(开集检测系列)open-Vocabulary object detection using captions
1、问题setting定义
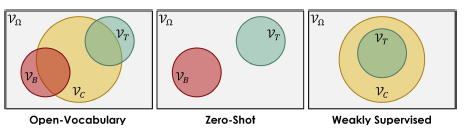
作者还特地比了一下三种setting,OVD跟ZSD的区别应该就是在训练时,OVD可能会用到target类的embedding信息(当然只是说这些embedding信息可能包含在一堆caption中,谁也不知道里面有没有target信息,肯定不能给target类的bbox信息),感觉这样的好处就像18年的ZSD中最后的DSES里面说的,可以在一个更加密集的embedding space里面实现进行视觉-文本特征的对齐,避免对齐的方向有问题。然后WSD是不能用base类的bbox信息并且要提前知道target类有哪些
2、动机
zsd setting是将trainable classifier换成fix word embedding,这样不管是base类的word embedding还是target类的word embedding都是在同一个embedding space里面,可以在转换测试类别时直接跟visual feature算相似度。但是作者指出了跟DSES同样的问题,在稀疏采样的base类上做对齐可能造成过拟合,因此作者提出了在更加密集的文本类采样空间里学习visual-text对齐,帮助视觉特征学习更加完整的语义信息,跟DSES引入dense类别的外部数据集不同,OVD还是用coco,只是用了粗粒度的image-caption标注,这样不用关心target类信息是否包含在caption标注里面,不用人为做一系列剔除等的预操作,感觉更加genelize一些。
3、框架
VFCNN为2截断检测,第一阶段使用大量的image-caption pair学习无边界的词汇概念,第二阶段使用第一阶段学会的词汇概念来学习少部分类型的目标检测;从模型架构图上,第一阶段主要学习 图片提取网络ResNet-50和V2L线性投影层(文章表达学习到的这个线性投影层很重要,图片投影层在更加大的语义空间训练的,所以可以映射出更加语义丰富的特征,因此第一阶段训练完,这个线性投影层在第二阶段fix使用)
整个模型的架构跟faster-rcnn几乎完全一样,只是将最后的cls head换成了v2l(也就是换成了一个将visual feature投影到word embedding space的投影矩阵),所以其实文章的核心就是在训练这个投影矩阵
3.1、第一阶段image-caption弱监督预训练
按照作者在文中的叙述,他们的word embedding获取方式应该不是从glove之类的预训练方式得到的,而是从预训练的BERT编码得到的。作者的最终目的就是要将经过v2l的visual feature e_i^I和word embedding e_j^C对齐(所以为啥还会有后面的multimodel transformer呢,这个一会儿再说)
由于image-caption本身是一种粗粒度的对齐方式,因此作者给的监督约束也是类似于弱监督的ground方式,本质上就是用attention聚合一种全局对齐作为图像-文本匹配的得分
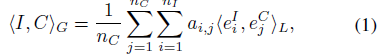
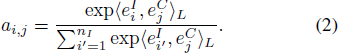
然后用contrastive loss来训练
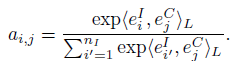
直观上来说,貌似做到这儿就ok了,因为已经可以训练v2l了。但是作者认为这种弱监督方式可能使得模型只学到能正确匹配视觉-文本的最少信息量,陷入局部最优(可能类似于是学一些简单的先验信息就能完成这个任务吧?比如出现啥单词,啥视觉概念就会将他们匹配到一起),学到的v2l会丢失很多语义信息。因此有了后面的multimodel transformer,主要是通过完成MLM(就是掩码单词预测,只不过利用多模态信息,应该就是希望经过v2l的变换后也能尽可能保留视觉信息来帮助补全单词)和ITM(image-text match,也就是再输出一次匹配分数,不是很懂这个存在的意义,可能就是为了直接用pixelbert),最后的损失函数就是
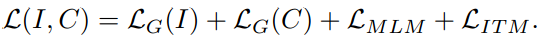
ps:预训练的时候bert是固定的,multimodel transformer是放开训的。
3.2、第二阶段base类bbox监督训练
有了预训练的v2l之后,剩下的就是训练主体的framework了,其实跟训通常的faster rcnn区别就是:
1)固定v2l和word embedding(作者在原文中合称classifier)
2)背景类分数是直接给了个margin(比如0,exp(0)=1,作者在文中尝试设置0.2比较work)
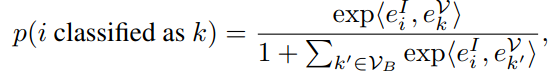
此外,尽管V2L是在grid feature上训的,不过ROI Align操作也是将形状不固定的bbox变成固定的,所以也没啥gap
4、效果:
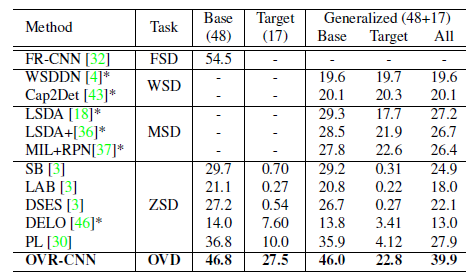
5、消融实验
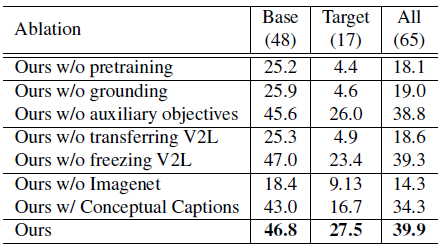
消融实验说明:
1)可以不用MLM,ITM,但是不能丢掉grounding,也就是说multimodel transformer是可选项
2)V2L训好后就要fix住
3)预训练的时候就要用imagenet上训好的r50
4)预训练时去掉conceptual caption数据集对结果的影响也算是挺大的,尤其是target类上
(感觉总结下来就是说要用grounding的方式预训练一个V2L,并且用的时候fix住,预训练的数据集越大越好)
5、结果可视化
作者将word embedding作为prototype,将v2l输出的特征用tsne进行了2维可视化,验证OVD的预训练方式确实得到了更好的视觉-文本对齐(emmmm反正就是个可视化结果,这肯定的吧,毕竟一个AP50 4.4,一个27.5)
参考https://zhuanlan.zhihu.com/p/419255664

 浙公网安备 33010602011771号
浙公网安备 33010602011771号