
通过spark-sql快速读取hive中的数据
1 配置并启动
1.1 创建并配置hive-site.xml
在运行Spark SQL CLI中需要使用到Hive Metastore,故需要在Spark中添加其uris。具体方法是将HIVE_CONF/hive-site.xml复制到SPARK_CONF目录下,然后在该配置文件中,添加hive.metastore.uris属性,具体如下:
<configuration>
<property>
<name>hive.metastore.uris</name>
<value>thrift://hadoop1:9083</value>
<description>Thrift URI for the remote metastore. Used by metastore client to connect to remote metastore.</description>
</property>
</configuration>

将mysql的jdbc驱动包拷贝给spark
将 $HIVE_HOME/lib/mysql-connector-java-5.1.12.jar copy或者软链到$SPARK_HOME/lib/
1.2 启动Hive Metastore
在使用Spark SQL CLI之前需要启动Hive Metastore(如果数据存放在HDFS文件系统,还需要启动Hadoop的HDFS),使用如下命令可以使Hive Metastore启动后运行在后台,可以通过jobs查询:
$nohup hive --service metastore > metastore.log 2>&1 &

1.3 启动Spark集群和Spark SQL CLI
通过如下命令启动Spark集群和Spark SQL CLI:
$cd /app/hadoop/spark-1.1.0 $sbin/start-all.sh $bin/spark-sql --master spark://hadoop1:7077 --executor-memory 1g
在集群监控页面可以看到启动了SparkSQL应用程序:

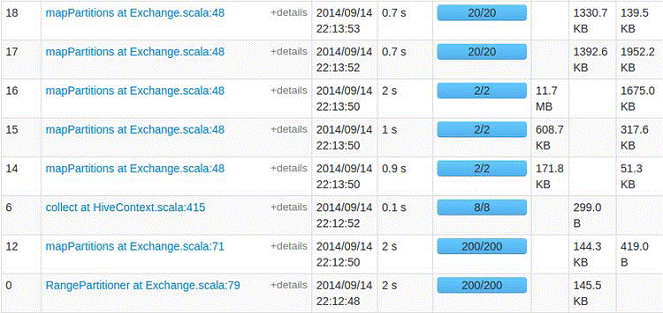
这时就可以使用HQL语句对Hive数据进行查询,另外可以使用COMMAND,如使用set进行设置参数:默认情况下,SparkSQL Shuffle的时候是200个partition,可以使用如下命令修改该参数:
SET spark.sql.shuffle.partitions=20;
运行同一个查询语句,参数改变后,Task(partition)的数量就由200变成了20。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号