
Django rest framework之序列化小结
最近在DRF的序列化上踩过了不少坑,特此结合官方文档记录下,方便日后查阅。
【01】前言
serializers是什么?官网是这样的”Serializers allow complex data such as querysets and model instances to be converted to native Python datatypes that can then be easily rendered into JSON, XML or other content types. “翻译出来就是,将复杂的数据结构,例如ORM中的QuerySet或者Model实例对象转换成Python内置的数据类型,从而进一步方便数据和json,xml等格式的数据进行交互。
根据实际的工作经验,我来总结下serializers的作用:
1.将queryset与model实例等进行序列化,转化成json格式,返回给用户(api接口)。
2.将post与patch/put的上来的数据进行验证。
3.对post与patch/put数据进行处理。(后面的内容,将用patch表示put/patch更新,博主认为patch更贴近更新的说法)
简单来说,针对get来说,serializers的作用体现在第一条,但如果是其他请求,serializers能够发挥2,3条的作用!
用一张图来说明下它的作用:
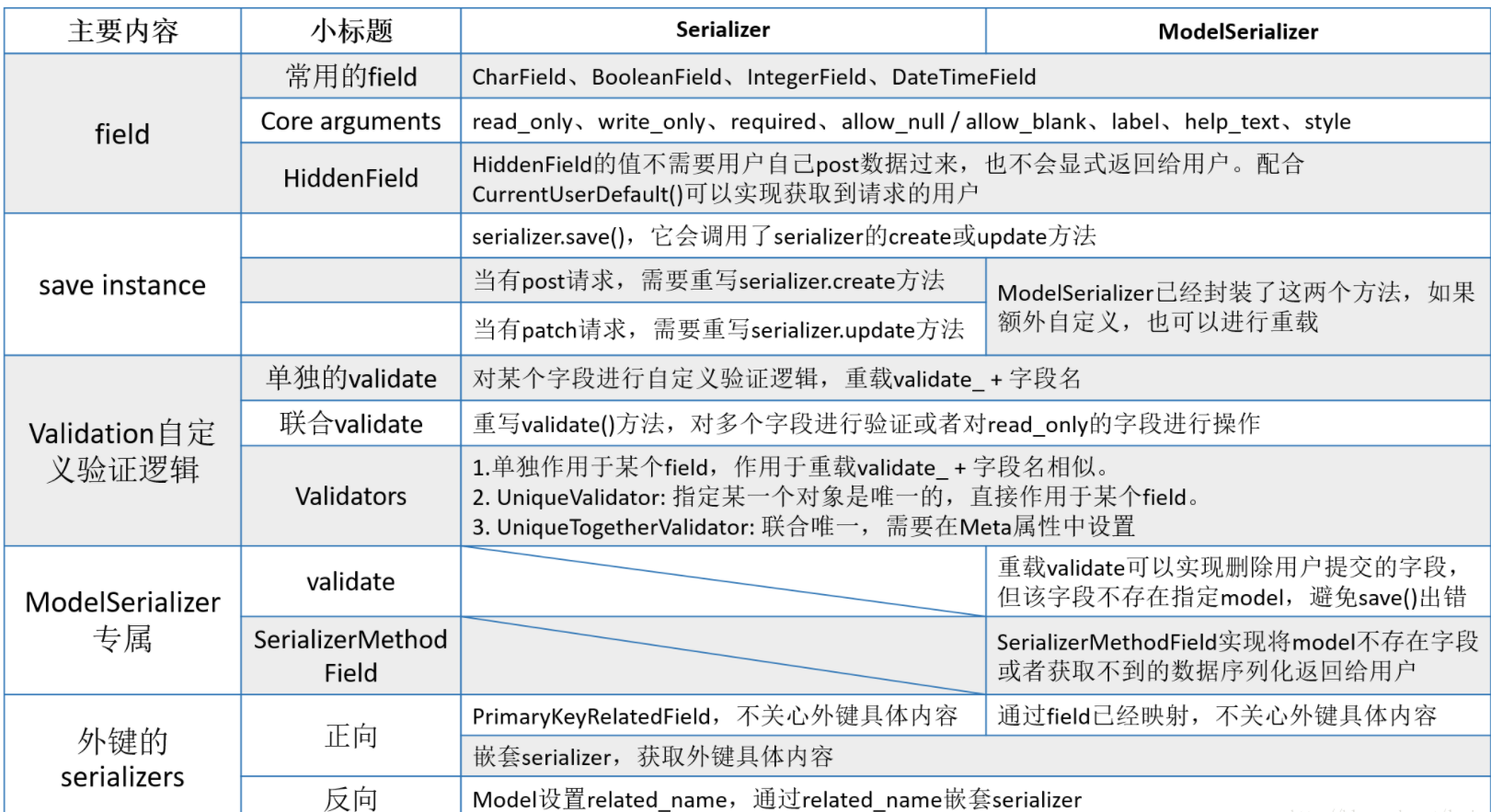
serializers.fieild:我们知道在django中,form也有许多field,那serializers其实也是drf中发挥着这样的功能。我们先简单了解常用的几个field。
1. 常用的field
CharField、BooleanField、IntegerField、DateTimeField这几个用得比较多,我们把外键的field放到后面去说!
参考如下的例子:
# 举例子
mobile = serializers.CharField(max_length=11, min_length=11)
age = serializers.IntegerField(min_value=1, max_value=100)
# format可以设置时间的格式,下面例子会输出如:2018-3-20 12:10
pay_time = serializers.DateTimeField(read_only=True,format='%Y-%m-%d %H:%M')
is_hot = serializers.BooleanField() # 例如设置商品是否热销
2. Core arguments参数
read_only:True表示不允许用户自己上传,只能用于api的输出。如果某个字段设置了read_only=True,那么就不需要进行数据验证,只会在返回时,将这个字段序列化后返回
举个简单的例子:在用户进行购物的时候,用户post订单时,肯定会产生一个订单号,而这个订单号应该由后台逻辑完成,而不应该由用户post过来,如果不设置read_only=True,那么验证的时候就会报错。再例如,我们在网上购物时,支付时通常会产生支付状态,交易号,订单号,支付时间等字段,这些字段都应该设置为read_only=True,即这些字段都应该由后台产生然后返回给客户端;举例如下:
pay_status = serializers.CharField(read_only=True)
trade_no = serializers.CharField(read_only=True)
order_sn = serializers.CharField(read_only=True)
pay_time = serializers.DateTimeField(read_only=True)
"""
在用户提交订单的时候,我们在这里给用户新增一个字段,就是支付宝支付的URL
要设置为read_only=True,这样的话,就不能让用户端提交了,而是服务器端生成
返回给用户的
"""
alipay_url = serializers.SerializerMethodField(read_only=True)
write_only:与read_only对应;就是用户post过来的数据,后台服务器处理后不会再经过序列化后返回给客户端;最常见的就是我们在使用手机注册的验证码和填写的密码。
required: 顾名思义,就是这个字段是否必填,例如要求:用户名,密码等是必须填写的;不填写就直接报错
allow_null/allow_blank:是否允许为NULL/空 。
error_messages:出错时,信息提示。
例如我们在定义用户注册序列化类时:
code = serializers.CharField(required=True, write_only=True, label="验证码", max_length=6, min_length=6,
error_messages={
"blank": "请输入验证码",
"required": "请输入验证码", #当用户不输入时提示的错误信息
"max_length": "验证码格式错误",
"min_length": "验证码格式错误"
},
help_text="验证码")
"""
验证用户名是否存在,allow_blank 不能为空;表示不允许用户名为空
"""
username = serializers.CharField(required=True, allow_blank=False, label="用户名",
validators=[UniqueValidator(queryset=User.objects.all(), message="用户已经存在")])
# 同理我们也应该将password设置write_only参数,不让它返回回去,这样容易被截获
password = serializers.CharField(
style={'input_type': 'password'}, help_text="密码", label="密码", write_only=True)
label: 字段显示设置,如 label=’验证码’
help_text: 在指定字段增加一些提示文字,这两个字段作用于api页面比较有用
style: 说明字段的类型,这样看可能比较抽象,看下面例子:
# 在api页面,输入密码就会以*显示
password = serializers.CharField(
style={'input_type': 'password'})
# 会显示选项框
color_channel = serializers.ChoiceField(
choices=['red', 'green', 'blue'],
style={'base_template': 'radio.html'})
3. HiddenField
HiddenField的值不依靠输入,而需要设置默认的值,不需要用户自己post数据过来,也不会显式返回给用户,最常用的就是user!!
我们在登录情况下,进行一些操作,假设一个用户去收藏了某一门课,那么后台应该自动识别这个用户,然后用户只需要将课程的id post过来,那么这样的功能,我们配合CurrentUserDefault()实现。
# 这样就可以直接获取到当前用户
user = serializers.HiddenField(
default=serializers.CurrentUserDefault())
再例如,我们在收藏某件商品的时候,后台要获取到当前的用户;相当于前台只需要传递过来一个商品的ID即可;那么在后台我根据当前的登入用户和当前的商品ID即可判断用户是否收藏过该商品;这就是一个联合唯一主键的判断;这同样需要使用HiddenField。
save instance
这个标题是官方文档的一个小标题,我觉得用的很好,一眼看出,这是为post和patch所设置的,没错,这一部分功能是专门为这两种请求所设计的,如果只是简单的get请求,那么在设置了前面的field可能就能够满足这个需求。
我们在view以及mixins的博客中提及到,post请求对应create方法,而patch请求对应update方法,这里提到的create方法与update方法,是指mixins中特定类中的方法。我们看一下源代码,源代码具体分析可以参考我的另外一篇博客:
# 只截取一部分
class CreateModelMixin(object):
def create(self, request, *args, **kwargs):
serializer = self.get_serializer(data=request.data)
serializer.is_valid(raise_exception=True)
self.perform_create(serializer)
headers = self.get_success_headers(serializer.data)
return Response(serializer.data, status=status.HTTP_201_CREATED, headers=headers)
def perform_create(self, serializer):
serializer.save()
class UpdateModelMixin(object):
def update(self, request, *args, **kwargs):
partial = kwargs.pop('partial', False)
instance = self.get_object()
serializer = self.get_serializer(instance, data=request.data, partial=partial)
serializer.is_valid(raise_exception=True)
self.perform_update(serializer)
if getattr(instance, '_prefetched_objects_cache', None):
# If 'prefetch_related' has been applied to a queryset, we need to
# forcibly invalidate the prefetch cache on the instance.
instance._prefetched_objects_cache = {}
return Response(serializer.data)
def perform_update(self, serializer):
serializer.save()
可以看出,无论是create与update都写了一行:serializer.save( ),那么,这一行,到底做了什么事情,分析一下源码。
在serializer.py文件中:
def save(self, **kwargs):
assert not hasattr(self, 'save_object'), (
'Serializer `%s.%s` has old-style version 2 `.save_object()` '
'that is no longer compatible with REST framework 3. '
'Use the new-style `.create()` and `.update()` methods instead.' %
(self.__class__.__module__, self.__class__.__name__)
)
assert hasattr(self, '_errors'), (
'You must call `.is_valid()` before calling `.save()`.'
)
assert not self.errors, (
'You cannot call `.save()` on a serializer with invalid data.'
)
# Guard against incorrect use of `serializer.save(commit=False)`
assert 'commit' not in kwargs, (
"'commit' is not a valid keyword argument to the 'save()' method. "
"If you need to access data before committing to the database then "
"inspect 'serializer.validated_data' instead. "
"You can also pass additional keyword arguments to 'save()' if you "
"need to set extra attributes on the saved model instance. "
"For example: 'serializer.save(owner=request.user)'.'"
)
assert not hasattr(self, '_data'), (
"You cannot call `.save()` after accessing `serializer.data`."
"If you need to access data before committing to the database then "
"inspect 'serializer.validated_data' instead. "
)
validated_data = dict(
list(self.validated_data.items()) +
list(kwargs.items())
)
if self.instance is not None:
self.instance = self.update(self.instance, validated_data)
assert self.instance is not None, (
'`update()` did not return an object instance.'
)
else:
self.instance = self.create(validated_data)
assert self.instance is not None, (
'`create()` did not return an object instance.'
)
return self.instance
显然,serializer.save的操作,它去调用了serializer的create或update方法,不是mixins中的!!!我们看一下流程图(以post为例):
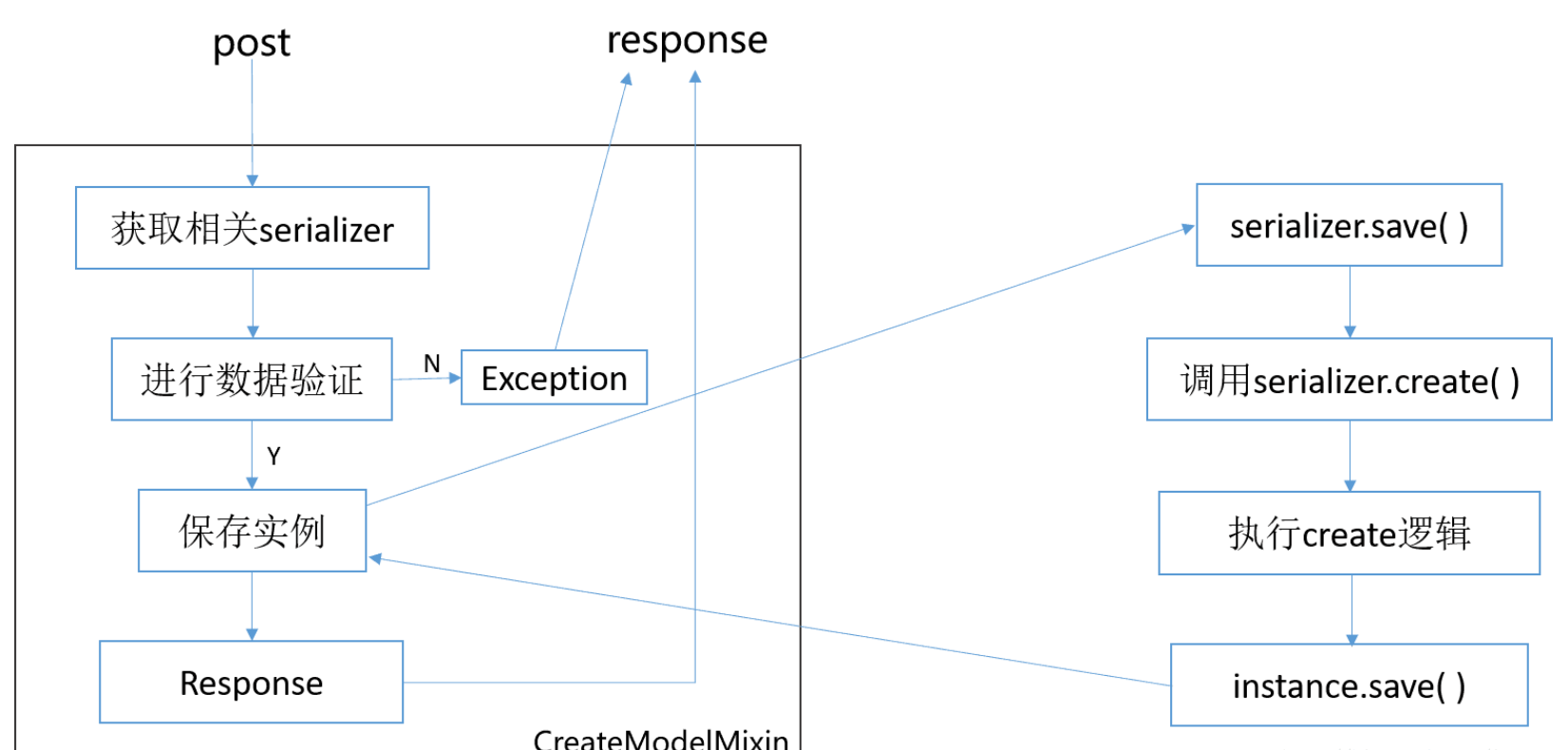
讲了那么多,我们到底需要干什么!重载这两个方法!!
如果你的viewset含有post,那么你需要重载create方法,如果含有patch,那么就需要重载update方法。
# 假设现在是个博客,有一个创建文章,与修改文章的功能, model为Article。
class ArticleSerializer(serializers.Serializer):
user = serializers.HiddenField(
default=serializers.CurrentUserDefault())
name = serializers.CharField(max_length=20)
content = serializers.CharField()
def create(self, validated_data):
# 除了用户,其他数据可以从validated_data这个字典中获取
# 注意,users在这里是放在上下文中的request,而不是直接的request
user = self.context['request'].user
name = validated_data['name ']
content = validated_data['content ']
return Article.objects.create(**validated_data)
def update(self, instance, validated_data):
# 更新的特别之处在于你已经获取到了这个对象instance
instance.name = validated_data.get('name')
instance.content = validated_data.get('content')
instance.save()
return instance
可能会有人好奇,系统是怎么知道,我们需要调用serializer的create方法,还是update方法,我们从save( )方法可以看出,判断的依据是:
if self.instance is not None:pass
那么我们的mixins的create与update也已经在为开发者设置好了:
# CreateModelMixin
serializer = self.get_serializer(data=request.data)
# UpdateModelMixin
serializer = self.get_serializer(instance, data=request.data, partial=partial)
也就是说,在update通过get_object( )的方法获取到了instance,然后传递给serializer,serializer再根据是否有传递instance来判断来调用哪个方法!
Validation自定义验证逻辑
单独的validate (这个就类似于Django中Form中的局部钩子函数)
我们在上面提到field,它能起到一定的验证作用,但很明显,它存在很大的局限性,举个简单的例子,我们要判断我们手机号码,如果使用CharField(max_length=11, min_length=11),它只能确保我们输入的是11个字符,那么我们需要自定义!就拿笔者在实际生产环境下的例子来说,光针对用户输入的手机号码,我们在后端就需要进行验证,例如该手机号码是否注册,手机号码是否合法(例如满足手机号码的zhengze表达式,以及要验证该手机号码向后台发送请求验证短信的频率等等)
class SmsSerializer(serializers.Serializer):
"""
为什不用ModelSerializer来完成手机号码的验证呢?
因为VerifyCode中还有一个字段是手机验证码字段,直接使用ModelSerializer来验证会报错
因为ModelSerializer会自动生成VerifyCode模型中的所有字段;但是
我们传递过来的就是一个手机号,判断它是否是合法的
因此使用Serializer来自定义合法性校验规则,相当于就是钩子函数
单独对手机号码进行验证
"""
mobile = serializers.CharField(max_length=11)
# 使用validate_字段名(self, 字段名):要么返回字段,要么抛出异常
def validate_mobile(self, mobile):
"""
验证手机号码,记住这里的validate_字段名一定要是数据模型中的字段
:param attrs:
:return:
"""
# 手机号码是否注册,查询UserProfile表即可
if User.objects.filter(mobile=mobile).exists():
raise serializers.ValidationError("用户已经存在")
# 验证手机号码是否合法,这部分应该是在前端做的,当然后台也需要进行验证
if not re.match(REGEX_MOBILE, mobile):
raise serializers.ValidationError("手机号码格式不正确")
# 验证发送频率,如果不做,用户可以一直向后台发送,请求验证码;
# 会造成很大的压力,限制一分钟只能发送一次 7-8 09:00
one_minute_ago = datetime.now() - timedelta(hours=0, minutes=1, seconds=0)
"""
如果添加时间在一分钟以内,它肯定是大于你一分钟之前的时间的
如果这条记录存在
"""
if VerifyCode.objects.filter(add_time__gt=one_minute_ago, mobile=mobile):
raise serializers.ValidationError("抱歉,一分钟只能发送一次")
# 如果验证通过,我就将这个mobile返回去,这里一定要有一个返回
return mobile
联合validate 这个就类似于全局钩子函数
上面验证方式,只能验证一个字段,如果是两个字段联合在一起进行验证,那么我们就可以重载validate( )方法。
start = serializers.DateTimeField()
finish = serializers.DateTimeField()
def validate(self, attrs):
# 传进来什么参数,就返回什么参数,一般情况下用attrs
if data['start'] > data['finish']:
raise serializers.ValidationError("finish must occur after start")
return attrs
这个方法非常的有用,我们还可以再这里对一些read_only的字段进行操作,我们在read_only提及到一个例子,订单号的生成,我们可以在这步生成一个订单号,然后添加到attrs这个字典中。看如下的代码:
class OrderSerializer(serializers.ModelSerializer):
user = serializers.HiddenField(
default=serializers.CurrentUserDefault()
)
pay_status = serializers.CharField(read_only=True)
trade_no = serializers.CharField(read_only=True)
order_sn = serializers.CharField(read_only=True)
pay_time = serializers.DateTimeField(read_only=True)
"""
在用户提交订单的时候,我们在这里给用户新增一个字段,就是支付宝支付的URL
要设置为read_only=True,这样的话,就不能让用户端提交了,而是服务器端生成
返回给用户的
"""
alipay_url = serializers.SerializerMethodField(read_only=True)
def get_alipay_url(self, obj): # obj就是OrderSerializer对象
alipay = AliPay(
appid="2016091200490227", # 沙箱环境中可以找到
app_notify_url="http://47.92.87.172:8000/alipay/return/",
app_private_key_path=private_key_path, # 个人私钥
alipay_public_key_path=ali_pub_key_path, # 支付宝的公钥,验证支付宝回传消息使用,不是你自己的公钥,
debug=True, # 默认False,上线的时候修改为False即可
return_url="http://47.92.87.172:8000/alipay/return/"
)
url = alipay.direct_pay(
# 一个订单里面可能有多个商品,因此subject
# 不适合使用商品名称
subject=obj.order_sn,
out_trade_no=obj.order_sn,
total_amount=obj.order_mount,
)
re_url = "https://openapi.alipaydev.com/gateway.do?{data}".format(data=url)
return re_url
def generate_order_sn(self):
"""
后台系统生成订单号
这个是系统后台生成的:
当前时间+userId+随机数
"""
random_ins = Random()
order_sn = "{time_str}{user_id}{random_num}".format(time_str=time.strftime("%Y%m%d%H%M%S"),
user_id=self.context["request"].user.id,
random_num=random_ins.randint(1000, 9999))
return order_sn
def validate(self, attrs): # 全局钩子函数
attrs["order_sn"] = self.generate_order_sn()
return attrs
class Meta:
model = OrderInfo
fields = "__all__"
这个方法运用在modelserializer中,可以剔除掉write_only的字段,这个字段只验证,但不存在于指定的model当中,即不能save( ),可以在这delete掉;例如短信验证码验证完毕后就可以删除了:
def validate(self, attrs):
"""
判断完毕后删除验证码,因为没有什么用了
"""
attrs["mobile"] = attrs["username"]
del attrs["code"]
return attrs
Validators
validators可以直接作用于某个字段,这个时候,它与单独的validate作用差不多;当然,drf提供的validators还有很好的功能:UniqueValidator,UniqueTogetherValidator等;UniqueValidator: 指定某一个对象是唯一的,如,用户名只能存在唯一:
username = serializers.CharField(required=True, allow_blank=False, label="用户名", max_length=16, min_length=6,
validators=[UniqueValidator(queryset=User.objects.all(), message="用户已经存在")],
error_messages={
"blank": "用户名不允许为空",
"required": "请输入用户名",
"max_length": "用户名长度最长为16位",
"min_length": "用户名长度至少为6位"
})
UniqueTogetherValidator: 联合唯一,例如我们需要判断用户是否收藏了某个商品,前端只需要传递过来一个商品ID即可。这个时候就不是像上面那样单独作用于某个字段,而是需要进行联合唯一的判断,即用户ID和商品ID;此时我们需要在Meta中设置。
class UserFavSerializer(serializers.ModelSerializer):
# 获取到当前用户
user = serializers.HiddenField(
default=serializers.CurrentUserDefault()
)
class Meta:
model = UserFav
"""
我们需要获取的是当前登入的user
以后要取消收藏,只需要获取这里的id即可
UniqueTogetherValidator作用在多个字段之上
因为是联合唯一主键
"""
validators = [
UniqueTogetherValidator(
queryset=UserFav.objects.all(),
fields=('user', 'goods'),
message="已经收藏"
)
]
fields = ("user", "goods", "id")
ModelSerializer
讲了很多Serializer的,在这个时候,我还是强烈建议使用ModelSerializer,因为在大多数情况下,我们都是基于model字段去开发。
好处:
ModelSerializer已经重载了create与update方法,它能够满足将post或patch上来的数据进行进行直接地创建与更新,除非有额外需求,那么就可以重载create与update方法。
ModelSerializer在Meta中设置fields字段,系统会自动进行映射,省去每个字段再写一个field。
class UserDetailSerializer(serializers.ModelSerializer):
"""
用户详情序列化
"""
class Meta:
model = User
fields = ("name", "gender", "birthday", "email", "mobile")
# fields = '__all__': 表示所有字段
# exclude = ('add_time',): 除去指定的某些字段
# 这三种方式,存在一个即可
ModelSerializer需要解决的2个问题:
1,某个字段不属于指定model,它是write_only,需要用户传进来,但我们不能对它进行save( ),因为ModelSerializer是基于Model,这个字段在Model中没有对应,这个时候,我们需要重载validate!
如在用户注册时,我们需要填写验证码,这个验证码只需要验证,不需要保存到用户这个Model中:
def validate(self, attrs):
del attrs["code"]
return attrs
2,某个字段不属于指定model,它是read_only,只需要将它序列化传递给用户,但是在这个model中,没有这个字段!我们需要用到SerializerMethodField。
假设需要返回用户加入这个网站多久了,不可能维持这样加入的天数这样一个数据,一般会记录用户加入的时间点,然后当用户获取这个数据,我们再计算返回给它。
class UserSerializer(serializers.ModelSerializer):
days_since_joined = serializers.SerializerMethodField()
# 方法写法:get_ + 字段
def get_days_since_joined(self, obj):
# obj指这个model的对象
return (now() - obj.date_joined).days
class Meta:
model = User
当然,这个的SerializerMethodField用法还相对简单一点,后面还会有比较复杂的情况。
关于外键的serializers
讲了那么多,终于要研究一下外键啦~
其实,外键的field也比较简单,如果我们直接使用serializers.Serializer,那么直接用PrimaryKeyRelatedField就解决了。
假设现在有一门课python入门教学(course),它的类别是python(catogory)。
# 指定queryset
category = serializers.PrimaryKeyRelatedField(queryset=CourseCategory.objects.all(), required=True)
ModelSerializer就更简单了,直接通过映射就好了
不过这样只是用户获得的只是一个外键类别的id,并不能获取到详细的信息,如果想要获取到具体信息,那需要嵌套serializer:
category = CourseCategorySerializer()
注意:上面两种方式,外键都是正向取得,下面介绍怎么反向去取,如,我们需要获取python这个类别下,有什么课程。
首先,在课程course的model中,需要在外键中设置related_name:
class Course(model.Model):
category = models.ForeignKey(CourseCategory, related_name='courses')
# 反向取课程,通过related_name
# 一对多,一个类别下有多个课程,一定要设定many=True
courses = CourseSerializer(many=True)
写到这里,我们的外键就基本讲完了!还有一个小问题:我们在上面提到ModelSerializer需要解决的第二个问题中,其实还有一种情况,就是某个字段属于指定model,但不能获取到相关数据。
假设现在是一个多级分类的课程,例如,编程语言–>python–>python入门学习课程,编程语言与python属于类别,另外一个属于课程,编程语言类别是python类别的一个外键,而且属于同一个model,实现方法:
parent_category = models.ForeignKey('self', null=True, blank=True,
verbose_name='父类目别',
related_name='sub_cat')
现在获取编程语言下的课程,显然无法直接获取到python入门学习这个课程,因为它们两没有外键关系。SerializerMethodField( )也可以解决这个问题,只要在自定义的方法中实现相关的逻辑即可!
courses = SerializerMethodField()
def get_courses(self, obj):
all_courses = Course.objects.filter(category__parent_category_id=obj.id)
courses_serializer = CourseSerializer(all_course, many=True,
context={'request': self.context['request']})
return courses_serializer.data
上面的例子看起来有点奇怪,因为我们在SerializerMethodField()嵌套了serializer,就需要自己进行序列化,然后再从data就可以取出json数据。
可以看到传递的参数是分别是:queryset,many=True多个对象,context上下文。这个context十分关键,如果不将request传递给它,在序列化的时候,图片与文件这些Field不会再前面加上域名,也就是说,只会有/media/img…这样的路径!
以上就是关于DRF的Serializer的小结,如果有错漏,烦请指正,后面我将把自己工作中遇到的坑分享出来,希望对大家有帮助!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号