基本数据类型之内置方法(二)
基本数据类型之内置方法(二)
字典的内置方法
1.类型转换
# 类型转换 data_dict = dict([['name', 'jerry'], ['age', 15]]) print(data_dict) # {'name': 'jerry', 'age': 15}
2.根据key取值
# 根据k取值 data_dict = {'name': 'jerry', 'age': 21} print(data_dict['name']) # jerry # print(data_dict['aaa']) # 报错 当字典的k值没有的话就会报错 print(data_dict.get('name')) # jerry print(data_dict.get('aaa')) # None 字典的k值没有不会报错,会返回None print(data_dict.get('aaa','sss')) # sss,当字典的k值不存在的时候会返回后面的值 print(data_dict.get('name','sss')) # jerry,当字典的k值存在的时候不会返回后面的值
3.修改值(字典也是可变类型)
# 修改值 data_dict = {'name': 'jerry', 'age': 21} print(id(data_dict)) # 2212839960512 data_dict['name'] = 'oscar' # 键存在是修改值 print(data_dict['name'],id(data_dict)) # oscar 2212839960512
4.添加键值对
# 添加键值对 data_dict = {'name': 'jerry', 'age': 21} data_dict['password'] = 111 # 键不存在是添加值 print(data_dict) # {'name': 'jerry', 'age': 21, 'password': 111}
5.统计字典中键值的个数
# 统计字典中键值的个数 data_dict = {'name': 'jerry', 'age': 21} print(len(data_dict)) # 2
6.成员运算(只能判断k值)
# 成员运算 data_dict = {'name': 'jerry', 'age': 21} print('jerry' in data_dict) # False print('name' in data_dict) # True
7.删除键值对
方式一:通用删除
# 通用删除 data_dict = {'name': 'jerry', 'age': 21} del data_dict['name'] print(data_dict) # v{'age': 21}
方式二:延迟删除
# 延迟删除 data_dict = {'name': 'jerry', 'age': 21} print(data_dict.pop('age')) # 21,还能使用,如果不使用就删除 print(data_dict) # {'name': 'jerry'}
方式三:随机删除
# 随机删除 data_dict = {'name': 'jerry', 'age': 21} print(data_dict.popitem()) # 随机弹出一个 ('age', 21) print(data_dict) # {'name': 'jerry'}
8.获取所有的键、值、键值对
1.获取所有的键
# 获取所有的键 data_dict = {'name': 'jerry', 'age': 21} print(data_dict.keys()) # dict_keys(['name', 'age']) 可以看成列表
2.获取所有的值
# 获取所有的值 data_dict = {'name': 'jerry', 'age': 21} print(data_dict.values()) # dict_values(['jerry', 21]) 可以看出列表
3.获取所有的键值对
# 获取所有的键值对 data_dict = {'name': 'jerry', 'age': 21} print(data_dict.items()) # dict_items([('name', 'jerry'), ('age', 21)]) 可以看成列表套元组
(注意:获取所有的键、值、键值对这三个方法在python2中返回的都是列表)
简单了解的字典内置方法
1.更新字典
# 更新字典 data_dict = {'name': 'jerry', 'age': 21} data_dict.update({'name': 'oscar','sex': 'man'}) print(data_dict) # 键值存在就修改,不存在就添加 {'name': 'oscar', 'age': 21, 'sex': 'man'}
2.快速创建字典
# 快速创建字典 data_dict = dict.fromkeys(['s1','s2','s3'],'你好') print(data_dict) # {'s1': '你好', 's2': '你好', 's3': '你好'}
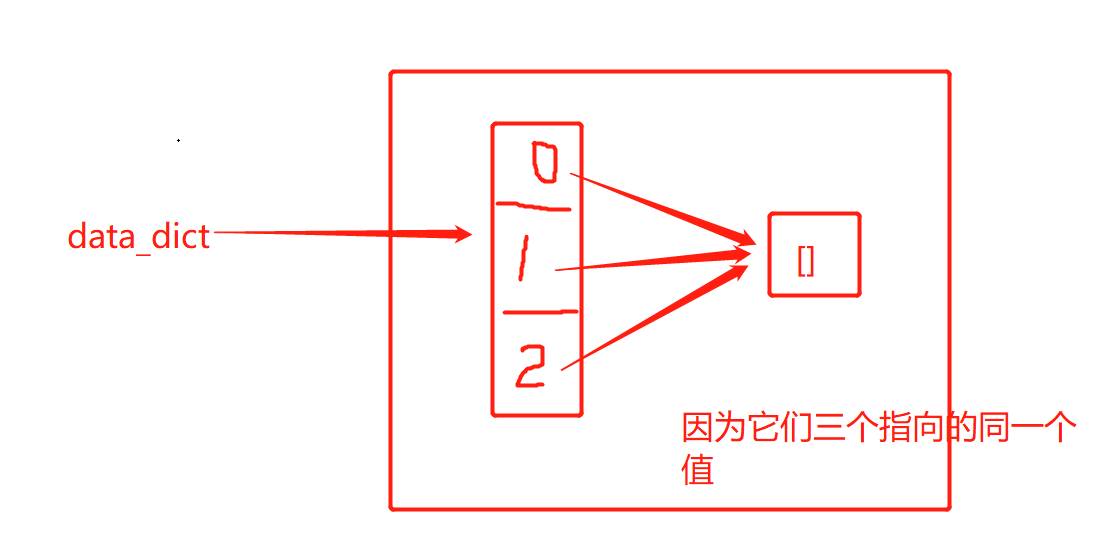
在这里讲一道题目:
data_dict = dict.fromkeys(['s1','s2','s3'],[]) data_dict['s1'].append([123]) # 那么输出的是什么? print(data_dict) # {'s1': [[123]], 's2': [[123]], 's3': [[123]]}
这是为什么呢?画个图就知道了:
3.setdefault()
data_dict = {'name': 'jerry', 'age': 21}
print(data_dict.setdefault('password', '123')) # 123 k值不存在时新增并返回v值
print(data_dict) # {'name': 'jerry', 'age': 21, 'password': '123'}
print(data_dict.setdefault('name','oscar')) # jerry k值存在时返回原来的值,并不做修改
print(data_dict) # {'name': 'jerry', 'age': 21, 'password': '123'}
元组的内置方法
特性:当元组内只有一个元素的时候 一定要在元素的后面加上逗号,能储存多个数据的基本数据类型,如果内部只有一个元素的话,后面也要加一个逗号。
1.类型转换
# 类型转换 # print(tuple(11)) # 报错 # print(tuple(11.11)) # 报错 print(tuple('jerry')) # ('j', 'e', 'r', 'r', 'y') print(tuple(['asd', 'zxc'])) # ('asd', 'zxc') print(tuple((11, 22, 33))) # (11, 22, 33) print(tuple({'name': 'jerry'})) # ('name',) # print(tuple(True)) # 报错
2.索引取值
# 索引取值 data_tuple = (11, 'jerry', 22, 44) print(data_tuple[1]) # jerry print(data_tuple[-1]) # 44
3.切片
# 切片 data_tuple = (11, 'jerry', 22, 44) print(data_tuple[0:2]) # (11, 'jerry') print(data_tuple[-3:-1]) # ('jerry', 22)
4.步长
# 步长 data_tuple = (11, 'jerry', 22, 44) print(data_tuple[0:3:2]) # (11, 22)
5.统计元素的个数
# 元素的个数 data_tuple = (11, 'jerry', 22, 44) print(len(data_tuple)) # 4
6.统计某个元素出现的个数
# 某个元素出现的次数 data_tuple = (11, 22, 11, 33, 22, 44) print(data_tuple.count(11)) # 2
7.成员运算
# 成员运算 data_tuple = (11, 'jerry', 22, 44) print(11 in data_tuple) # True
8.元组内元素的值不能修改:元组内各个索引指向的内存地址不能修改
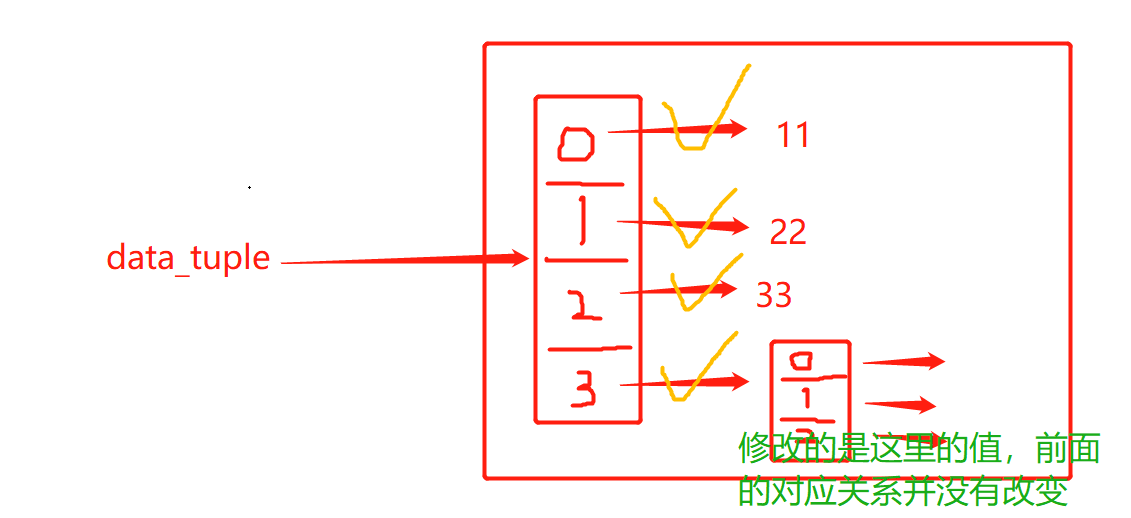
这里我们出一道题目:
data_tuple = ('jeery', 11, 22, [11, 22]) data_tuple[-1].append('33') print(data_tuple) # 程序会怎么样? # 答案:输出('jeery', 11, 22, [11, 22, '33'])
这是为什么呢?不是说元组内元素的值不能修改吗,这里为什么改了呢?看我画个图就知道了:
集合内置方法
1.类型转换
# 类型转换 # print(set(11)) # 报错 # print(set(11.11)) # 报错 # print(set(True)) # 报错 print(set('jeery')) # {'j', 'e', 'y', 'r'} print(set((11, 22, 33))) # {33, 11, 22} print(set({'name': 'jeery'})) # {'name'} print(set([11, 22, 'jeery'])) # {11, 'jeery', 22}
2.去重(集合内不能出现重复的元素,如果出现了,自动去重)
# 去重 data_set = {1, 1, 1, 2, 3, 5, 6} print(data_set) # {1, 2, 3, 5, 6}
3.关系运算(判断某个群体的差异)
# 关系运算 data_set = {1, 2, 3, 4} data_set1 = {2, 5, 4, 6} # 共有的 print(data_set & data_set1) # {2, 4} # 某个独有的 print(data_set - data_set1) # {1, 3} # 所有的 print(data_set | data_set1) # {1, 2, 3, 4, 5, 6} # 各自的 print(data_set ^ data_set1) # {1, 3, 5, 6}
垃圾回收机制
1.引用计数
python会将引用计数为零的数据清除。
name = 'jerry' # jeery引用计数为1 a = name # jeery引用计数为2
计数就是内存中一个值绑定变量名的个数。
2.标记清除
当内存空间快要溢出的时候,python会启动应急模式,挨个检查变量的计数,并将计数为0的变量标记起来,然后一次性删除。
3.分代回收
划分不同的等级,根据不同的等级来设置不同的时间间隔,去检查并计数回收为零的变量。
这里是IT小白陆禄绯,欢迎各位大佬的指点!!!


 浙公网安备 33010602011771号
浙公网安备 33010602011771号