20242120 实验四 Python综合实践实验报告
Python综合实践实验报告
课程:《Python程序设计》
班级: 2421
姓名: 庞耀
学号:20242120
实验教师:王志强
实验日期:2025年5月14日
必修/选修: 公选课
一、课程总结
Python应该是我最早接触的编程语言,高中时期就已经在学校机房打印过"hello world",然而当时并没有用心学习。本学期,有幸抢到了王老师的Python公选课,十分高兴,一方面是早就从学长口中了解到王老师是一个优秀,幽默的老师;另一方面,能够通过这门课拓宽自己的编程能力,学到更多东西。本学期的课程可以说是干货满满,从最基础的语法到较为高阶的数据库和爬虫,我渐渐领悟到Python作为一种面向对象的编程语言的真正魅力。再次感谢王老师!如果可以提出一些建议,我希望王老师放慢一些课程节奏。下面来说说最后一次综合实践的具体内容吧。当下人工智能崛起迅速,我是计算机科学与技术专业的学生,刚刚加入了网空系卓越班,学习智能工程方向,想借着这个契机,先简单地实现一个单层线性人工神经网络,完成天气预测的任务。
二、需求分析与实验思路
每日最高气温一般由三个因素决定:前一日的最高温,前一日的降水量,以及前一日的风速。因此,在已知今日三个天气数据的情况下,能够采取一些手段,预测第二天的最高气温。在这里,我采用人工神经网络中最简单的线性回归模型实现这个功能。本次实验的大致纲要如下:
1.配置虚拟环境
2.获取一个城市的历史天气情况,作为训练数据
3.构建模型并训练模型
4.利用训练好的模型实现最高气温预测
下面是对线性回归模型的简要介绍:
线性模型:单层神经网络

优化方法-梯度下降

三. 实验过程与实验结果
1.配置虚拟环境
目前主流的研究人工智能模型的工具有很多,我选择应用最为广泛的PyTorch完成本次实验。
(1)安装annaconda
访问 anaconda官网,注册账号后下载最新版本anaconda
(2)配置虚拟环境pytorch_env
打开Anaconda Prompt,输入以下命令
conda create -n pytorch_env python=3.12
(选择Python版本为3.12,创建虚拟环境名为pytorch_env)
创建成功后激活环境
conda activate pytorch_env
(3)安装PyTorch的CPU和GPU版本
CPU:
conda install pytorch torchvision torchaudio cpuonly -c pytorch
GPU:
conda install pytorch torchvision torchaudio pytorch-cuda=12.6 -c pytorch -c nvidia
由于本次训练量较小,因此后续代码放入CPU中计算
安装完成后通过下面代码检查是否成功:
import torch
print(torch.__version__)
print(torch.cuda.is_available())
print(torch.cuda.get_device_name(0))
检查结果如下:
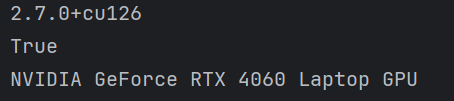
(4)安装其他需要的python库
本实验中后续还涉及文件处理,绘制散点图,绘制GUI图形界面等内容,统一在终端中使用pip安装
(5)在Pycharm中配置conda解释器
设置中搜索Python解释器,点击"添加新的解释器",选择添加本地解释器,选择现有。找到conda路径,生成新的环境即可,配置过程如下:
环境配置成功!
2.获取历史天气情况作为训练数据
进入网址Seattle Weather Dataset,下载csv文件到Pycharm项目目录下(命名为synthetic_weather_data.csv)
后续通过pandas库处理csv文件
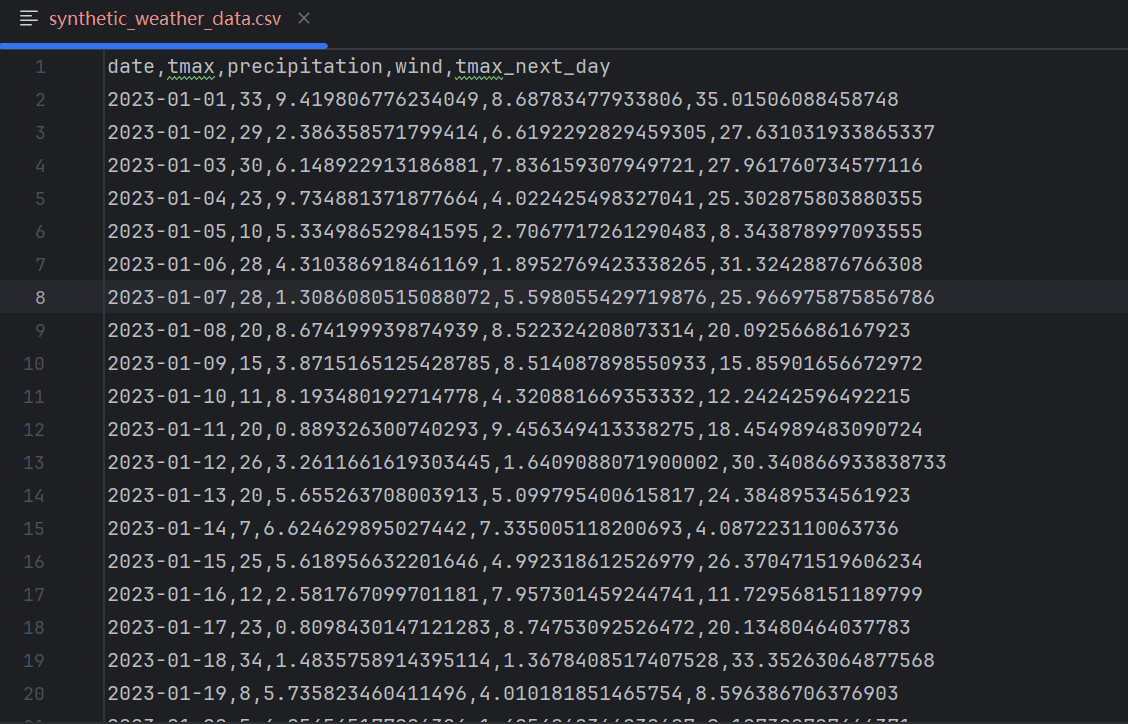
至此准备工作完成
3.构建模型并训练模型
(1)导入必要的库
import torch
import pandas as pd #c处理csv文件
import matplotlib.pyplot as plt#数据可视化
from torch import nn #借助已有模型
import tkinter as tk #应用端可视化
from tkinter import messagebox
(2)准备数据,利用pd库读取已有的csv文件
data=pd.read_csv('synthetic_weather_data.csv')
features=data[['tmax','precipitation','wind']].values
labels=data['tmax_next_day'].values
将csv文件中所有数据读取到data中,.values()将数据转为numpy格式,便于后续处理,区分features(特征)和labels(标签)
X=torch.tensor(features,dtype=torch.float32)
y=torch.tensor(labels,dtype=torch.float32).view(-1,1)
将特征和标签转换为tensor张量,准备放入CPU中计算
转换完成后,X形状为(100,3);y形状为(100,1),为列向量
(3)打乱数据,划分训练数据与测试数据
indices=torch.randperm(len(X))
X=X[indices]
y=y[indices]
train_size=int(0.8*len(X))
X_train,X_test=X[:train_size],X[train_size:]
y_train,y_test=y[:train_size],y[train_size:]
这里创建了一个乱序一维张量indices(0--len(X)-1),打乱原本的X,y的顺序,但保证X,y对应关系不变;取总数据中80%作为训练数据,剩余20%作为训练完成后的测试数据
(4)数据归一化
mean = X_train.mean(dim=0)#均值
std = X_train.std(dim=0)#方差
X_train = (X_train - mean) / std
X_test = (X_test - mean) / std
作用是将数据转化为均值为0,标准差为1d的分布
(5)模型构建
class Net(nn.Module):
def __init__(self):
super(Net,self).__init__()
self.linear = nn.Linear(in_features=X_train.shape[1],out_features=1)
#前向传播
def forward(self,x):
return self.linear(x)
#实例化模型
model=Net()
#采用均方损失
Loss=nn.MSELoss()
#采用sgd梯度下降优化参数,学习率定为0.01
trainer = torch.optim.SGD(model.parameters(),lr=0.01)
定义了一个Net类,作为实验模型框架,继承nn.Module的方法,便于后续简化操作。其中super(Net,self).__init__()为固定语法,作用为调用父类nn.Module的构造函数,确保模型正确初始化。
模型的核心是线性层self.linear,作用是线性回归,计算XW+b并返回
(6)训练模型
#训练次数500次
epochs=500
#记录损失
loss_history=[]
for epoch in range(epochs):
outputs=model(X_train)
loss=Loss(outputs,y_train)
#清空过往梯度
trainer.zero_grad()
#反向传播
loss.backward()
#更新参数
trainer.step()
loss_history.append(loss.item())
#每五十轮打印一次损失
if (epoch+1)%50==0:
print(f"epoch:{epoch+1},loss:{loss.item():.4f}")
清空过往梯度意义在于防止模型自动运作,参数更新时污染相应计算图
更新参数可替换为手写,代码如下:
with torch.no_grad():
for param in net.parameters():
param-=lr*param.grad
(7)绘制损失函数,验证模型并绘制预测结果与实际值对比图
plt.plot(loss_history)
#设置x,y轴标签
plt.xlabel('epoch')
plt.ylabel('loss')
plt.title('Train_loss')
plt.show()
model.eval()
with torch.no_grad():
y_pred=model(X_test)
y_true_np=y_test.numpy()
y_pred_np=y_pred.numpy()
#创建散点图
plt.scatter(x=y_true_np,
y=y_pred_np,
alpha=0.5,
)
plt.plot([min(y_true_np), max(y_true_np)],
[min(y_true_np), max(y_true_np)],
'r--', lw=2)#红色虚线,线宽为2
plt.xlabel('True Values')
plt.ylabel('Predictions')
plt.title('Prediction vs True Value')
plt.show()
model.eval()目的在于切换为评估模式,不改变模型参数,将X_test放入模型中运算得到y_pred,即测试数据的预测值;使用plt库绘制图像
模型已经搭建完毕
(8)绘制用户使用的图形界面
def create_gui():
window=tk.Tk()
window.title("天气预测")
window.geometry("300x200")
window.iconbitmap("test.ico")
window_labels=["今日最高气温(°C):","降水量(mm):","风速(km/h):"]
entries=[]
创建主窗口windows,将窗口命名为“天气预测”,大小为300×200像素,图标换为自己喜欢的火影角色自来也;将窗口中所有将要用到的标签存入labels中。创建一个空列表用于存储后续用户输入的数据
for i,text in enumerate(window_labels):
tk.Label(window,text=text).grid(row=i,column=0,padx=5,pady=5)
entry=tk.Entry(window)
entry.grid(row=i,column=1,padx=5,pady=5)
entries.append(entry)
result_label=tk.Label(window,text="预测明日最高温:")
result_label.grid(row=4,columnspan=2,pady=10)
将标签文本依次布局在窗口中,在其后依次增加输入框(entries)
def predict():
try:
inputs=[e.get() for e in entries]
new_data=[float(x) for x in inputs]
if len(new_data)!=3:
raise ValueError('需要三个数值')
input_tensor=torch.tensor(new_data,dtype=torch.float32)
norm_input_tensor=(input_tensor-mean)/std
with torch.no_grad():
prediction=model(norm_input_tensor)
result_label.config(text=f"预测明日最高气温{prediction.item():.1f}°C")
except ValueError as e:
messagebox.showerror("输入错误",str(e))
for item in entries:
item.delete(0,tk.END)
读取输入框中输入的数据,将其转化为tensor格式,如果用户输入数据不完全,则报错,并清除输入框中所有数据,如果成功,调用模型,计算第二日最高气温并打印在界面中。
tk.Button(window,text="开始预测",command=predict).grid(row=3,columnspan=2)
window.mainloop()
if __name__=="__main__":
create_gui()
最后增加按钮,输入所有数据后按下即可执行代码开始预测,开启界面主循环
实验结果
1.终端
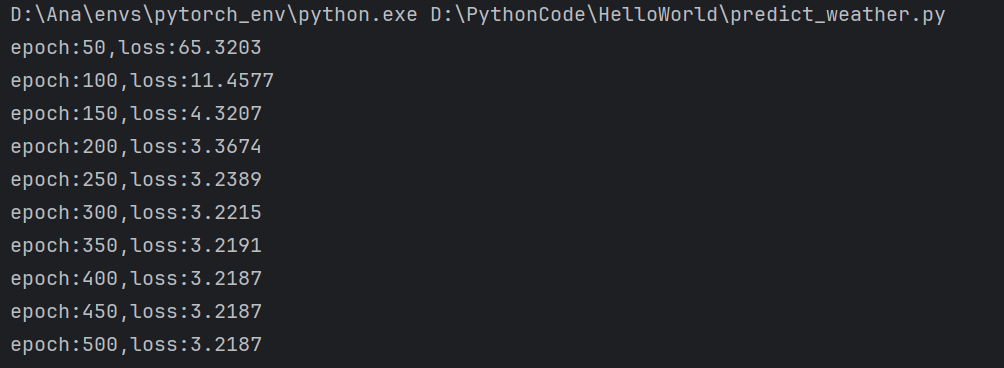
实现了预定的每训练50次打印依次损失值,最后损失值趋于稳定,达到了这个简单模型能够实现的最优解
2.损失函数图与预测结果,真实值对比图
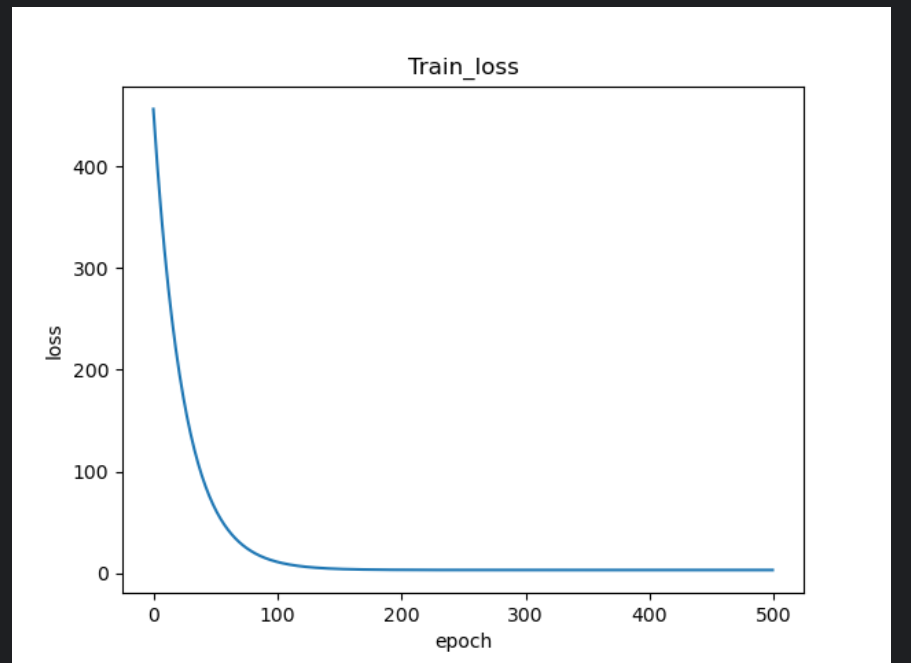
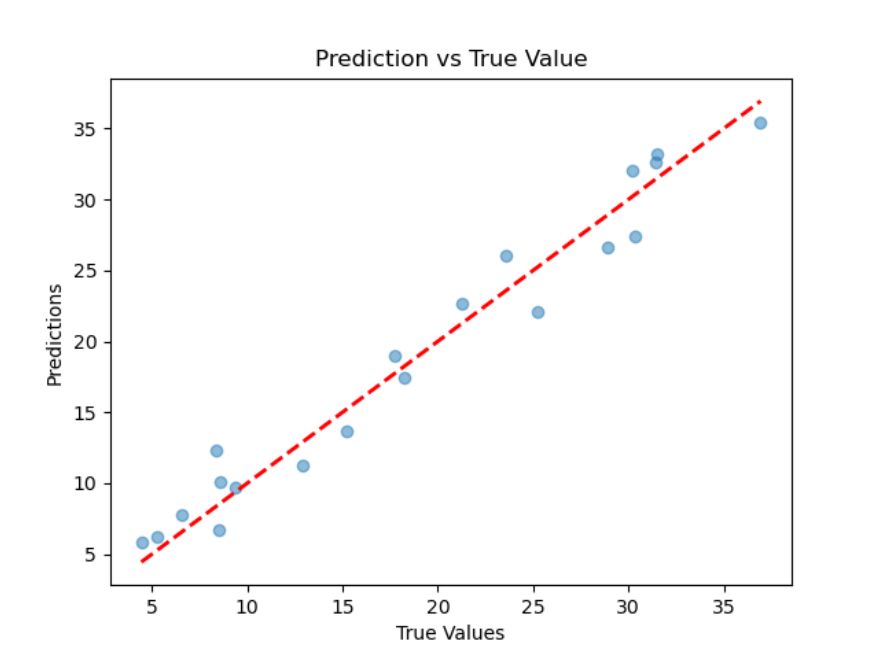
可以看到预测结果散点基本位于标准线两侧,距离标准线较近,经判断可以初步达到预测目的。
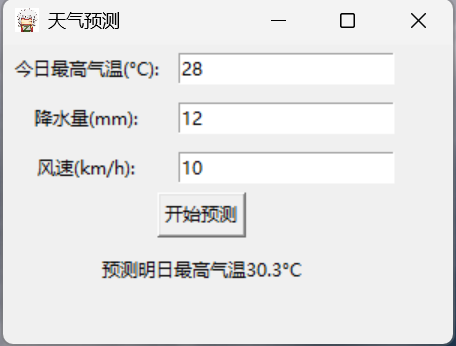
3.用户使用界面
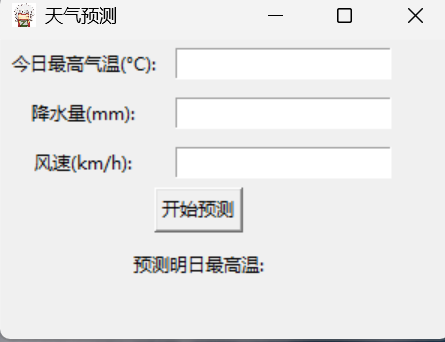
在此界面中依次输入相关数据,点击“开始预测”按钮即可开始预测第二日最高气温
四、实验问题及解决
1.下载完PyTorchGPU版本后无法正常使用
在配置虚拟环境时,我最初下载的是CUDA118版本,然而运行测试代码时发生报错。询问DeepSeek后得知,报错的原因是CUDA版本与PyTorch版本不匹配。查询NVIDIA官网查询后得知,需要下载CUDA126版本。通过清除环境,重新安装的操作后,配置成功
2.模型训练时终端中的损失值发生较大幅度波动
初次训练模型时,观察终端中打印的损失值发现,训练前期损失值快速下降,接近后期时发生波动,最终没有达到最小值。查询了李沐老师书籍《动手学深度学习》及观看相关视频后,认为应该是学习率过大导致的。多次重新训练模型,逐渐降低学习率,将其调整到合适值,最终损失值趋于稳定。
五、思考与感悟
本次结课实验是对这学期公选课内容的一个很好的结束,一方面,我在这次实验中复习了几乎所有Python的基础知识,从最简单的print,到类,方法的创建;从Python的下载,到机器学习环境的搭建和各种库的下载,导入,运用,我真正实现了“Python编程从入门到实践”,而非“Python编程从入门到放弃”。另一方面,当下人工智能正以一种革命般的状态席卷全球,改变着我们的生活,学习Python,研究人工智能的底层逻辑能让我更好的理解和运用人工智能。虽然受到时间限制,在本次实验中我仅仅实现了最为基础的单层线性人工神经网络,但日后我会继续学习深度学习,了解CNN,RNN等更深层次的内容,在大创项目中将人工智能与其他领域进行结合,学以致用,我相信这是最好的学习路径。最后,再次感谢王老师一学期的引导和栽培!!!
六 、参考资料
- 《Python编程从入门到实践》第十章文件操作
- 《动手学深度学习》-李沐 在线电子版
- 《动手学深度学习》 配套视频

 浙公网安备 33010602011771号
浙公网安备 33010602011771号