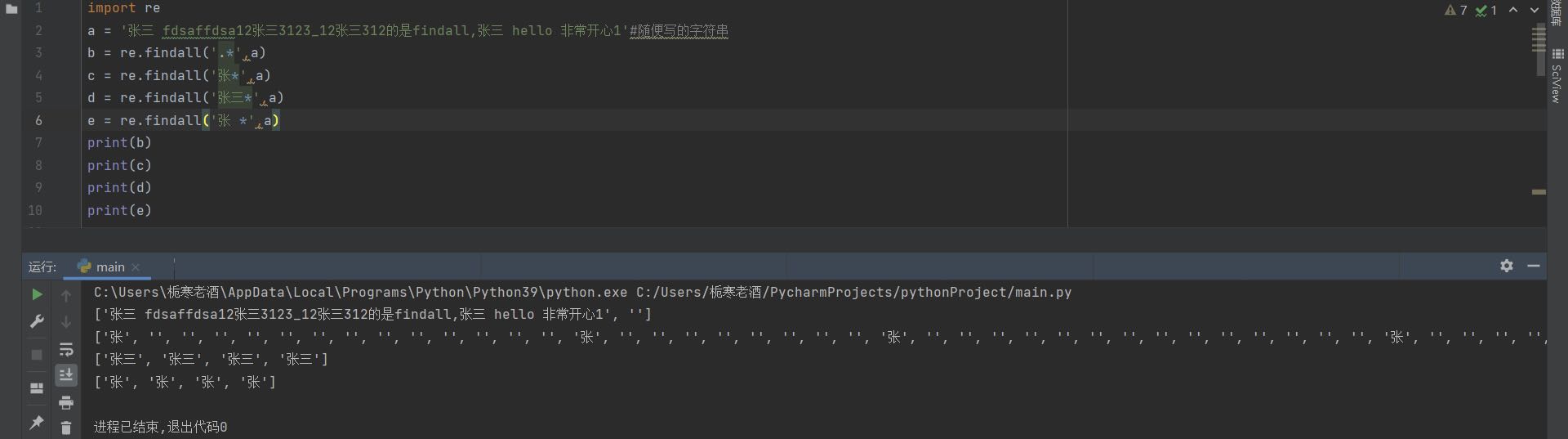
匹配*前的字符出现0次或者无数次,即可有可无,如果没有则返回空列表,这里解释一下上图中的输出的b的最后那个' ', .*是一个一个去找,找完最后的1以后,再往下找一个,发现是空,然后返回,所以有个' ',还要注意上图中输出的c和e的区别,如果e中为'张 *',也就是两个空格,就返回空列表了
(2)+
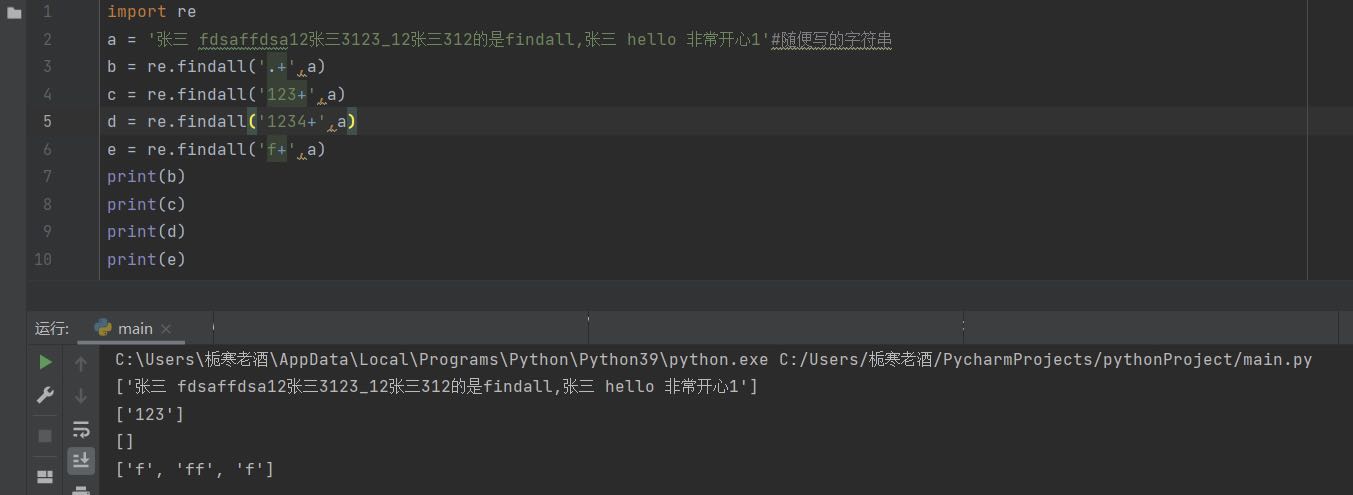
匹配前一个字符1次或无数次,最少一次,+前的字符串无论多长都是一个整体,匹配的时候用这个整体去匹配,匹配到的结果里,你写的匹配规则里的元素必须全都有,e的输出结果中ff为贪婪模式,正则中默认为贪婪模式,文末会提到
(3)?
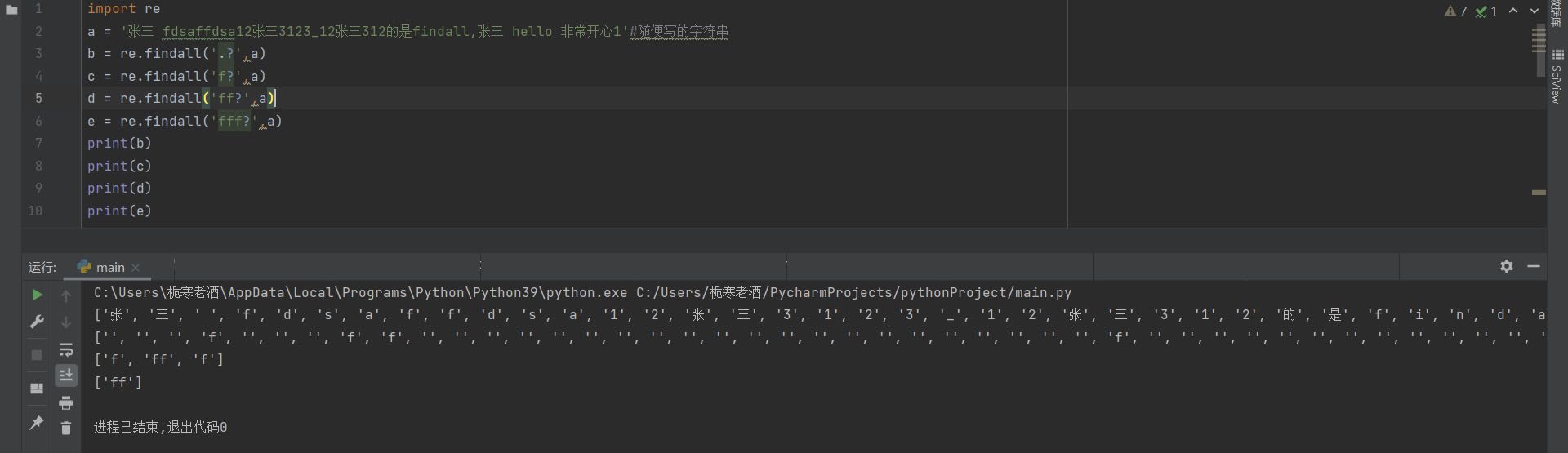
匹配?前的字符出现0次或1次,即要么有1次,要么没有
(4){m}
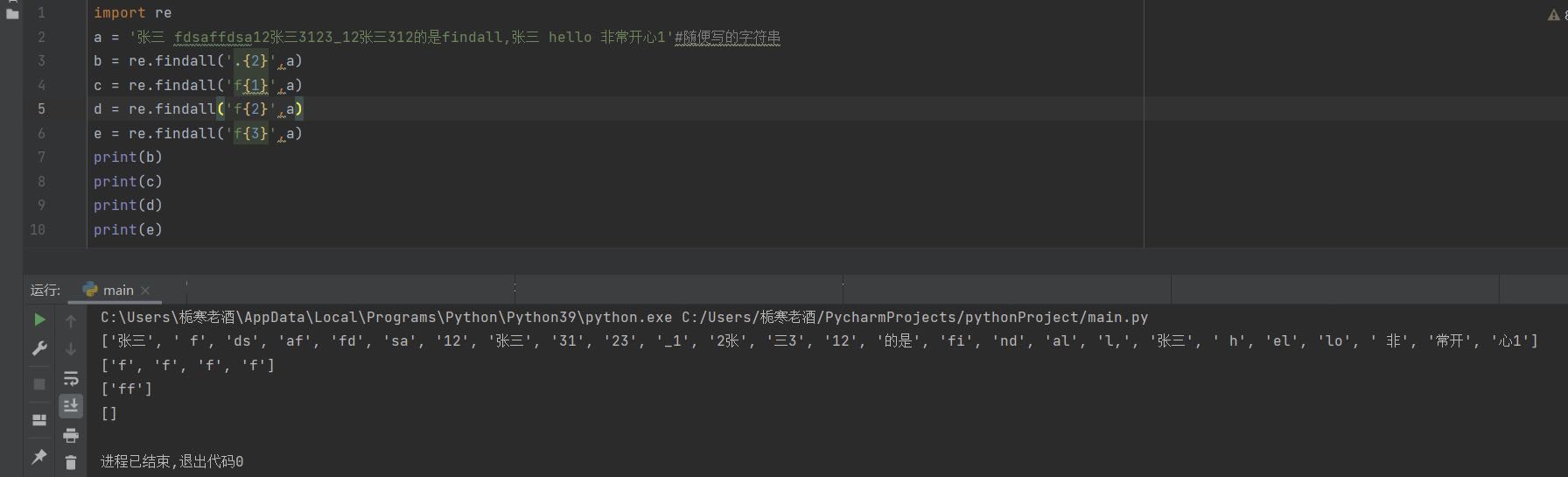
匹配前一个字符出现m次,必须挨在一起才有效,才能输出
(5){m,}
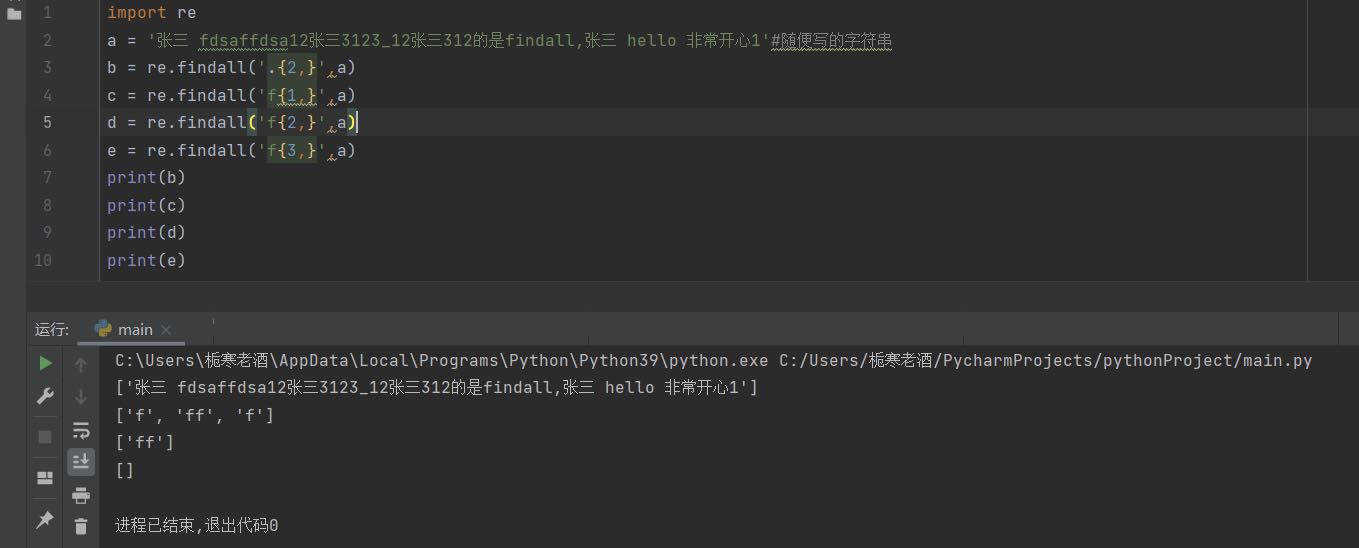
匹配前一个字符至少出现m次,贪婪原则,尽可能多的输出,下面会说
(6){m,n}
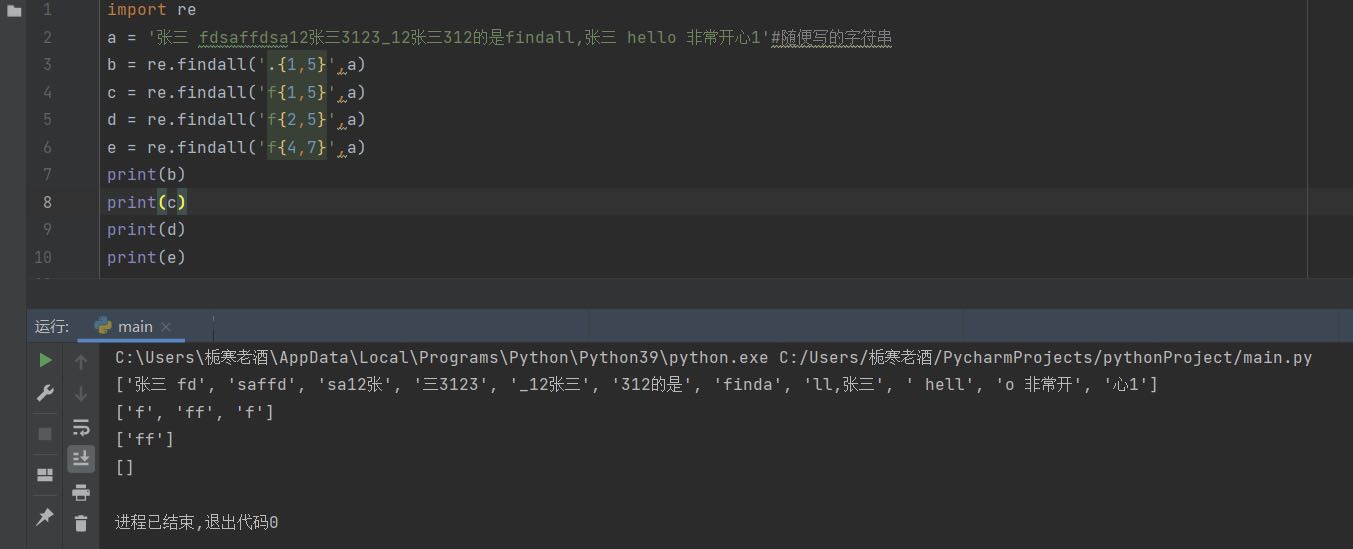
匹配前一个字符出现从m到n次(m<n),没有会返回空列表
3.代表边界的元字符
(1)^
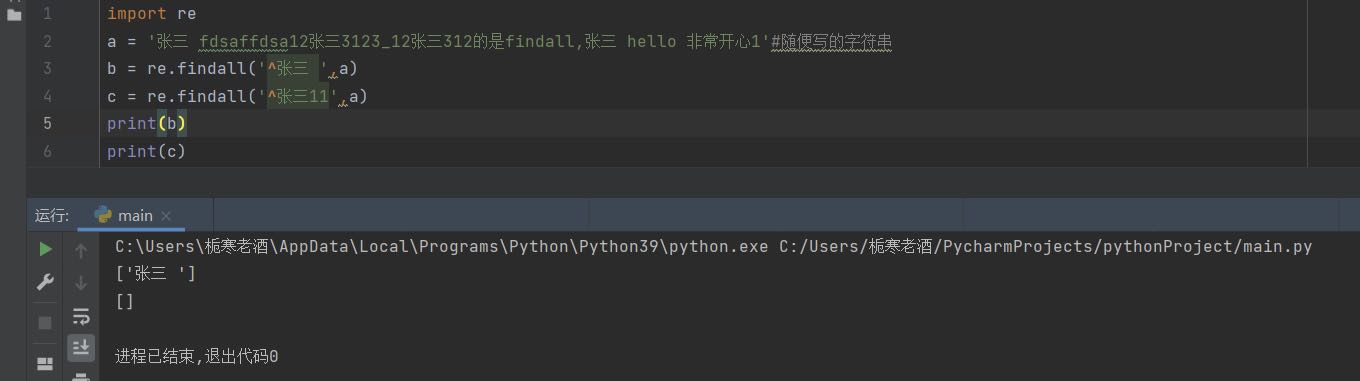
匹配字符串开头,不符合则返回空列表
(2)$
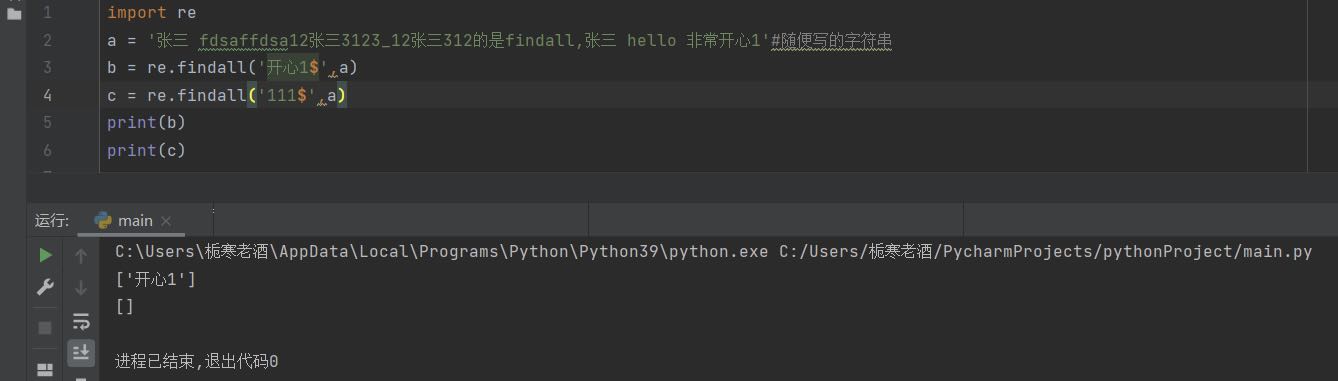
匹配字符串结尾,不符合返回空列表,^必须放在前面,$必须放在后面,否则会高亮显示,不管匹配后符不符合都会返回空列表(但不会报错)
(3)\b,\B
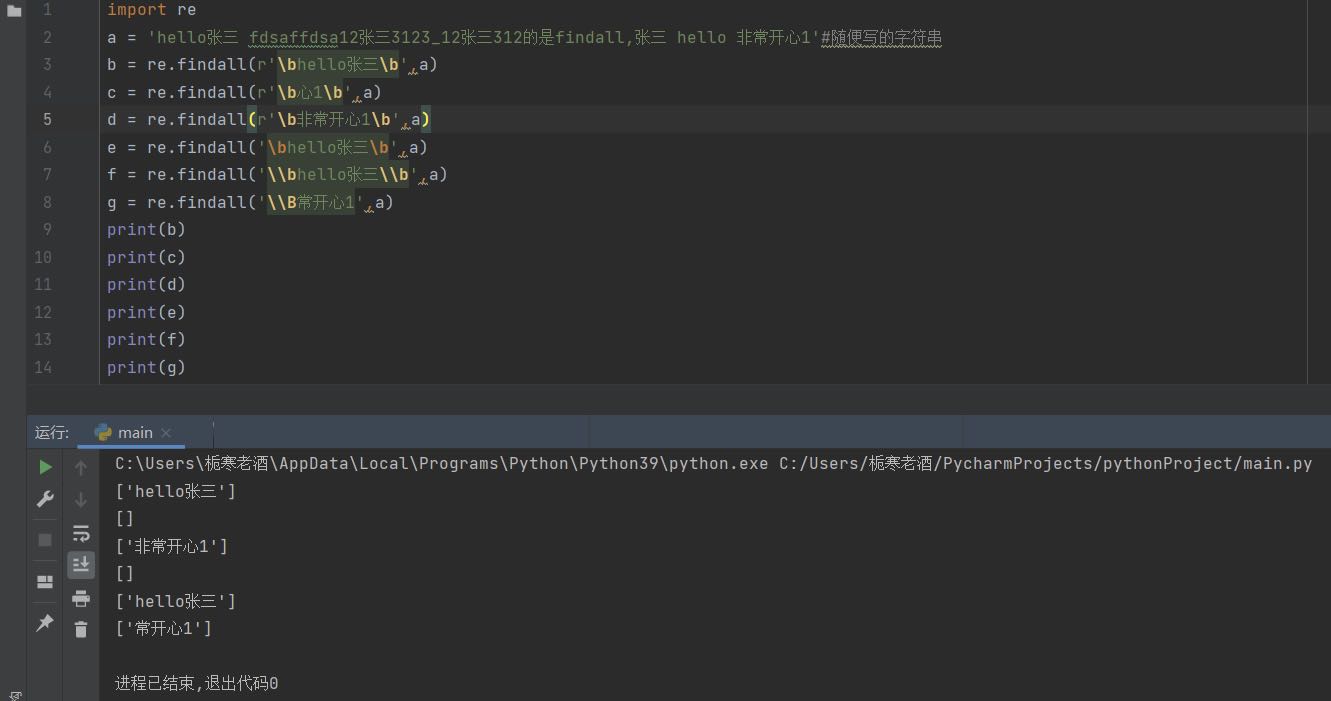
\b匹配一个单词的边界,\B匹配非单词的边界,\b匹配的必须是一个独立的单词(不一定都要是字母,但一定要有字母),不能是一个单词的一部分(中间没有空格),
\bx\b:x两侧必须是空格,不能有东西,\Bx:x两侧最少有一侧不是空格也就是还有东西,两侧都有也可以,\b有1个2个都行,在前在后都行,\B只能有一个,并且只能在前面,b或B前要么加个r,要么写成\\
4.分组匹配
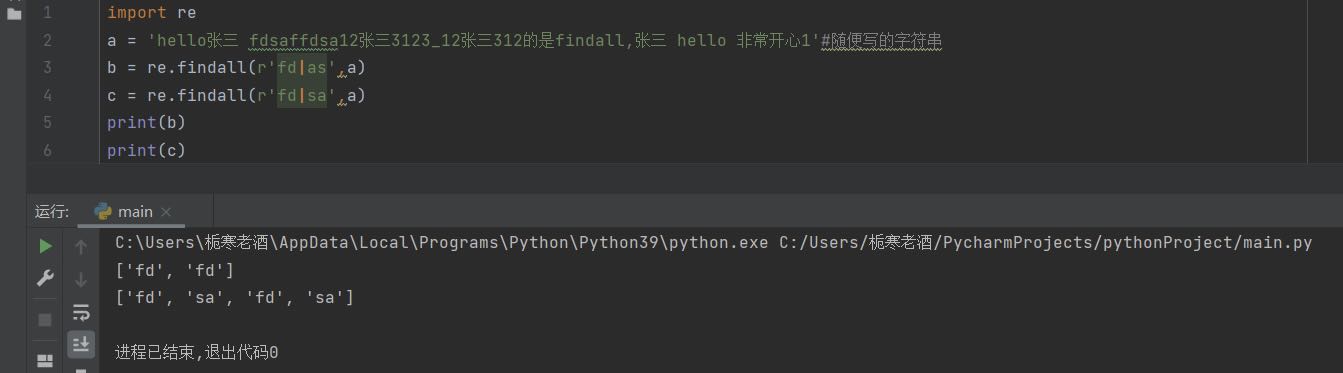
匹配左右任意一个表达式
5.一些额外例子
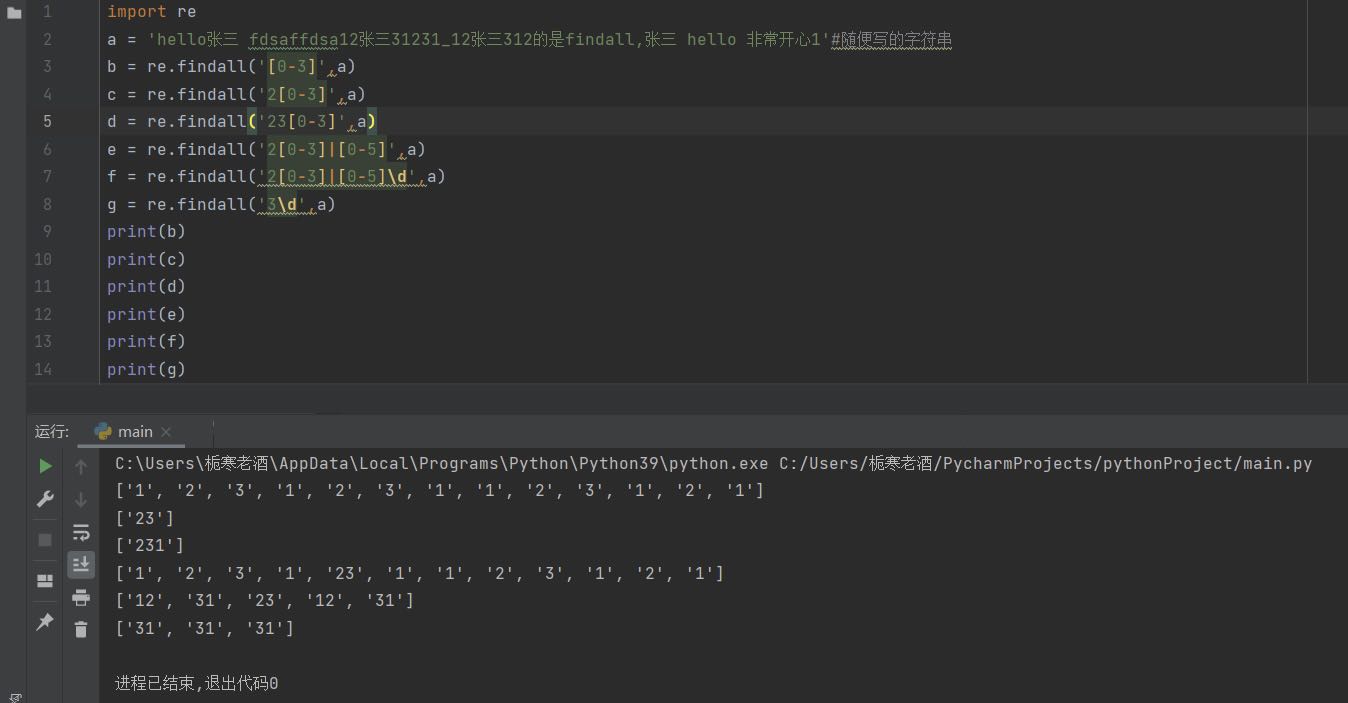
6.贪婪模式,非贪婪模式
贪婪模式是指在符合你写的寻找规则的情况下,先找多的,再找少的,正则默认情况下是贪婪模式,如下图:
如d,先找有没有出现5次的,再找4次,3次,2次

 浙公网安备 33010602011771号
浙公网安备 33010602011771号