爬虫之Requests模块
1. 简介
requests模块是python中原生的基于网络请求的模块,主要用来模拟浏览器发起请求,而且功能强大,用法简洁高效。在使用urllib模块时,需要手动处理url编码和post请求参数,也需要处理cookie,而且代理操作繁琐。使用requests模块会自动处理url编码和post请求参数,并能简化cookie和代理操作
2. 如何使用
1. 下载安装:pip install requests
2. 使用流程:指定url;基于requests模块发起请求,获取响应对象;获取响应对象中的数据值;持久化存储响应数据
3. 需要的参数:
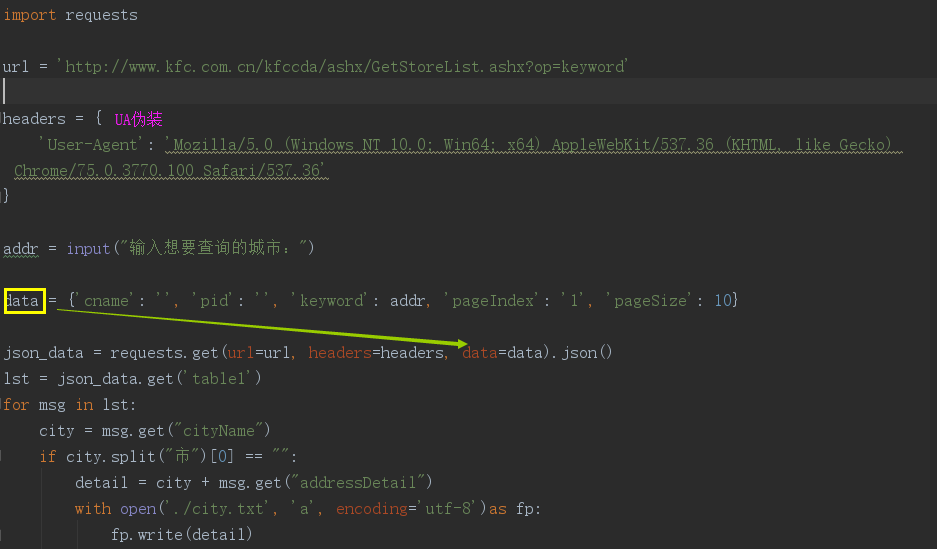
(1) params参数,get请求中需要的携带的参数;data参数,是post请求中需要携带的参数
(2) UA监测和伪装:访问网站时,网站会对当前请求载体的身份标识进行监测,所以需要在爬虫程序中进行User-Agent伪装
比如:爬取肯德基餐厅地址信息
3. session处理cookie问题
cookie概念:当用户通过浏览器首次访问一个域名时,访问的web服务器会给客户端发送数据,来保持web服务端与客户端之间的状态
cookie作用:在浏览器中经常涉及到数据交换,比如在登录一个页面时,经常会有提醒设置30天内记住或者自动登录选项。它们就是通过cookie来记录信息,Cookie是由HTTP服务器设置的,保存在浏览器中,但HTTP协议是一种无状态协议,在数据交换完毕后,服务器端和客户端的链接就会关闭,每次交换数据都需要建立新的链接。就像我们在高校用CMCC-EDU校园网,没有设置自动登陆时,每一次使用都需要输入用户名和密码,而当我们设置了自动登陆时,在每一次连接时就不用再输入用户名和密码了。
所以,当我们需要爬取某项具体信息时,就需要在headers中添加cookie参数,再把headers参数作用到get或者post方法的headers中;在添加cookie时,可以手动处理也可以自动进行处理。在自动处理时就需要借助session来实现,而session会很占用资源,要大于requests
# 使用session发起请求,如果请求过程中产生cookie,就会把cookie自动存储到session中 # 创建一个session对象 session = requests.Session() # 访问url,获取url中携带的cookie session.get("url地址", headers=headers) # 获取到url中携带的cookie后,就可以携带cookie进行请求发送
4. 基于requests的代理操作
代理是什么:代理的服务器,可以用作拦截请求和响应,第三方代替本身处理一些事务。比如我们生活中的代购、中介等;
代理流程:先将请求发送给代理ip,再由代理ip向真整的服务器发起请求
代理匿名度:透明代理,使用透明代理,服务器方能监测到使用的是代理ip,并且能监测到真正的ip;匿名代理:对方服务器知道使用了代理,但监测不到真实ip;高匿:对方服务器不知道使用了代理,而且也监测不到真实ip
为什么要使用代理:
大多数网站都有相应的反爬虫措施,会检测某个时间段内某个ip的访问次数,如果访问频率太快不像是正常访客,就可能会禁掉这个ip对服务器的访问,所以需要设置一些代理ip,作为连接池;每隔一段时间可以换一个代理ip,就算ip被禁止,依旧可以换一个ip继续获取数据。
代理分类:
正向代理,代理客户端获取数据,保护客户端防止被追究责任;
反向代理:代理服务器提供数据,为保护服务器或者负载均衡
免费代理ip网站:http://www.goubanjia.com/;站大爷


import requests if __name__ == "__main__": header = { "User-Agengt": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_0) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11" } proxy = {"https": "121.41.171.223:3128"} url = "http:www.baidu.com/s?ie=UTF-8&wd=ip" request.get(url=url, headers=header, proxies=proxy) with open("detail.html", "wb", encoding="utf-8")as fp: fp.write(response.content)
5. 基于线程池的数据爬取
异步操作可以和非异步操作结合使用,线程池多应用在比较耗时的操作中
# 基于异步操作的requests模块 import requests from lxml import etree header = { "User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_0) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11" } url = "http://www.pearvideo.com/category_1" # 获取页面数据 page_text = requests.get(url=url, headers=header).text # 获取相关视频详情链接进行解析 tree = etree.HTML(page_text) li_list = tree.xpath('//div[@id="listvideoList"]/ul/li') # 存储二级页面的url detail_urls = [] for li in li_list: detail_url = 'http://www.pearvideo.com/'+li.xpath('./div/a/@href')[0] title = li.xpath('.//div[@class="vervideo-title"]/text()')[0] detail_urls.append(detail_url) # 存储视频的url vedio_urls = [] for url in detail_urls: page_text = requests.get(url=url,headers=headers).text vedio_url = re.findall('srcUrl="(.*?)"',page_text,re.S)[0] vedio_urls.append(vedio_url) # 使用线程池进行视频数据下载 func_request = lambda link:requests.get(url=link,headers=headers).content video_data_list = pool.map(func_request,vedio_urls) #使用线程池进行视频数据保存 func_saveData = lambda data:save(data) pool.map(func_saveData,video_data_list) def save(data): fileName = str(random.randint(1,10000))+'.mp4' with open(fileName,'wb') as fp: fp.write(data) print(fileName+'已存储') pool.close() pool.join() # 进程和线程是不能无限开启的,进程池和线程池可以适当的提升爬取的效率,但并不是最优选择

 浙公网安备 33010602011771号
浙公网安备 33010602011771号