python面试题----2
Python面试重点(进阶篇)
注意:只有必答题部分计算分值,补充题不计算分值。
第一部分 必答题
-
简述 OSI 7层模型及其作用?(2分)
物理层:主要是基于电器特性发送高低电压(电信号),高电压对应数字1,低电压对应数字0 数据链路层:定义了电信号的分组方式 网路层:引入一套新的地址用来区分不同的广播域/子网,这套地址即网络地址 传输层:建立端口到端口的通信 会话层:建立客户端与服务端连接 表示层:对来自应用层的命令和数据进行解释,按照一定格式传给会话层。如编码、数据格式转换、加密解密、压缩解压 应用层:规定应用程序的数据格式 -
简述 TCP三次握手、四次回收的流程。(3分)
三次握手: 第一次握手 1:客户端先向服务端发起一次询问建立连接的请求,并随机生成一个值作为标识 第二次握手 2:服务端向客户端先回应第一个标识,再重新发一个确认标识 第三次握手 3:客户端确认标识,建立连接,开始传输数据 四次挥手 ---> 断开连接 第一次挥手 客户端向服务端发起请求断开连接的请求 第二次挥手 服务端向客户端确认请求 第三次挥手 服务端向客户端发起断开连接请求 第四次挥手 客户端向服务端确认断开请求 -
TCP和UDP的区别?(3分)
TCP/UDP区别 TCP协议是面向连接,保证高可靠性传输层协议 UDP:数据丢失,无秩序的传输层协议(qq基于udp协议) -
什么是黏包?(2分)
在获取数据时,接收方不知道数据长度,将多个数据包一次接受,造成数据黏在一起 -
什么 B/S 和 C/S 架构?(2分)
c/s架构,就是client(客户端)与server(服务端)即:客户端与服务端的架构。 b/s架构,就是brosver(浏览器端)与sever(服务端)即:浏览器端与服务端架构 优点:统一了所有应用程序的入口、方便、轻量级 -
请实现一个简单的socket编程(客户端和服务端可以进行收发消息)(3分)
服务端 import socket sk = socket.socket() sk.bind(('127.0.0.1',6666)) sk.listen() conn,addr=sk.accept() ma = conn.recv(1024).decode('utf-8') print(ma) sonn.close() sk.close() 客户端 import socket sk = socket.socket() sk.connect(('127.0.0.1',6666)) mc = sk.send('这是客户端'.encode('utf-8')) sk.close() -
简述进程、线程、协程的区别?(3分)
进程是计算机分配资源的最小单位,线程是被CPU调用的最小单位,协程又称为微线程,是基于代码人为创造的 ,而进程和线程是计算机中真实存在的,一个进程中可以有多个线程,一个线程可以创建多个协程; 在python中由于有GIL锁,所以在同一时刻的同一进程中只能有一个线程被CPU调用,在python开发中 计算密集型应用用多进程 IO密集型用多线程 单纯的协程是没有办法并发,只是代码之间的来回切换,加上io自动切换才有意义,有 io操作时才用协程 进程之间不能资源共享,线程间的资源是 共享的,协程需要导入第三方库,需要加补丁 -
什么是GIL锁?(2分)
全局解释器锁 同一时刻保证一个进程中只有一个线程可以被cpu调度,所以在使用Python开发时要注意: 计算密集型,用多进程. IO密集型,用多线程. -
进程之间如何进行通信?(2分)
进程间的通信 IPC 队列 生产者消费者模型 进程之间通信 IPC Inter Process Communication from multiprocessing import Queue,Process def son(q): print(q.get()) if __name__ == '__main__': q = Queue() p = Process(target=son,args=(q,)) p.start() q.put(123) 在进程之间维护数据的安全 -- 进程安全 队列是进程安全的(进程队列保证了进程的数据安全) 队列都是先进先出的 队列是基于文件 + 锁实现的 队列一共提供两个方法:get put q = Queue() q.put({1,2,3}) num = q.get() # get是一个同步阻塞方法,会阻塞直到数据来 print(num) q = Queue(2) q.put({1,2,3}) q.put({1,2,3}) q.put({1,2,3}) # put是一个同步阻塞方法,会阻塞直到队列不满 import queue q = Queue(2) try: for i in range(4): q.put_nowait(i) # put_nowait 同步非阻塞方法 except queue.Full: print(i) q2 = Queue(2) try: print(q2.get_nowait()) except queue.Empty:pass q = Queue(5) ret = q.qsize() # 查看当前队列有多少值 print(q.empty()) print(q.full()) 生产者消费者模型 队列Queue = 管道Pipe + 锁 Pipe 基于文件实现的(socket+pickle) = 数据不安全 Queue 基于文件(socket+pickle)+锁(lock)实现的 = 数据安全 基于pipe+锁(lock)实现的 IPC: 内置的模块实现的机制 :队列\管道 第三方工具 : redis rabbitMQ memcache -
Python如何使用线程池、进程池?(2分)
作用:
保证程序中最多可以创建的线程(进程)个数,防止无节制的创建线程(进程),导致性能降低
线程池
例一:
import time
from concurrent.futures import ThreadPoolExecutor
def task(n1, n2):
time.sleep(2)
print('任务')
pool = ThreadPoolExecutor(10)# 创建线程池
for i in range(100):
pool.submit(task, i, 1)
print('END')
pool.shutdown(True)# 等线程池中的任务执行完毕之后,再继续往下走
print('其他操作,依赖线程池执行的结果')
例二:
import time
from concurrent.futures import ThreadPoolExecutor
def task(n1, n2):
time.sleep(2)
print('任务')
return n1+n2
pool = ThreadPoolExecutor(10)# 创建线程池
future_list = []
for i in range(20):
fu = pool.submit(task, i, 1)
future_list.append(fu)
pool.shutdown(True)
for fu in future_list:
print(fu.result())
进程池
例:
import time
from concurrent.futures import ProcessPoolExecutor
def task(n1, n2):
time.sleep(2)
print('任务')
if __name__ == '__main__':
pool = ProcessPoolExecutor(10) # 创建进程池
for i in range(20):
pool.submit(task, i, 1)
print('END')
-
请通过yield关键字实现一个协程? (2分)
-
什么是异步非阻塞? (2分)
非阻塞:不等待 即:遇到IO阻塞不等待(setblooking=False),(可能会报错->捕捉异常) - sk=socket.socket() - sk.setblooking(False) 异步:回调,当达到某个指定的状态之后,自动调用特定函数 -
什么是死锁?如何避免?(2分)
当两个线程相互等待对方释放资源时,就会发生死锁。 避免: 1.避免多次锁定 2.具有相同的加锁顺序 3.使用定时锁 4.死锁检测 -
程序从flag a执行到falg b的时间大致是多少秒?(2分)
import threading import time def _wait(): time.sleep(60) # flag a t = threading.Thread(target=_wait) t.setDeamon(False) t.start() # flag b 60 -
程序从flag a执行到falg b的时间大致是多少秒?(2分)
import threading import time def _wait(): time.sleep(60) # flag a t = threading.Thread(target=_wait) t.setDeamon(True) t.start() # flag 不用等待 -
程序从flag a执行到falg b的时间大致是多少秒?(2分)
import threading import time def _wait(): time.sleep(60) # flag a t = threading.Thread(target=_wait) t.start() t.join() # flag b 60 -
读程序,请确认执行到最后number是否一定为0(2分)
import threading loop = int(1E7) def _add(loop:int = 1): global number for _ in range(loop): number += 1 def _sub(loop:int = 1): global number for _ in range(loop): number -= 1 number = 0 ta = threading.Thread(target=_add,args=(loop,)) ts = threading.Thread(target=_sub,args=(loop,)) ta.start() ta.join() ts.start() ts.join() 0 -
读程序,请确认执行到最后number是否一定为0(2分)
import threading loop = int(1E7) def _add(loop:int = 1): global number for _ in range(loop): number += 1 def _sub(loop:int = 1): global number for _ in range(loop): number -= 1 number = 0 ta = threading.Thread(target=_add,args=(loop,)) ts = threading.Thread(target=_sub,args=(loop,)) ta.start() ts.start() ta.join() ts.join() 不是1 -
MySQL常见数据库引擎及区别?(3分)
InnoDB 支持事务 支持表锁、行锁(for update) 表锁:select * from tb for update 行锁:select id,name from tb where id=2 for update myisam 查询速度快 全文索引 支持表锁 表锁:select * from tb for update NDB 高可用、 高性能、高可扩展性的数据库集群系统 Memory 默认使用的是哈希索引 -
简述事务及其特性? (3分)
事务用于将某些操作的多个SQL作为原子性操作,一旦有某一个出现错误,即可回滚到原来的状态,从而保证数据库数据完整性。 事务的特性: 原子性: 确保工作单元内的所有操作都成功完成,否则事务将被中止在故障点,和以前的操作将回滚到以前的状态。 一致性: 确保数据库正确地改变状态后,成功提交的事务。 隔离性: 使事务操作彼此独立的和透明的。 持久性: 确保提交的事务的结果或效果的系统出现故障的情况下仍然存在。 -
事务的隔离级别?(2分)
读未提交(read uncommitted) 一个事务还没提交时,它做的变更就能被别的事务看到 读提交(read committed) 一个事务提交之后,它做的变更才会被其他事务看到 可重复读(repeatable read) 一个事务执行过程中看到的数据,总是跟这个事务在启动时看到的数据是一致的。当然在可重复读隔离级别下,未提交变更对其他事务也是不可见的 串行化(serializable ) 顾名思义是对于同一行记录,“写”会加“写锁”,“读”会加“读锁”。当出现读写锁冲突的时候,后访问的事务必须等前一个事务执行完成,才能继续执行 -
char和varchar的区别?(2分)
varchar与char的区别char是一种固定长度的类型,varchar则是一种可变长度的类型 char是定长 ,用空间换时间 varchar,是可变长度,用时间换空间 -
mysql中varchar与char的区别以及varchar(50)中的50代表的含义。(2分)
varchar(50)表示最大长度为50字节 char(50)表示一个字符占50字节 -
MySQL中delete和truncate的区别?(2分)
delete 是删除一条数据,truncate是将这个表的所有数据都删除 -
where子句中有a,b,c三个查询条件, 创建一个组合索引abc(a,b,c),以下哪种会命中索引(3分)
(a) (b) (c) (a,b) (b,c) (a,c) (a,b,c)√ -
组合索引遵循什么原则才能命中索引?(2分)
- 1.只有对创建了索引的列进行条件筛选的时候效率才能提高 - 2.索引对应的列做条件不能参与运算、不能使用函数 - 3.当某一列的区分度非常小(重复率高),不适合创建索引 - 4.当范围作为条件的时候,查询结果的范围越大越慢,越小越快 - 5.like关键字 : 如果使用%/_开头都无法命中索引 - 6.多个条件 : 如果只有一部分创建了索引,条件用and相连,那么可以提高查询效率,如果用or相连,不能提高查询效率 -
列举MySQL常见的函数? (3分)
聚合函数 max/sum/min/avg 时间格式化 date_format 字符串拼接 concat(当拼接了null,则返回null) 截取字符串 substring 返回字节个数 length -
MySQL数据库 导入、导出命令有哪些? (2分)
导出sql文件可以使用mysqldump。 主要有如下几种操作: 1.导出整个数据库(包括数据库中的数据): mysqldump -u username -ppassword dbname > dbname.sql ; 2.导出数据库中的数据表(包括数据表中的数据): mysqldump -u username -ppassword dbname tablename > tablename.sql; 3.导出数据库结构(不包括数据,只有创建数据表语句): mysqldump -u username -ppassword -d dbname > dbname.sql; 4.导出数据库中数据表的表结构(不包括数据,只有创建数据表语句): mysqldump -u username -ppassword -d dbname tablename > tablename.sql。 导出:mysqldump --default-character-set=utf8 -u root -p news > news.sql 导入 连接数据库时: source sql文件路径 未连接数据库 mysql -h ip -u userName -p dbName < sqlFilePath (最后没有分号) 导入:mysql --default-character-set=utf8 -u root -p news<news.sql -
什么是SQL注入?(2分)
sql注入是一种将sql代码添加到输入参数中,传递到sql服务器解析并执行的一种攻击手法 -
简述left join和inner join的区别?(2分)
left join 是左连接 inner join是内连接 -
SQL语句中having的作用?(2分)
having过滤出符合条件的内容 -
MySQL数据库中varchar和text最多能存储多少个字符?(2分)
varchar(n) 表示n个字符,无论汉字和英文,MySql都能存入 n 个字符,仅实际字节长度有所区别 在UTF8状态下text: 65535/3=21845个汉字,约20000,存储空间占用:65535/1024=64K的数据; 在UTF8状态下的varchar,最大只能到 (65535 - 2) / 3 = 21844个汉字,英文也为 21844个字符串 -
MySQL的索引方式有几种?(3分)
单列 功能 普通索引:加速查找 唯一索引:加速查找 + 约束:不能重复(只能有一个空,不然就重复了) 主键(primay key):加速查找 + 约束:不能重复 + 不能为空 多列 联合索引(多个列创建索引)-----> 相当于单列的普通索引 联合唯一索引 -----> 相当于单列的唯一索引 ps:联合索引的特点:遵循最左前缀的规则 其他词语: ·· - 索引合并,利用多个单例索引查询;(例如在数据库查用户名和密码,分别给用户名和密码建立索引) - 覆盖索引,在索引表中就能将想要的数据查询到; -
什么时候索引会失效?(有索引但无法命中索引)(3分)
-
数据库优化方案?(3分)
1、创建数据表时把固定长度的放在前面() 2、将固定数据放入内存: 例如:choice字段 (django中有用到,数字1、2、3…… 对应相应内容) 3、char 和 varchar 的区别(char可变, varchar不可变 ) 4、联合索引遵循最左前缀(从最左侧开始检索) 5、避免使用 select * 6、读写分离 - 实现:两台服务器同步数据 - 利用数据库的主从分离:主,用于删除、修改、更新;从,用于查; 读写分离:利用数据库的主从进行分离:主,用于删除、修改更新;从,用于查 7、分库 - 当数据库中的表太多,将某些表分到不同的数据库,例如:1W张表时 - 代价:连表查询 8、分表 - 水平分表:将某些列拆分到另外一张表,例如:博客+博客详情 - 垂直分表:讲些历史信息分到另外一张表中,例如:支付宝账单 9、加缓存 - 利用redis、memcache (常用数据放到缓存里,提高取数据速度) 如果只想获取一条数据 - select * from tb where name=‘alex’ limit 1 -
什么是MySQL慢日志?(2分)
慢日志查询的主要功能就是,记录sql语句中超过设定的时间阈值的查询语句。例如,一条查询sql语句,我们设置的阈值为1s,当这条查询语句的执行时间超过了1s,则将被写入到慢查询配置的日志中. 慢查询主要是为了我们做sql语句的优化功能. 修改配置文件 slow_query_log = OFF 是否开启慢日志记录 long_query_time = 2 时间限制,超过此时间,则记录 slow_query_log_file = /usr/slow.log 日志文件 log_queries_not_using_indexes = OFF 为使用索引的搜索是否记录 下面是开启 slow_query_log = ON long_query_time = 2 log_queries_not_using_indexes = OFF log_queries_not_using_indexes = ON 注:查看当前配置信息: show variables like '%query%' 修改当前配置: set global 变量名 = 值 -
设计表,关系如下: 教师, 班级, 学生, 科室。(4分)
科室与教师为一对多关系, 教师与班级为多对多关系, 班级与学生为一对多关系, 科室中需体现层级关系。1. 写出各张表的逻辑字段 2. 根据上述关系表 a.查询教师id=1的学生数 b.查询科室id=3的下级部门数 c.查询所带学生最多的教师的id -
有staff表,字段为主键Sid,姓名Sname,性别Sex(值为"男"或"女"),课程表Course,字段为主键Cid,课程名称Cname,关系表SC_Relation,字段为Student表主键Sid和Course表主键Cid,组成联合主键,请用SQL查询语句写出查询所有选"计算机"课程的男士的姓名。(3分)
-
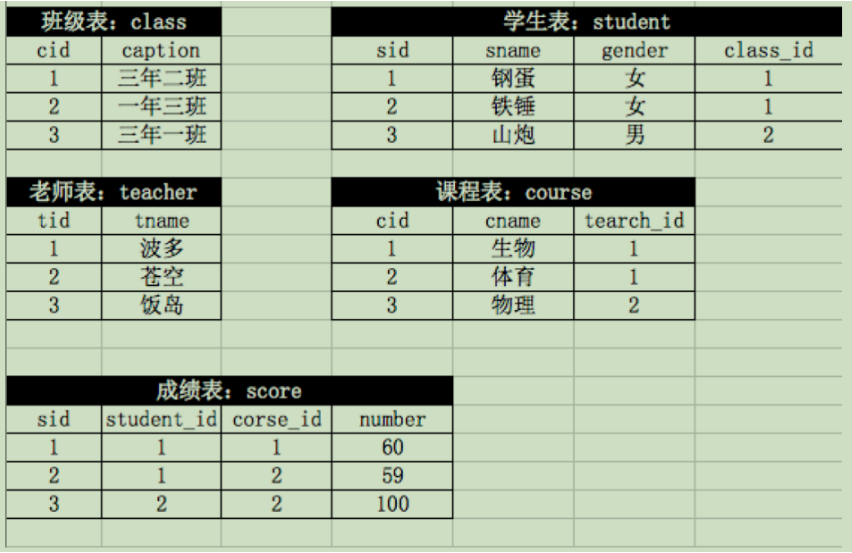
根据表关系写SQL语句(10分)
![]()
- 查询所有同学的学号、姓名、选课数、总成绩;
- 查询姓“李”的老师的个数;
- 查询平均成绩大于60分的同学的学号和平均成绩;
- 查询有课程成绩小于60分的同学的学号、姓名
- 删除学习“叶平”老师课的score表记录;
- 查询各科成绩最高和最低的分:以如下形式显示:课程ID,最高分,最低分;
- 查询每门课程被选修的学生数;
- 查询出只选修了一门课程的全部学生的学号和姓名;
- 查询选修“杨艳”老师所授课程的学生中,成绩最高的学生姓名及其成绩;
- 查询两门以上不及格课程的同学的学号及其平均成绩;
第二部分 补充题
-
什么是IO多路复用?
-
async/await关键字的作用?
-
MySQL的执行计划的作用?
-
简述MySQL触发器、函数、视图、存储过程?
-
数据库中有表:t_tade_date
id tade_date 1 2018-1-2 2 2018-1-26 3 2018-2-8 4 2018-5-6 ... 输出每个月最后一天的ID

 浙公网安备 33010602011771号
浙公网安备 33010602011771号